【解决】qlalchemy.exc.DataError: (pymysql.err.DataError) (1366, “Incorrect string value
qlalchemy.exc.DataError: (pymysql.err.DataError) 1366, 的解决办法
·
问题:qlalchemy.exc.DataError: (pymysql.err.DataError) (1366, “Incorrect string value: ‘\xE9\x9D\x9E\xE5\x85\xB3…’ for column ‘Columns’ at row 3”)
原因:Columns列中存在中文,还有就是to_sql默认创建的数据表的编码格式是:ENGINE=InnoDB DEFAULT CHARSET=latin1 |
解决办法:在你要存储的数据库中运行:ALTER DATABASE db CHARACTER SET utf8 COLLATE utf8_general_ci;
就应该可以解决了;
如果不行,可以运行下方命令重试:SET character_set_client = utf8mb4;SET character_set_connection = utf8mb4;SET character_set_database = utf8mb4;
我的场景是,在内服服务器中存储数据库到外部服务器的mysql中,利用的是pandas中df.to_sql命令;详细如下:
import cx_Oracle
import pymysql
from sqlalchemy import create_engine
pymysql.install_as_MySQLdb()
df = pd.read_excel(.....)
# user 是数据库的用户名,password 是数据库密码,ip是服务器的ip地址,db是数据库名称
engine = create_engine('mysql+mysqldb://user:password@ip:3306/db?charset=utf8')
df.to_sql('db',con=engine,chunksize=10000,if_exists='replace')
运行发生上述的错误;利用ChatGPT排查原因: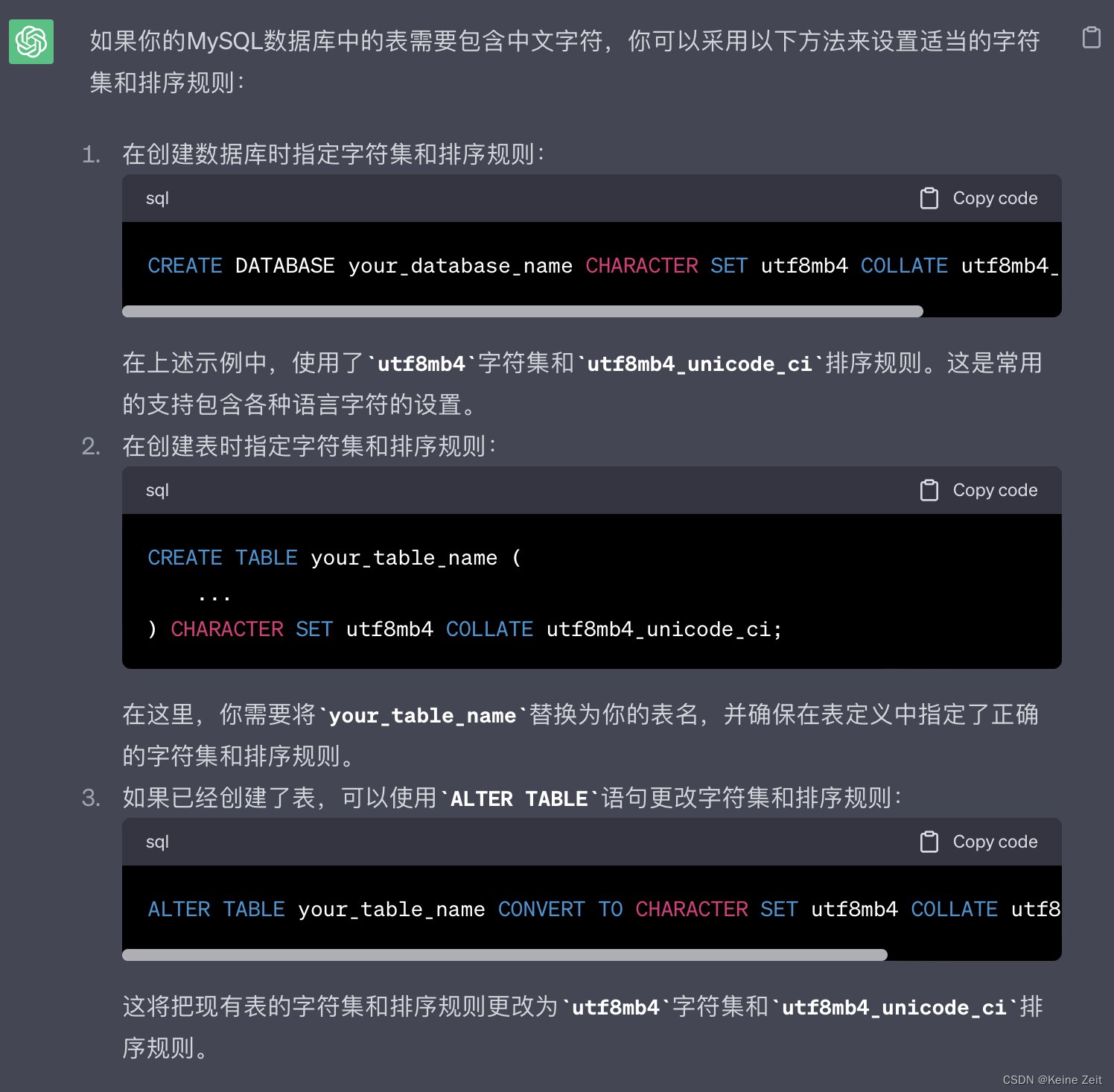
小知识:
1、如何利用python来检测df中某一列的编码格式:
# pip install chardet
import chardet
import pandas as pd
#假设你的DataFrame名为df,包含中文字符的列名为'column_name'
df['column_name'] = df['column_name'].astype(str) # 将列转换为字符串类型
# 遍历DataFrame中的每个字符串
for index, row in df.iterrows():
data = row['column_name']
result = chardet.detect(data.encode())
encoding = result['encoding']
confidence = result['confidence']
print(f"String: {data} - Encoding: {encoding} - Confidence: {confidence}")
import pandas as pd
# 假设你的数据DataFrame名为df,列名为column_name
df[column_name] = df[column_name].apply(lambda x: x.encode('utf-8').decode('utf-8') if isinstance(x, str) else x)
# 现在,数据中的字符串应该都是UTF-8编码了

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)