本文章是3.2的内容,如果想要源代码和数据可以看以下链接:
https://download.csdn.net/download/Ahaha_biancheng/83338868
3.2 Pandas数组结构
结构化数据分析是一种成熟的过程和技术。关系数据库用于结构化数据。
pandas是基于python的Numpy库的数据分析工具包,非常方便关系数据库的处理。
◆ Series数据结构用于处理一维数据
◆ DataFrame数据结构用于处理二维数据和高维数据
◆ 汇集多种数据源数据、处理缺失数据
◆ 对数据进行切片、聚合和汇总统计
◆ 实现数据可视化

import numpy as np
import pandas as pd
from pandas import DataFrame, Series
3.2.1 Series对象
Series创建
Series([data, index, ....])
data:Python的列表或Numpy的一维ndarray对象
index:列表,若省略则自动生成0 ~n-1的序号标签
例题3-1 创建5名篮球运动员身高的Series结构对象height,值是身高,
索引为球衣号码(数字字符串作为索引)。
height=Series([187,190,185,178,185],index=['13','14','7','2','9'])
height
13 187
14 190
7 185
2 178
9 185
dtype: int64
height2=Series([187,190,185,178,185])
height2
0 187
1 190
2 185
3 178
4 185
dtype: int64
Series对象与字典类型类似,可以将index和valus数组中序号相同的一组元素视为字典的键-值对。用字典创建Series对象,将字典的key作为索引:
height3 = Series({'13':187, '14':190})
height3
13 187
14 190
dtype: int64
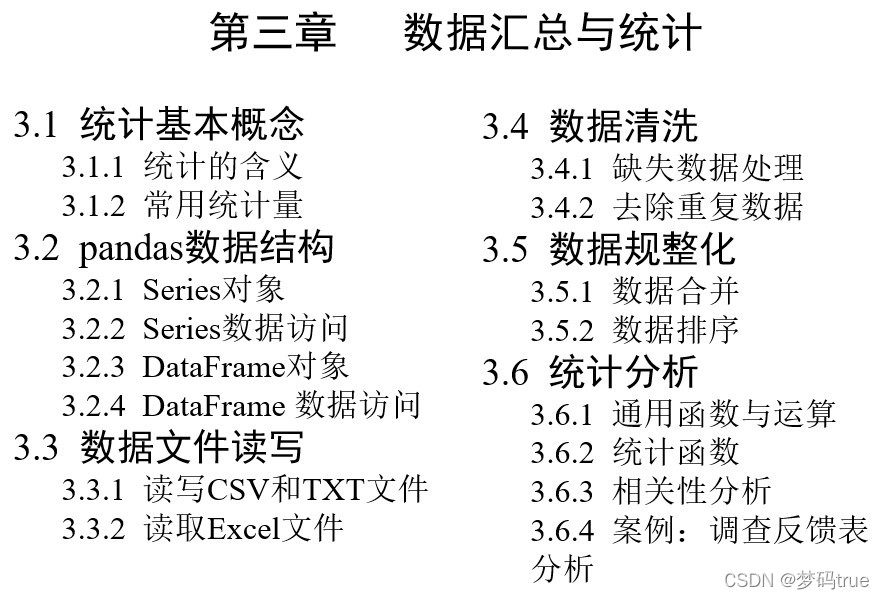
3.2.2 Series数据选取
(1)查询
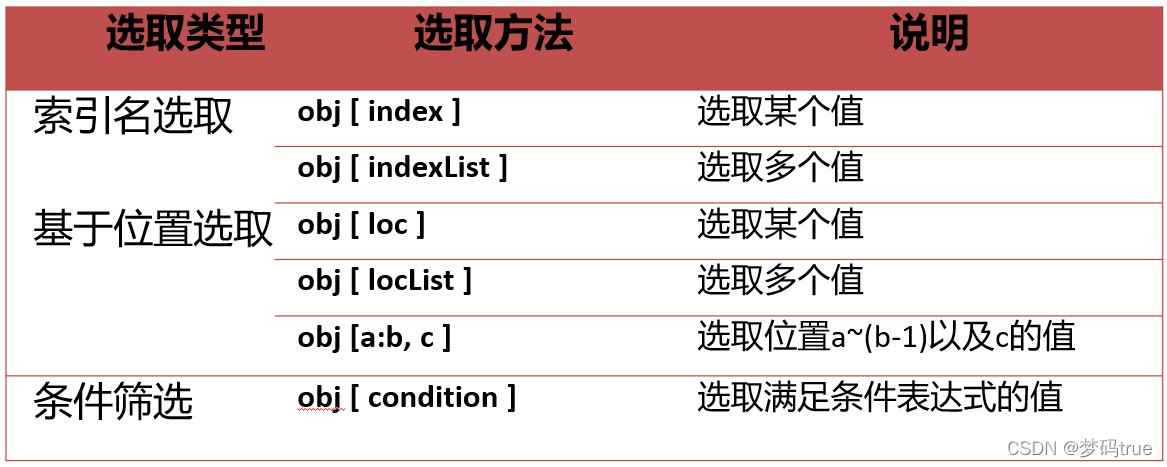
height['13']
187
height[['13','2']]
13 187
2 178
dtype: int64
height[4]
185
height[0:3]
13 187
14 190
7 185
dtype: int64
height[height.values>=185]
13 187
14 190
7 185
9 185
dtype: int64
height=Series([187,190,185,178,185], index = ['13','14','7','2','9'])
height
13 187
14 190
7 185
2 178
9 185
dtype: int64
height.values>=185
array([ True, True, True, False, True])
height[[ True, True, True, False, True]]
13 187
14 190
7 185
9 185
dtype: int64
(2)修改
先查询后赋值
height['13'] = 180
height
13 180
14 190
7 185
2 178
9 185
dtype: int64
height[['13','14']] = 180
height
13 180
14 180
7 185
2 178
9 185
dtype: int64
height[:] = 180
height
13 180
14 180
7 180
2 180
9 180
dtype: int64
(3) 增加
Series不能直接添加新数据
append()函数将两个Series拼接产生一个新的Series
不改变原Series
height.append({'3':191})
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-34d946c9e2bd> in <module>
----> 1 height.append({'3':191}) # 出错
E:\AnacondaInstall\lib\site-packages\pandas\core\series.py in append(self, to_append, ignore_index, verify_integrity)
2579 else:
2580 to_concat = [self, to_append]
-> 2581 return concat(
2582 to_concat, ignore_index=ignore_index, verify_integrity=verify_integrity
2583 )
E:\AnacondaInstall\lib\site-packages\pandas\core\reshape\concat.py in concat(objs, axis, join, ignore_index, keys, levels, names, verify_integrity, sort, copy)
269 ValueError: Indexes have overlapping values: ['a']
270 """
--> 271 op = _Concatenator(
272 objs,
273 axis=axis,
E:\AnacondaInstall\lib\site-packages\pandas\core\reshape\concat.py in __init__(self, objs, axis, join, keys, levels, names, ignore_index, verify_integrity, copy, sort)
355 "only Series and DataFrame objs are valid".format(typ=type(obj))
356 )
--> 357 raise TypeError(msg)
358
359 # consolidate
TypeError: cannot concatenate object of type '<class 'dict'>'; only Series and DataFrame objs are valid
a = Series([191, 182], index=['3','0'])
a
3 191
0 182
dtype: int64
new = height.append(a)
new
13 187
14 190
7 185
2 178
9 185
3 191
0 182
dtype: int64
height
13 180
14 180
7 180
2 180
9 180
dtype: int64
(4) 删除
height.drop(['13'])
14 190
7 185
2 178
9 185
dtype: int64
height.drop('14')
13 187
7 185
2 178
9 185
dtype: int64
height
13 187
14 190
7 185
2 178
9 185
dtype: int64
new = height.drop(['13'])
new
14 190
7 185
2 178
9 185
dtype: int64
(5) 更改索引
用新的列表替换即可
height.index = [5, 6, 7, 8, 9]
height
5 180
6 180
7 180
8 180
9 180
dtype: int64
height[[5, 6]]
5 180
6 180
dtype: int64
height.iloc[0]
180
3.2.3 DataFrame对象
DataFrame 包括值(values)、行索引(index)和列索引(columns)3部分
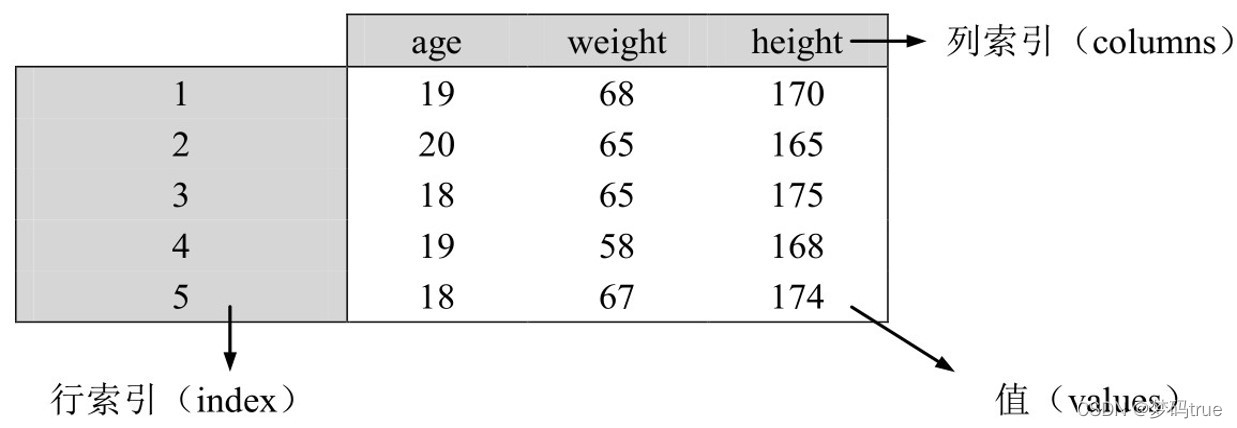
DataFrame 创建方法:
DataFrame ( data,index = […],columns=[…] )
* data:列表或NumPy的二维ndarray对象
* index,colunms:列表,若省略则自动生成0 ~n-1的序号标签
data = np.array([[19,170,68],[20,165,65],[18, 175, 65]])
st = DataFrame(data, index=[11,12,13], columns=['age','height','weight'])
st
|
age |
height |
weight |
| 11 |
19 |
170 |
68 |
| 12 |
20 |
165 |
65 |
| 13 |
18 |
175 |
65 |
DataFrame数据访问
(1) 访问
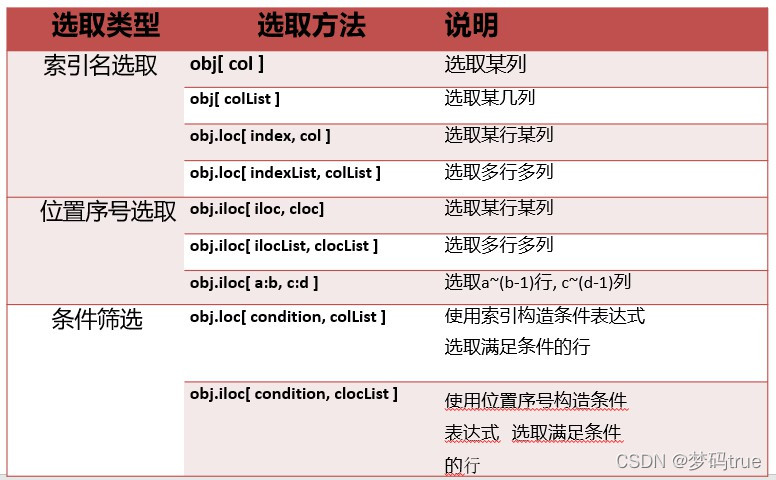
st
|
age |
height |
weight |
| 11 |
19 |
170 |
68 |
| 12 |
20 |
165 |
65 |
| 13 |
18 |
175 |
65 |
st[['age']]
st[['age','height']]
|
age |
height |
| 11 |
19 |
170 |
| 12 |
20 |
165 |
| 13 |
18 |
175 |
st[0:2]
st.iloc[0:2, :]
|
age |
height |
weight |
| 11 |
19 |
170 |
68 |
| 12 |
20 |
165 |
65 |
st.loc[11]
age 19
height 170
weight 68
Name: 11, dtype: int32
st.loc[[11,13],['age','height']]
|
age |
height |
| 11 |
19 |
170 |
| 13 |
18 |
175 |
st
|
age |
height |
weight |
| 11 |
19 |
170 |
68 |
| 12 |
20 |
165 |
65 |
| 13 |
18 |
175 |
65 |
st.iloc[[0,1],[0,1]]
|
age |
height |
| 11 |
19 |
170 |
| 12 |
20 |
165 |
st.iloc[0:2, 0:2]
|
age |
height |
| 11 |
19 |
170 |
| 12 |
20 |
165 |
st.loc[st['age']>=19, ['height']]
(2)增加
DataFrame对象可以添加新的列,但不能直接增加新的行,增加行需要通过两个DataFrame对象的合并实现(见章节3.5)
st
|
age |
height |
weight |
| 11 |
19 |
170 |
68 |
| 12 |
20 |
165 |
65 |
| 13 |
18 |
175 |
65 |
st['expense'] = [1100, 1000, 900]
st
|
age |
height |
weight |
expense |
| 11 |
19 |
170 |
68 |
1100 |
| 12 |
20 |
165 |
65 |
1000 |
| 13 |
18 |
175 |
65 |
900 |
(3)修改
st['age'] = st['age'] + 1
st
|
age |
height |
weight |
expense |
| 11 |
20 |
170 |
68 |
1100 |
| 12 |
21 |
165 |
65 |
1000 |
| 13 |
19 |
175 |
65 |
900 |
st['expense'] = 1200
st
|
age |
height |
weight |
expense |
| 11 |
19 |
170 |
68 |
1200 |
| 12 |
20 |
165 |
65 |
1200 |
| 13 |
18 |
175 |
65 |
1200 |
st['expense'] = [1300, 1400, 1500]
st
|
age |
height |
weight |
expense |
| 11 |
19 |
170 |
68 |
1300 |
| 12 |
20 |
165 |
65 |
1400 |
| 13 |
18 |
175 |
65 |
1500 |
st.loc[[11]] = [21,180,70,20]
st
|
age |
height |
weight |
expense |
| 11 |
21 |
180 |
70 |
20 |
| 12 |
20 |
165 |
65 |
1400 |
| 13 |
18 |
175 |
65 |
1500 |
st.loc[st['expense']<800, 'expense'] = 800
st
|
age |
height |
weight |
expense |
| 11 |
21 |
180 |
70 |
800 |
| 12 |
20 |
165 |
65 |
1400 |
| 13 |
18 |
175 |
65 |
1500 |
st.loc[st['expense']==800, 'expense'] = 80
mask = st['expense']<800
mask
11 True
12 False
13 False
Name: expense, dtype: bool
st.loc[mask, 'expense'] = 900
st
|
age |
height |
weight |
expense |
| 11 |
21 |
180 |
70 |
900 |
| 12 |
20 |
165 |
65 |
1400 |
| 13 |
18 |
175 |
65 |
1500 |
(4)删除
不修改原始数据对象,如果需要直接删除原始对象的行或列,设置参数 inplace=True
axis = 0表示行,axis = 1表示列 ˈaksəs
st.drop(11, axis=0)
|
age |
height |
weight |
expense |
| 12 |
20 |
165 |
65 |
1400 |
| 13 |
18 |
175 |
65 |
1500 |
st.drop('age', axis=1)
|
height |
weight |
expense |
| 11 |
170 |
68 |
1100 |
| 12 |
165 |
65 |
1000 |
| 13 |
175 |
65 |
900 |
st.drop(['height','age'], axis=1)
|
weight |
expense |
| 11 |
68 |
1100 |
| 12 |
65 |
1000 |
| 13 |
65 |
900 |
st
|
age |
height |
weight |
expense |
| 11 |
20 |
170 |
68 |
1100 |
| 12 |
21 |
165 |
65 |
1000 |
st.drop([13], axis=0, inplace=True)
st
|
age |
height |
weight |
expense |
| 11 |
20 |
170 |
68 |
1100 |
| 12 |
21 |
165 |
65 |
1000 |



 0
0 0
0


 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)