grafana从mysql取数据_grafana简介以及grafana从mysql获取数据绘制折线图-Go语言中文社区...
1、可视化工具Grafana:Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch
1、可视化工具Grafana:
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
下载安装:
#使用Yum安装Grafana
#sudo yum install
sudo yum install https://dl.grafana.com/oss/release/grafana_6.2.5_amd64.deb
#使用手动安装
#wget
wget https://dl.grafana.com/oss/release/grafana_6.2.5_amd64.deb
sudo dpkg -i grafana_6.2.5_amd64.deb
sudo yum install grafana
#包装细节:
#安装二进制文件 /usr/sbin/grafana-server
#将init.d脚本复制到 /etc/init.d/grafana-server
#安装默认文件(环境变量) /etc/sysconfig/grafana-server
#将配置文件复制到 /etc/grafana/grafana.ini
#安装systemd服务(如果systemd可用)名称 grafana-server.service
#默认配置使用日志文件 /var/log/grafana/grafana.log
#默认配置指定sqlite3数据库 /var/lib/grafana/grafana.db
#启动服务器(init.d服务)
#启动Grafana
#这将以安装包期间创建grafana-server的grafana用户身份启动进程。默认HTTP端口是3000,默认用户和组是admin。默认登录名和密码admin/admin
sudo service grafana-server start
#To configure the Grafana server to start at boot time
sudo /sbin/chkconfig --add grafana-server
#启动服务器(通过systemd)
systemctl daemon-reload
systemctl start grafana-server
systemctl status grafana-server
#Enable the systemd service to start at boot
sudo systemctl enable grafana-server.service
#首次登录
#要运行Grafana,请打开浏览器并转到http:// localhost:3000 /,3000是Grafana侦听的默认http 端口。
#登陆之后
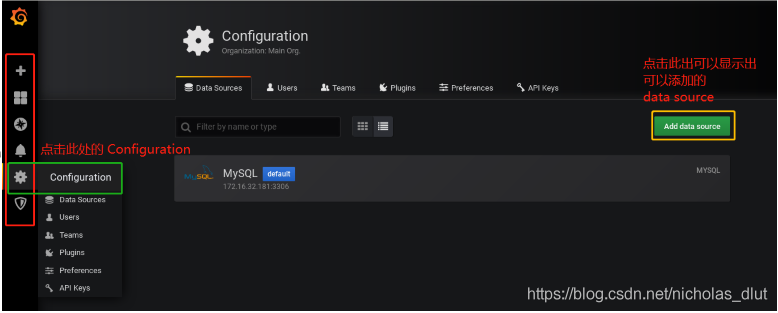
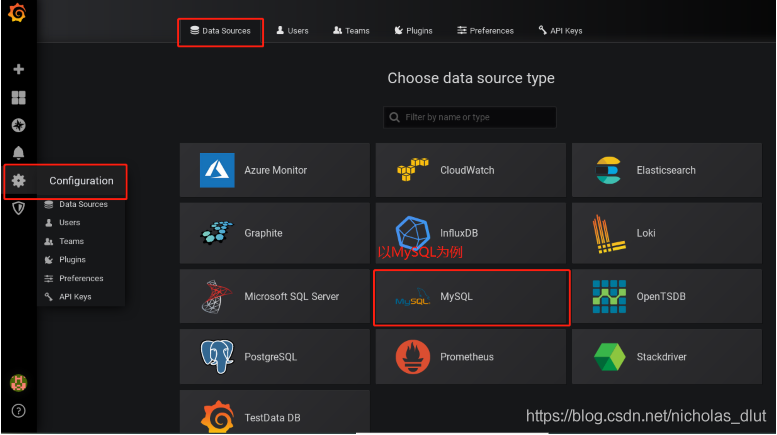
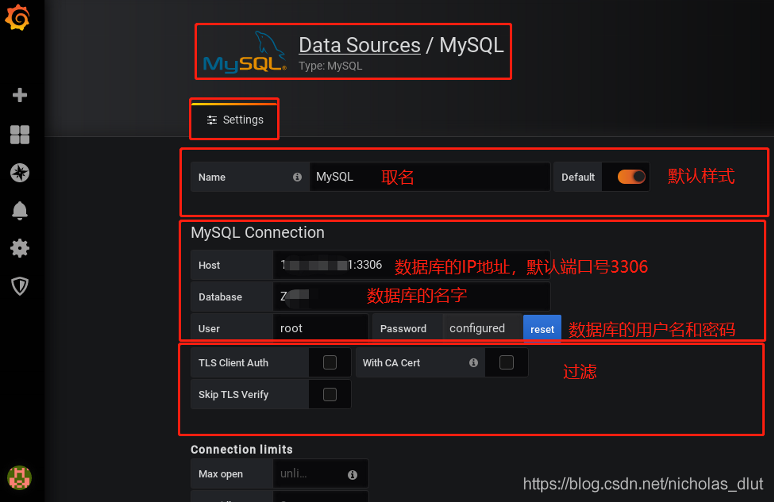
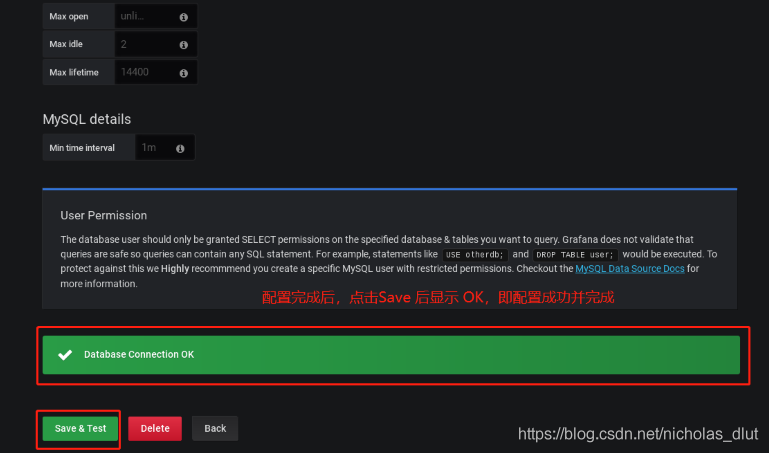
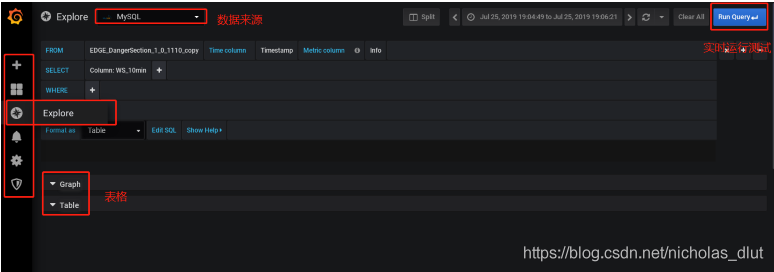
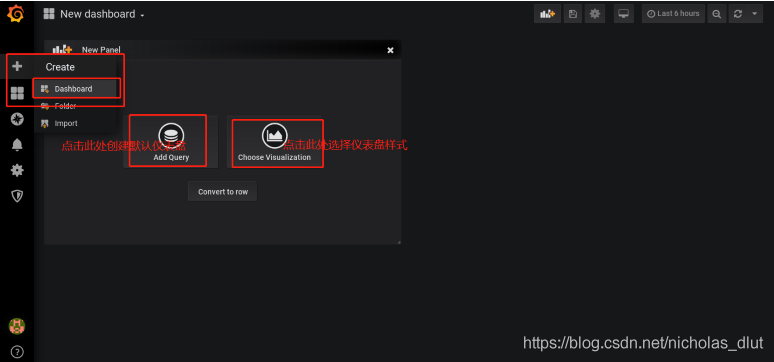
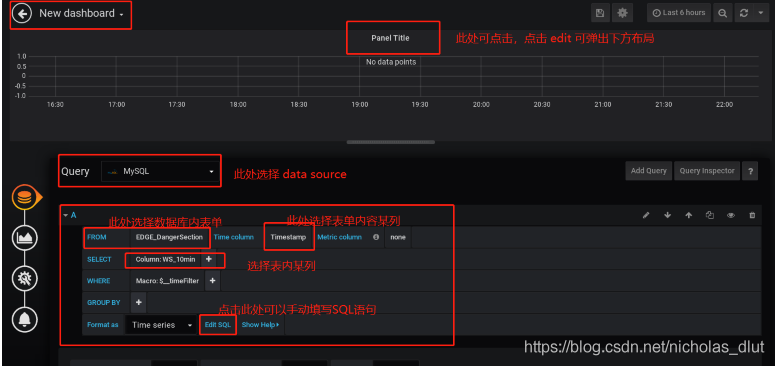
2、
画折线图:暂需注意一点,若以时间未x轴,则需要数据未double类型的unix时间戳格式
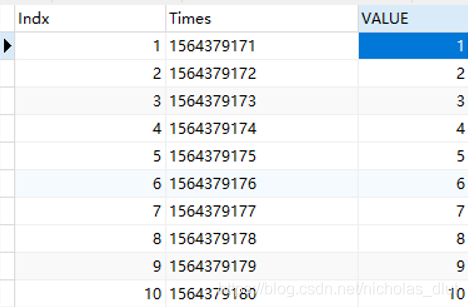

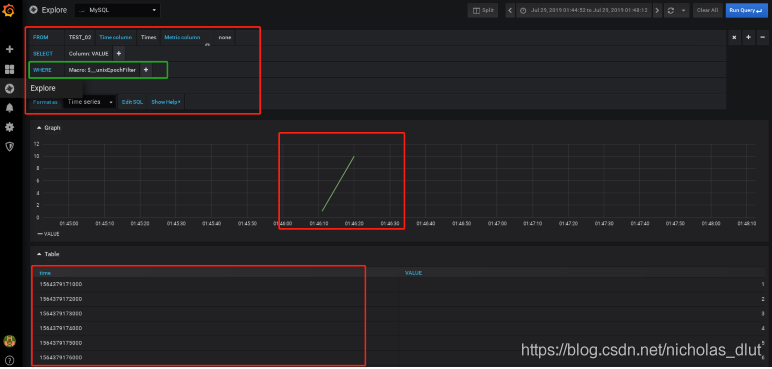
3、
pymysql
# conding=utf-8
import time
import pymysql
创建数据库连接
conn = pymysql.connect(host='xxx.xxx.x.x',user='xxxx',passwd='xxxxx',db='xxxxx',charset='utf8')
# 获取游标
cursor = conn.cursor()
# 创建数据表
cursor.execute("""CREATE TABLE IF NOT EXISTS TEST_01 (
Indx INT NOT NULL AUTO_INCREMENT,
Times DOUBLE DEFAULT '0',
Value FLOAT DEFAULT '0',
PRIMARY KEY(Indx)
)ENGINE=InnoDB DEFAULT CHARSET=utf8
""")
i = 1
while i < 11:
# 插入数据
cursor.execute('insert into TEST_01(Times,Value) values(%d,%d)'%(int(time.time()),i))
i+=1
time.sleep(1)
cursor.close()
conn.close()
conn.commit()
#cursor.execute(sql, args) 执行单条 SQL
cursor.execute('insert into TEST_01(Times,Value) values(%d,%d)'%(int(time.time()),i))
#cursor.executemany(sql, args) 批量执行 SQL
sql = 'insert into TEST_01(Times,Value) values(%d,%d)'
args = [
(int(time.time()),i),
(int(time.time()+=1),i+=1)),
]
cursor.executemany(sql, args)
# 执行查询 SQL
cursor.execute('SELECT * FROM TEST_01')
# 获取单条数据
cursor.fetchone()
# 获取前N条数据
cursor.fetchmany(3)
# 获取所有数据
cursor.fetchall()
#开启事务
connection.begin()
#INSERT、UPDATE、DELETE 等修改数据的语句需手动执行connection.commit()完成对数据修改的提交。
#提交修改
connection.commit()
#回滚事务
connection.rollback()
#转义特殊字符
connection.escape_string(str)
connection的参数:
host,连接的数据库服务器主机名,默认为本地主机(localhost)。
user,连接数据库的用户名,默认为当前用户。
password,连接密码,没有默认值。或者 passwd
database,默认操作的数据库。或者 db
port,指定数据库服务器的连接端口,默认是3306
conv,Conversion dictionary to use instead of the default one. This is used to provide custom marshalling and unmarshaling of types.
cursorclass,设置默认的游标类型。
init_command,当连接建立完成之后执行的初始化 SQL 语句。
read_default_file,Specifies my.cnf file to read these parameters from under the [client] section。
read_default_group,Group to read from in the configuration file。
unix_socket,unix 套接字地址,区别于 host 连接。
charset,数据库编码.
4、
mysql语句
#删除数据表
DROP TABLE table_name
#如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句。
SELECT * FROM table_name WHERE key=' value'
#ORDER BY 语句
#ORDER BY 语句用于根据指定的列对结果集进行排序。
#ORDER BY 语句默认按照升序对记录进行排序。
SELECT key1,key2 FROM table_name ORDER BY key1
#GROUP BY 语句
#GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)