DataX:数据同步json配置详解|mysql同步到clickhouse案例
上节我们讲解了datax的安装和基本工作流程,本期我们具体讲解datax同步的配置项含义,以及如何利用datax实现全量、增量数据同步
文章目录
0. 引言
上节我们讲解了datax的安装和基本工作流程,本期我们具体讲解datax同步的配置项含义,以及如何利用datax实现全量、增量数据同步
1. datax配置详解
datax中的json同步配置文件在官方文档中都可以找到示例
其配置文件主要分为以下结构:
|-- setting
|-- speed
|-- errorLimit
|-- content
|-- reader
|-- writer
以下我们以mysql的为例,具体讲解其参数含义
1.1 setting
1.1.1 speed
DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,用以灵活控制作业速度,让同步作业在库可以在承受的范围内达到最佳的同步速度
"speed": {
"channel": 5,
"byte": 1048576,
"record": 10000
}
- channel:管道数,即并行数,即DataX会使用多少个并行通道进行数据传输。默认值为1,需与splitPk一同使用,否则无效果,也就是说要配置并行数,同时还要指定拆分字段splitPk,否则并行数会退化为1个,该字段具体如何选择,我们在下文讲解
- record:每次同步多少条数据,取record和byte中的最小值
- byte:每次同步多少字节数据,取record和byte中的最小值
1.1.2 errorLimit
errorLimit为错误数据限制,这里有两个参数record和percentage,指当异常数据达到多少时同步取消,取record和percentage的最小值
数据同步时,如果数据中包含格式不正确的字段(如日期、数字等),可能会导致解析失败,这时就会判定为错误数据。
"errorLimit": {
"record": 0,
"percentage": 0.02
}
- record: 达到错误的条数
- percentage:达到错误的百分比
1.2 content
1.2.1 reader
reader模块的作用是从数据源读取数据,它是整个数据同步任务的数据来源端
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "yiAxzw1jSbbutLBTMTLrAA==",
"column": [
"`id`",
"`name`",
"`sex`",
"`number`"
],
"splitPk": "",
"connection": [
{
"table": [
"src_zhang"
],
"jdbcUrl": [
"jdbc:mysql://192.168.6.23:3308/2024122710082_default"
]
}
]
}
}
- name:用于指定reader的类型,如mysqlreader、oraclereader
- parameter.username:来源数据库连接账号
- parameter.password:来源数据库连接账号密码
- parameter.column:要同步的字段,*表示所有字段,也可支持常量配置,但是要遵循对应数据库的sql与法,示例:
["id", "table", "1", "'bazhen.csy'", "null", "to_char(a + 1)", "2.3" , "true"] - parameter.connection.table: 要同步的表,*表示所有表
- parameter.connection.jdbcUrl:来源数据库的jdbc链接,支持书写多个,如果多个,datax会进行探测,选择一个可以正常链接的。
- parameter.splitPk:用于数据分片的字段名,与
speed.channel连用,推荐使用表主键(目前splitPk仅支持整形数据切分)。其字段选取遵循以下原则:
(1)splitPk应选择一个数据分布相对均匀的字段,以避免某个子任务处理过多数据而导致性能瓶颈,比如一张表中,主键id为自增id, 那么splitPk就可以设置为id;
(2)另外要确保splitPk字段在源数据库和目标数据库中都存在,并且类型一致
- parameter.where:指定数据过滤条件,只同步满足条件的数据,示例:
"where": "id > 10" - parameter.querySql:当不指定table时,可以指定一个sql来查询数据,主要用于需要关联查询的场景,示例:
"querySql": ["select * from sys_user"]
1.2.2 writer
writer模块的作用是将reader模块读取并处理后的数据写入到目标数据源中。它是整个数据同步任务的数据目标端
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?useUnicode=true&characterEncoding=gbk",
"table": [
"test"
]
}
]
}
}
- name: 指定writer的类型,例如mysqlwriter、oraclewriter、txtfilewriter等。
- parameter.connection: 目标数据库的连接信息,用于与reader类似
- parameter.column:目标数据表的字段,与reader中相对应,但是不能指定常量值
- parameter.writeMode:写入模式,如insert、update、replace等,用于处理数据冲突。分别代表写入数据时采用的sql语句为
insert into或者ON DUPLICATE KEY UPDATE或者replace into - parameter.session:DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
- parameter.preSql:写入数据到目的表前,会先执行这个sql。如果 Sql 中有你需要操作到的表名称,请使用 @table 表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, … datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:“preSql”:[“delete from @table”],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称
- parameter.postSql:写入后执行的sql,用法同preSql
- parameter.batchSize:次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况,默认值1024
2. mysql同步至clickhouse案例
2.1 全量同步
1、这里我先单独讲解利用datax创建同步配置文件,然后进行手动调用的场景,后续我们再结合datax-web带大家进行可视化配置
根据上文的讲解,查询官方针对mysql reader和clickhouse writer的文档说明,书写配置文件
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "yiAxzw1jSbbutLBTMTLrAA==",
"column": [
"`id`",
"`name`",
"`sex`",
"`number`"
],
"splitPk": "id",
"connection": [
{
"table": [
"src_zhang"
],
"jdbcUrl": [
"jdbc:mysql://192.168.6.23:3308/2024122710082_default"
]
}
]
}
},
"writer": {
"name": "clickhousewriter",
"parameter": {
"username": "default",
"password": "kFBucg+xHfmPLLcml8cg6w==",
"column": [
"id",
"name",
"sex",
"number"
],
"connection": [
{
"table": [
"src_zhang_a"
],
"jdbcUrl": "jdbc:clickhouse://192.168.6.23:8123/2025010713174_default"
}
]
}
}
}
]
}
}
2、将该json文件mysql2ck.json放到datax安装目录的job目录下
3、进入datax安装目录,然后执行同步任务指令
python bin/datax.py job/mysql2ck.json
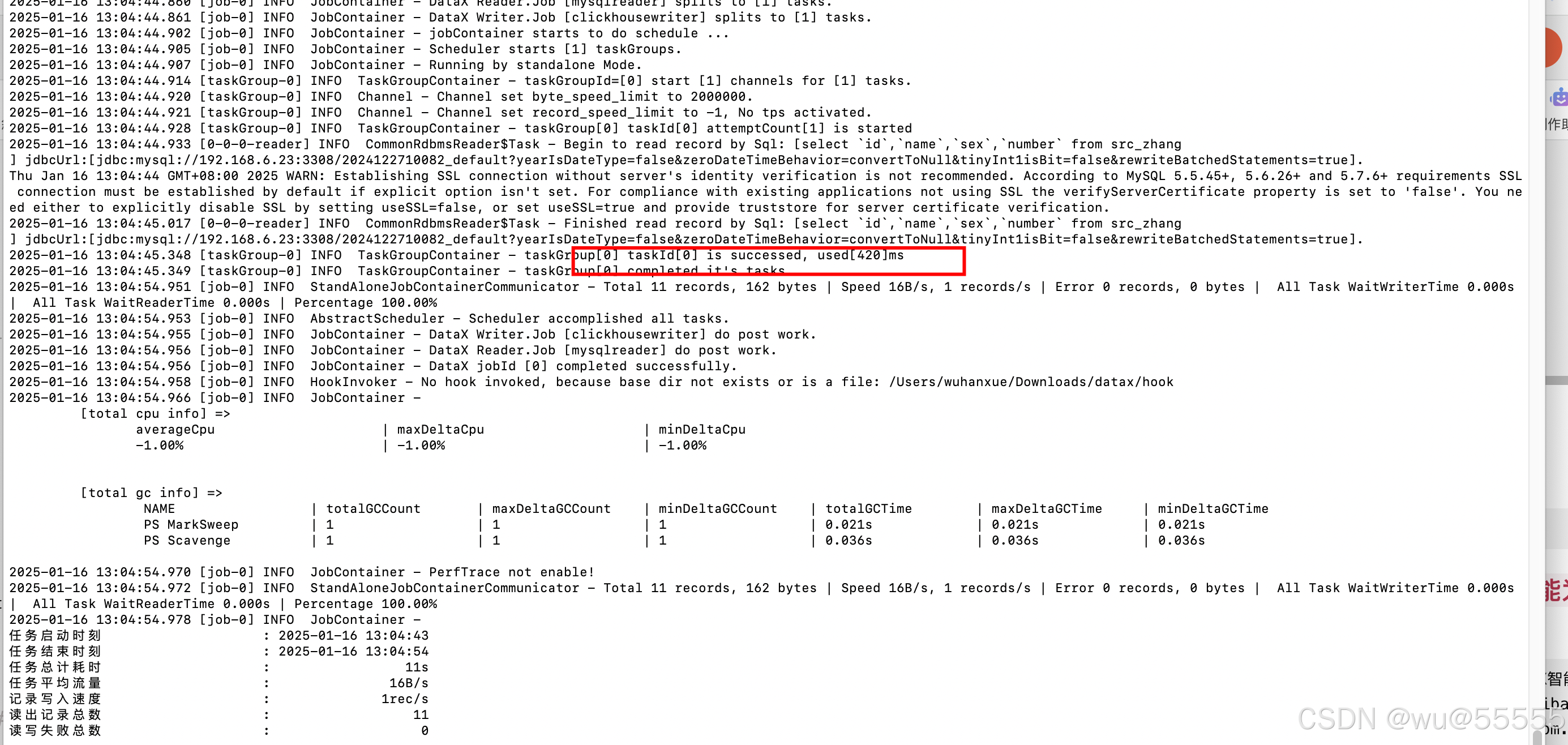
4、可以看到执行成功,我们去clickhouse数据库查询,咱们的数据已经同步过来了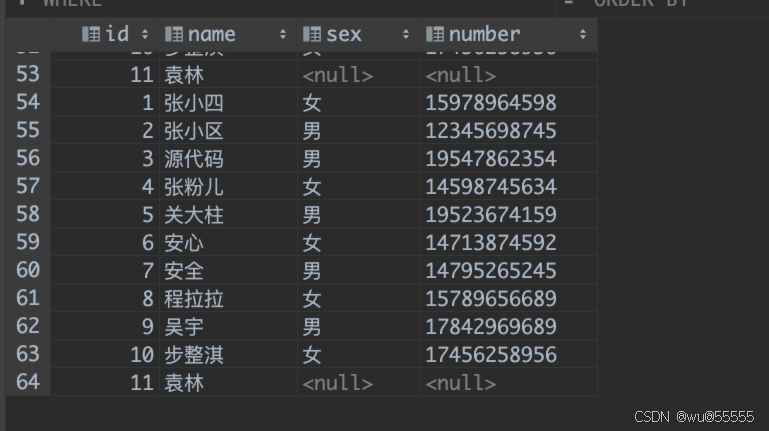
补充:出现报错在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] 经DataX智能分析,该任务最可能的错误原因是:
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] com.alibaba.datax.common.exception.DataXException: Code:[Framework-03], Description:[DataX引擎配置错误,该问题通常是由于DataX安装错误引起,请联系您的运维解决 .]. - 在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:30)
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] at com.alibaba.datax.core.job.JobContainer.adjustChannelNumber(JobContainer.java:430)
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] at com.alibaba.datax.core.job.JobContainer.split(JobContainer.java:387)
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] at com.alibaba.datax.core.job.JobContainer.start(JobContainer.java:117)
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] at com.alibaba.datax.core.Engine.start(Engine.java:86)
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] at com.alibaba.datax.core.Engine.entry(Engine.java:168)
2025-01-15 14:45:14 [AnalysisStatistics.analysisStatisticsLog-53] at com.alibaba.datax.core.Engine.main(Engine.java:201)
这是因为新版本中单个channel的bps不能为非负数,这个我们调整下datax下的/conf/core.json配置文件,调整其中的core.transport.channel.speed.byte为非负数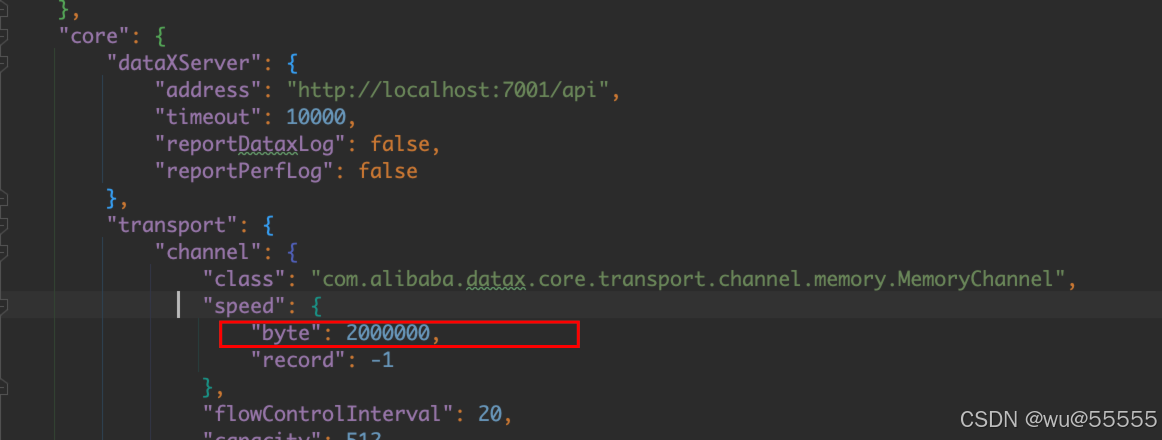
2.2 增量同步
上述我们演示的是全量同步的配置,但是在实际运行时,我们更多需要的是增量定时同步,于是我们就需要额外配置每次同步的限制条件,
如果我们的数据是T+1的,并且有创建时间字段,那么可以直接通过where配置项来实现
"where": "create_time >= CURDATE()"
这里就是通过自带的日期函数来实现,但如果没有日期字段,或者不是按天更新的,那么就需要我们有地方记录上一次更新的偏移量,然后在更新脚本里通过${}占位符声明,如
"where": "id >= ${last_max_id}"
或者也可以使用querySql参数来定义
"connection": [
{
"table": [
"src_zhang"
],
"jdbcUrl": [
"jdbc:mysql://192.168.6.23:3308/2024122710082_default"
],
"querySql": ["select id,name,sex,number from src_zhang where id >= ${last_max_id}"]
}
]
}
然后通过datax的-p参数来定义自定义参数,如下,定义自定义参数last_max_id(参数名前加-D配置),datax中会通过该配置将参数值传递到配置文件中并进行替换
python bin/datax.py -p "-Dlast_max_id=4" job/mysql2ck_delta.json
执行脚本,查看结果,可以看到新同步的数据就是从id>=4开始同步的

那么这个-Dlast_max_id=4中的4在哪里维护呢,不能每次都手动修改吧,这里提供两种思路给大家:
1、每次执行前查询一下最大的id,然后保存到数据库中,二次运行时,将该值取出,执行完后再次更新新的id到数据库
2、通过datax-web来实现增量同步,该组件已经帮我们实现了上述的步骤,我们只需要配置即可,下文我们将讲解如何在datax-web中配置定时增量同步。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 50
50 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)