【数据分析与展示】Pandas库入门
Pandas库
一、什么是Pandas
Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的经常与NumPy和Matplotlib库配合使用。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。其中最重要的两种数据结构就是Series和DataFrame,在此数据类型的基础上又延伸出基本操作、运算操作、特征类操作以及关联类操作。
NumPy和Pandas都是用于科学计算的库,但是仔细深究的话,二者之间也是存在有一定的区别的,首先NumPy作为Pandas的基础,内部使用的是基础数据类型,更注重与数据的结构表达,也就是维度方面的表达,而Pandas实际上是扩展的数据类型,更加关注数据的应用表达,也就是数据与索引之间的关系。
二、Series类型的基本操作
Series可以理解为带标签的一维数组,有点像C语言数据结构里面的Map,数组中的数据可以为任何类型,由一组数据和一组索引组成。索引与数据的关系是整个Pandas中十分看重的一点,不管是Series还是DataFrame都是很关键的一点。
创建的语法并不麻烦,引入包之后,将数据存入即可。创建可以以多种数据进行创建,包括列表、标量值、字典、数组和函数。创建时有两个参数,存入的数据和所使用的标签,标签可以不写,不写采用默认的设置,即用数字来作为索引,这种情况称为自动索引,如果要使用自己的索引,则需要用一个列表给出索引的名字,这种方式称为自定义索引。
采用列表作为数据的载体是最常用的方法,效果如下: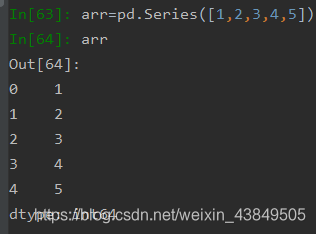
使用标量也就是使用单个数字创建相当于提供了一个全是一样数值的列表进行创建,这种创建方式下必须要指明索引,效果如下: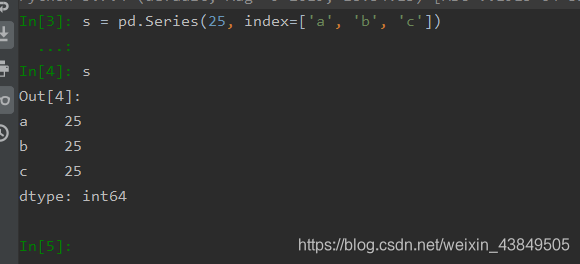
不难看出,这种方式创建会让每个索引对应的数值都取给定的数值。
利用字典创建主要还是利用了字典中键值对的概念,键值对和Series类型中索引和值之间的关系完美对应,所以可以直接利用这个对应关系进行创建,创建后键值对中键作为索引,值作为数值,效果如下: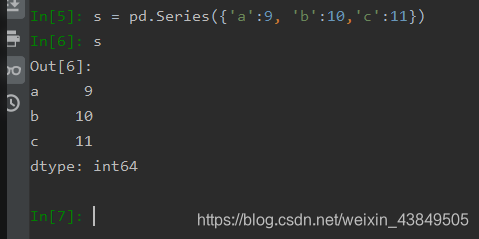
使用数组的创建于使用列表的创建差别不大,这里就不重复了。
前面提到过,Series相当于一个带有标签的一维数组,所以最基本的操作就是读取索引和读取数据,可以使用index获得索引,使用values获得数据。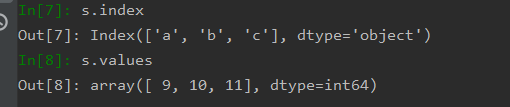
当然,也可以根据索引直接读取数据,这里的操作就像是C++里面的Map与数组的结合,可以使用key值进行索引,也可以使用下标进行索引,效果如下: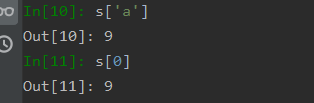
此外,Series的索引还可以同时检索多个,此时需要用一个列表将要检索的关键字都放进去,需要注意的是上面提到直接索引可以用key值也可以用下标,但在同时检索多个的情况下是不可以的,只能单独使用一个,而不能混用,效果如下: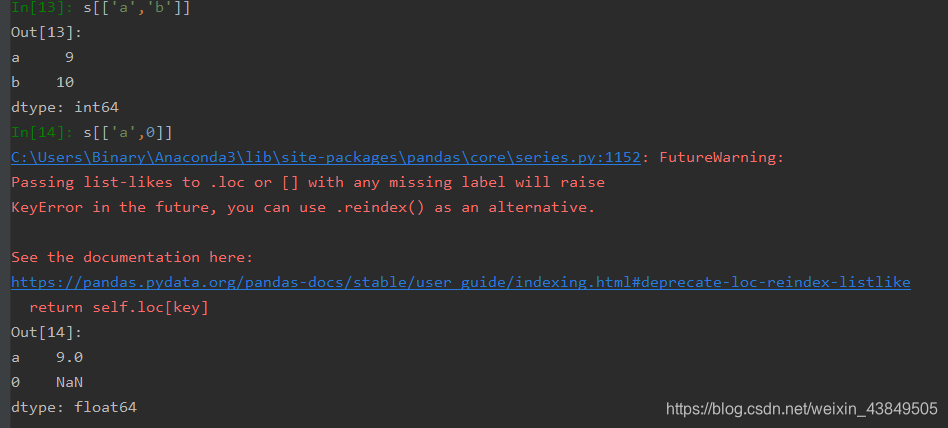
上图中直接使用key值进行索引是没有问题的,直接返回了ab对应的数据,而key值和下标混用就出现了问题,0对应的value并不能正确检索到,只能采用一种方式进行检索,而不能混用检索。
对于Series的索引切片很大程度上和Pandas是一样的,除了使用起始位置切片,还可以用布尔切片等方法。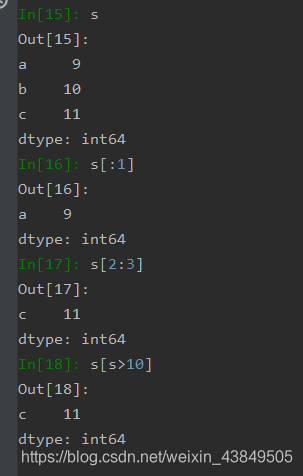
修改值可以直接修改对应位置上的数据,支持随时修改并且立即生效。当需要在已经建好的series后面添加时,可使用append,此方法可以将两个series直接连接在一起。删除时直接使用del即可。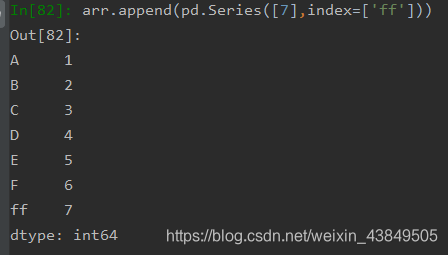
三、DataFrame类型的基本操作
DataFrame是pandas里面另一种基础数据结构,由共用相同索引的一组列组成,是一个表格型的数据类型,可以看作带行名和列名的二维数组,其中的一列就是一个series,不仅有行索引还有列索引。常常使用DataFrame来表达二维或者多维数据。
DataFrame的创建有多种方式:二维结构创建、复杂字典创建、Series创建。
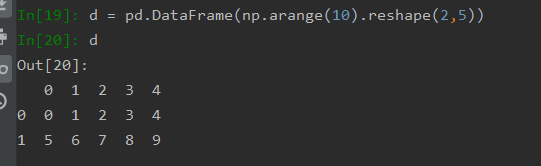
使用二维结构创建包括很多种方式,二维数组、二维列表都可以进行创建,只要是采用二维结构即可:
使用复杂字典其实也是利用了一个二维结构,字典中的键是列的索引,而值则是包含有一维索引的结构,下面的创建方式都是使用复杂字典进行的创建:
①使用Series组成的字典进行创建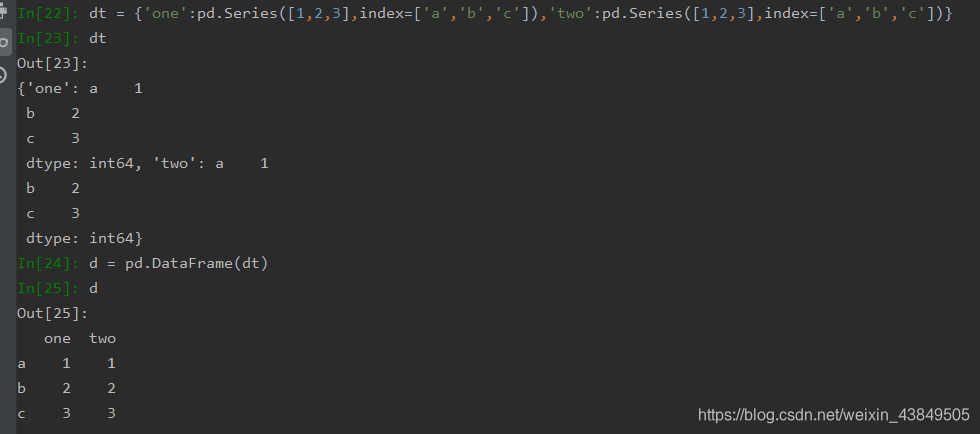
②使用列表字典进行创建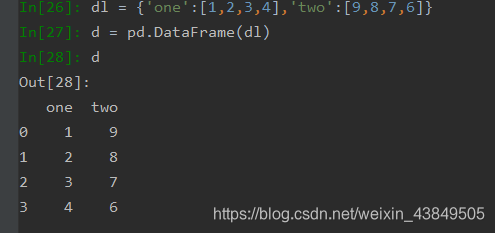
创建的方式有很多种,总之记住二维结构要用二维结构来创建。
三、Pandas库的数据类型操作
可以发现Pandas库中的两个重要数据结构,都是针对索引的,所以对于索引的操作也是Pandas库中很重要的知识。对于索引的操作主要还是增和删。
对索引的增加也可以说是重新索引,主要使用reindex函数,用于重新排列Series和DataFrame的索引,函数的主要参数如下:
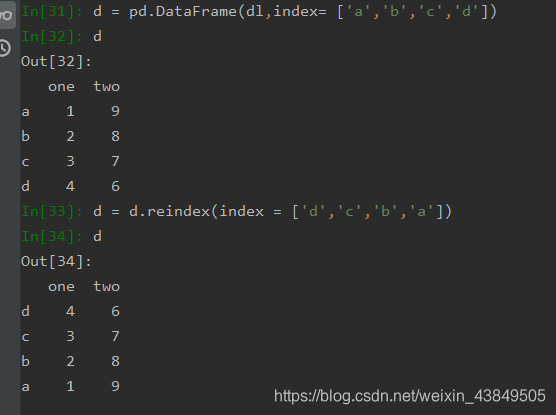
需要注意的是,reindex是重新排列索引,而不是更换索引的名称,也就是说重新排列的索引必须是原索引换一下顺序,如果有原来没有的项,则会直接出现缺失值。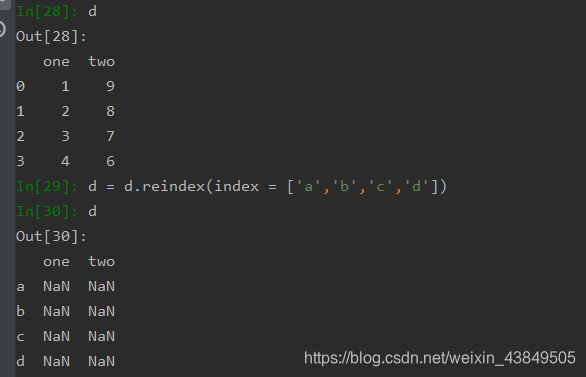
实际上无论是DataFrame还是Series,索引都是Index类型的一个对象,这个对象是一个不可修改类型,专门作为索引,有着自己独有的一些方法: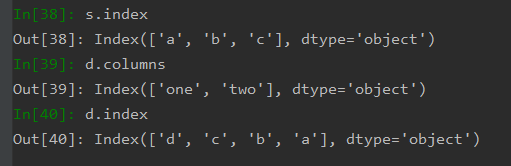
对于索引对象,常用的方法如下: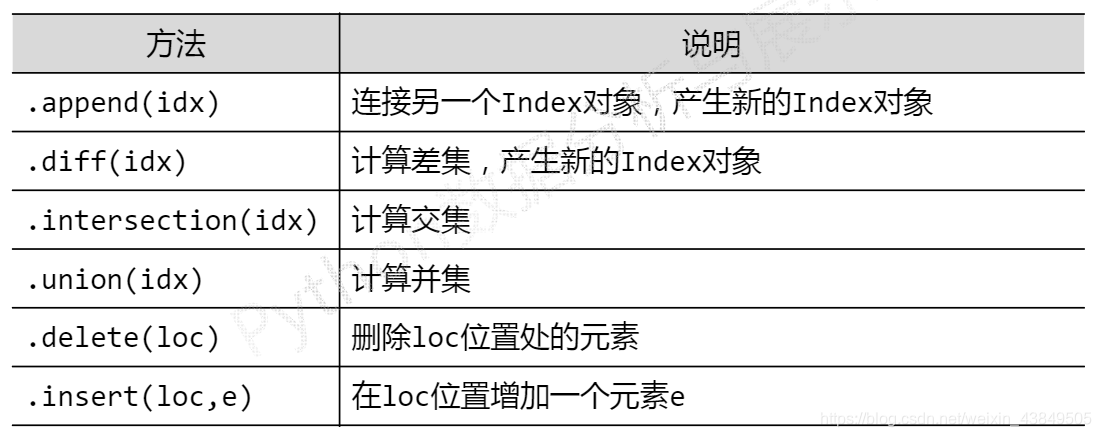
这些方法需要通过DataFrame或者Series的对象来调用,二者调用区别不大,DataFrame只需要注意一下轴的方向问题就好,需要使用axis参数来指定是在横轴索引上操作还是在纵轴索引上操作,默认是axis=0,即对index进行操作。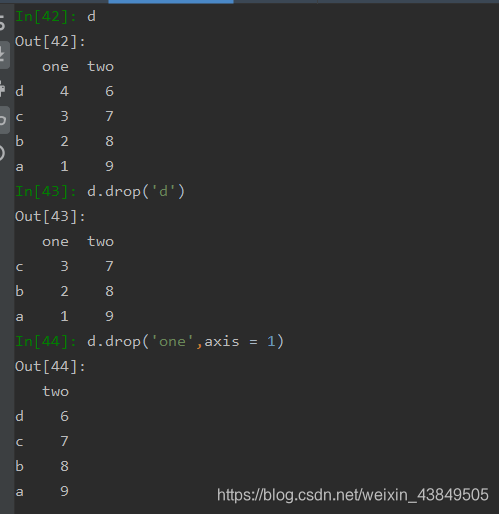
四、Pandas库的数据类型运算
Pandas库中的数据类型运算和NumPy里面的实际上是很相似的,也是分为和标量或者和对象进行运算,和标量的运算就没什么好说的了,和另一个数据类型的运算一方面是广播的问题,另一方面则是Pandas库对象的一个特有的问题,因为DataFrame和Series都是带有标签的数据结构,所以在运算时存在一个索引的对齐关系,只有标签一致的才可以进行运算,也就是先进行补齐,补齐后再运算。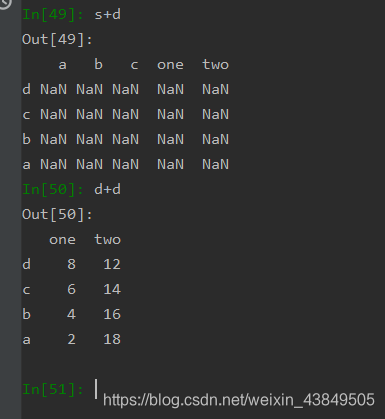
上图就是一种很典型的错误,两个Pandas对象相加,会根据索引去相加,也就是说d的index是abcd,与之相加的s,只有索引abcd的项才会与之相加,否则会自动补上NaN,补上之后再运算,无论怎么运算都还是一个NaN,而d+d在运算时,直接根据索引匹配,而且是完全匹配的,不需要补充,所以可以直接运算。
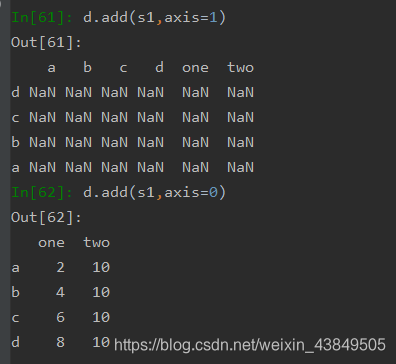
此外,对于DataFrame,由于其有两个轴,所以会出现按照哪个轴的索引进行匹配的情况,这时候就不能直接使用加减法符号来进行计算了,而是需要使用下面的这种通过方法进行运算的方式:
五、Pandas库的数据排序
提到排序就必然是和sort有关,在Pandas库中由于提供了标签这种机制,所以就有两种排序的方法,一种是根据索引排序,另一种是根据数值排序。主要使用sort_index方法在指定轴上根据索引进行排序,默认为升序,使用axis选择轴,使用ascending选择是升序还是降序(默认升序),使用sort_values方法在指定轴上根据数值进行排序,参数与sory_index一样。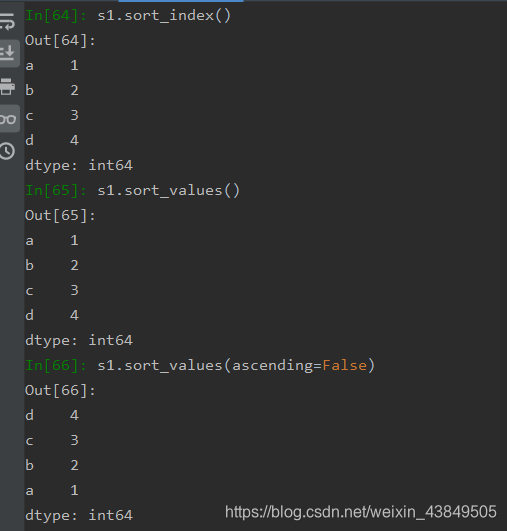
此外,对于空值,也就是NaN,一般统一放到排序的末尾。
六、数据的基本统计分析
基本的统计分析实际上就是一些函数,典型的见名知意: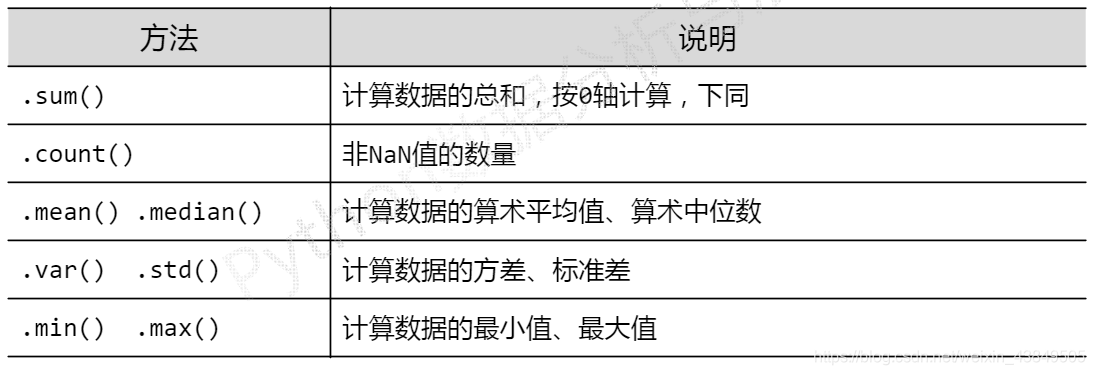
这些是同时适用于DataFrame和Series的方法,也有只适用于Series的方法:
也有一个笨办法,直接使用describe方法,这个方法用于针对各轴各列进行统计汇总,一般是用在正式处理之前,先用这个方法来大体看一眼数据的情况,效果如下: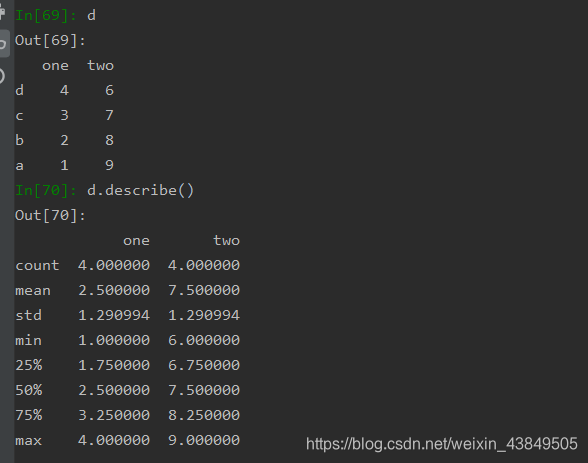
七、数据的累计统计分析
累计统计分析也是一些方法,和前面的基本统计分析不同的是,这部分主要是涉及一些求和、求积等需要多个元素参与的方法:

最后附一道作业题,大佬求放过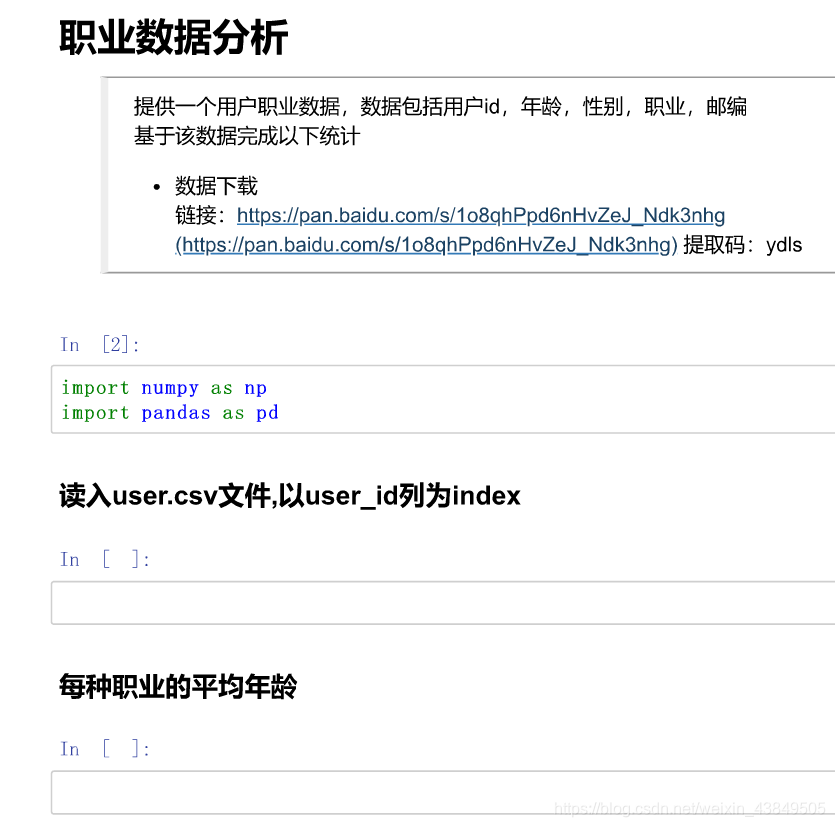


import numpy as np
import pandas as pd
values = pd.read_csv('C:\\Users\\Binary\\Desktop\\user.csv', index_col='user_id')
print('***The average age ,the maximum and the minimum age in every occupation***')
ages = values.groupby('occupation').age.agg(['min', 'max', 'mean'])
print(ages)
print('***The rate of male***')
def sexnum(s):
if s == 'M':
return 1
else:
return 0
values['gender_t'] = values['gender'].apply(sexnum)
sex = values.groupby('occupation').gender_t.sum()/values.occupation.value_counts()*100
print(sex.sort_values(ascending = False))
print('***The average age in every occupation and gender***')
ageave = values.groupby(['occupation', 'gender']).age.agg(['mean'])
print(ageave)
print('***The male female ratio in every occupation***')
ans = values.groupby('occupation').gender_t.sum()/(values.occupation.value_counts()-values.groupby('occupation').gender_t.sum())
print(ans)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)