数据结构--哈希表
/定义节点类型//表示哈希表数组每个元素是节点类型//函数声明//哈希表初始化//插入数据//查找数据//删除数据//除留余数法。
·
概念
通过哈希函数,直接对关键字进行映射访问的表称之为哈希表
哈希表需要解决的两个问题
映射函数--------Hash函数(除留余数法)
冲突解决--------链地址法
解决冲突的方式
##闭散列(开放定址法)
闭散列–所有数据在封闭空间内进行定位存储,不增加新的存储空间
1.线性探测-思路简单,但容易产生元素堆积
2.平方探测法-可以有效解决元素堆积问题,但只能探测一半空间,空间利用率不高
3.双散列法-是利用伪随机探测思路的方法,跳跃式的探测,失败概率不好计算
##开散列
开散列(拉链法)-数据冲突时,申请新的空间进行存储数据
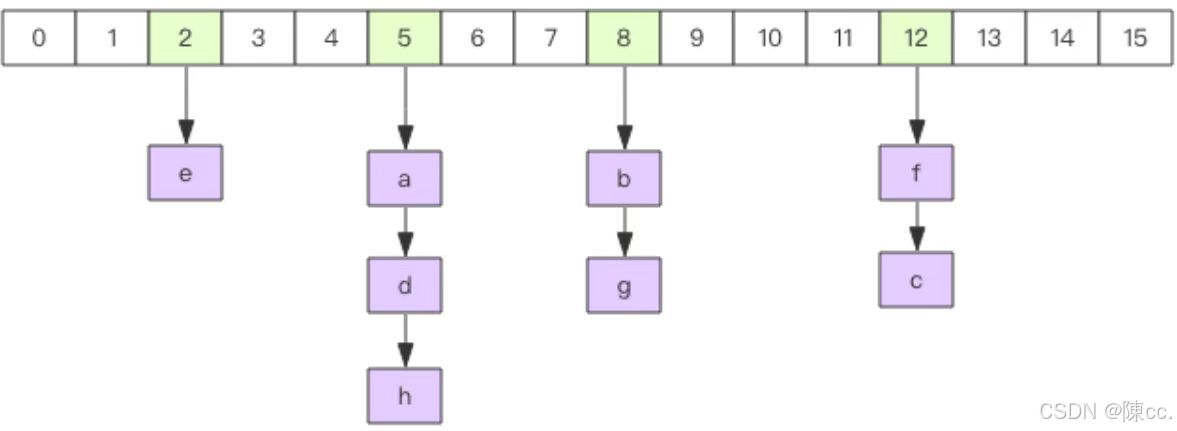
哈希表定义
//定义节点类型
struct HashNode
{
ElemType data;
struct HashNode* next;
};
typedef HashNode* hashtable[SIZE];//表示哈希表数组每个元素是节点类型
//函数声明
//哈希表初始化
void InitHash(hashtable h);
//插入数据
void Inserthash(hashtable h, ElemType x);
//查找数据
HashNode* Findhash(hashtable h, ElemType key);
//删除数据
void Deletehash(hashtable h, ElemType key);
//除留余数法
int Hash(ElemType x);
void Printhash(hashtable h);
哈希表实现
void InitHash(hashtable h)
{
for (int i = 0; i < SIZE; i++)
{
h[i] = NULL;
}
}
//除留余数法
int Hash(ElemType x)
{
return x % SIZE;
}
void Inserthash(hashtable h, ElemType x)
{
//计算索引(hash映射过程)
int idx = Hash(x);//计算数据所对应的下标
//插入数据 采用头插(效率会更高) 尾插浪费空间
HashNode* s = (HashNode*)malloc(sizeof(HashNode));
assert(s != NULL);
s->data = x;
s->next = h[idx];
h[idx] =s;
}
//查找数据
HashNode* Findhash(hashtable h, ElemType key)
{
int idx = Hash(key);
HashNode* p = h[idx];//找到所查数据的头结点
while (p != NULL && p->data != key)
{
p = p->next;
}
return p;
}
//删除数据
void Deletehash(hashtable h, ElemType key)
{
HashNode* p = Findhash(h, key);
if (p == NULL)
return;
//寻找前驱节点
int idx = Hash(key);
HashNode* pre = h[idx];
if (pre == p)
{
h[idx] = p->next;
}
else
{
while (pre->next != p)
{
pre = pre->next;
}
pre->next = p->next;
}
free(p);
}
#总结
Hsah表采用拉链式存储结构,除留得到的余数相同时采用头插方法链接起来,解决了元素堆积问题,空间灵活,数据冲突是就直接申请新的空间。
加油加油加油加油加油加油!!!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)