26届大数据毕业设计选题推荐| 基于协同过滤的动漫推荐系统设计与实现 可视化数据分析 在线动漫推荐系统
本文介绍了一个基于协同过滤算法的动漫推荐系统,采用Python+Django框架开发,集成爬虫技术、大数据处理和可视化功能。系统通过爬虫自动采集动漫数据,使用Hadoop+Spark处理海量用户行为,实现个性化推荐。用户端支持动漫浏览、社区交流和数据可视化展示;管理员端提供内容管理、用户管理和运营监控。研究重点包括需求分析、爬虫系统构建、协同过滤算法优化及Web应用开发,旨在解决动漫内容过载问题,
🔥作者:it毕设实战小研🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java实战项目
Python实战项目
微信小程序实战项目
大数据实战项目
PHP实战项目
💕💕文末获取源码
文章目录
本次文章主要是介绍基于协同过滤+数据可视化的动漫推荐系统的功能,
1、动漫推荐系统-前言介绍
1.1背景
网络视频内容的爆发式增长为用户带来了前所未有的选择困扰,动漫产业作为数字娱乐的重要组成部分正面临着信息过载的严峻挑战。根据艾瑞咨询发布的《2023年中国动漫产业研究报告》显示,截至2023年底,国内动漫作品总数量已突破15000部,年增长率达到32.7%,用户规模超过4.6亿人次;同时腾讯视频、爱奇艺、哔哩哔哩等主流平台的动漫内容库容量均超过8000部作品,海外引进作品占比高达60%以上。庞大的内容体量使得普通用户在寻找符合个人喜好的动漫作品时往往需要耗费大量时间进行筛选,传统的分类浏览和关键词搜索方式已无法满足用户个性化观影需求。中国音像与数字出版协会的调研数据表明,超过78%的动漫爱好者表示在内容选择上存在明显困难,平均每位用户需要花费25分钟以上才能找到满意的观看内容,这种低效的内容发现机制严重影响了用户体验和平台粘性。面对日益多元化的用户群体和不断丰富的内容生态,如何通过技术手段实现精准的内容推荐成为当前动漫平台急需解决的核心问题。
1.2课题功能、技术
该动漫推荐系统采用Python+Django框架构建Web应用程序,通过爬虫技术自动获取各大动漫平台的作品信息和用户评价数据,建立涵盖动漫基本信息、用户行为记录、评分数据的综合数据库;系统运用Hadoop分布式存储架构和Spark计算引擎处理海量用户行为数据,实现协同过滤推荐算法的高效运算和实时响应。用户端功能模块包括个人账户管理、动漫作品浏览、社区交流论坛、个性化推荐列表等核心服务,管理员端则提供用户信息管理、内容审核发布、系统运维监控等后台管理功能;特别值得关注的是,系统集成了动态数据可视化大屏,能够实时展示平台运营数据、用户偏好分析、热门作品趋势等多维度统计信息。协同过滤算法通过分析用户历史观看记录、评分行为、收藏习惯等数据特征,计算用户间的相似度矩阵,为每位用户生成个性化的动漫推荐清单。
1.3 意义
从理论研究角度来看,该课题在推荐系统算法优化和大数据处理技术融合方面具有重要的学术价值。协同过滤算法在动漫推荐场景中的应用研究为改进传统推荐模型提供了新的思路,特别是在处理稀疏数据和冷启动问题方面的技术创新对推荐系统理论发展具有积极意义;同时,Hadoop+Spark大数据处理架构与Django Web框架的整合应用为构建高并发、高可用的推荐系统提供了可行的技术方案。该研究通过实际项目验证了分布式计算在推荐算法中的有效性,为相关领域的学术研究提供了宝贵的实践经验和数据支撑。从实际应用价值来看,该系统的建设能够显著提升动漫平台的用户体验和商业价值。精准的个性化推荐机制可以有效缩短用户内容发现时间,提高用户满意度和平台活跃度,据相关研究表明,优质的推荐系统能够将用户平均观看时长提升40%以上,用户留存率增加25%;此外,系统的数据可视化功能为平台运营决策提供了科学依据,帮助管理者及时了解用户偏好变化和市场趋势,制定更加精准的内容采购和推广策略。该项目的成功实施不仅为动漫产业的数字化转型提供了技术支持,也为其他垂直领域的推荐系统建设提供了可借鉴的实践模式。
2、动漫推荐系统-研究内容
1、动漫推荐系统需求分析与架构设计:深入研究当前动漫平台用户行为特征和内容消费习惯,通过线上问卷调研、用户访谈、数据分析等方式全面收集用户对个性化推荐功能的具体需求和体验期望。基于Python+Django框架设计系统整体技术架构,采用前后端分离的开发模式构建可扩展的服务体系,制定MySQL数据库设计方案和RESTful API接口规范。运用UML建模工具设计系统用例图、类图、时序图等核心设计文档,结合Hadoop+Spark大数据处理架构规划数据流转机制和算法执行流程,确保系统架构能够支撑海量数据处理和高并发访问需求,为推荐算法的高效运行提供稳定的技术基础。
2、网络爬虫数据采集系统构建与实现:基于Python爬虫技术开发多源数据采集模块,实现对主流动漫平台作品信息、用户评价、播放数据的自动化抓取和更新。设计分布式爬虫架构,通过多线程并发处理和反爬虫策略应对提升数据获取效率,建立数据清洗和去重机制确保采集信息的准确性和完整性。构建动态数据监控系统,实时跟踪热门动漫作品的更新状态、用户讨论热度、评分变化等关键指标;集成数据预处理模块,对采集到的非结构化文本信息进行分词、情感分析、标签提取等处理,为后续推荐算法提供高质量的数据支撑和特征输入。
3、协同过滤推荐算法设计与Spark计算优化:研究基于用户的协同过滤算法和基于物品的协同过滤算法在动漫推荐场景中的适用性,设计混合推荐模型解决数据稀疏性和冷启动问题。利用Spark分布式计算引擎实现用户相似度矩阵计算和物品相似度分析,通过RDD并行处理机制提升大规模数据集上的算法执行效率。建立用户行为特征工程体系,综合考虑观看历史、评分偏好、收藏习惯、社交互动等多维度数据特征,设计动态权重调整机制适应用户兴趣变化;实现推荐结果的实时更新和个性化排序,通过A/B测试验证不同算法参数对推荐效果的影响,持续优化推荐准确率和用户满意度。
4、Web应用系统开发与可视化展示实现:采用Django框架构建动漫推荐系统的Web应用程序,实现用户注册登录、个人资料管理、动漫作品浏览、个性化推荐展示等核心功能模块。开发交流论坛系统,支持用户发帖讨论、评论互动、话题标签分类等社区功能,增强用户粘性和平台活跃度;构建管理员后台管理系统,实现用户信息管理、动漫内容审核、系统配置维护等管理功能。集成数据可视化大屏展示模块,运用图表组件动态呈现动漫类型分布、评分统计分析、用户行为热力图、推荐效果监控等多维度运营数据,为平台运营决策和算法优化提供直观的数据支持和分析工具。
5、系统集成测试与性能调优验证:完成各功能模块开发后,进行全系统集成联调测试,验证前后端数据交互的准确性、推荐算法的执行效率、大数据处理流程的稳定性。设计涵盖功能测试、性能测试、安全测试、兼容性测试的综合测试方案,通过单元测试验证核心算法逻辑、集成测试检验模块间协作效果、压力测试评估系统并发处理能力。针对推荐算法响应时间、数据库查询效率、Spark作业执行速度等关键性能指标进行专项优化,建立系统监控预警机制和异常恢复策略;通过用户体验测试收集真实使用反馈,持续改进推荐精度和界面交互设计,确保动漫推荐系统能够稳定高效运行并满足用户个性化内容发现需求。
3、动漫推荐系统-开发技术与环境
1、开发环境: Python环境,pycharm,mysql(5.7或者8.0)
2、技术栈:Python+Djingo+爬虫,hadoop+spark
4、动漫推荐系统-功能介绍
2个角色:用户/管理员(亮点:爬虫、大屏可视化、协同过滤推荐算法)
用户:登录注册、查看动漫信息、交流论坛、查看动漫番剧 大屏可视化(类型统计、集数统计、评分统计、语言统计、动漫信息)
管理员:用户管理、动漫信息管理、动漫番剧管理、系统管理
5、动漫推荐系统成果展示
5.1演示视频
26届大数据毕业设计选题推荐| 基于协同过滤的动漫推荐系统设计与实现 可视化数据分析 在线动漫推荐系统
5.2演示图片
1、用户端页面:
☀️登录注册☀️
☀️动漫资讯☀️
☀️动漫番剧☀️
☀️交流论坛☀️
2、管理员端页面:
☀️用户管理☀️
☀️动漫番剧管理☀️
☀️动漫信息管理☀️
☀️数据可视化☀️
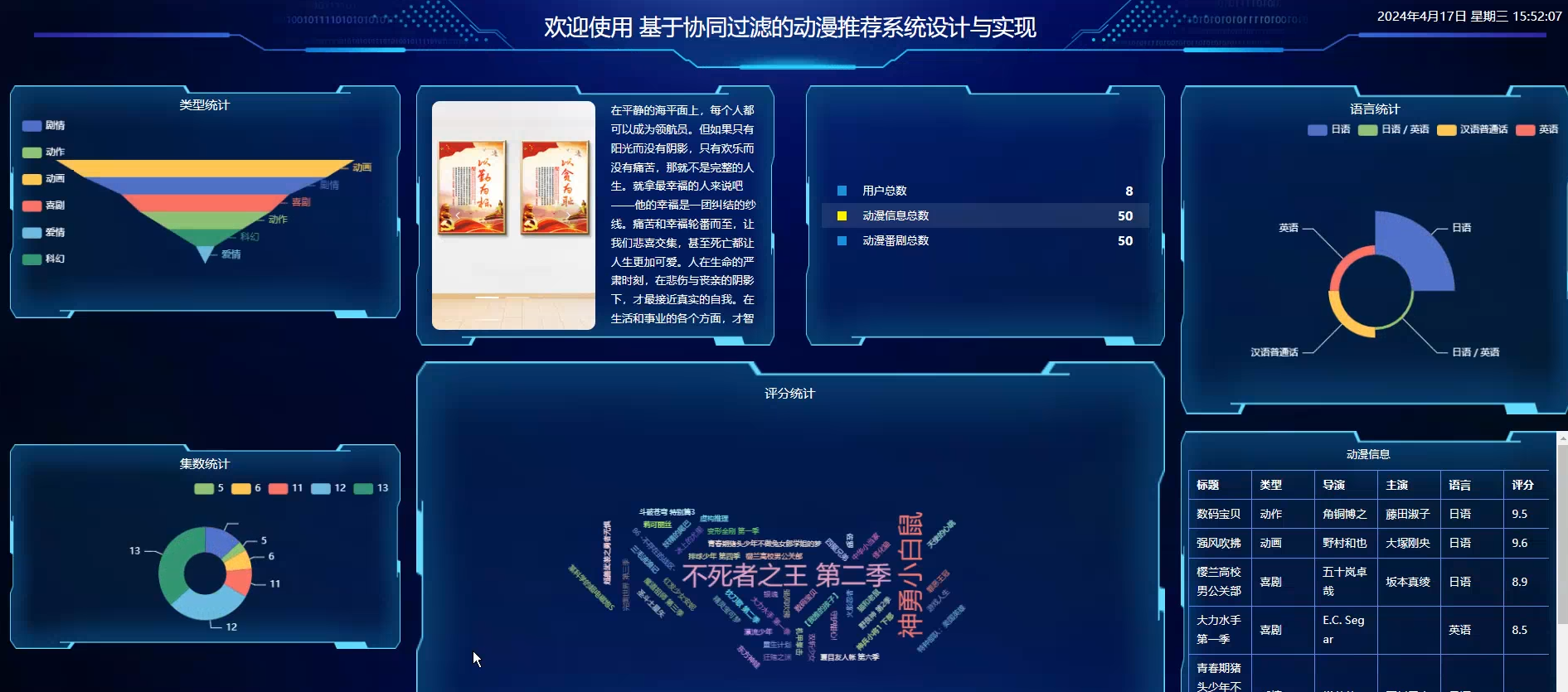
动漫推荐系统-代码展示
1.数据爬虫【代码如下(示例):】
class AnimeCrawler:
def __init__(self):
"""初始化爬虫配置"""
self.ua = UserAgent()
self.session = requests.Session()
self.setup_logging()
self.setup_database()
self.setup_selenium()
# 请求头配置
self.headers = {
'User-Agent': self.ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
self.session.headers.update(self.headers)
# 反爬虫配置
self.delay_range = (1, 3) # 请求间隔时间范围
self.max_retries = 3 # 最大重试次数
def setup_logging(self):
"""配置日志系统"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('anime_crawler.log', encoding='utf-8'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def setup_database(self):
"""初始化数据库连接"""
try:
self.db_config = {
'host': 'localhost',
'user': 'root',
'password': 'your_password',
'database': 'anime_recommendation',
'charset': 'utf8mb4'
}
self.create_tables()
except Exception as e:
self.logger.error(f"数据库连接失败: {e}")
def setup_selenium(self):
"""配置Selenium WebDriver"""
chrome_options = Options()
chrome_options.add_argument('--headless') # 无头模式
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument(f'--user-agent={self.ua.random}')
self.driver = webdriver.Chrome(options=chrome_options)
def create_tables(self):
"""创建数据库表结构"""
create_anime_table = """
CREATE TABLE IF NOT EXISTS anime_info (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
english_title VARCHAR(255),
year INT,
season VARCHAR(50),
episodes INT,
duration VARCHAR(50),
genre TEXT,
director VARCHAR(255),
studio VARCHAR(255),
rating DECIMAL(3,1),
rating_count INT,
description TEXT,
image_url VARCHAR(500),
source_url VARCHAR(500),
language VARCHAR(50),
status VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
2.数据清洗【代码如下(示例):】
class AnimeDataCleaner:
def __init__(self):
"""初始化数据清洗器"""
self.setup_logging()
self.setup_database()
self.genre_mapping = self.load_genre_mapping()
self.language_mapping = self.load_language_mapping()
self.studio_mapping = self.load_studio_mapping()
def setup_logging(self):
"""配置日志系统"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('data_cleaning.log', encoding='utf-8'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def setup_database(self):
"""初始化数据库连接"""
self.db_config = {
'host': 'localhost',
'user': 'root',
'password': 'your_password',
'database': 'anime_recommendation',
'charset': 'utf8mb4'
}
def load_genre_mapping(self):
"""加载动漫类型映射表"""
return {
'动作': 'Action', '冒险': 'Adventure', '喜剧': 'Comedy',
'戏剧': 'Drama', '奇幻': 'Fantasy', '恐怖': 'Horror',
'神秘': 'Mystery', '心理': 'Psychological', '浪漫': 'Romance',
'科幻': 'Sci-Fi', '惊悚': 'Thriller', '运动': 'Sports',
'校园': 'School', '日常': 'Slice of Life', '机甲': 'Mecha',
'魔法': 'Magic', '后宫': 'Harem', '治愈': 'Healing',
'百合': 'Yuri', '耽美': 'BL', '历史': 'Historical'
}
def load_language_mapping(self):
"""加载语言标准化映射"""
return {
'中文': 'Chinese', '英文': 'English', '日文': 'Japanese',
'韩文': 'Korean', '中国': 'Chinese', '美国': 'English',
'日本': 'Japanese', '韩国': 'Korean', 'CN': 'Chinese',
'EN': 'English', 'JP': 'Japanese', 'KR': 'Korean'
}
def load_studio_mapping(self):
"""加载制作公司标准化映射"""
return {
'东映动画': 'Toei Animation', '万代': 'Bandai',
'京都动画': 'Kyoto Animation', '骨头社': 'BONES',
'疯房子': 'Madhouse', 'A-1 Pictures': 'A-1 Pictures',
'MAPPA': 'MAPPA', 'WIT STUDIO': 'WIT Studio',
'日升': 'Sunrise', '白狐': 'White Fox'
}
def load_data_from_database(self):
"""从数据库加载原始数据"""
try:
conn = pymysql.connect(**self.db_config)
# 加载动漫基本信息
anime_query = """
SELECT id, title, english_title, year, episodes, genre, director,
studio, rating, rating_count, description, status, language,
created_at, updated_at
FROM anime_info
"""
self.anime_df = pd.read_sql(anime_query, conn)
# 加载用户评分数据
rating_query = """
SELECT ur.id, ur.anime_id, ur.user_name, ur.rating, ur.review,
ur.helpful_count, ur.created_at, a.title as anime_title
FROM user_ratings ur
JOIN anime_info a ON ur.anime_id = a.id
"""
self.rating_df = pd.read_sql(rating_query, conn)
conn.close()
self.logger.info(f"数据加载完成 - 动漫: {len(self.anime_df)} 条, 评分: {len(self.rating_df)} 条")
except Exception as e:
self.logger.error(f"数据加载失败: {e}")
def data_quality_report(self):
"""生成数据质量报告"""
self.logger.info("开始生成数据质量报告...")
# 动漫数据质量分析
anime_quality = {
'总记录数': len(self.anime_df),
'重复记录数': self.anime_df.duplicated().sum(),
'缺失值统计': self.anime_df.isnull().sum().to_dict(),
'异常年份数量': len(self.anime_df[(self.anime_df['year'] < 1900) | (self.anime_df['year'] > 2030)]),
'异常评分数量': len(self.anime_df[(self.anime_df['rating'] < 0) | (self.anime_df['rating'] > 10)]),
'异常集数数量': len(self.anime_df[self.anime_df['episodes'] > 1000])
}
动漫推荐系统-结语(文末获取源码)
💕💕
java精彩实战毕设项目案例
小程序精彩项目案例
Python精彩项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)