【SCI-Idea】从零实现知识图谱框架
知识图谱的整体框架如上,本章将一一讲解其中的步骤原理。本项目实现了一个简单的知识图谱系统,包括知识图谱的构建、图片搜索和可视化等功能。和。
一、引言
在信息爆炸的时代,如何从海量的数据中提取有价值的信息并进行有效的组织和利用,成为了亟待解决的问题。知识图谱作为一种强大的知识表示和管理工具,应运而生。它通过图的方式来表示实体之间的关系,为信息的检索、理解和推理提供了有力的支持。本文将深入探讨知识图谱的发展历程、技术原理,并结合具体的代码实现,详细介绍知识图谱在实际项目中的应用。
二、知识图谱发展历程
2.1 早期知识表示阶段
知识图谱的概念可以追溯到早期的知识表示研究。在人工智能发展的初期,研究者们就开始尝试用形式化的方法来表示知识,以便计算机能够理解和处理。最早的知识表示方法包括语义网络、框架系统等。
语义网络是一种用节点和边来表示概念和关系的图结构。例如,“猫”和“动物”之间可以用一条“是一种”的边来连接,表示猫是动物的一种。框架系统则是一种结构化的知识表示方法,它将知识表示为一组框架,每个框架包含多个槽,每个槽又可以有不同的值。这些早期的知识表示方法为知识图谱的发展奠定了基础。
2.2 万维网时代的发展
随着万维网的普及,信息的规模急剧增长。为了更好地组织和利用这些信息,研究者们开始探索如何将知识表示与互联网结合起来。在这个时期,出现了一些重要的项目,如WordNet和Cyc。
WordNet是一个基于语义的英语词汇数据库,它将单词按照语义关系组织成一个网络。例如,“汽车”和“轿车”、“卡车”等词之间存在着上下位关系。WordNet为自然语言处理和信息检索提供了重要的资源。
Cyc是一个大规模的常识知识库,它试图将人类的常识知识形式化并存储在计算机中。Cyc项目的目标是让计算机能够像人类一样理解和处理自然语言,进行推理和决策。
2.3 知识图谱的正式提出
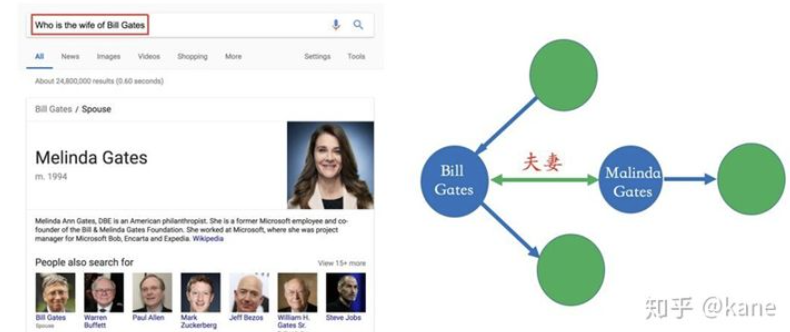
2012年,谷歌正式提出了知识图谱的概念,并将其应用于搜索引擎中。谷歌知识图谱通过整合大量的结构化数据,为用户提供更加准确和丰富的搜索结果。例如,当用户搜索“苹果公司”时,谷歌知识图谱不仅会显示苹果公司的基本信息,还会展示与苹果公司相关的人物、产品、事件等信息。
谷歌知识图谱的成功应用,引起了学术界和工业界的广泛关注。此后,知识图谱技术得到了快速发展,越来越多的企业和研究机构开始投入到知识图谱的研究和应用中。
2.4 知识图谱的广泛应用
随着技术的不断进步,知识图谱的应用领域也越来越广泛。除了搜索引擎之外,知识图谱还被应用于智能问答、推荐系统、金融风控、医疗诊断等领域。
在智能问答系统中,知识图谱可以为问题提供准确的答案。例如,当用户询问“谁是《红楼梦》的作者”时,智能问答系统可以通过知识图谱快速找到答案。
在推荐系统中,知识图谱可以帮助系统更好地理解用户的兴趣和偏好,从而提供更加个性化的推荐。例如,根据用户的历史购买记录和知识图谱中的商品关系,推荐系统可以为用户推荐相关的商品。
三、知识图谱的技术介绍
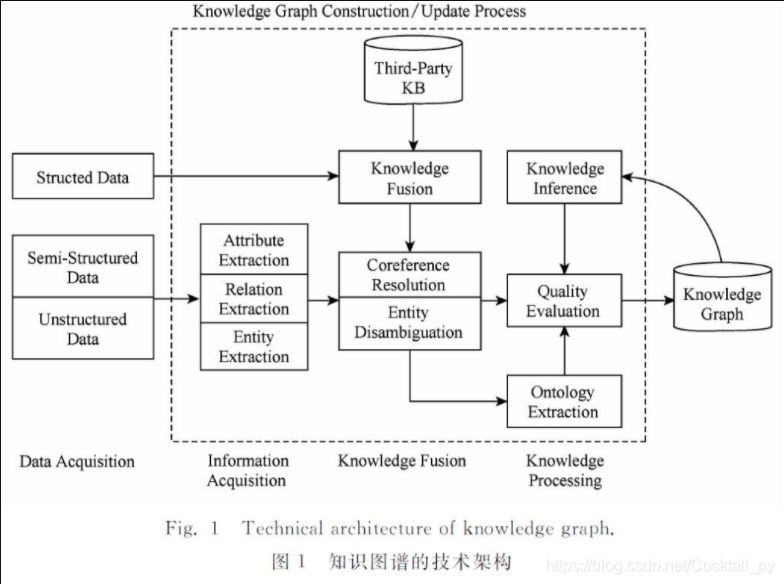
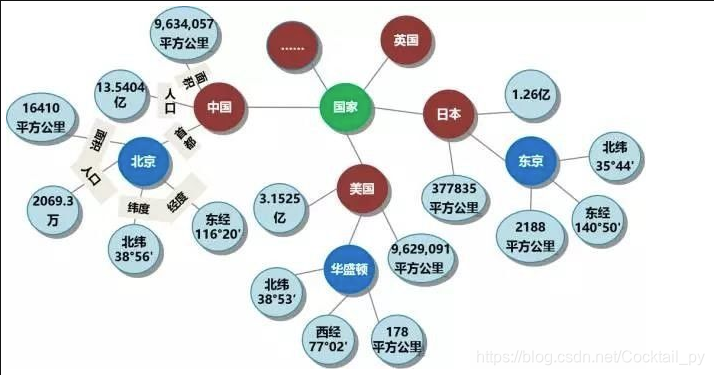
知识图谱的整体框架如上,本章将一一讲解其中的步骤原理。
3.1 知识图谱的基本概念
知识图谱是一种基于图的数据结构,它由节点(实体)和边(关系)组成。节点表示现实世界中的实体,如人、组织、事物等;边表示实体之间的关系,如“是一种”、“属于”、“位于”等。
例如,一个简单的知识图谱可以表示为:
(苹果公司) -[总部位于]-> (加利福尼亚州)
(苹果公司) -[生产]-> (iPhone)
在这个知识图谱中,“苹果公司”、“加利福尼亚州”和“iPhone”是节点,“总部位于”和“生产”是边。
3.2 知识表示
知识表示是知识图谱的核心技术之一,它的目的是将现实世界中的知识以计算机能够理解和处理的形式表示出来。常见的知识表示方法包括三元组、RDF(Resource Description Framework)和OWL(Web Ontology Language)。
三者的示例如下:
# 三元组示例
triplet = ("OpenAI", "developed", "GPT-4")
# RDF表示(带命名空间)
@prefix ex: <http://example.org/>.
ex:OpenAI ex:developed ex:GPT-4.
# OWL本体定义
Class: LLM
SubClassOf: AI_Model
EquivalentTo:
hasTrainingData some BigData
3.2.1 三元组
三元组是知识图谱中最基本的知识表示形式,它由主语(Subject)、谓语(Predicate)和宾语(Object)组成,通常表示为 (S, P, O)。例如,(苹果公司, 生产, iPhone) 就是一个三元组,表示苹果公司生产了iPhone。
3.2.2 RDF

RDF是一种用于描述资源的标准语言,它基于三元组的概念,使用URI(Uniform Resource Identifier)来表示实体和关系。例如,一个RDF三元组可以表示为:
<http://example.org/Apple> <http://example.org/produces> <http://example.org/iPhone>
在这个RDF三元组中,<http://example.org/Apple> 表示苹果公司,<http://example.org/produces> 表示生产关系,<http://example.org/iPhone> 表示iPhone。
3.2.3 OWL
OWL是一种用于描述本体的语言,它在RDF的基础上增加了更多的语义表达能力。本体是对特定领域的概念和关系的形式化描述,它可以帮助计算机更好地理解和推理知识。例如,OWL可以定义类、属性、实例等概念,以及它们之间的关系。
3.3 知识抽取
知识抽取是从各种数据源中提取知识的过程,它是构建知识图谱的重要步骤。常见的知识抽取方法包括实体识别、关系抽取和事件抽取。
3.3.1 实体识别
实体识别是指从文本中识别出实体的过程,它的任务是确定文本中哪些词或短语表示实体,并将其分类到不同的实体类型中。例如,在文本“苹果公司发布了新款iPhone”中,“苹果公司”和“iPhone”是实体,它们分别属于“组织”和“产品”类型。
3.3.2 关系抽取
关系抽取是指从文本中识别出实体之间关系的过程,它的任务是确定两个或多个实体之间的语义关系。例如,在文本“苹果公司生产了iPhone”中,“苹果公司”和“iPhone”之间存在“生产”关系。
3.3.3 事件抽取
事件抽取是指从文本中识别出事件的过程,它的任务是确定文本中描述的事件,并抽取事件的相关信息,如事件的主体、客体、时间、地点等。例如,在文本“2023年9月,苹果公司在加利福尼亚州发布了新款iPhone”中,“苹果公司发布新款iPhone”是一个事件,“苹果公司”是事件的主体,“新款iPhone”是事件的客体,“2023年9月”是事件的时间,“加利福尼亚州”是事件的地点。
3.4 知识推理
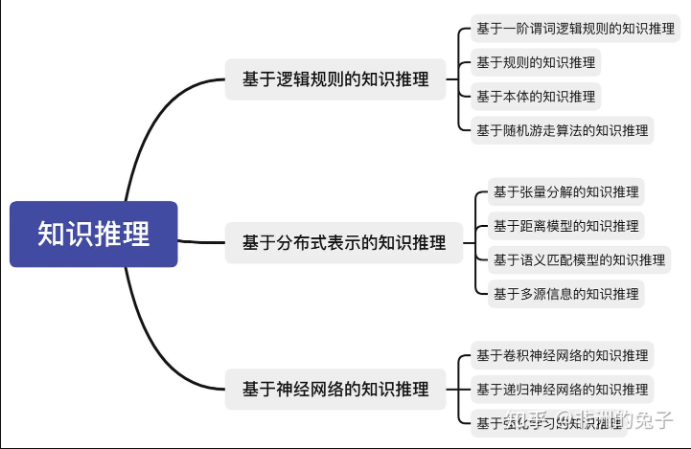
知识推理是指利用已有的知识推导出新的知识的过程,它是知识图谱的重要应用之一。常见的知识推理方法包括基于规则的推理、基于本体的推理和基于机器学习的推理。
3.4.1 基于规则的推理
基于规则的推理是指利用预先定义的规则来推导出新的知识的过程。例如,如果定义了规则“如果A是B的父亲,B是C的父亲,那么A是C的祖父”,那么当知识图谱中存在 (A, 父亲, B) 和 (B, 父亲, C) 两个三元组时,就可以推导出 (A, 祖父, C) 这个新的三元组。
3.4.2 基于本体的推理
基于本体的推理是指利用本体的语义信息来推导出新的知识的过程。例如,在OWL本体中,如果定义了“人”是“动物”的子类,那么当知识图谱中存在 (张三, 是一种, 人) 这个三元组时,就可以推导出 (张三, 是一种, 动物) 这个新的三元组。
3.4.3 基于机器学习的推理
基于机器学习的推理是指利用机器学习算法来学习知识图谱中的模式和规律,并推导出新的知识的过程。例如,可以使用深度学习模型来学习知识图谱中的嵌入表示,然后利用这些嵌入表示来进行推理。
3.5 知识图谱的用途
知识图谱具有广泛的用途,主要包括以下几个方面:
3.5.1 信息检索
知识图谱可以为信息检索提供更加准确和丰富的结果。通过将搜索关键词与知识图谱中的实体和关系进行匹配,可以找到与关键词相关的所有信息,并以结构化的方式展示给用户。
3.5.2 智能问答
知识图谱可以为智能问答系统提供准确的答案。当用户提出问题时,智能问答系统可以通过知识图谱进行推理和查询,找到问题的答案。
3.5.3 推荐系统
知识图谱可以帮助推荐系统更好地理解用户的兴趣和偏好,从而提供更加个性化的推荐。通过分析用户的历史行为和知识图谱中的实体关系,推荐系统可以为用户推荐相关的商品、文章、电影等。
3.5.4 决策支持
知识图谱可以为决策支持系统提供全面的信息和分析。通过整合多个数据源的知识,知识图谱可以帮助决策者更好地了解问题的背景和相关因素,从而做出更加明智的决策。
四、以项目引领知识图谱代码的实现
4.1 项目概述
本项目实现了一个简单的知识图谱系统,包括知识图谱的构建、图片搜索和可视化等功能。项目主要由三个Python文件组成:knowledge_graph.py、image_searcher.py 和 example_usage.py。
4.2 knowledge_graph.py 代码分析
knowledge_graph.py 文件实现了知识图谱的构建功能,主要包括从Markdown文件中提取图片信息、使用通义千问API分析图片、构建知识图谱并保存到JSON文件中。
import json
import re
import base64
from openai import OpenAI
class KnowledgeGraphBuilder:
def __init__(self, graph_file="knowledge_graph.json"):
self.graph_file = graph_file
self.graph = self._load_graph()
self.client = OpenAI(
api_key="xxx",
base_url="xxx",
)
def _load_graph(self):
"""加载或创建新的图数据"""
try:
with open(self.graph_file, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
return {
"images": [],
"entities": [],
"relationships": []
}
def _save_graph(self):
"""保存图数据到文件"""
with open(self.graph_file, 'w', encoding='utf-8') as f:
json.dump(self.graph, f, ensure_ascii=False, indent=2)
def extract_images_from_markdown(self, content):
"""从Markdown内容中提取图片信息"""
pattern = r'!\[(.*?)\]\((.*?)\)'
return re.findall(pattern, content)
def get_image_context(self, content, image_url):
"""获取图片的上下文信息"""
pos = content.find(image_url)
if pos == -1:
return ""
start = max(0, pos - 300)
end = min(len(content), pos + 300)
return content[start:end]
def encode_image(self, image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def analyze_image_with_qwen(self, image_url, context):
"""使用通义千问API分析图片"""
# 将图片转换为base64
base64_img = self.encode_image(image_url)
# 构建提示词
prompt = (
f"请分析这张图片并以JSON格式返回以下信息:\n"
f"1. 图片类型(流程图、界面截图、代码等)\n"
f"2. 图片中的关键实体\n"
f"3. 实体之间的关系\n"
f"上下文信息:{context}\n"
f"请严格按照以下JSON格式返回:\n"
f"{{'image_type': '类型', 'entities': ['实体1', '实体2'], "
f"'relationships': [['实体1', '关系', '实体2']]}}"
)
response = self.client.chat.completions.create(
model="qwen-vl-max",
messages=[{
"role": "user",
"content": [{
"type": "text",
"text": prompt,
}, {
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_img}"
}
}],
}]
)
content = response.choices[0].message.content
if content[-1] == ".":
content = content[:-1]
try:
# 尝试解析返回的JSON
result = json.loads(content)
# 转换relationships格式以匹配原代码
result['relationships'] = [
(r[0], r[1], r[2]) for r in result['relationships']
]
return result
except json.JSONDecodeError:
# 如果解析失败,返回默认结果
return {
'image_type': 'Unknown',
'entities': [],
'relationships': []
}
def build_graph(self, data_path):
"""构建知识图谱"""
with open(data_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for item in data:
for knowledge in item['knowledge']:
content = knowledge['content']
images = self.extract_images_from_markdown(content)
for caption, image_url in images:
# 添加图片节点
image_data = {
"url": image_url,
"caption": caption,
"type": None
}
# 获取上下文并分析图片
context = self.get_image_context(content, image_url)
analysis = self.analyze_image_with_qwen(image_url, context)
# 更新图片类型
image_data["type"] = analysis["image_type"]
# 添加实体
for entity in analysis["entities"]:
if entity not in self.graph["entities"]:
self.graph["entities"].append(entity)
# 添加关系
for subject, relation, obj in analysis["relationships"]:
self.graph["relationships"].append({
"subject": subject,
"relation": relation,
"object": obj,
"image_url": image_url
})
self.graph["images"].append(image_data)
self._save_graph()
- 初始化:
__init__方法初始化知识图谱构建器,加载或创建知识图谱数据,并初始化OpenAI客户端。 - 加载和保存图数据:
_load_graph方法用于加载已有的知识图谱数据,如果文件不存在则创建一个新的空图;_save_graph方法用于将知识图谱数据保存到JSON文件中。 - 图片信息提取:
extract_images_from_markdown方法使用正则表达式从Markdown内容中提取图片信息,返回图片的标题和URL。 - 图片上下文获取:
get_image_context方法获取图片的上下文信息,即图片前后一定范围内的文本。 - 图片编码:
encode_image方法将图片文件转换为Base64编码的字符串。 - 图片分析:
analyze_image_with_qwen方法使用通义千问API分析图片,获取图片的类型、关键实体和实体之间的关系。 - 知识图谱构建:
build_graph方法从JSON文件中读取数据,提取图片信息,分析图片,将图片、实体和关系添加到知识图谱中,并保存到JSON文件中。
4.3 image_searcher.py 代码分析
image_searcher.py 文件实现了图片搜索和知识
点击【SCI-Idea】从零实现知识图谱框架查看全文

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)