mysql中不等于到底走不走索引?实测记录
很多人疑惑!=到底走不走索引, 这里可以肯定的说该操作是可以走索引的,但实际情况中都为啥都不走索引呢? 首先我们要知道走索引与数据量和数据趋势(cardinality)有很大的关系,如果表本身就上百条记录,那走索引和表扫描区别不大,甚至在存在书签跳转情况下还不如表扫描更有效率,这个时候可能是不走索引的我们来看看个例子:CREATE TABLE `b` (`id` int(11) NOT NULL
·
很多人疑惑!= 到底走不走索引, 这里可以肯定的说该操作是可以走索引的,但实际情况中都为啥都不走索引呢? 首先我们要知道走索引与数据量和数据趋势(cardinality)有很大的关系,如果表本身就上百条记录,那走索引和表扫描区别不大,甚至在存在书签跳转情况下还不如表扫描更有效率,这个时候可能是不走索引的
我们来看看个例子:
CREATE TABLE `b` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` bigint(20) DEFAULT 50,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB
insert into b (name) values('a'),('b'),('c'),('d'),('e'),('f'),('g'),('h'),('i');
--多次执行
insert into b (name)
select 'k' from b ;
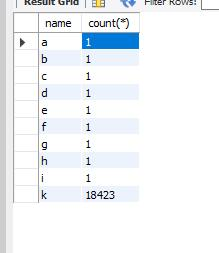
select name, count(*)
from b
group by name
explain select * From b where name !='k';

explain select * From b where name !='a';

很明显 我们从统计中看到 K的数值很大,所以我们!='k’的数据集才8条,在总数据中占比很小,可以很好的走索引,而如果将k替换成 a,则不会走索引,变成了全表扫描
个人总结:
!=操作后获取的结果集在总结果集中占据的比例也是关键因素,如果返回的结果集过大(大于20%),那么可能也不会走索引,而是选择更有效率的表扫描了

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)