毕业设计:基于python招聘推荐系统+协同过滤推荐算法+数据分析+可视化 +Django框架 大数据毕业设计 hadoop✅
毕业设计:基于python招聘推荐系统+协同过滤推荐算法+数据分析+可视化 +Django框架 大数据毕业设计 hadoop✅
·
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
在商业领域,推荐系统近些年被广泛运用于向用户推荐符合其兴趣偏好的产品服务或内容,是解决当今信息超载问题的有效方法。基于网络爬虫技术和推荐算法实现的招聘信息分析与用户职位推荐系统,通过研究和对比用户的兴趣偏好进行用户定制化和个性化的计算,由系统发现用户的兴趣点,从而引导用户发现自己的信息需求,让推荐系统和用户之间建立密切关系,让用户对推荐系统产生依赖。
本职位推荐系统可以有效提高应聘者的求职效率和职位匹配度,通过求职者的浏览记录和收藏列表为用户定向推荐与其需求相似的职位。系统基于Python3.9开发环境,通过Scrapy爬虫框架爬取招聘网站相关职位信息并对其进行存储、清洗,后端存储在Sqlite数据库,采用Django框架以web界面的方式为用户提供了招聘信息浏览查看功能、可视化分析功能、职位收藏以及职位查询功能,并且基于协同过滤推荐算法把职位信息定向推荐给用户。
关键词:招聘信息推荐;Python;数据爬虫;可视化分析;
2、项目界面
(1)数据分析可视化界面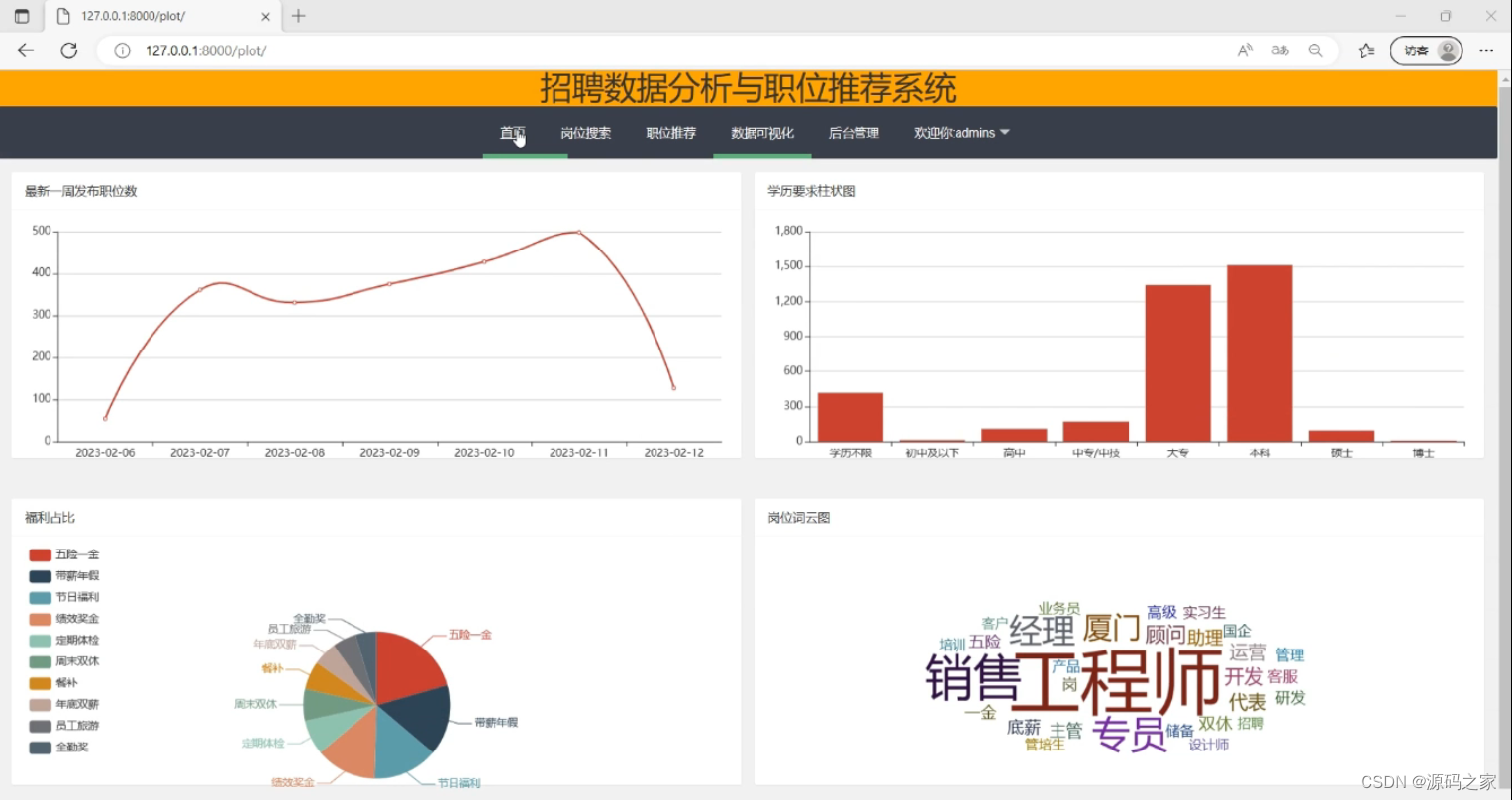
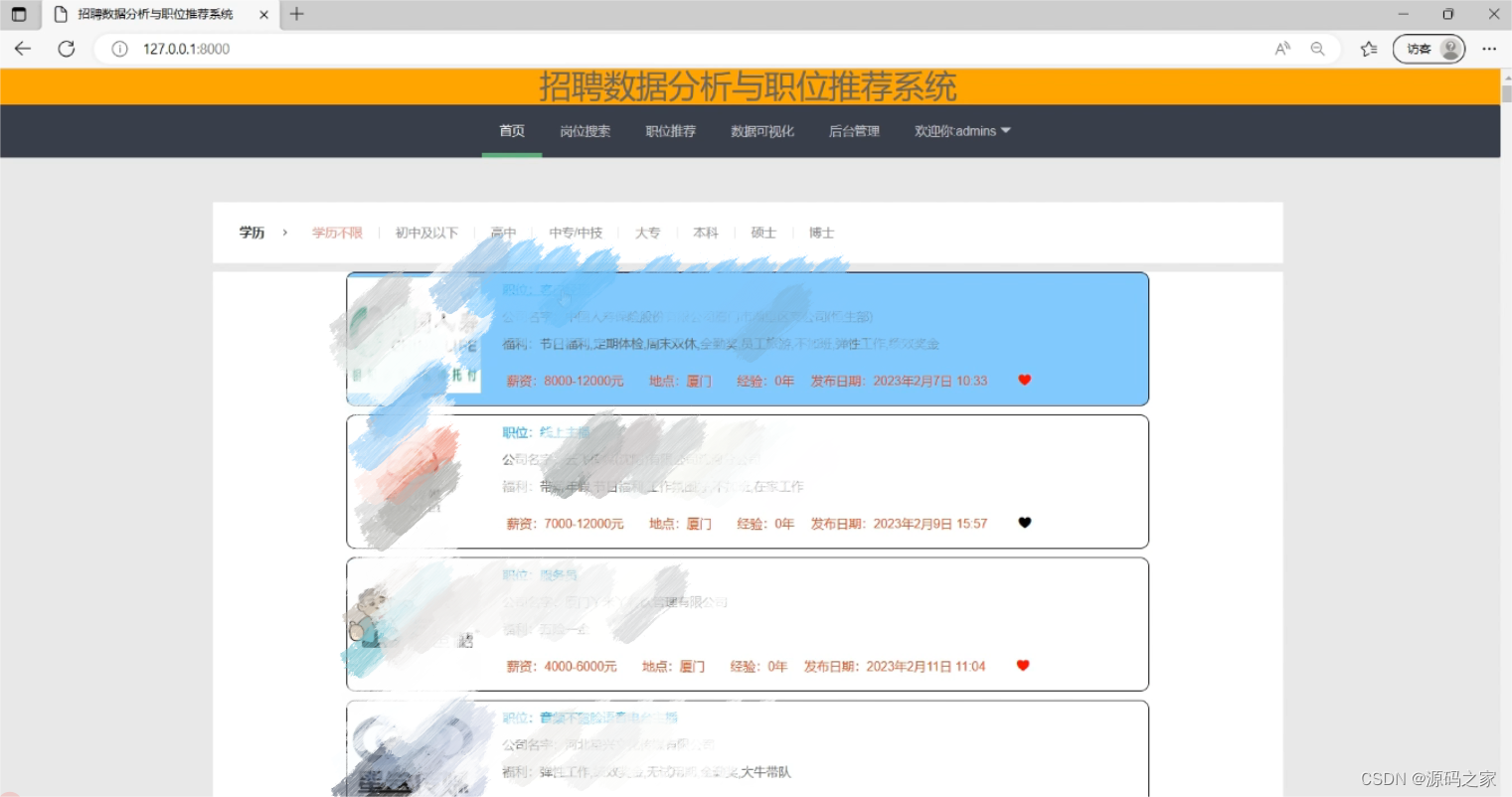
(2)首页------数据筛选界面
(3)招聘数据详情页

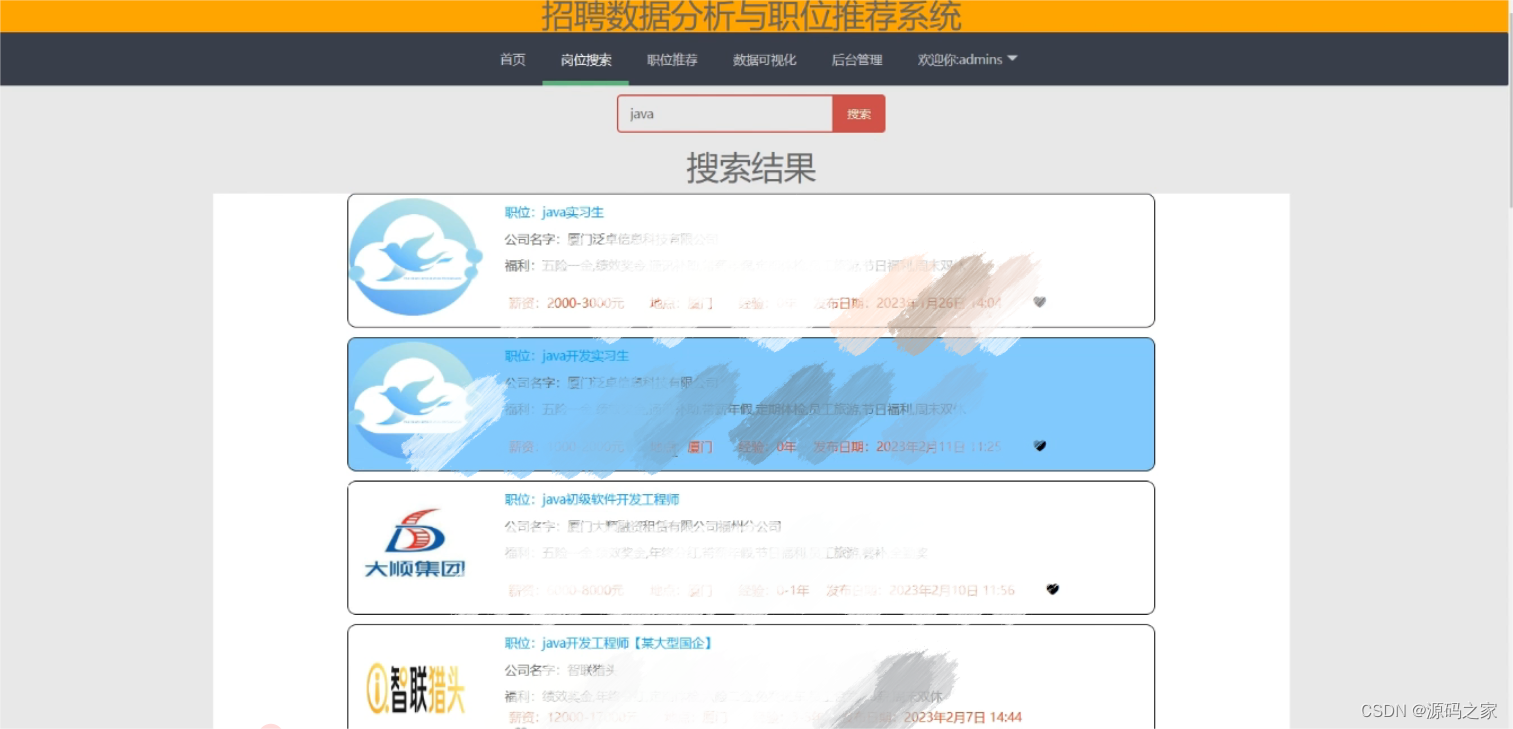
(4)推荐模块
(5)我的收藏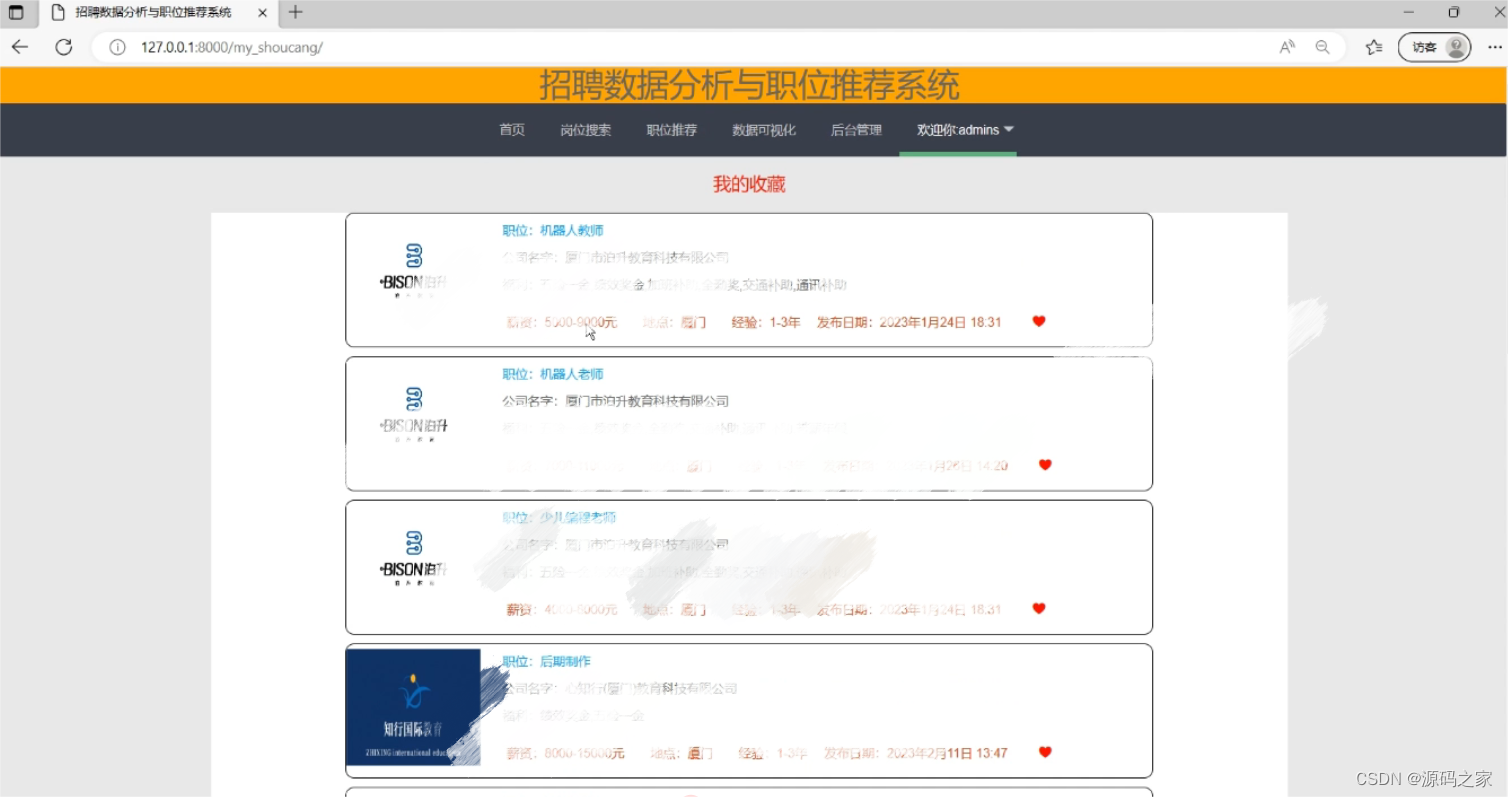
(6)注册登录模块
3、项目说明
(1)推荐模块Python代码:
class KNN:
def __init__(self, train):
self.train = train
int(float(score))
def ItemSimilarity(self):
cooccur = dict() # 物品-物品的共现矩阵
buy = dict() # 物品被多少个不同用户购买N
for user, items in self.train.items():
for i in items.keys():
buy.setdefault(i, 0)
buy[i] += 1
cooccur.setdefault(i, {})
for j in items.keys():
if i == j: continue
cooccur[i].setdefault(j, 0)
cooccur[i][j] += 1 / math.log(1 + len(items) * 1.0)
# 计算职位相似度矩阵
self.similar = dict()
for i, related_items in cooccur.items():
self.similar.setdefault(i, {})
for j, cij in related_items.items():
self.similar[i][j] = cij / (math.sqrt(buy[i] * buy[j]))
# print(self.similar)
return self.similar
# 给用户user推荐,前K个相关用户,前N个物品
def Recommend(self, user, K=10, N=10):
rank = dict()
action_item = self.train[user]
# print(action_item)
# 用户user产生过行为的item和评分
for item, score in action_item.items():
sortedItems = sorted(self.similar[item].items(), key=lambda x: x[1], reverse=True)[0:K]
for j, wj in sortedItems:
if j in action_item.keys():
continue
rank.setdefault(j, 0)
rank[j] += score * wj
return dict(sorted(rank.items(), key=lambda x: x[1], reverse=True)[0:N])
(2)功能模块框架设计
数据爬取:使用Scrapy爬虫框架实现对智联招聘网址上招聘信息数据的爬取,并对爬取到的职位数据进行处理(例如薪资单位统一,经验需求格式统一等)。
职位信息展示:通过Django框架把爬取的数据信息展示在系统首页。按学历筛选职位信息:在系统首页提供根据学历筛选职位的功能;职位详情页展示:用户通过点击首页职位进入职位详情页,并在浏览表中记录用户uid、职位jid、浏览次数。
职位收藏:用户通过点击职位栏中的心形按键实现职位的收藏,收藏表记录收藏职位用户uid、职位jid。
职位搜索:用户通过点击进入搜索页面,输入关键字来对职位名称和公司名称进行搜索。
职位信息可视化分析:通过准备好的ECharts实例进行数据的可视化展示,包括最新发布职位折线图、学历要求柱状图、福利待遇饼状图、岗位词云图。
用户注册登陆:求职者可以通过用户名,密码,手机号注册,同一手机号无法重复注册,正确输入账号密码可以登陆到职位推荐系统。
用户信息修改:可重置密码、手机号信息。
职位推荐:根据用户职位收藏和浏览信息,系统通过协同过滤算法计算用户偏好,并以此进行职位的推荐。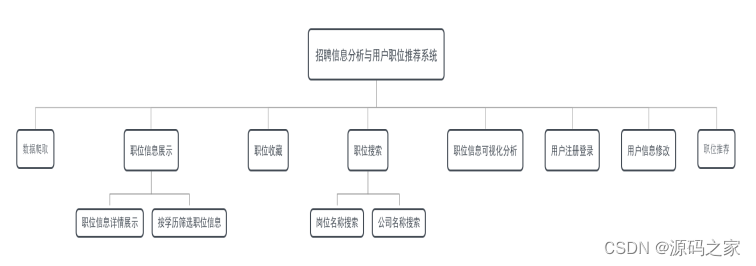
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)