python基于Python对b站热门视频的数据分析与研究
随着互联网技术不断地发展,网络与大数据成为了人们生活的一部分,而对B站热门视频的数据分析与研究作为网上应用的一个全新的体现,由于其特有的便捷性,已经被人们所接受。目前主流的对B站热门视频的数据分析与研究服务不仅不明确并且管理盈利较低,针对用户定制的对B站热门视频的数据分析与研究更能够体现出其服务特色。本项目以对B站热门视频的数据分析与研究为研究背景,采用的框架为 Django和python开发了对
学校代码 13651
编 号
系统简介
随着互联网技术不断地发展,网络与大数据成为了人们生活的一部分,而对B站热门视频的数据分析与研究作为网上应用的一个全新的体现,由于其特有的便捷性,已经被人们所接受。目前主流的对B站热门视频的数据分析与研究服务不仅不明确并且管理盈利较低,针对用户定制的对B站热门视频的数据分析与研究更能够体现出其服务特色。
本项目以对B站热门视频的数据分析与研究为研究背景,采用的框架为 Django和python开发了对B站热门视频的数据分析与研究。本文通过分析对B站热门视频的数据分析与研究的需求,建立起了相关的开发模型,构建出相关的系统需要的开发环境。通过调研,明确了对B站热门视频的数据分析与研究的需求,最后开发实现了系统并进行了测试。
关键词:对B站热门视频的数据分析与研究; Django框架;python语言
1 相关工具及介绍
2.1 Python语言
Python是由荷兰数学和计算机研究学会的吉多·范罗苏姆于20世纪90年代设计的一款高级语言。Python优雅的语法和动态类型,以及解释型语言的本质,使它成为许多领域脚本编写和快速开发应用的首选语言。Python相比与其他高级语言,开发代码量较小,代码风格简洁优雅,拥有丰富的第三方库。Python的代码风格导致其可读性好,便于维护人员阅读维护,程序更加健壮。Python能够轻松地调用其他语言编写的模块,因此也被成为“胶水语言”。
2.2 hive简介
Hive是一个数据仓库工具,当把特定结构地数据文件存入Hive对应的HDFS目录时,Hive能将其映射成表,并提供类 SQL 查询功能。底层会将sql语句转成MapReduce程序,大大方便程序开发,其中执行引擎可以更换,执行效率大大提高,Hive主要用于解决海量结构化日志的数据统计。
在本课题中,配置Hive为主要数据仓库,有以下几点原因
(1) Hive的操作接口采用类SQL语法,提供快速开发能力。
(2)相对于传统的关系型数据库,Hive更擅长于数据分析。
(3) Hive支持用户自定义函数,用户可根据自己的需求来实现自己的函数。
(4) Hive基于HDFS进行存储,扩展性高,可靠性高。
(5) Hive底层计算引擎可更换。
由于Hive默认底层引擎位MapReduce,MapReduce在遇到迭代式任务时,会将任务落盘至HDFS再进行运算,对于大批量数据处理来说,这很影响效率,所以我们会将引擎改成Tez。
2.3 Django框架简介
Django被官方称之为“完美主义者框架”,只需要很少的代码就能更快的完成一个优秀的Web应用。Django采用了MTV框架模式,此模式根据MVC进行改进形成了更适于Django的设计模式。M为模型(Model)、T为模板(Template)、V为视图(View)。
2.4 hadoop技术
Hadoop 是 Apache 软件基金会下的一个开源分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心。Hadoop提供了一个可靠的共享存储与分析系统[2]。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop拥有以下4大优势:
(1) 高容错性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2) 高扩展性:在集群间分配任务数据,可方便扩展数以千计的节点。
(3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,大大加快了任务的处理速度。
Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
在本课题中,由于其中的Mapreduce框架其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景中存在诸多计算效率等问题,Hadoop框架主要用于数据存储。
2.5 Spark
是一种DAG(有向无环图)的,基于内存的快速、通用、可扩展的大数据分析计算引擎。Spark 是分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),简称RDD,提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,不像MapReduce需要落盘数据才能进行迭代式运算,可支持复杂的数据挖掘算法和图形计算算法[4]。Spark的运行模式包括Local、Standalone、Yarn及Mesos几种。其中Local模式仅用于本地开发,Mesos模式国内几乎不用。在公司中因为大数据服务基本搭载Yarn集群调度,因此Spark On Yarn模式会用的比较多。
Spark是一个基于内存的,用于大规模数据处理的统一分析引擎,其运算速度可以达到Mapreduce的10-100倍。具有如下特点:内存计算。Spark优先将数据加载到内存中,数据可以被快速处理,并可启用缓存。shuffle过程优化。和Mapreduce的shuffle过程中间文件频繁落盘不同,Spark对Shuffle机制进行了优化,降低中间文件的数量并保证内存优先。RDD计算模型。Spark具有高效的DAG调度算法,同时将RDD计算结果存储在内存中,避免重复计算。
2 数据分析
4.3.2 布局设计
页面布局设计:头部 + 侧边栏 + 内容栏。头部为一级菜单导航,侧边栏为二级菜单导航,内容栏实现具体数据展示功能。一级菜单导航包括数据采集,视频平台,数据开发三大模块。视频平台二级菜单包含视频工厂,视频中心。二级菜单子菜单分为有视频工厂(实体管理,视频建模)视频中心(视频地图,视频圈选)
4.7 功能模块设计
该章节的功能模块设计,只是大概描述了系统的所有功能模块,将功能按权限来讲解。系统总体结构图如图4-7所示。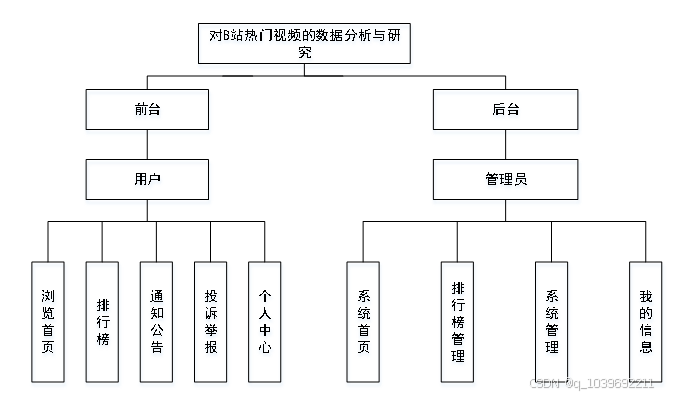
图4.7 系统总体结构图
3 数据可视化
5.1 数仓功能实现
设计分层,ods层存储原始数据,对数据进行标准化后存入std层,根据std层建立一致性维度,一致性事实,通过dwd层打标签至标签日表,由日表再汇总至总表,通过总表生成标签索引表,通过维度表生成实体索引表,随后总表与索引表进行关联,分别形成tag_index, entity_index表,自定义Spark jar包集成Rorabitmap将数据导入至bitmap表,通过sqoop 将数据导出至Postgres数据库,通过es jar包将实体表由Hive导出至elasticsearch
(1)Hive建表 如图5.1所示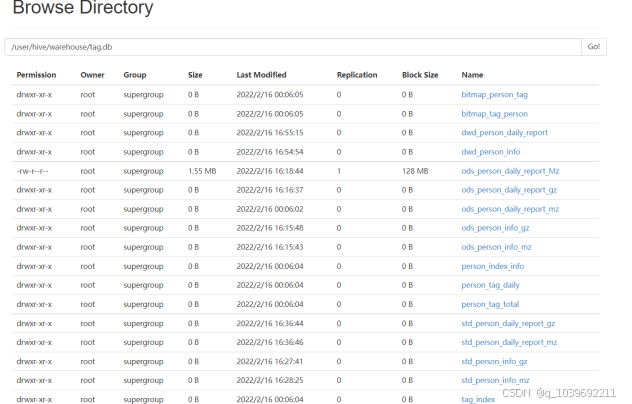
图5.1 Hive表目录图
(2)数据导入, 将数据存入HDFS文件系统(如表5-1所示)
表5-1 数据导入HDFS命令
HDFS dfs -put personInfoMz-2024-05-23.txt.lzo /user/Hive/warehouse/tag.db/ods_person_info_mz
HDFS dfs -put personInfoGz-2024-05-23.txt.lzo /user/Hive/warehouse/tag.db/ods_person_info_gz
HDFS dfs -put reportMz-2024-05-23.txt.lzo /user/Hive/warehouse/tag.db/ods_person_daily_report_mzz
HDFS dfs -put reportGz-2024-05-23.txt.lzo /user/Hive/warehouse/tag.db/ods_person_daily_report_gz
(3)数据标准化, 通过SQL进行数据标准化,如表5-2所示
表5-2 数据标准化命令
insert into tag.std_person_info_gz
select *
from tag.ods_person_info_gz;
insert into tag.std_person_info_mz
select *
from tag.ods_person_info_mz;
insert into tag.std_person_daily_report_gz
select *
from tag.ods_person_daily_report_gz;
insert into tag.std_person_daily_report_mz
select *
from tag.ods_person_daily_report_mz;
(4)一致性维度构建
表5-3 一致性维度构建命令
insert into tag.dwd_person_info
Select *
from tag.std_person_info_gz;
insert into tag.dwd_person_info
select *
from tag.std_person_info_mz;
insert into tag.dwd_person_daily_report
select *
from tag.std_person_daily_report_mz;
insert into tag.dwd_person_daily_report
Select *
from tag.std_person_daily_report_gz;
(5)标签日表: 根据维度表,事实表打标签,如表5-4所示
表5-4 打标签命令
insert overwrite table tag.person_tag_daily partition (dt, tag_name)
select id_number,
case
when ten_symptoms = “0” then “sdzz_0”
when ten_symptoms = “1” then “sdzz_1”
when ten_symptoms = “2” then “sdzz_2”
when ten_symptoms = “3” then “sdzz_3”
when ten_symptoms = “4” then “sdzz_4”
when ten_symptoms = “5” then “sdzz_5”
when ten_symptoms = “6” then “sdzz_6”
when ten_symptoms = “7” then “sdzz_7”
when ten_symptoms = “8” then “sdzz_8”
when ten_symptoms = “9” then “sdzz_9”
when ten_symptoms = “10” then “sdzz_10”
end as tag_code,
1,
“tag.dwd_person_daily_report”,
dt,
“sdzz”
from tag.dwd_person_daily_report;
(6)标签总表,聚合日表数据,如表5-5所示
表5-5 标签总表汇聚命令
insert overwrite table tag.person_tag_total
select id_number,
tag_code,
max(tag_weight),
max(table_name),
min(dt),
max(dt),
count(1)
from tag.person_tag_daily
group by tag_code, id_number;
(7)标签索引表,通过总表+实体表构建标签索引表
表5-6 标签索引表构建命令
set Hive.auto.convert.sortmerge.join=true;
set Hive.optimize.bucketmapjoin = true;
set Hive.optimize.bucketmapjoin.sortedmerge = true;
set tez.grouping.max-size=134217728;
set tez.grouping.min-size=134217728;
set Hive.tez.container.size=3072;
insert overwrite table tag.tag_index
select tag_code, index
from tag.person_tag_total t1
inner join tag.person_index_info t2 on t1.id_number = t2.id_number;
(8)自定义Spark jar包集成RoraingBitmap, 生成bitmap表 如图5-2所示。
优化1:对象展开(不要shuffle小对象)
我们知道一个对象的内存布局为对象头header(markword + class pointer) 8+4字节,实例数据instance data (存储实际数据),对齐padding (内存读取数据时每次读8字节效率最高),即使padding为0,也会凭空多出12节
优化2:使用HashMap + 累加器
原本的操作是group by tag_code 把所有实体id聚合进RoraingBitmap, 此时在map阶段进行group by 操作而没有聚合操作时,将产生大量shuffle。如果在map阶段通过hashmap对每个tag_code进行预聚合,将大大减少shuffle所需的数据量。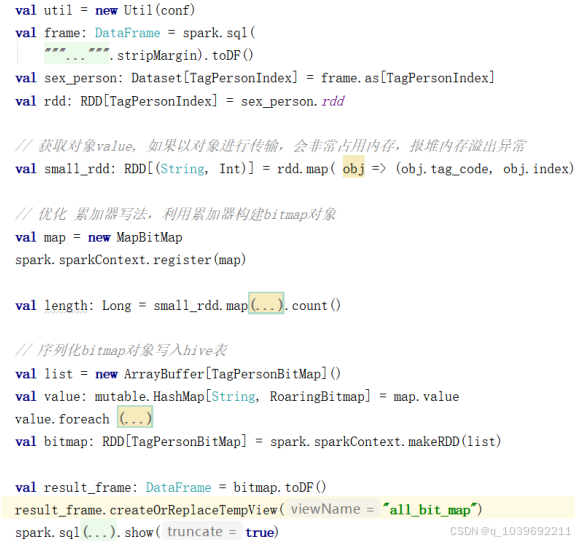
图5-2 RoraingBitmap插入优化图
5.2 前台用户功能的实现
当游客打开系统的网址后,首先看到的就是首页界面。在这里,游客能够看到对B站热门视频的数据分析与研究的导航条显示首页、排行榜、通知公告、投诉举报、个人中心等,系统首页界面如图5.3所示: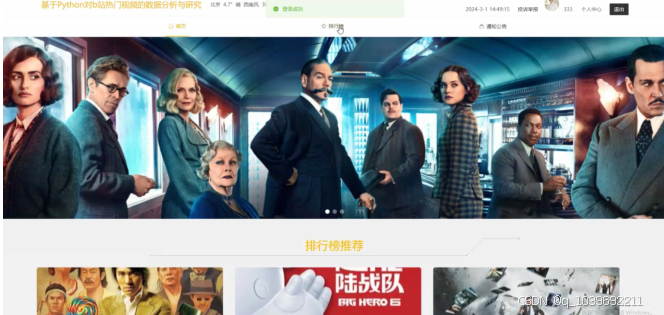
图5.3 系统首页界面
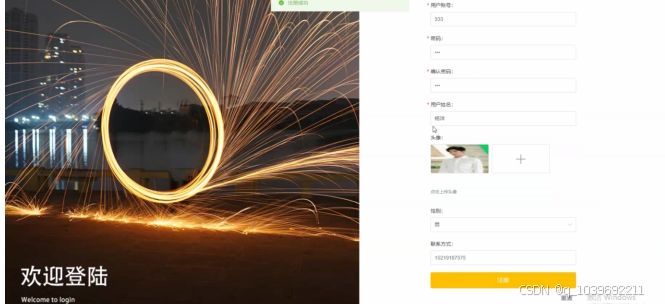
当用户进入系统进行相关操作前必须进行注册、登录,用户注册、用户登录界面如图5.4所示:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)