数据结构:带头双向循环链表
本文详解了带头双向循环链表的结构,在做足了准备工作之后,细致的讲述了如何一步步实现该链表的各个接口,文章末尾又对链表进行了增强一致性的改造。
写有“售后”的博客:一定回复评论和私信,答疑解惑到底,认真探讨大家的疑问,欢迎大家多多指出批评与建议!
参考书籍:《大话数据结构》,《数据结构(C语言版)》
目录
一、准备工作
1.链表的分类
链表根据【有无头结点(带头/不带头);单向/双向;循环/不循环】分为2x2x2=8类。此前我们已经学过单链表(不带头单向不循环链表)数据结构:单链表(Single Linked List)。
今天让我们一起来学习总是和单链表"背道而驰"的带头双向循环链表。
2.带头双向循环链表图解
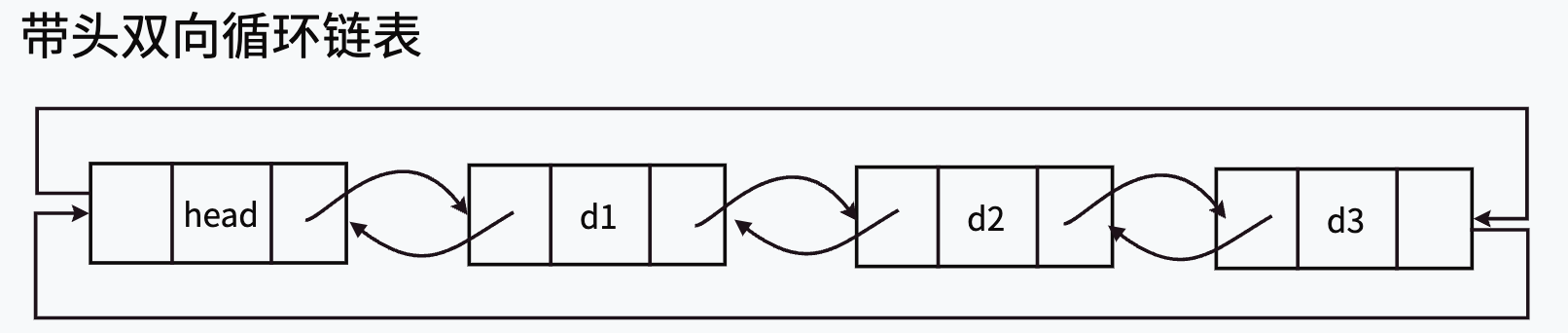
带头:带有一直都处在链表首位的节点——头结点(哨兵位)。头结点中的数据是无意义的。头结点一动不动,指向头结点的指针也不发生改变,因此我们在实现过程中,大多数函数不必使用传址调用,大大简化了代码。
双向:链表中每个节点都有两个指针,一个指向后一个节点,另一个指向前一个节点。
循环:该链表是首尾相连的。
双向和循环特性的巧妙运用可以使得带头双向循环链表增删操作的时间复杂度为O(1)。
二、带头双向循环链表的实现
1.相关头文件及单个节点的定义
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <assert.h>
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prve;
}LTNode;
data是节点中存放的数据。
节点中存放的数据可能会被更改为各种类型,我们为了修改方便使用typedef 类型 STDataType;
next指针指向下一个结构体,prve指针指向上一个结构体。
2.节点的创建
LTNode* LTBuyNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("malloc");
exit(1);
}
newnode->data = x;
newnode->next = newnode->prve = newnode;
return newnode;
}
倒数第二行,创建的节点的两个指针为什么都要指向自己呢?能不能都指向NULL呢?
带头双向循环链表创建的第一个节点一定要是头结点,如果我们的头结点的newnode->next = newnode->prve = NULL;那么这个只含一个头结点的链表就变成了带头双向不循环链表,不是我们想要的循环链表了。因此我们让两个指针指向自己所在的节点,这样才能正确创建头结点,创建其它节点时也没有隐患。
3.链表初始化
void LTInit(LTNode** pphead)
{
assert(pphead);
*pphead = LTBuyNode(-1);
}
int main()
{
LTNode* plist = NULL;
LTInit(&plist);
return 0;
}
在主函数中创建头结点plist并初始化为NULL,我们初始化链表需要让plist从指向NULL变为指向头结点,plist需要发生改变,形参要影响实参,初始化使用传址调用。
头结点的数据是无意义的,我们就定为-1吧
4.链表的尾插
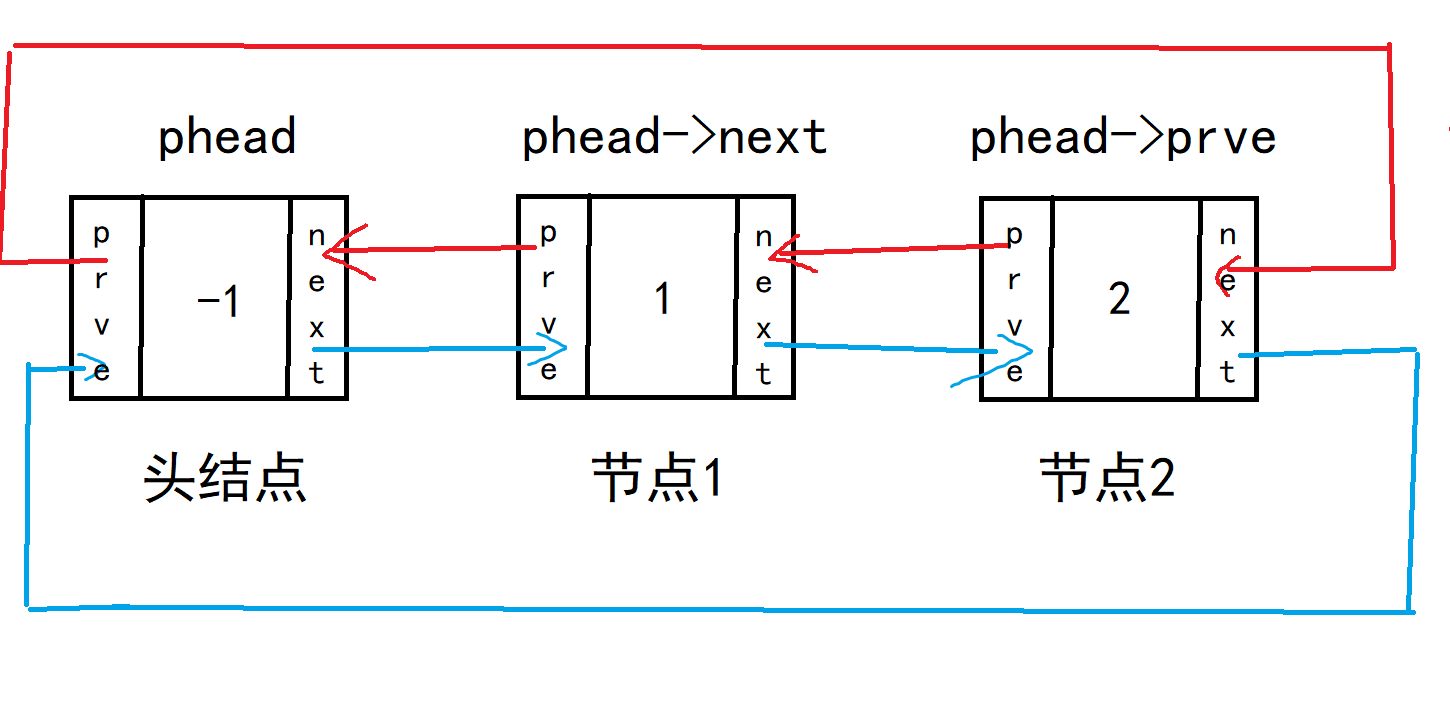
void LTPushBack(LTNode* phead,LTDataType x)
{
assert(phead);
LTNode* newnode = LTBuyNode(x);
newnode->next = phead;
newnode->prve = phead->prve;
phead->prve->next = newnode;
phead->prve = newnode;
}
我们假设链表中已有多个节点,这时候来尾插节点
3。
头结点指针phead指向空就是单链表了,我们防一手,不让他为NULL。
先改变不影响链表的指针:先改变“外人”newnode的两个指针,newnode要插在末尾,他的next指针指向头结点,即指向next。prve指针指向节点2,即指向phead->prve;因此有
newnode->next = phead;
newnode->prve = phead->prve;
接下来改变节点2的next指针和头结点的prve指针。有三种方法
方法一:先改变节点2的next指针,再改变头结点的prve指针。
phead->prve->next = newnode;
phead->prve = newnode;
方法二:先改变头结点的prve指针,再改变节点2的next指针。不使用遍历。
注意,我们先改变的头结点的prve指针指向,就无法通过头结点的prve指针找到节点2了,若想找到节点2,需要从newnode着手,节点2是newnode->prve,那么再使newnode->prve->next = newnode;
phead->prve = newnode;
newnode->prve->next = newnode;
方法三:先改变头结点的prve指针,再改变节点2的next指针。不从新节点着手,从头结点的下一个节点开始遍历。
phead->prve = newnode;
LTNode* pcur = phead->next;
while(pcur->next!=phead)
{
pcur = pcur->next;
}
pcur->next=newnode;
经验证,只有头结点的链表也适合这样的尾插,因此不必再特殊照顾了。
方法一和方法二的时间复杂度为O(1),方法三的时间复杂度为O(n),显然方法三遍历的方式不够好,这样对比也解释了为什么前文说:双向和循环特性的巧妙运用可以使得带头双向循环链表增删操作的时间复杂度为O(1)。
此后的增删思路和本接口相似,便不再多讲。
5.链表的打印
void LTPrint(LTNode* phead)
{
assert(phead);
LTNode* pcur = phead->next;
while (pcur != phead)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("\n");
}
6.链表的头插
void LTPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = LTBuyNode(x);
newnode->next = phead->next;
newnode->prve = phead;
phead->next->prve = newnode;
phead->next = newnode;
}
头结点是一成不变的,头插是在头结点之后,有效节点们之前插入。
7.判断链表是否为空链表
bool LTEmpty(LTNode* phead)
{
assert(phead);
return phead->next == phead;
}
8.链表的尾删
void LTPopBack(LTNode* phead)
{
assert(phead);
assert(!LTEmpty(phead));
LTNode* del = phead->prve;
del->prve->next = phead;
phead->prve = del->prve;
free(del);
del->next = del->prve = NULL;
}
9.链表的头删
void LTPopFront(LTNode* phead)
{
assert(phead);
assert(!LTEmpty(phead));
LTNode* del = phead->next;
del->next->prve = phead;
phead->next = del->next;
free(del);
del->next = del->prve = NULL;
}
10.链表的查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* pcur = phead->next;
while (pcur != phead)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
这样做不会查找到头结点,只查找了有效节点
11.指定位置之前插入
void LTInsert(LTNode*pos, LTDataType x)
{
assert(pos);
LTNode* newnode = LTBuyNode(x);
newnode->next = pos;
newnode->prve = pos->prve;
pos->prve->next= newnode;
pos->prve = newnode;
}
12.指定位置之后插入
oid LTInsertAfter(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = LTBuyNode(x);
newnode->prve = pos;
newnode->next = pos->next;
pos->next->prve = newnode;
pos->next= newnode;
}
13.指定位置删除
void LTErase(LTNode* pos)
{
assert(pos);
pos->prve->next = pos->next;
pos->next->prve = pos->prve;
free(pos);
pos->next = pos->prve = NULL;
}
14.链表的销毁
void LTDestroy(LTNode** pphead)
{
assert(*pphead);
LTNode* pcur = (*pphead)->next;
while (pcur != *pphead)
{
LTNode* next = pcur->next;
free(pcur);
pcur = next;
next = NULL;
}
free(*pphead);
pcur = *pphead = NULL;
}
销毁链表需要plist从指向头结点到指向NULL,plist需要改变,需要传址调用,形参用二级指针接收。
三、小改进
除链表初始化和链表销毁接口外,其它接口都接收一级指针。为了保持接口的一致性,我们进行一些小改变。
1.链表的初始化
LTNode* LTInit()
{
return LTBuyNode(-1);
}
int main()
{
LTNode*plist=LTInit();
return 0;
}
直接给plist返回一个无意义节点作为头结点,以此达到初始化的目的。
2.链表的销毁
void LTDestroy(LTNode* phead)
{
assert(phead);
LTNode* pcur = phead->next;
while (pcur != phead)
{
LTNode* next = pcur->next;
free(pcur);
pcur = next;
next = NULL;
}
free(phead);
pcur = phead = NULL;
}
int main()
{
LTNode*plist = LTInit();
LTDestroy(plist);
plist = NULL;
return 0;
}
传值调用,形参的改变不影响实参。在函数中,链表的各个节点都被释放掉了,形参也被置为空了。但实参仍指向老地方,指向一个被释放掉了的空间,是野指针,因此我们在出链表销毁函数后必须对plist手动置NULL。
完~
感谢您的阅读!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)