实践 | 文本数据处理实践
这是我第一次接触NLP,很激动、只是死去的语文回忆突然攻击我
·
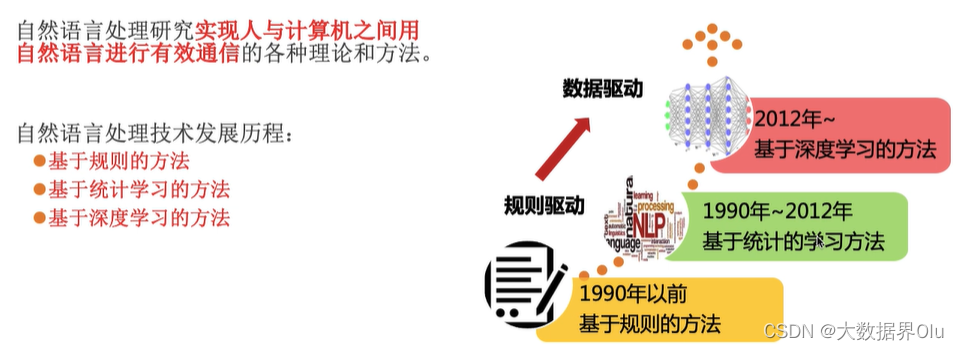
NLP知识背景

中文分词工具:
jieba
snownlp
thulac
nlpir
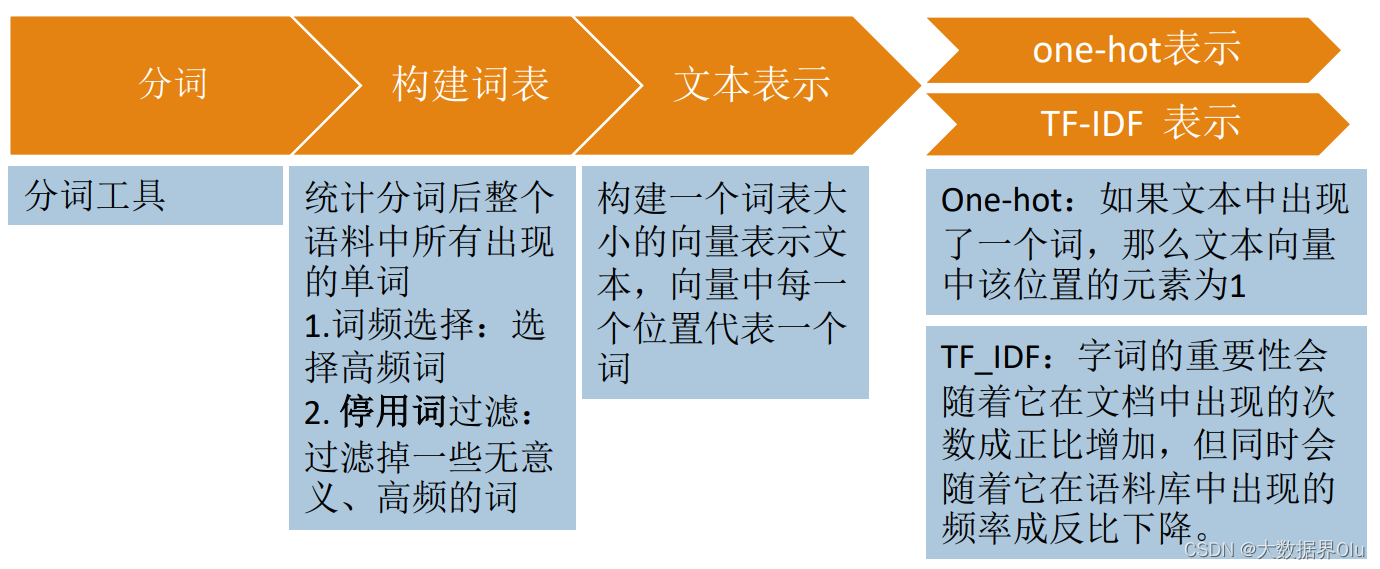
文本序列化 ex英文
数据说明:
work/data1.txt 英文数据
work/data2.txt 中文数据
加载数据
import jieba
import numpy as np
dict_path = 'work/dict.txt'
data_sat = 'data/data130495/data1.txt' # 'work/data2.txt'中文
#创建数据字典,存放位置:dicts.txt。在生成之前先清空dict.txt
#在生成all_data.txt之前,首先将其清空
with open(dict_path, 'w') as f:
f.seek(0)
f.truncate()
dict_set = set()
train_data = open(data_sat)
for data in train_data:
seg = jieba.lcut(data)#lcut返回列表,cut返回迭代器
for datas in seg:
if not datas is " ":
if not datas is '\n':
dict_set.add(datas)
dicts = open(dict_path,'w')
for data in dict_set:
dicts.write(data + '\n')
dicts.close()
分配序号
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
vocab = {}
with open(vocab_file, "r", encoding="utf-8") as reader:
tokens = reader.readlines()
for index, token in enumerate(tokens):
token = token.rstrip("\n").split("\t")[0]
vocab[token] = index
return vocab
vocab = load_vocab(dict_path)
for k, v in vocab.items():
print(k, v)

语料表示成向量
train_data = open(data_sat)
for data in train_data:
input_ids = []
input_names = ''
for token in jieba.cut(data):
# print(token)
# break
if not token is " ":
if not token is '\n':
token_id = vocab.get(token, 1)
input_ids.append(token_id)
input_names += token
input_names += ' '
print(input_names)
print(input_ids)

one-hot 文本向量化 ex汉语

数据内容:
import numpy as np
#初始数据:每个样本是列表的一个元素(本例中的样本是一个句子,但也可以是一整篇文档)
train_data = open('work/data2.txt')
samples = []
for data in train_data:
samples.append(data)
# print(samples)
# samples = ['The cat sat on the mat.', 'The dog ate my homework.']
#构建数据中所有标记的索引
token_index = {}
for sample in samples:
#利用 split 方法对样本进行分词。在实际应用中,还需要从样本中去掉标点和特殊字符
for word in jieba.lcut(sample):
# print(word)
if word not in token_index:
#为每个唯一单词指定一个唯一索引。注意,没有为索引编号 0 指定单词
token_index[word] = len(token_index) + 1
print(token_index)
#对样本进行分词。只考虑每个样本前 max_length 个单词
max_length = 10
results = np.zeros((len(samples), max_length, max(token_index.values()) + 1))
for i, sample in enumerate(samples):
# print(sample)
# datas = jieba.lcut(sample)
#每句话只取10个单词
for j, word in list(enumerate(jieba.lcut(sample)))[:max_length]:
index = token_index.get(word)
#将结果保存在 results 中
results[i, j, index] = 1.
for i in range(len(samples)):
print(f'data:{samples[i][:-1]}')
print(f'ont-hot:{results[i]}')

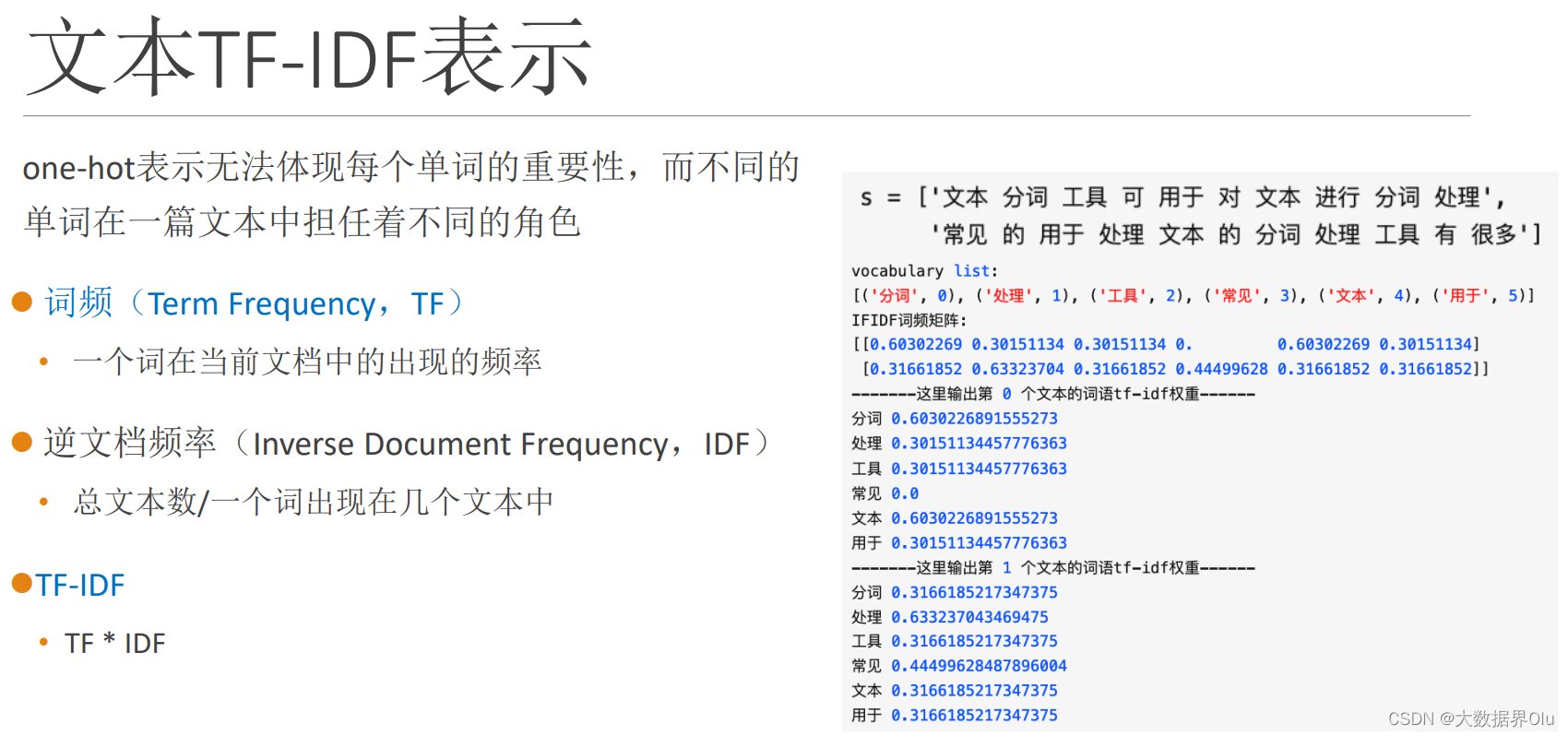
TF-IDF 文本向量化 ex英语
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
def sklearn_tfidf():
train_data = open('work/data1.txt')
samples = []
for data in train_data:
samples.append(data)
vectorizer = CountVectorizer() #将文本中的词语转换为词频矩阵
X = vectorizer.fit_transform(samples) #计算个词语出现的次数
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X) #将词频矩阵X统计成TF-IDF值
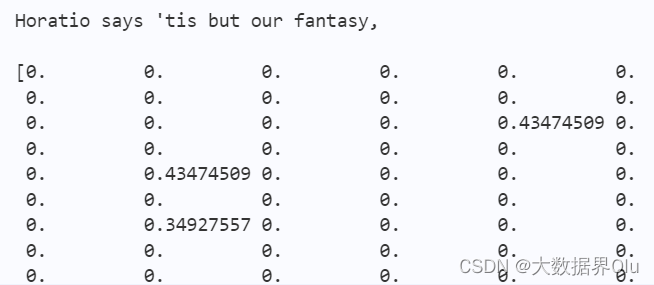
for i in range(len(samples)):
print(samples[i])
print(tfidf.toarray()[i])
sklearn_tfidf()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)