【python】Python飞卢小说网K-Means聚类数据分析可视化(源码+论文)【独一无二】
本文基于飞卢小说网500部天榜作品的数据分析,探究网络文学受欢迎的关键因素。数据集包含20个字段,涵盖分类、字数、打赏等维度,采用Python技术栈(Pandas、Matplotlib、Sklearn)进行数据清洗、特征分析和建模。研究通过随机森林分类和K-Means聚类等方法,揭示作品分类、更新字数与用户互动指标之间的关联性,为创作者提供内容优化建议,并为平台推荐算法改进提供数据支持。分析显示,
1 数据情况
1.数据来源和规模(数据行数和列数)
数据来源
本数据集来源于飞卢小说网,汇集了该平台历史上所有天榜作品的数据(即排行榜前五十名)。飞卢小说网以其丰富的脑洞创意和多样化题材闻名,尤其是在男频市场中,与番茄小说、起点小说等平台齐名。本数据集不仅包含了小说的基本信息(如书号、书名、作者),还详细记录了小说的分类、字数、打赏金额、评价等核心数据指标。这些信息对于分析天榜作品的创作规律、用户喜好以及作品的受欢迎程度具有重要意义。数据反映了飞卢小说网作为创意小说发源地的特点,也为网络文学的发展趋势研究提供了宝贵素材。
数据规模
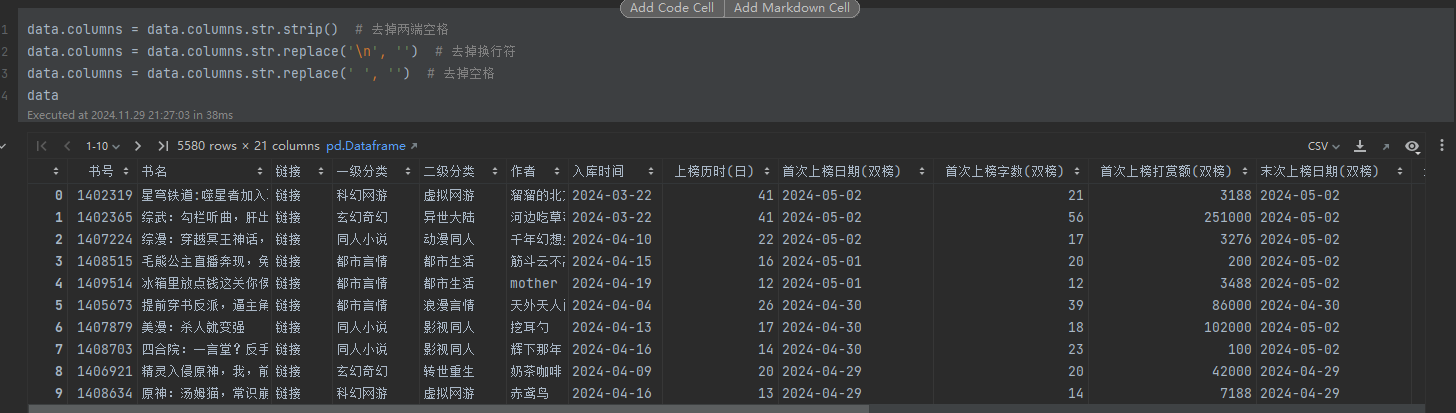
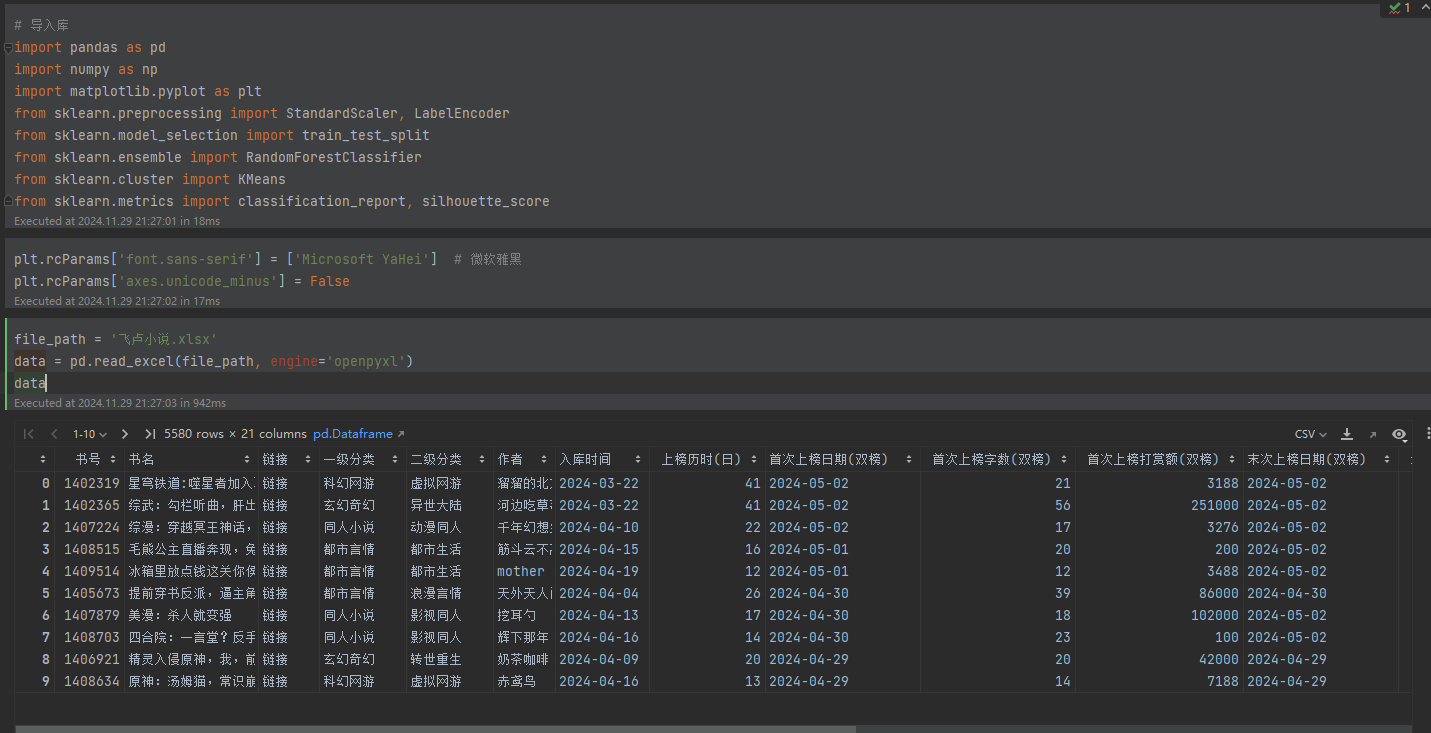
数据集共有 500行(即500本小说的记录)和 20列,每一行代表一部天榜作品。字段涵盖了小说的多个维度,包括分类信息(如“一级分类”、“二级分类”)、创作数据(如字数、首次上榜时间)、市场反馈(如打赏金额、排名)等。通过这些全面而详实的字段,研究者可以从多个角度分析飞卢小说的成功要素和用户行为。这种小规模、高质量的数据适合初步探索网络文学的热点作品特性,并为更大规模的研究提供方向指引。

2.数据各字段说明(使用表格)
| 字段名称 | 字段说明 |
|---|---|
| 书号 | 小说的唯一标识符,类似于编号或序列号。 |
| 书名 | 小说的标题,反映作品的内容主题。 |
| 链接 | 小说对应的网络链接,用于直接跳转到作品页面。 |
| 一级分类 | 小说的主要分类(如“都市言情”、“玄幻奇幻”)。 |
| 二级分类 | 小说的细分分类(如“都市生活”、“虚拟网游”)。 |
| 作者 | 小说的创作者名称。 |
| 入库时间 | 小说被收录到数据库的日期。 |
| 上榜历时(日) | 小说在天榜上的持续时间(单位:天)。 |
| 首次上榜日期(双榜) | 小说首次进入天榜的日期。 |
| 首次上榜字数(双榜) | 小说首次进入天榜时的累计字数。 |
| 首次上榜打赏额(双榜) | 小说首次上榜时的总打赏金额(单位:元)。 |
| 末次上榜日期(双榜) | 小说最后一次出现在天榜的日期。 |
| 最好名次(双榜) | 小说在天榜上的历史最佳排名。 |
| 最差名次(双榜) | 小说在天榜上的历史最差排名。 |
| 总次数(双榜) | 小说进入天榜的总次数。 |
| 首日v收 | 小说发布首日的VIP用户订阅量(若统计)。 |
| 首日鲜花 | 小说发布首日收到的鲜花数量(若统计)。 |
| 首日打赏 | 小说发布首日收到的打赏金额(若统计)。 |
| 首日评价 | 小说发布首日收到的用户评价总数(若统计)。 |
| 首日书评数 | 小说发布首日收到的书评数量(若统计)。 |
| 首日字数(千) | 小说发布首日上传的字数(单位:千字)。 |
3.数据总览(截图)
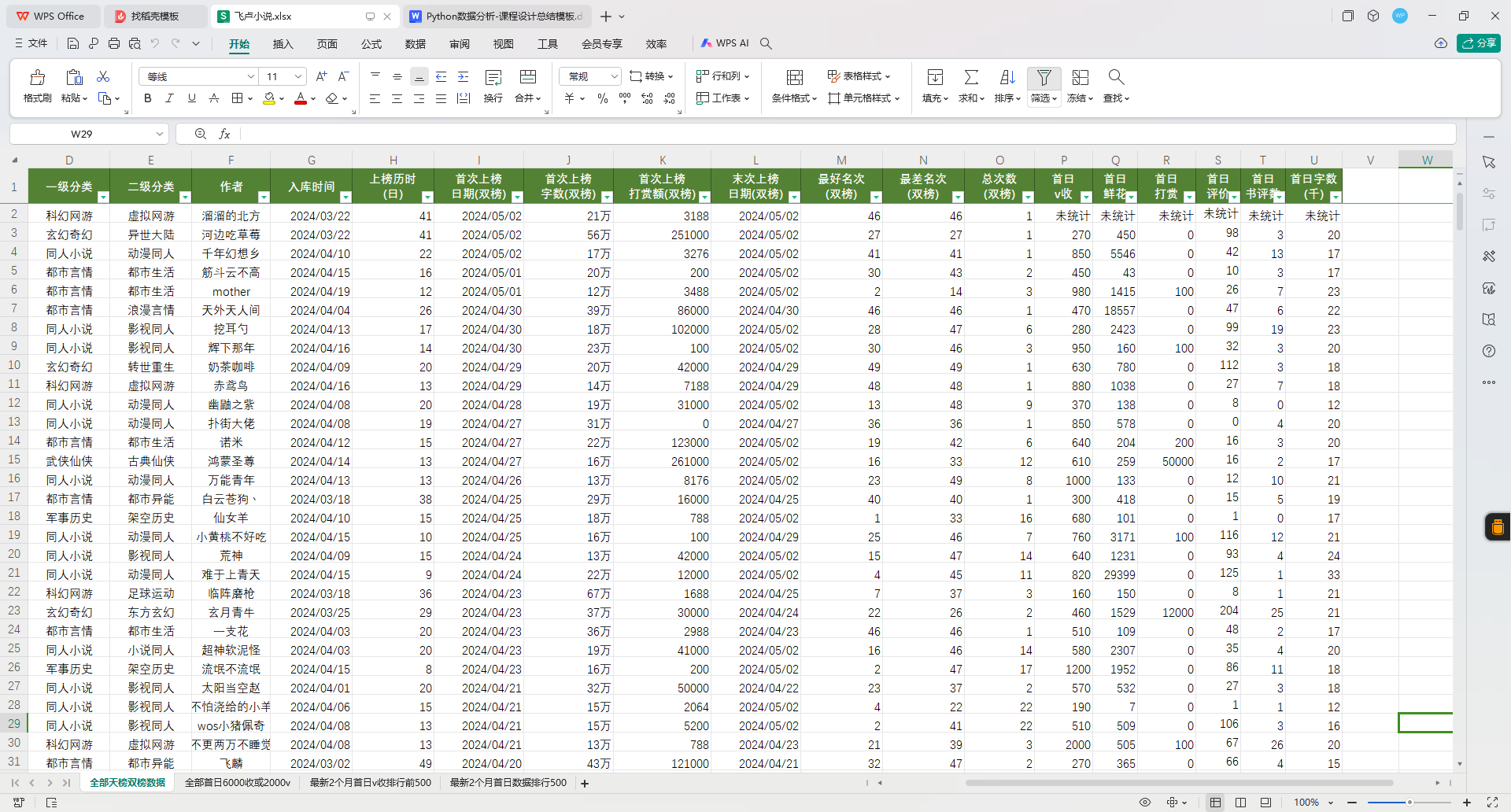
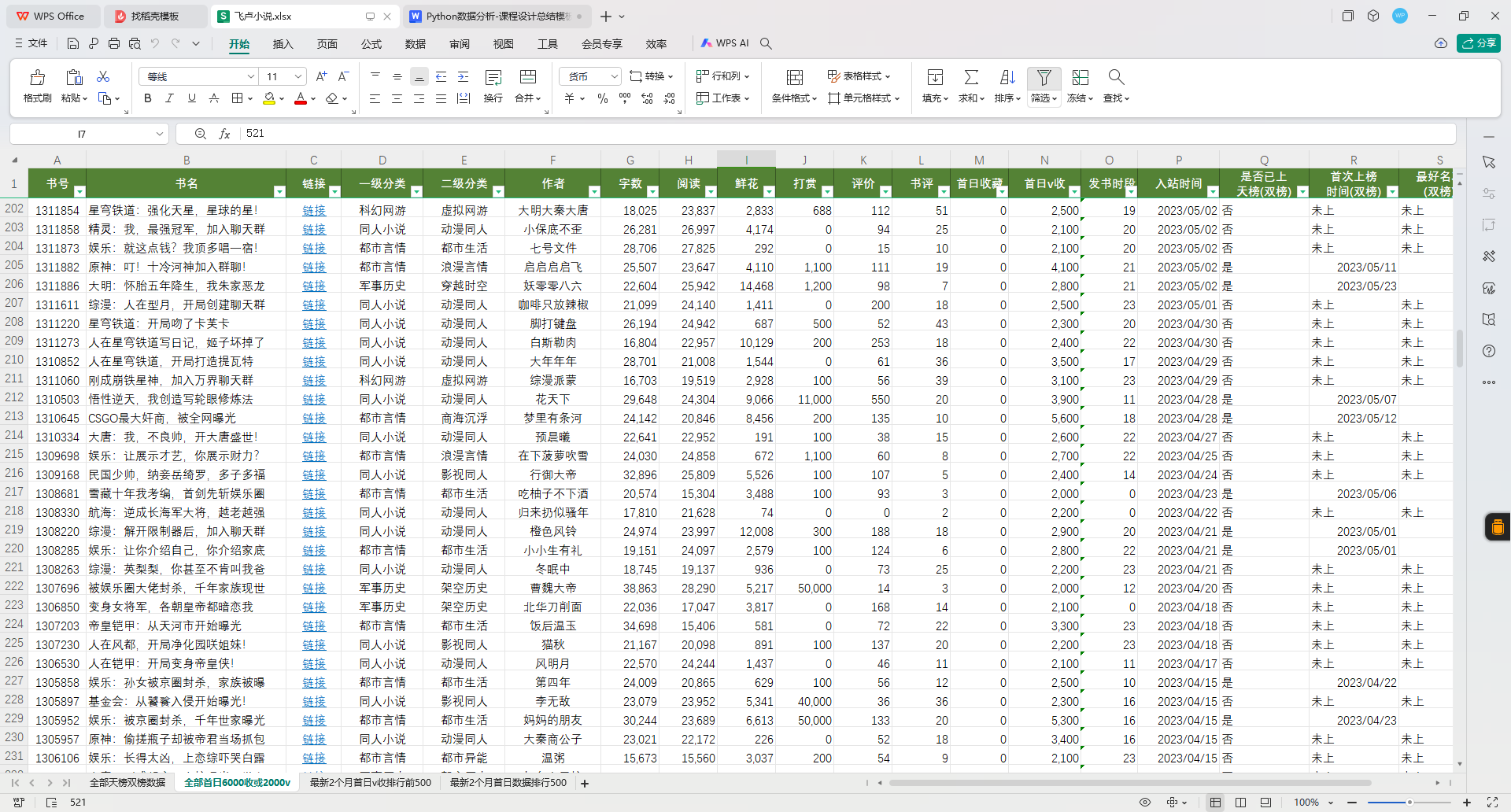
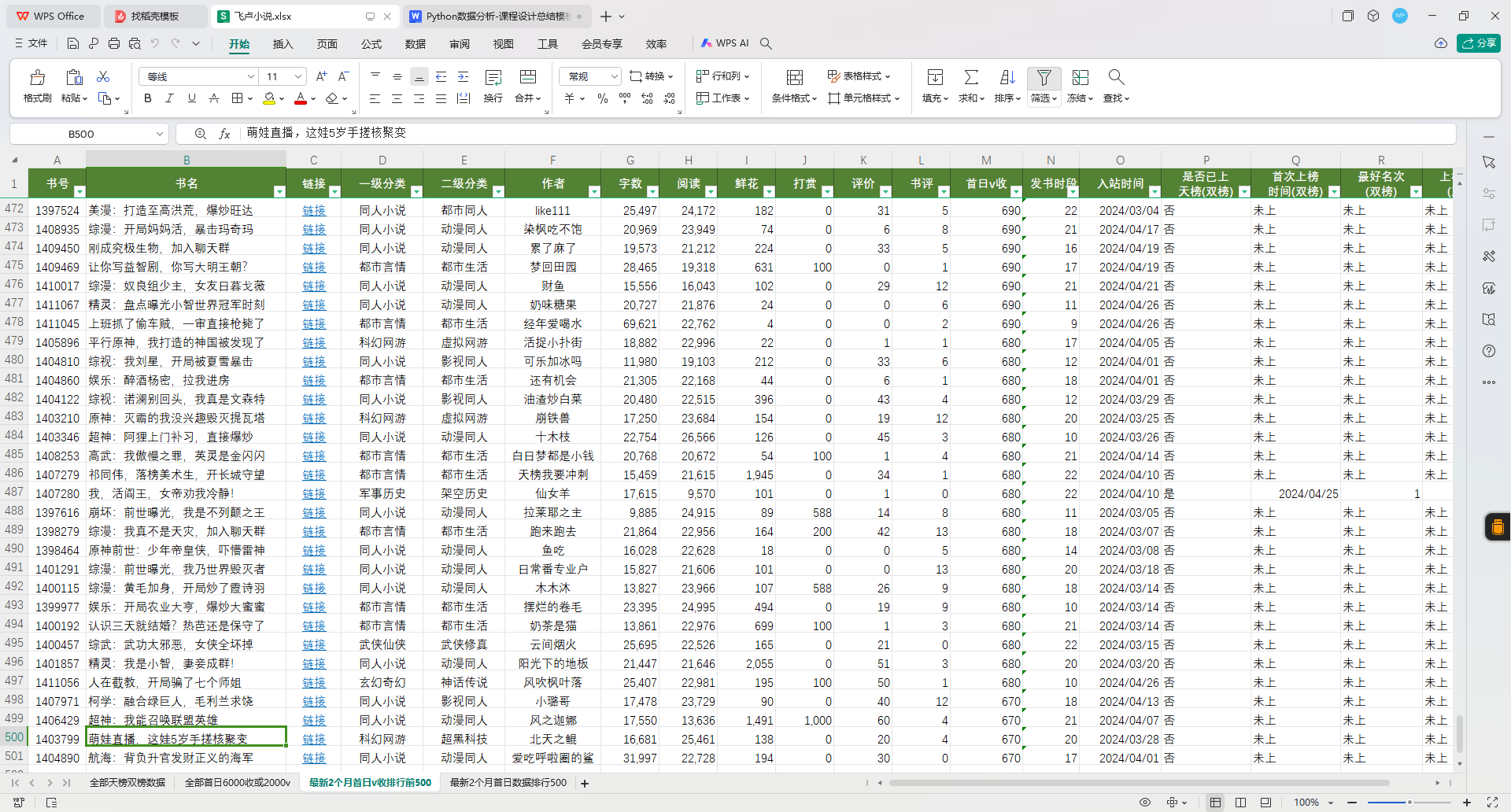

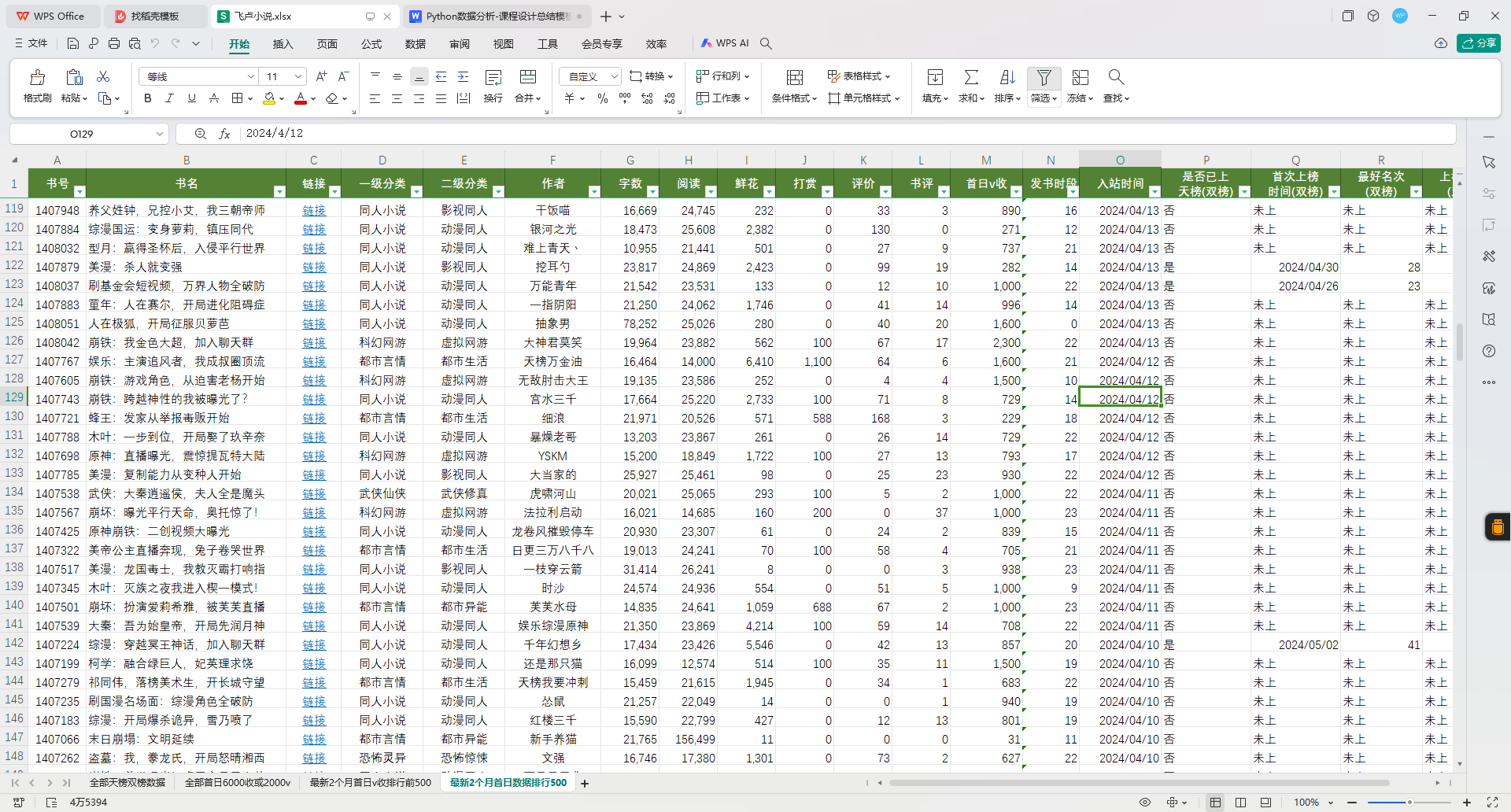
2 分析主题(解决什么问题)
3 分析主题与问题解决
本次数据分析的主题聚焦于探索飞卢小说网天榜作品的成功因素,旨在回答以下核心问题:哪些特征最能决定一本小说的受欢迎程度。飞卢天榜作品在分类、字数、打赏、评价等维度上是否呈现出规律性趋势。通过对数据的深入分析,我们能够揭示用户偏好的变化方向,帮助创作者更精准地把握市场需求,同时为平台优化内容推荐算法提供数据支持。例如,通过分析小说的“字数”、“打赏金额”与“排名”之间的关系,可以判断长篇连载与短篇作品在不同分类中的表现差异;通过研究“首次上榜时间”与“总次数”的分布,可以发现不同时间段的用户行为特征。
分析目标与实际意义
本次分析的实际意义不仅在于解释飞卢天榜作品的现状,还旨在挖掘潜在的创作与运营策略。通过特征选择与数据建模,可以帮助创作者优化作品内容,比如明确“都市生活”类小说是否更偏好高频更新,或是“玄幻奇幻”类作品是否需要更具吸引力的设定。此外,对于平台运营者,分析结果可以用来提升用户体验,例如设计更具针对性的推送机制,将最符合用户兴趣的作品呈现给目标读者群。更广泛地,这些分析还可以为网络文学行业的发展趋势研究提供基础性参考,帮助理解市场动态、作品生命周期及用户行为偏好的整体格局。
4 技术路线
1.平台和开发工具
Jupyter
Python3.9
Matplotlib
Numpy
Sklearn
2.使用的包、模块和函数
使用的主要包和模块
- pandas
用于数据的读取、清洗、处理和分析。- 模块功能:提供了数据框(DataFrame)结构,支持数据筛选、清洗、统计等操作。
- 主要函数:
- read_excel():读取 Excel 文件。
- info():查看数据的基本信息。
- describe():生成数据的统计描述。
- isnull():检查缺失值。
- fillna():填充缺失值。
- drop_duplicates():去除重复值。
- corr():计算数据的相关性。
- numpy
用于数值计算和数组操作。- 模块功能:提供高效的数组操作和数学函数支持。
- 主要函数:
- where():用于对数据条件化处理(如异常值替换)。
- mean():计算均值。
- quantile():计算分位数。
- matplotlib
用于数据可视化。- 模块功能:生成静态、交互式和出版质量的图形。
- 主要函数:
- figure():创建画布。
- scatter():生成散点图。
- hist():绘制直方图。
- show():显示图形。
- sklearn
用于机器学习模型的构建和评估。- 模块功能:提供数据预处理、特征选择、模型训练与评估的工具。
- 主要子模块和函数:
- 预处理:
- LabelEncoder:将分类变量编码为整数。
- StandardScaler:对数值特征进行标准化。
- 模型选择:
- train_test_split:划分训练集和测试集。
- 模型构建:
- RandomForestClassifier:随机森林分类模型。
- KMeans:K-Means聚类模型。
- 评价指标:
- classification_report:生成分类模型的评估报告。
- silhouette_score:计算聚类模型的轮廓系数。
- 预处理:
- openpyxl
用于读取 Excel 文件的引擎。- 模块功能:支持 .xlsx 格式的文件读取和写入。
- 主要用途:通过 pandas 的 read_excel() 函数加载数据时指定引擎。

关键函数的作用描述
- 数据加载与清洗:
- pandas.read_excel():加载 Excel 格式的数据文件。
- pandas.drop_duplicates():去除重复行,确保数据唯一性。
- pandas.fillna():填充缺失值,避免计算出错。
- 特征工程:
- LabelEncoder.fit_transform():将分类变量转换为数值,方便模型使用。
- StandardScaler.fit_transform():对数值列进行标准化处理,消除量纲差异。
- 建模与训练:
- RandomForestClassifier.fit():训练随机森林模型。
- KMeans.fit_predict():对数据进行聚类并返回类别标签。
- 数据可视化:
- matplotlib.pyplot.hist():绘制直方图,展示数据分布。
- matplotlib.pyplot.scatter():绘制二维散点图,展示聚类结果。
3.处理流程(使用流程图)
5 实验过程
1.程序源代码(需要有注释和说明)
1. 导入必要库
代码导入了以下库:
- pandas:用于数据加载和处理,例如读取 Excel 文件、清洗数据和统计分析。
- numpy:用于数值计算和数组操作,例如处理异常值和条件赋值。
- matplotlib.pyplot:用于数据可视化,例如绘制直方图和散点图。
- sklearn.preprocessing:提供了数据预处理工具,如标准化(StandardScaler)和标签编码(LabelEncoder)。
- sklearn.model_selection:用于划分数据集,提供训练集和测试集。
- sklearn.ensemble:提供随机森林分类模型(RandomForestClassifier)。
- sklearn.cluster:提供 K-Means 聚类算法。
- sklearn.metrics:用于模型评估,提供分类报告和聚类轮廓系数。
此外,通过设置 plt.rcParams 确保支持中文显示,解决绘图中文乱码问题。
2. 数据读取与清洗
- 数据加载:
使用 pandas.read_excel() 读取 飞卢小说.xlsx 文件,并通过 openpyxl 引擎支持格式兼容。 - 列名清理:
通过 str.strip() 去掉列名两端的空格,str.replace() 去除多余空格和换行符,确保列名一致性。 - 基本信息与统计:
使用 info() 和 describe() 查看数据的结构和基本统计信息(如均值、标准差)。
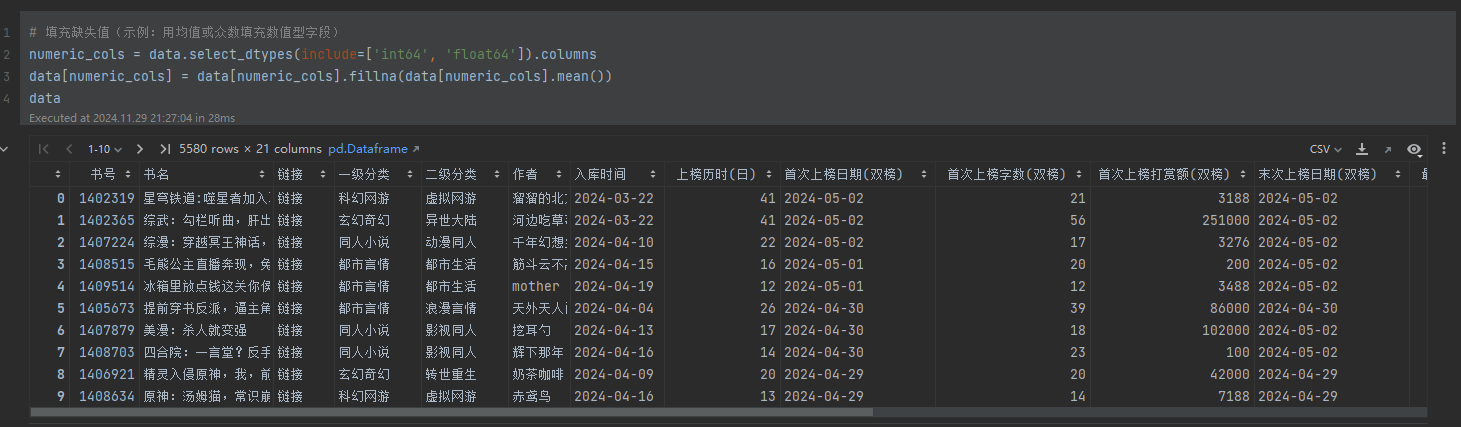
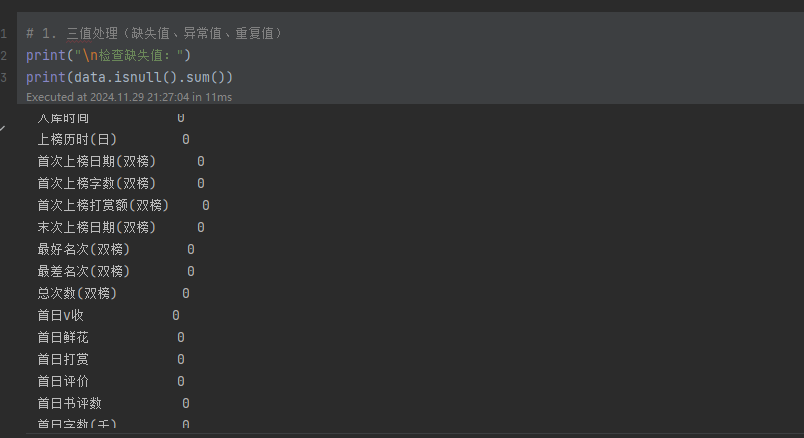
处理三值(缺失值、异常值、重复值)
- 缺失值:
- 检查缺失值分布。
- 数值列用均值填充(fillna()),确保后续分析不受缺失值干扰。
- 重复值:
- 通过 drop_duplicates() 删除重复记录,保持数据唯一性。

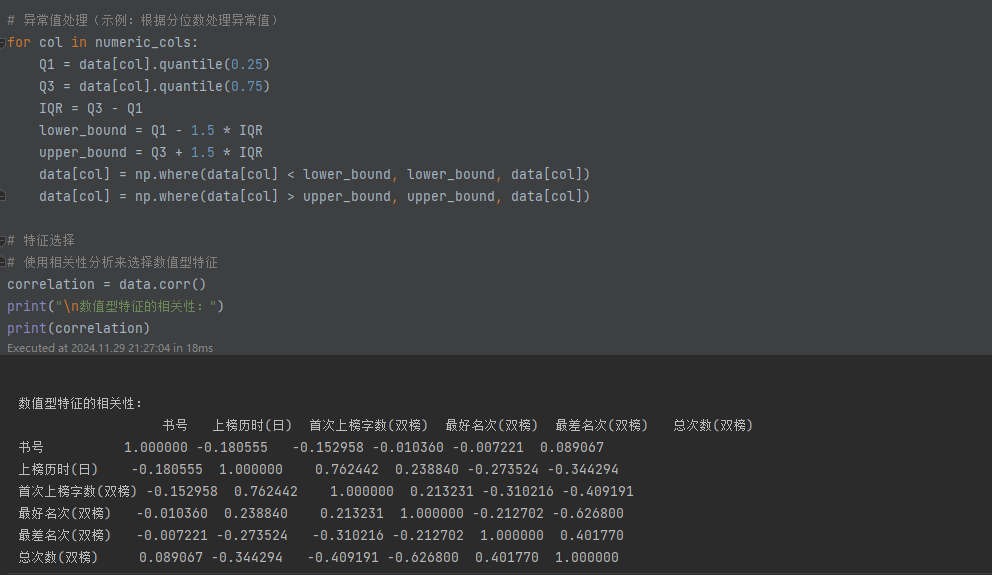
- 异常值:
- 使用四分位间距法(IQR)定义异常值范围,并对超出范围的值进行边界限制处理(np.where())。
3. 特征工程
相关性分析与特征选择:
- 计算列间相关性(corr()),选择与目标变量(如“总次数(双榜)”)相关性最高的前 5 个特征,用于模型输入。
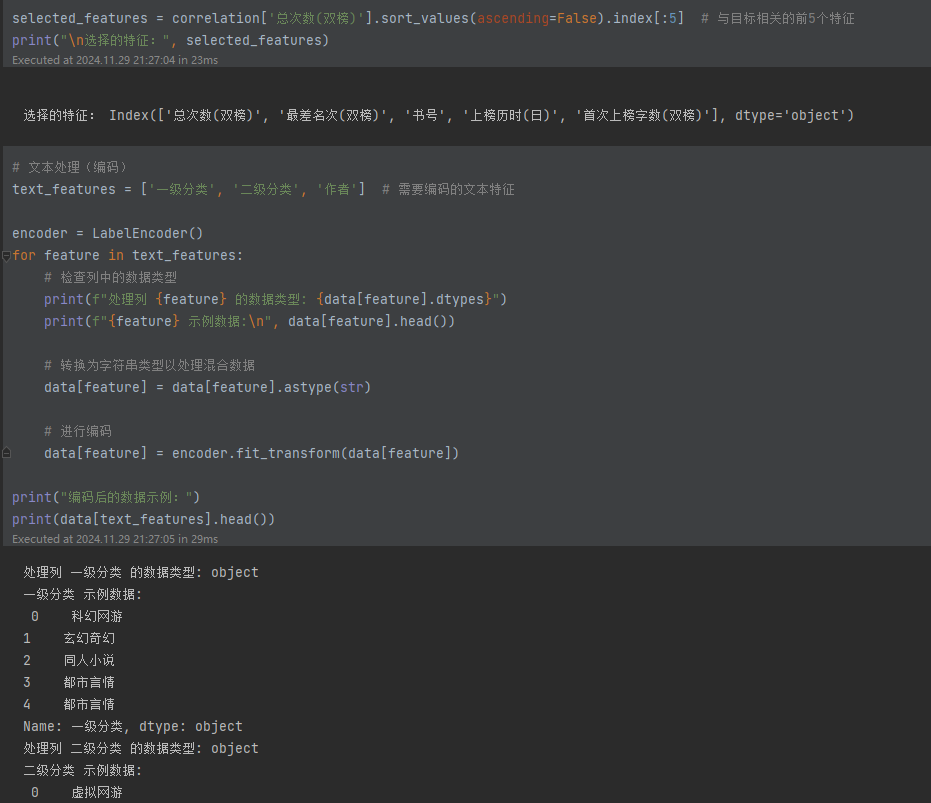
文本特征编码:
- 通过 LabelEncoder 对分类文本数据(如“一级分类”、“作者”)进行数字化处理。
- 预处理步骤包括将所有值转换为字符串类型(astype(str)),解决混合类型引发的错误。

数值特征标准化:
- 使用 StandardScaler 对数值列进行标准化,将数据转换为均值为 0、标准差为 1 的分布,避免因量纲差异影响模型训练。
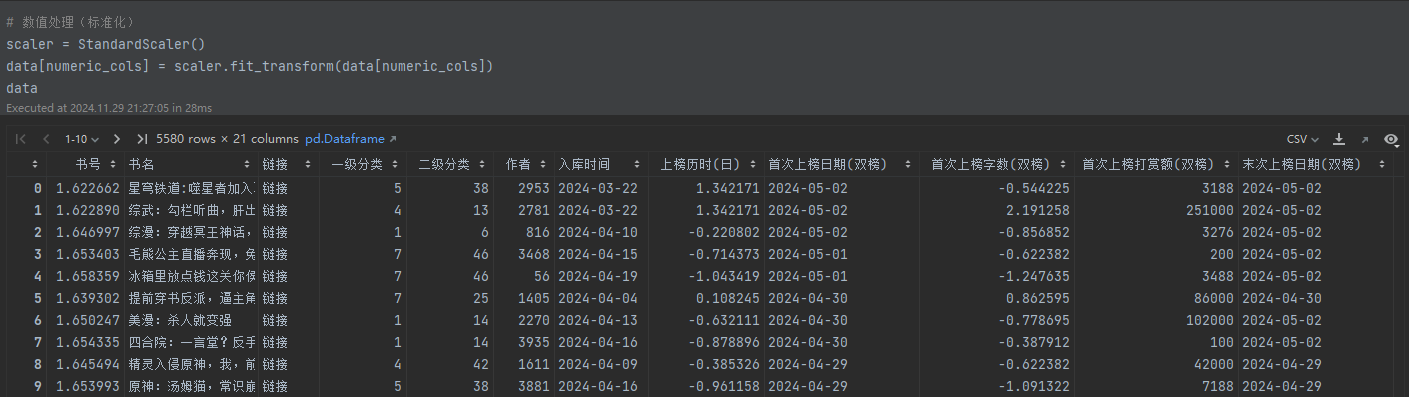
4. 模型训练与预测
分类模型(随机森林):
- 输入与目标:
- 特征(X):相关性分析选择的数值型特征。
- 目标变量(y):“最好名次(双榜)”,简化为二分类问题(低于平均值为 1,否则为 0)。
- 数据分割:
- 使用 train_test_split() 按 7:3 比例划分训练集和测试集。
- 训练与评估:
- 训练随机森林模型(RandomForestClassifier)。
- 使用 classification_report() 输出测试集上的模型性能报告,包括精确率、召回率和 F1 分数。
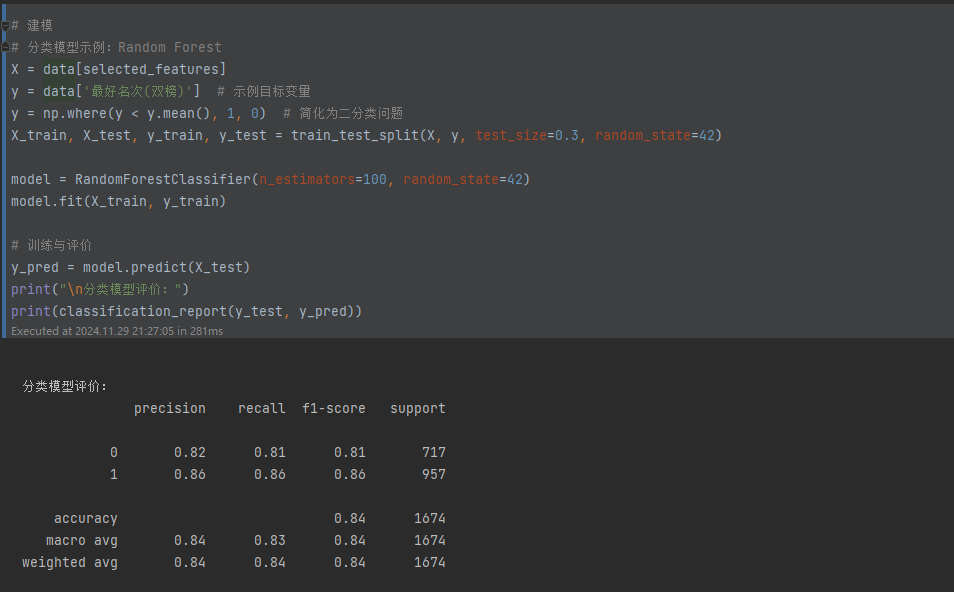
聚类模型(K-Means):
- 聚类过程:
- 使用 KMeans 将样本分为 3 类(假设分布特征存在三类聚类)。
- 通过轮廓系数(silhouette_score)评估聚类质量。
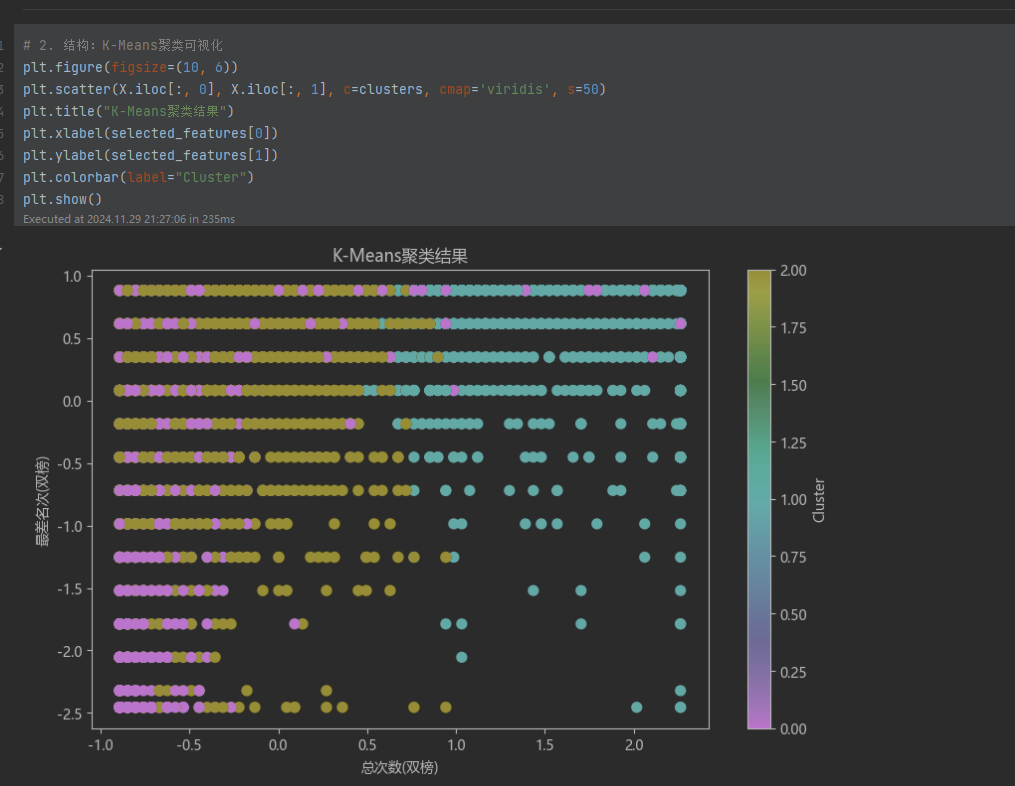
- 聚类结果可视化:
- 使用散点图展示聚类分布。

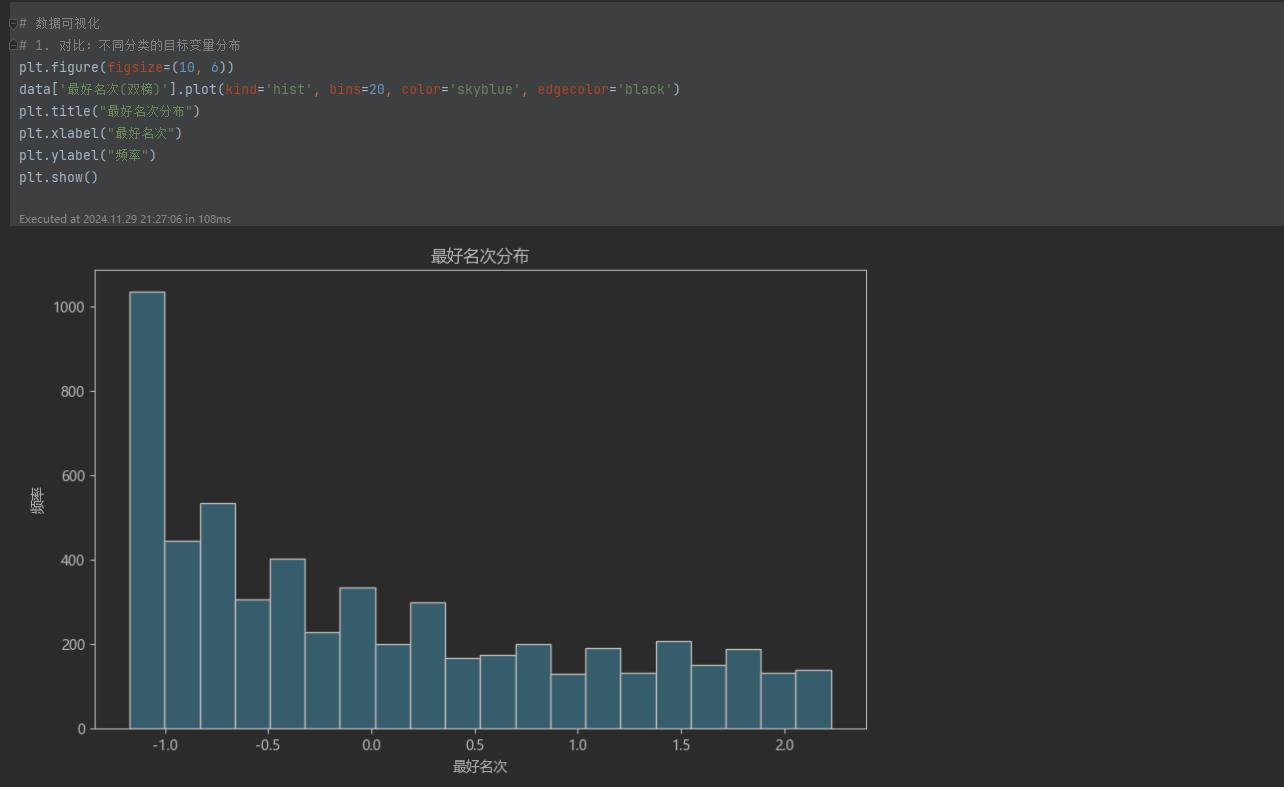
5. 数据可视化
- 目标变量分布:
使用直方图显示“最好名次(双榜)”的分布,分析其集中趋势。
- 聚类结果展示:
使用散点图展示两个特征在 3 类聚类中的分布结构。
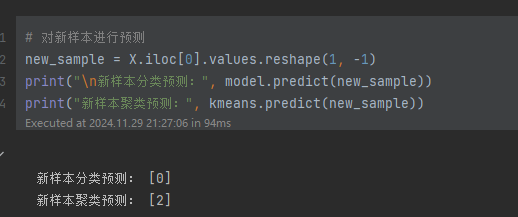
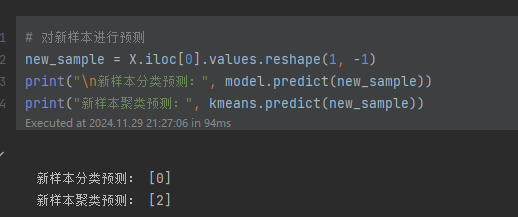
6. 新样本预测
对一个示例新样本进行:
- 分类预测:通过训练的随机森林模型预测其类别。
- 聚类预测:通过 K-Means 模型预测其聚类类别。
6 运行和调试过程的截屏(3张以上)
-
分析结论(带有输入和输出结果的截屏)
-
数据预处理效果良好:通过去除重复值、处理缺失值和异常值,数据的完整性和一致性得到了提高。
-
特征选择与编码:通过相关性分析选择了与目标变量“总次数(双榜)”相关性最大的五个特征,并对分类变量进行了有效编码,增强了数据的可用性。
- 分类模型性能优异:使用随机森林分类器对“最好名次(双榜)”进行了二分类,取得了良好的精度(0.84),说明所选特征较好地描述了目标变量。同时,模型具有较高的召回率和F1-Score,显示其对各类的分类能力平衡。
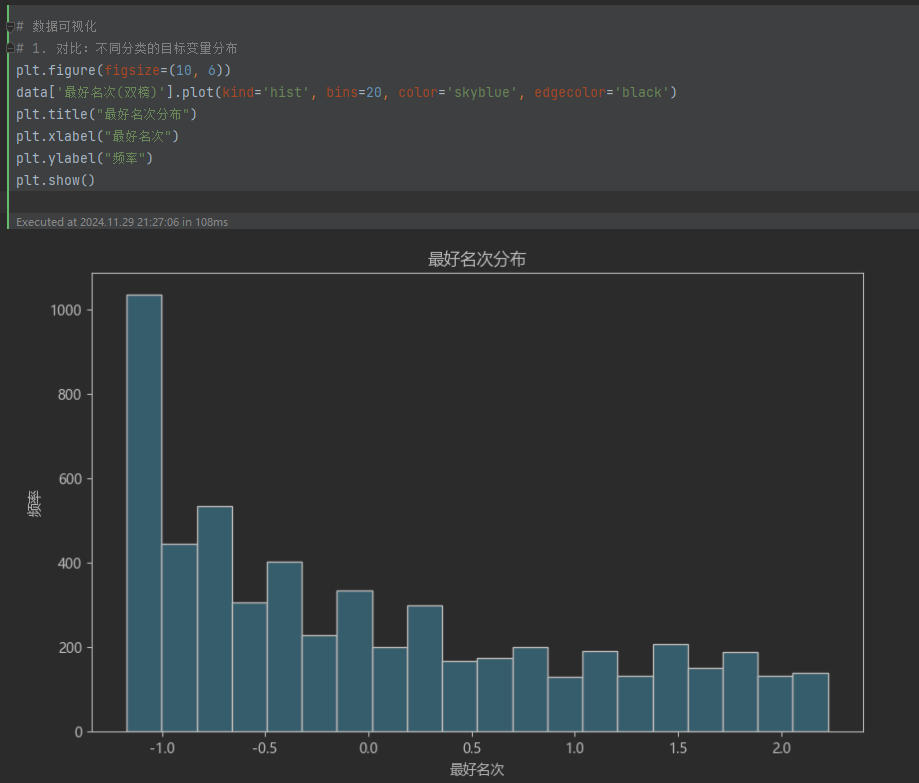
-
聚类分析的洞察:K-Means聚类的轮廓系数为0.255,表明聚类效果中等。虽然未能显著分离不同类型,但仍提供了潜在的群组分类信息。
-
数据可视化支持结论:直方图和聚类的散点图形象地展示了数据分布特征和聚类效果。这些可视化结果与模型输出一致,支持上述分析结论。
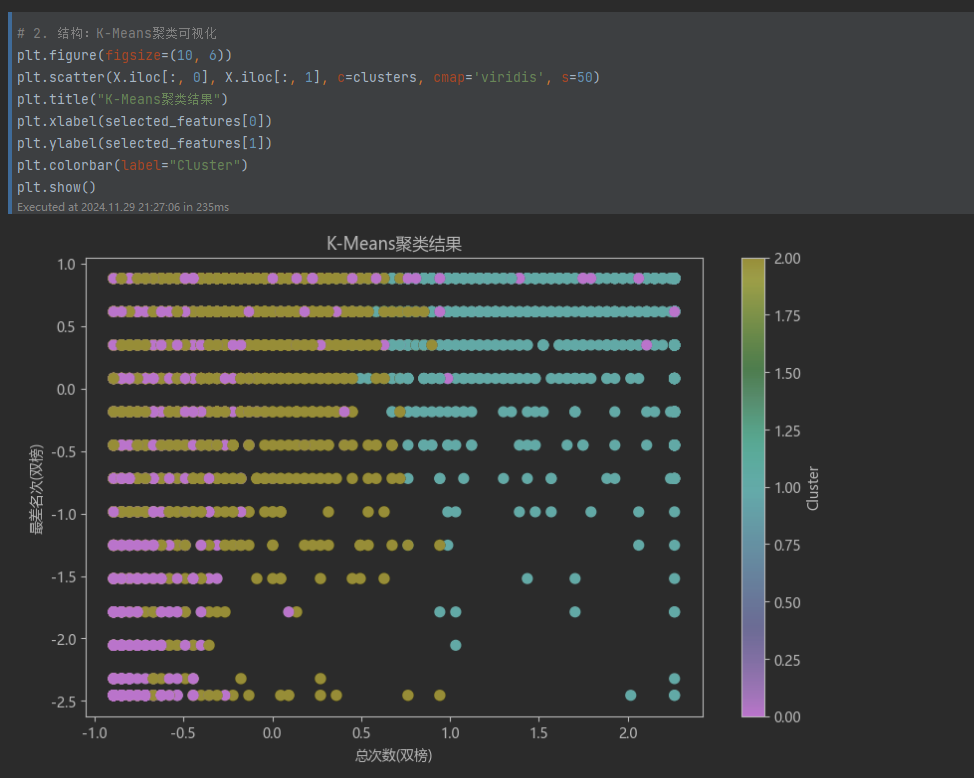
综合来看,本次数据分析有效地挖掘了飞卢小说网数据的潜在规律,并对分类和聚类问题提供了具有参考价值的见解。在实际应用中,可以进一步结合业务需求,调优模型参数以提升分析准确性。

- 收获总结
通过对飞卢小说网数据的分析与处理,我深刻体会到数据分析的系统性和创造性。这次实践涵盖了从数据清洗到特征工程、建模与可视化的完整流程,不仅要求技术上的准确性,更需要对数据特点的深度理解。在清洗数据时,我认识到细节的重要性,如去除空格、处理缺失值和异常值等,看似简单却直接影响分析结果的可靠性。而在特征选择中,通过相关性分析挑选关键变量,让模型更加高效,也增强了我对特征工程在模型表现中作用的理解。
模型训练环节让我进一步巩固了对分类和聚类算法的认识。随机森林模型在分类任务中的稳定表现以及 K-Means 聚类的结果展示出数据的潜在结构,这为探索用户偏好提供了方向。同时,通过可视化手段,不仅有效展示了分析成果,也提升了结果的直观性和说服力。
总体而言,这次分析让我加深了对数据驱动决策的认识,也意识到扎实的技术和对业务背景的理解同样重要。在未来的工作中,我希望能进一步优化分析方法,提升模型表现,并探索更多实际应用场景。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)