基于LLM与检索增强生成(RAG)的文本生成
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将信息检索与文本生成相结合的 AI 技术。它通过检索模块从外部知识库中检索与问题相关的文档或信息,然后利用生成模块处理这些信息,生成更专业的文本。RAG广泛应用于问答系统、对话系统、个性化推荐等领域。
什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将信息检索与文本生成相结合的 AI 技术。它通过检索模块从外部知识库中检索与问题相关的文档或信息,然后利用生成模块处理这些信息,生成更专业的文本。RAG广泛应用于问答系统、对话系统、个性化推荐等领域。
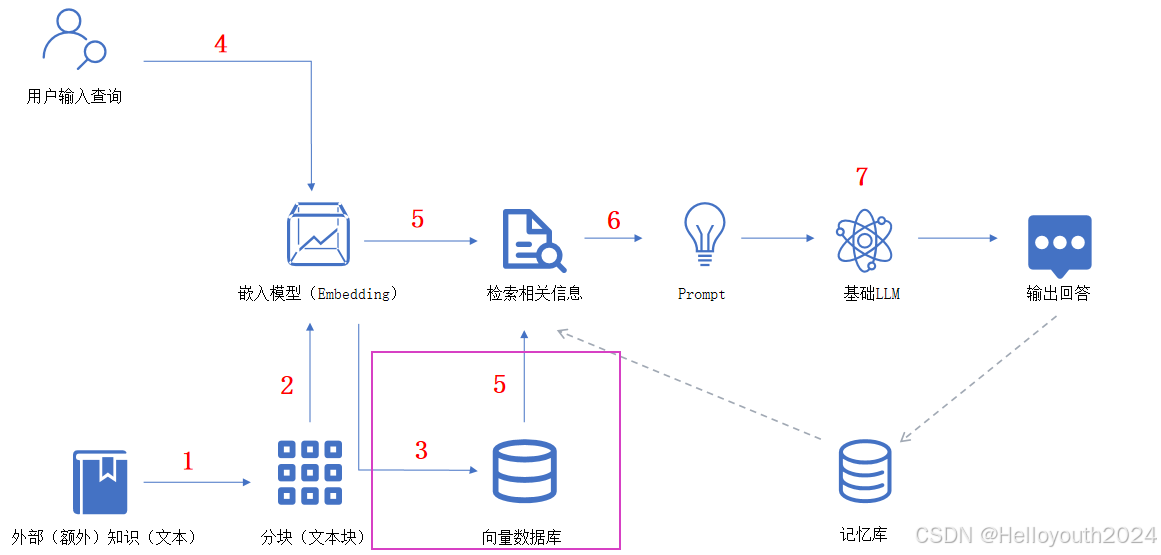
RAG的一般工作流程
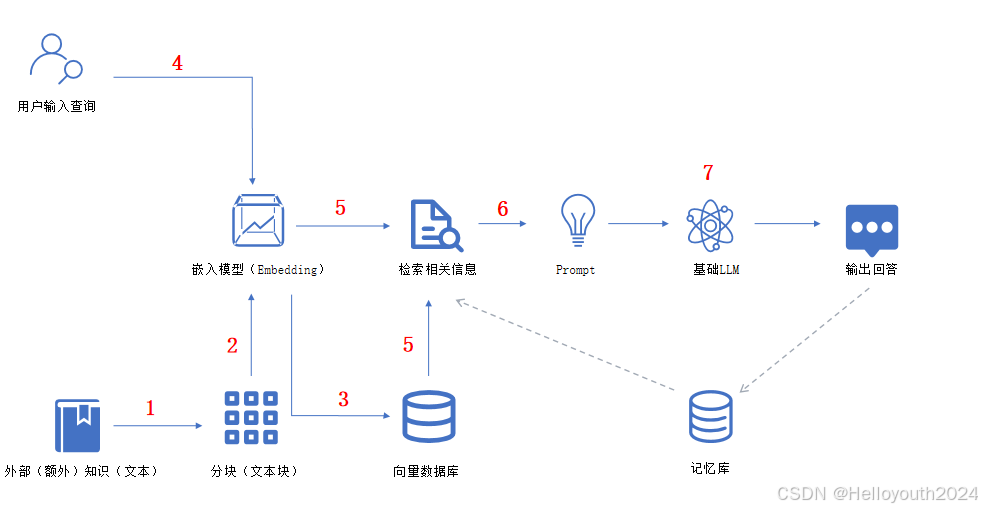
① 构建知识库:1 → 2 → 3
知识文档分块 → 文本块向量化 → 向量高效存储
② 用户查询:4 → 5 → 6 → 7
用户输入查询 → 从“向量数据库”检索查询相关的信息 → 根据提示模板生成辅助提示信息 → 用户查询和提示信息(Prompt)一起作为LLM的输入并得到最终回答
③ 可将历史对话信息存入知识库作为下次用户查询输入的相关辅助信息(上图图中的虚线箭头部分)
基于LLM结合RAG进行文本生成的实验——使用pytorch和transformers构建
准备相关依赖包
本文python环境:Python 3.11.10
核心依赖包:
torch
transformers==4.47.0
sentence_transformers
beautifulsoup4~=4.12.3
PyPDF2~=3.0.1
markdown~=3.7
jieba其中 jieba库是分词工具包,它是一款基于词典的中文分词工具,它可以将中文文本分割成词语。另外,其实其可以对规范的英文文本进行单词级别的分词,所以本文实验使用 jieba 进行中英文双语语料库的文本进行token级别的分词。
# jieba分词
import jieba
# 示例文本
text = "Hello, world! 今天我去看了电影Avatar。\n 我觉得这部电影太棒了!"
print(list(jieba.cut(text)))输出结果:
['Hello', ',', ' ', 'world', '!', ' ', '今天', '我', '去', '看', '了', '电影', 'Avatar', '。', '\n', ' ', '我', '觉得', '这部', '电影', '太棒了', '!']
读取文件与处理
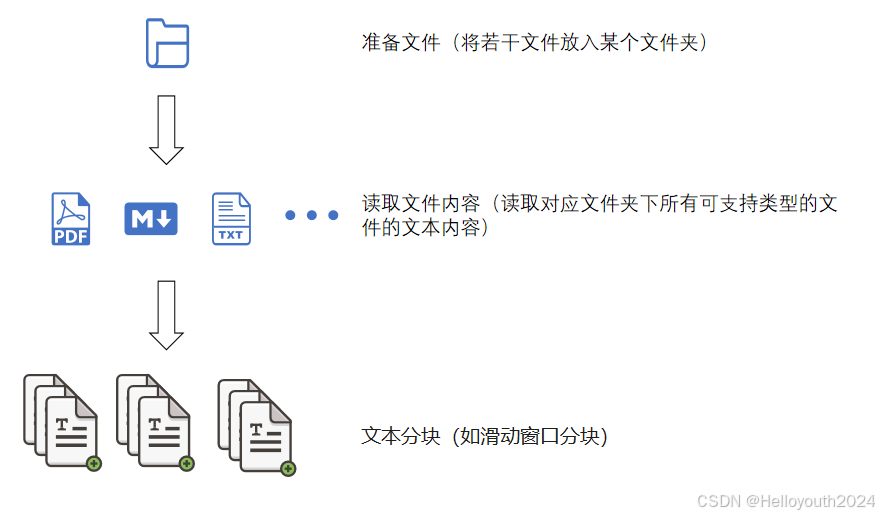
1. 读取文件:读取对应文件夹下所有文件。
2. 提取内容:判断文件类型,设计提取内容方式,实现多种格式统一化处理。
3. 分块:采用滑动窗口分块的逻辑分割长文本,确保段落间的语义连续性。
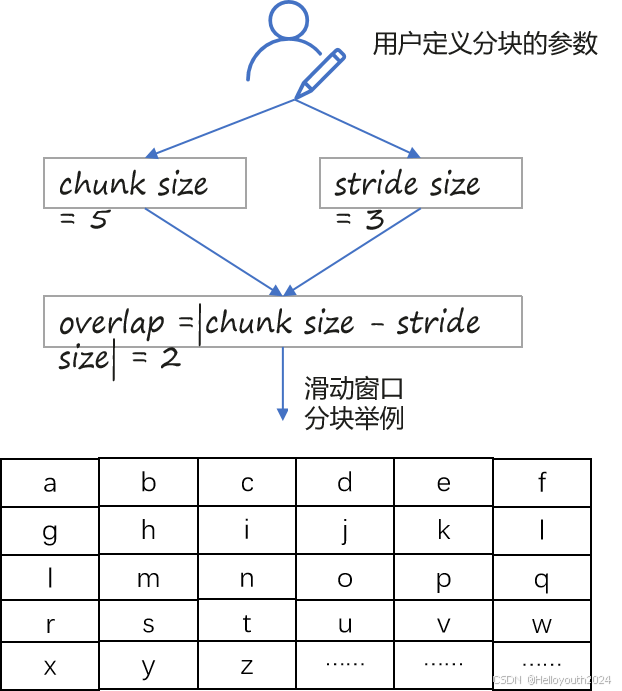
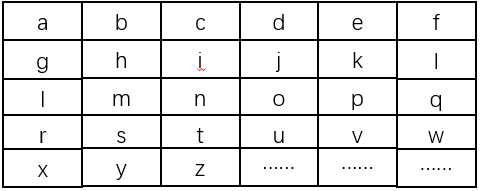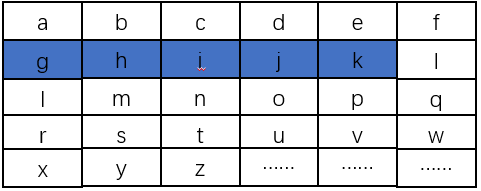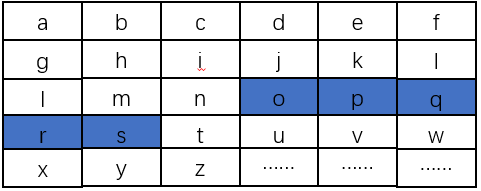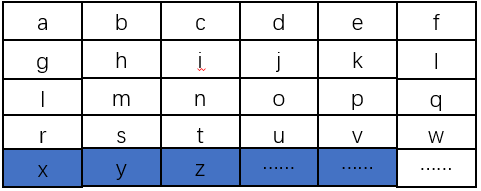
其中,核心处理是滑动窗口分块算法的实现:
代码:
class ReadFiles:
"""
class to read files
"""
# 定义 可支持读取的文件的类型( 根据类型编写相关读取函数:read_xxx() )
SUPPORT_TYPES = ['.md', '.txt', '.pdf']
def __init__(self, path: str) -> None:
"""
path: 文件所在文件夹的路径
"""
self._path = path
self.file_list = self.get_files() # 获取 可支持类型的 文件的路径列表
@classmethod
def read_pdf(cls, file_path: str):
# 读取PDF文件
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
text += reader.pages[page_num].extract_text()
return text
@classmethod
def read_markdown(cls, file_path: str):
# 读取Markdown文件
with open(file_path, 'r', encoding='utf-8') as file:
md_text = file.read()
html_text = markdown.markdown(md_text)
# 使用BeautifulSoup从HTML中提取纯文本
soup = BeautifulSoup(html_text, 'html.parser')
plain_text = soup.get_text()
# 使用正则表达式移除网址链接
text = re.sub(r'http\S+', '', plain_text)
return text
@classmethod
def read_text(cls, file_path: str):
# 读取文本文件
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
def get_files(self):
# args:dir_path,目标文件夹路径
file_list = [] # 存储文件路径的列表
# 遍历目标文件夹的所有文件(含子目录中的文件)
for filepath, dirnames, filenames in os.walk(self._path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断 当前文件的类型是否满足要求
for support_type in self.SUPPORT_TYPES:
if filename.endswith(support_type):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
break
return file_list
def get_content(self, chunk_size: int = 500, stride_size: int = 100):
docs = []
# 读取文件内容
for file in self.file_list:
content = self.read_file_content(file) # 读取文件内容
# 切分长文本为多个文本块
chunk_content, _ = self.get_chunk(content, chunk_size=chunk_size, stride_size=stride_size)
# 将每个块加入到文档列表
docs.extend(chunk_content)
# 返回最后进行分块处理后的文档列表
return docs
@classmethod
def get_chunk(cls, text: str, chunk_size: int = 500, stride_size: int = 100):
"""
滑动窗口分块策略
text: 待分块文本
chunk_size: 单个块的大小(单个文本块的token数量,这里的token指jieba分词后的词语/单词)
stride_size: 窗口滑动步长
"""
assert chunk_size > stride_size, "chunk_size must be greater than stride_size"
chunk_text = []
chunk_text_token_version = []
# 去掉text的换行符为空格
# text = text.replace('\n', ' ')
# 切分为单词列表
words = list(jieba.cut(text))
# 计算单词列表的长度
words_len = len(words)
# 计算overlap
overlap = chunk_size - stride_size
chunk_text_token_version.append(words[:chunk_size]) # 第一个块
# 循环遍历,生成其它块
for i in range(chunk_size, words_len, stride_size):
# 计算当前块的起始位置
start = i - overlap
# 计算当前块的结束位置
end = start + chunk_size
# 加入到块列表
chunk_text_token_version.append(words[start:end])
# 将token列表转换为文本列表
chunk_text = [''.join(token_list) for token_list in chunk_text_token_version]
return chunk_text, chunk_text_token_version
@classmethod
def read_file_content(cls, file_path: str):
# 根据文件扩展名选择读取方法
if file_path.endswith('.pdf'):
return cls.read_pdf(file_path)
elif file_path.endswith('.md'):
return cls.read_markdown(file_path)
elif file_path.endswith('.txt'):
return cls.read_text(file_path)
else:
raise ValueError("Unsupported file type")
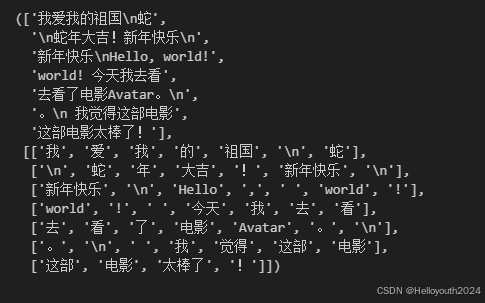
ReadFiles.get_chunk("我爱我的祖国\n蛇年大吉!新年快乐\nHello, world! 今天我去看了电影Avatar。\n 我觉得这部电影太棒了!", 7, 5)
本次实验准备了一个测试文档(来自本人在本科时的一门课程——运筹学的期末课程报告):
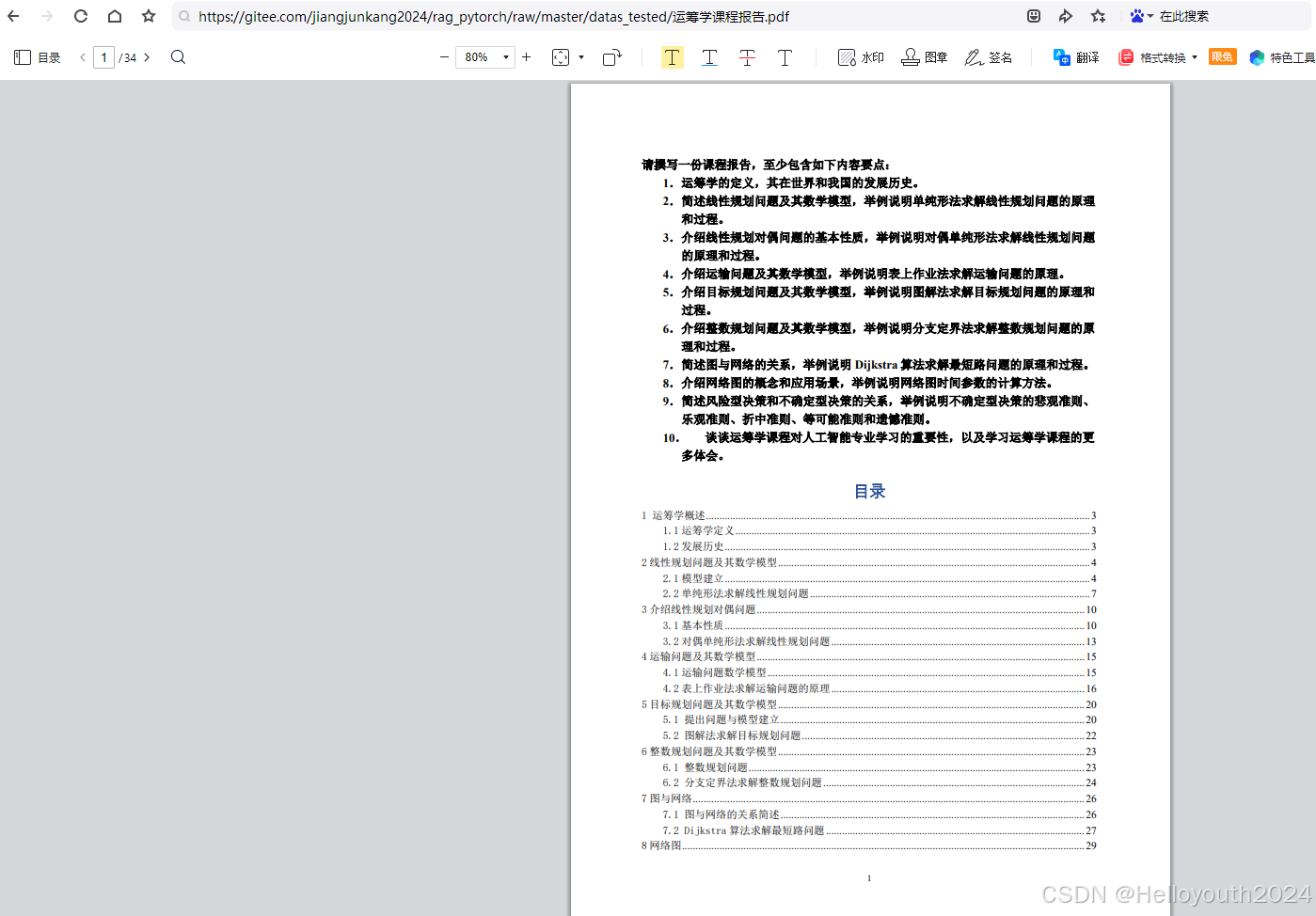
files_dir = './datas_tested'
texts = ReadFiles(files_dir)
texts_chunks = texts.get_content(chunk_size = 500, stride_size = 300) # 获得data目录下的所有文件内容并分割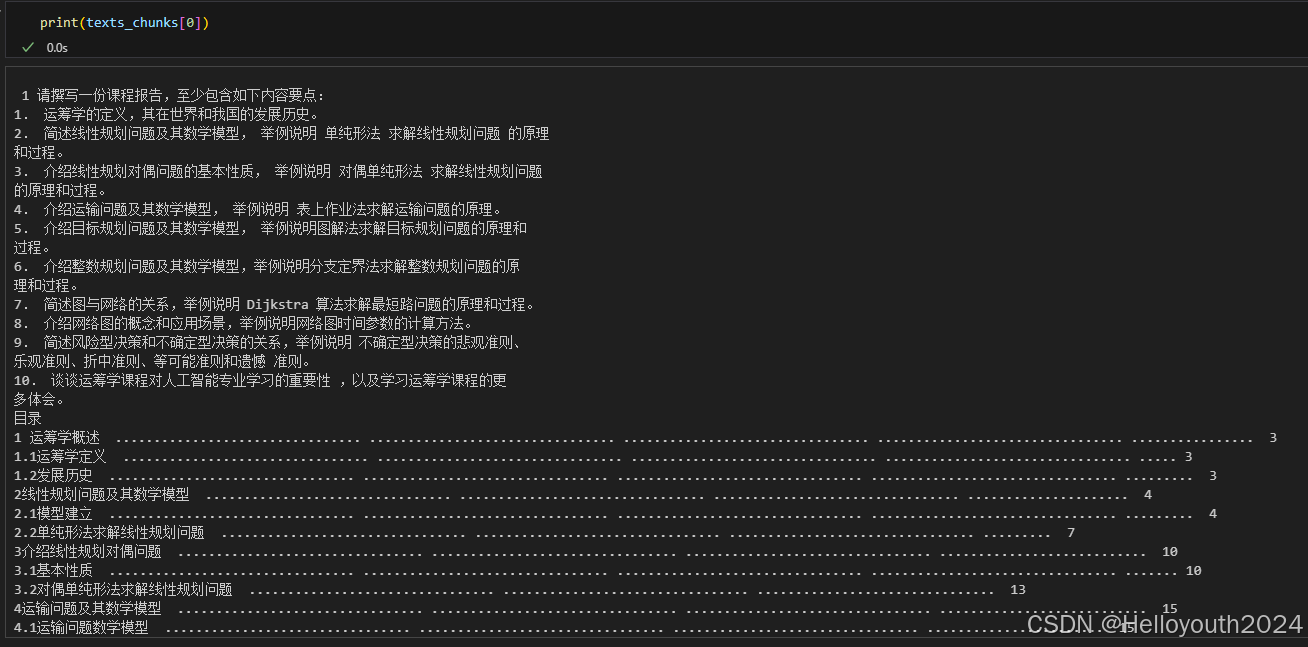
Embedding设计:嵌入模型、检索、SentenceTransformer
1. 嵌入模型:将文本转为可被计算机识别和认识的向量表示形式
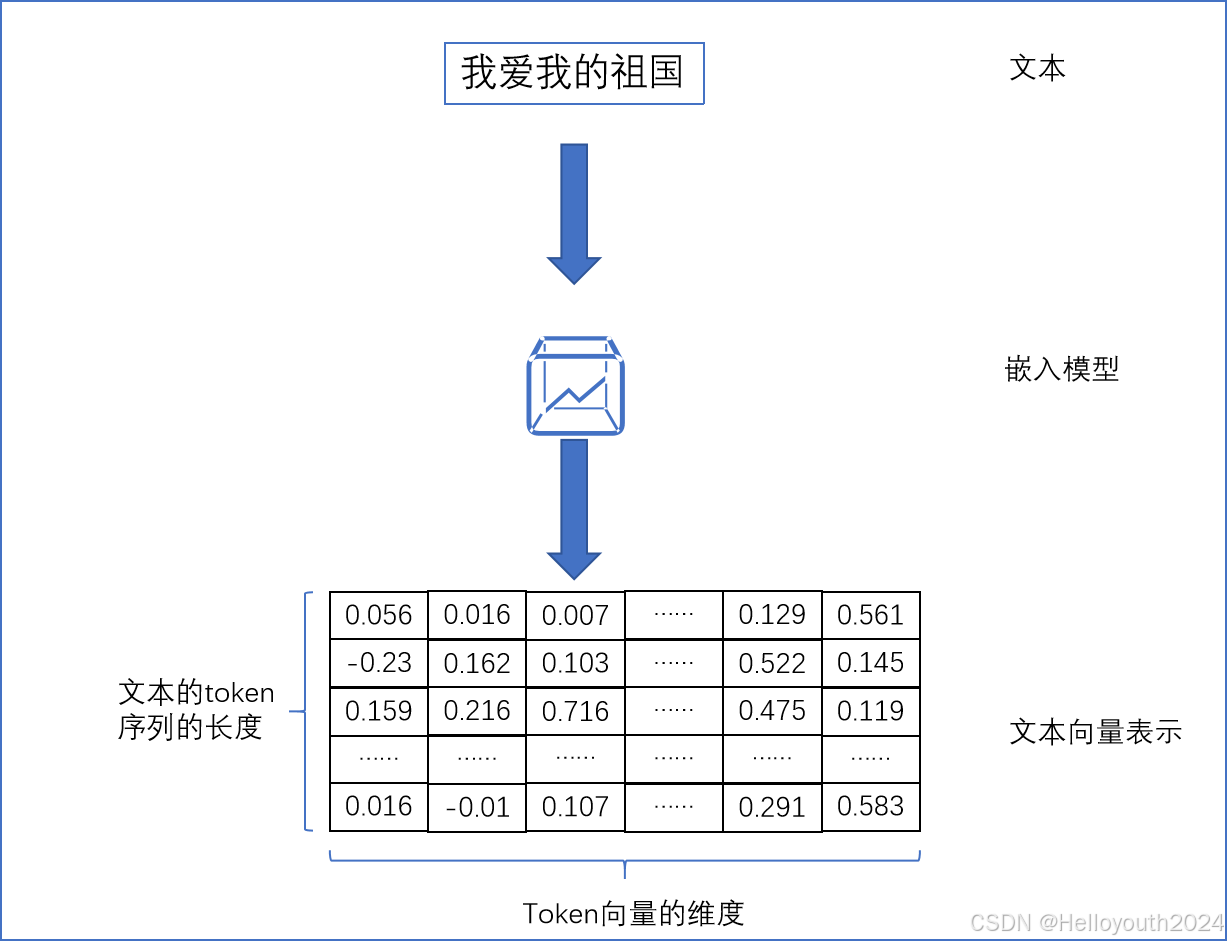
2. 检索:通过两个不同文本对应的向量之间的相似度来衡量文本之间的相关性,从而可以实现通过一个文本找到其它相似的文本,也即“检索”
余弦相似度通过计算两个向量之间的夹角的余弦值,来表示它们在向量空间中的相似性。余弦相似度的值范围在 [ − 1 , 1 ]之间。
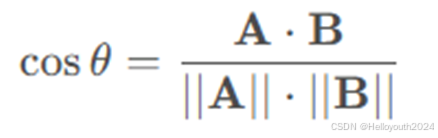
3. SentenceTransformers是一个用于句子、文本嵌入的组件,提供了简单易用的接口来生成高质量的文本嵌入。
class BaseEmbeddings:
"""
Base class for embeddings
"""
def __init__(self, path: str, is_api: bool) -> None:
"""
参数:
path: 一个字符串,表示嵌入模型的路径或资源位置
is_api: 一个布尔值,表示是否通过 API 接口获取嵌入向量
"""
self.path = path
self.is_api = is_api
def get_embedding(self, text: str, model: str) -> List[float]:
pass
raise NotImplementedError
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
"""
calculate cosine similarity between two vectors
"""
dot_product = np.dot(vector1, vector2)
magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2)
if not magnitude:
return 0
return dot_product / magnitude
class ModelEmbedding(BaseEmbeddings):
"""
class for Model embeddings
"""
def __init__(self, path: str = 'BAAI/bge-base-zh-v1.5', is_api: bool = False) -> None:
super().__init__(path, is_api)
self._model = self.load_model(path)
def get_embedding(self, text: str):
sentence_embedding = self._model.encode([text], normalize_embeddings=True)
return sentence_embedding
def load_model(self, path: str):
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(path)
return model
@classmethod
def cosine_similarity(cls, sentence_embedding_1, sentence_embedding_2):
"""
calculate similarity between two vectors
"""
similarity = sentence_embedding_1 @ sentence_embedding_2.T
return similarity
bge_base_model = r"BAAI/bge-base-zh-v1.5"
embedding = ModelEmbedding(bge_base_model) #"BAAI/bge-base-zh-v1.5"
embedding._model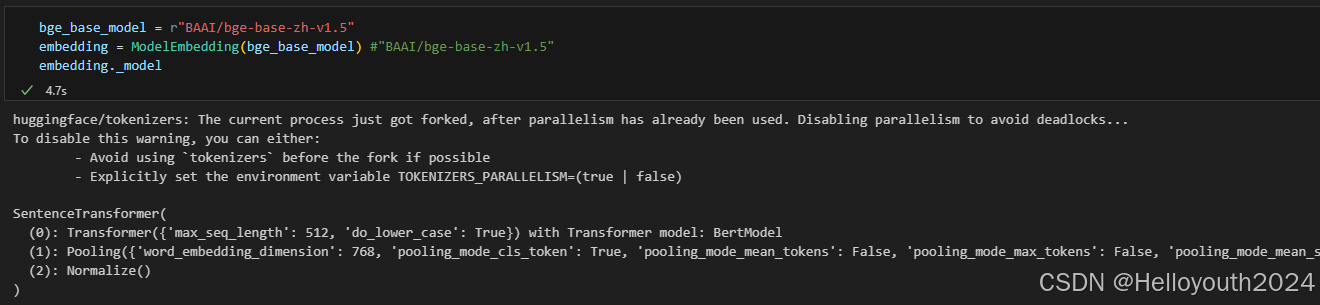
知识库设计:存储、检索指定文本嵌入向量的“数据库”
在RAG架构设计中,知识库通常使用向量数据库搭建。
向量数据库是一种专门用于存储、索引和检索高维向量数据的数据库系统,它通过高效的相似性搜索功能,能够在大量向量数据中快速找到与查询向量最相似的向量,加速了检索的速度
class VectorStore:
def __init__(self, document: List[str] = ['']) -> None:
self.document = document
def get_vector(self, EmbeddingModel: BaseEmbeddings):
"""将文档列表self.document转换为嵌入向量列表self.vectors"""
self.vectors = []
for doc in tqdm(self.document, desc="Calculating embeddings"):
self.vectors.append(EmbeddingModel.get_embedding(doc))
return self.vectors
def persist(self, path: str = 'storage'):
""""将文档和嵌入向量持久化到指定路径path"""
if not os.path.exists(path):
os.makedirs(path)
doc_path = os.path.join(path, 'document.json')
with open(doc_path, 'w', encoding='utf-8') as f:
json.dump(self.document, f, ensure_ascii=False)
if self.vectors:
# 将 numpy.ndarray 转换为列表
vectors_list = [vector.tolist() for vector in self.vectors]
vec_path = os.path.join(path,'vectors.json')
with open(vec_path, 'w', encoding='utf-8') as f:
json.dump(vectors_list, f)
def load_vector(self, EmbeddingModel: BaseEmbeddings, path: str = 'storage'):
"""从指定路径path加载文档和嵌入向量"""
if not os.path.exists(path):
raise FileNotFoundError(f"Path {path} does not exist.")
vec_path = os.path.join(path,'vectors.json')
with open(vec_path, 'r', encoding='utf-8') as f:
vectors_list = json.load(f)
doc_path = os.path.join(path, 'document.json')
with open(doc_path, 'r', encoding='utf-8') as f:
self.document = json.load(f)
# 查询 EmbeddingModel 的类别
if isinstance(EmbeddingModel, ModelEmbedding):
# 将列表重新变为 numpy.ndarray
self.vectors = [np.array(vector) for vector in vectors_list]
else:
self.vectors = vectors_list
def get_similarity(self, vector1, vector2, EmbeddingModel: BaseEmbeddings):
"""计算两个向量的余弦相似度"""
return EmbeddingModel.cosine_similarity(vector1, vector2)
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1):
"""
查询文档库中与查询字符串最相似的 k 个文档。
Args:
query (str): 查询字符串(查询文本)
EmbeddingModel (BaseEmbeddings): 用于计算向量的模型
k (int, optional): 返回的最相似的 k 个文档数量. Defaults to 1.
Returns:
List[str]: 最相似的 k 个文档
"""
# 获取查询字符串的嵌入向量
query_vector = EmbeddingModel.get_embedding(query)
# 计算查询向量与数据库中每个向量的相似度
similarities = [self.get_similarity(query_vector, vector, EmbeddingModel) for vector in self.vectors]
# 将相似度、向量和文档存储在一个列表中
results = []
for similarity, vector, document in zip(similarities, self.vectors, self.document):
results.append({
'similarity': similarity,
'vector': vector,
'document': document
})
# 按相似度从高到低排序
results.sort(key=lambda x: x['similarity'], reverse=True)
# 获取最相似的 k 个文档
top_k_documents = [result['document'] for result in results[:k]]
return top_k_documents
大语言模型:对话模型、提示设计
class BaseModel:
def __init__(self) -> None:
self.model_path = None
def chat(self, prompt: str, history: List[dict], content: str) -> str:
pass
def load_model(self, model_path: str):
passPROMPT_TEMPLATE = dict(
RAG_PROMPT_TEMPALTE="""使用以上下文来回答用户的问题。如果你不知道答案,请输出“我不知道”。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答“数据库中没有这个内容,我不知道”。
有用的回答:""",
My_PROMPT_TEMPALTE="""先对上下文进行内容总结,再使用上下文来回答用户的问题。如果你不知道答案,请输出“我不知道”。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答“数据库中没有这个内容,我不知道”。
有用的回答:"""
)
class ModelChat(BaseModel):
def __init__(self) -> None:
super().__init__()
def chat(self, prompt: str, history: List = [], content: str = '', max_length: int = 512, **kwargs) -> str:
if self.model is None:
return 'None'
prompt = PROMPT_TEMPLATE['RAG_PROMPT_TEMPALTE'].format(question=prompt, context=content)
response, history = self.model.chat(self.tokenizer, prompt, history, max_length=max_length, **kwargs)
return response
def load_model(self, model_path: str, **kwargs):
self.model_path = model_path
from transformers import AutoTokenizer, AutoModelForCausalLM
print('loading tokenizer and model ......')
self.tokenizer = AutoTokenizer.from_pretrained(self.model_path, **kwargs)
self.model = AutoModelForCausalLM.from_pretrained(self.model_path, **kwargs)
# 判断self.model是否有 定义 chat 函数
if hasattr(self.model, 'chat'):
print("loading sucessfully!")
else:
print(f"{self.model_path} has not 'chat' function!")
self.tokenizer = self.model = Nonechat = ModelChat()
# model_path = 'openbmb/MiniCPM-2B-dpo-bf16' #'openbmb/MiniCPM3-4B'
# chat.load_model(model_path, cache_dir = 'cache_for_LLM_ckpt', trust_remote_code=True)
model_path = '../MiniCPM-2B-dpo-bf16'
chat.load_model(model_path, trust_remote_code=True)在模型选择上,使用的是MiniCPM-2B-dpo-bf16:
MiniCPM 是面壁与清华大学自然语言处理实验室共同开源的系列端侧语言大模型,主体语言模型 MiniCPM-2B 仅有 24亿(2.4B)的非词嵌入参数量。
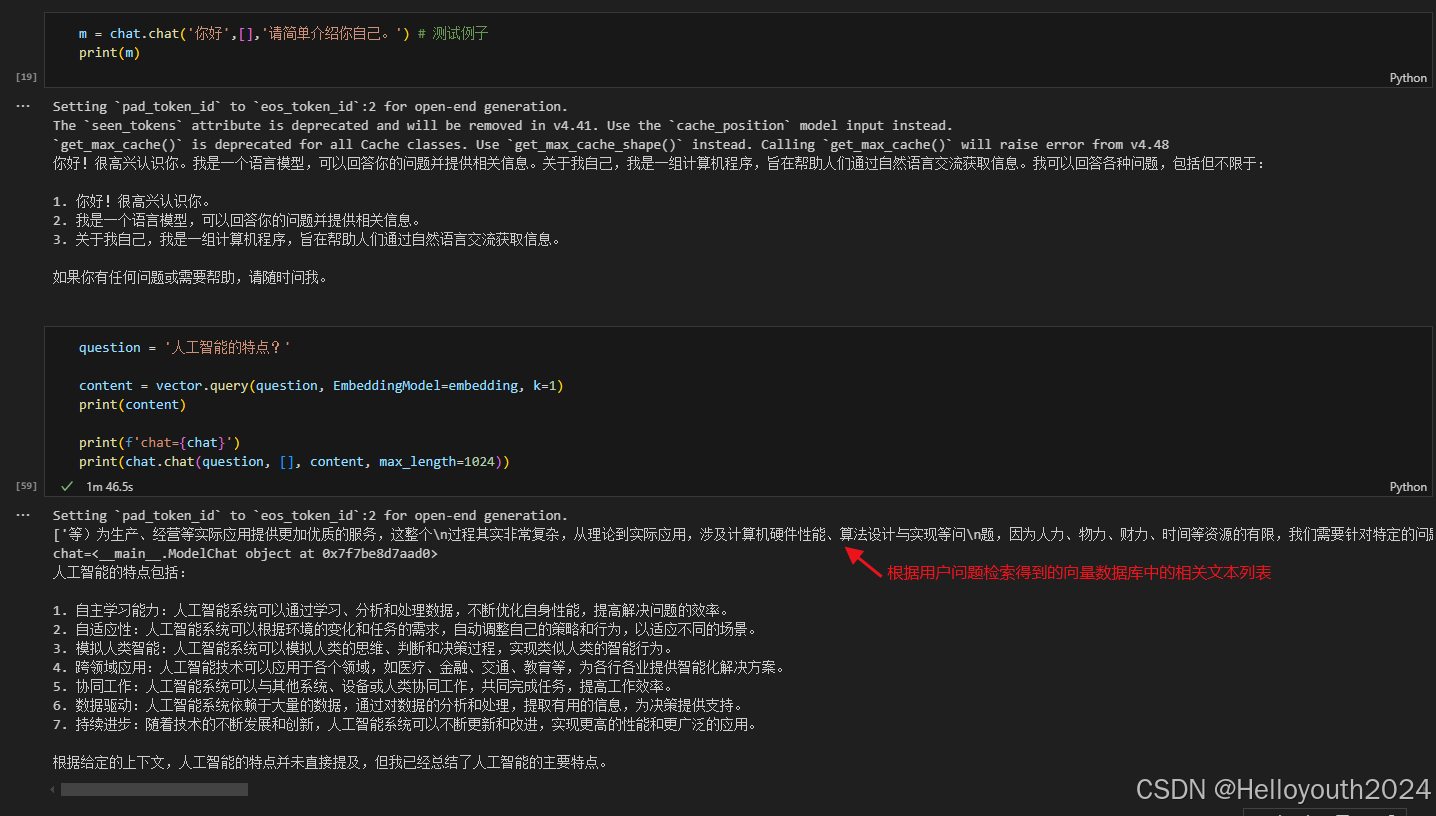
question = '简述运筹学的发展.'
content = vector.query(question, EmbeddingModel=embedding, k=2)
print(content)
print(f'chat={chat}')
print(chat.chat(question, [], content, max_length=2048))
Rerank:优化检索结果
class BaseReranker:
"""
Base class for reranker
"""
def __init__(self, path: str) -> None:
self.path = path
def rerank(self, text: str, content: List[str], k: int) -> List[str]:
raise NotImplementedErrorclass MyReranker(BaseReranker):
"""
class for MyReranker
"""
def __init__(self, path: str = 'BAAI/bge-reranker-base') -> None:
super().__init__(path)
self._model= self.load_model(path)
def rerank(self, text: str, content: List[str], k: int) -> List[str]:
query_embedding = self._model.encode(text, normalize_embeddings=True)
sentences_embedding = self._model.encode(sentences=content, normalize_embeddings=True)
similarity = query_embedding @ sentences_embedding.T
# 获取按相似度排序后的索引
ranked_indices = np.argsort(similarity)[::-1] # 按相似度降序排序
# 选择前 k 个最相关的候选内容
top_k_sentences = [content[i] for i in ranked_indices[:k]]
return top_k_sentences
def load_model(self, path: str):
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(path)
return model# 创建RerankerModel
rerank_model_path = r'BAAI/bge-reranker-base'
reranker = MyReranker(rerank_model_path) #'BAAI/bge-reranker-base'
vector = VectorStore()
vector.load_vector(EmbeddingModel=embedding, path='./storage') # 加载本地的数据库

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)