一文搞懂大模型的RAG(知识库和知识图谱)
RAG(检索增强生成)技术融合了信息检索与文本生成,通过动态检索外部知识库解决大模型的"幻觉"问题。其核心流程包括检索相关文档、将结果作为上下文输入、生成最终答案。文章详细介绍了RAG的知识库构建方法(文本分块与向量化)和知识图谱应用(实体关系抽取与图谱索引),并提供了Prompt+RAG的实战策略,如多路召回技术和结构化输入设计。为帮助读者深入理解,文章还分享了大模型学习路线
一文搞懂大模型的RAG(知识库和知识图谱)
原创 AllenTang 架构师带你玩转AI 2025年06月13日 22:34 湖北
*RAG(Retrieval-Augmented Generation,检索增强生成)是一种将检索与生成协同结合的技术。当大模型(如DeepSeek、Qwen、GPT)需要生成文本时,会先从外部知识库中检索相关信息,再基于检索到的内容生成答案。*
*在知识库的构建过程中,RAG通过向量数据库和动态更新机制,实现了高效的知识检索与内容生成;而在知识图谱的构建中,RAG则借助GraphRAG、Graphusion等框架,实现了实体关系的精准抽取与图谱的深度融合。*
**一、RAG****
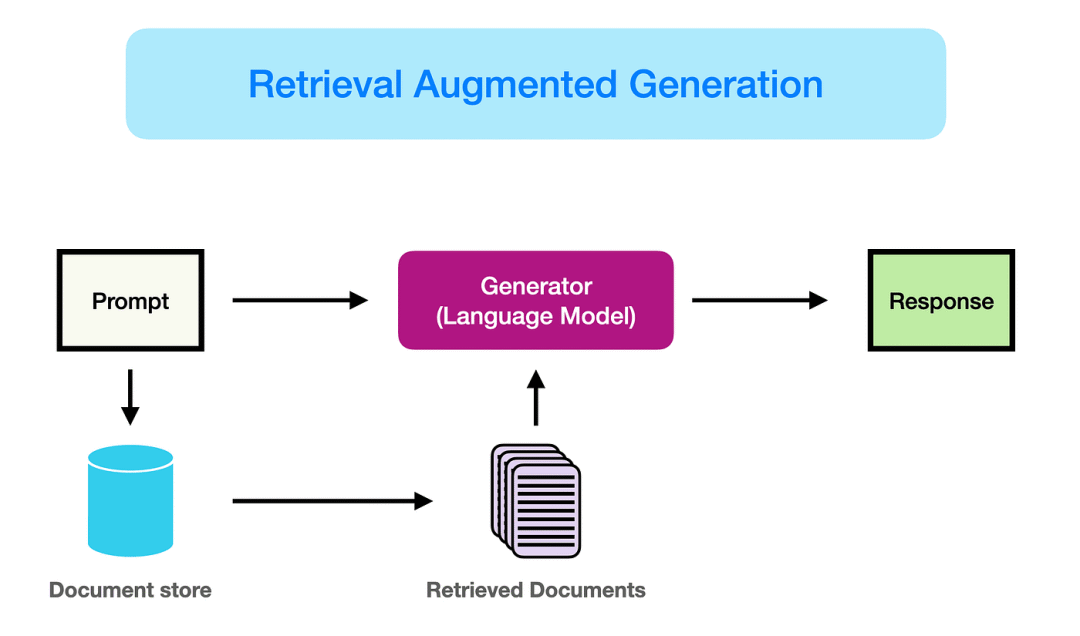
******RAG(Retrieval-Augmented Generation,检索增强生成)是什么******?***RAG是一种结合信息检索与文本生成的人工智能技术,旨在通过引入外部知识库,解决大语言模型的幻觉问题。*
*RAG的核心目标是让大语言模型(LLM)在回答问题时不再仅依赖训练时的固化知识,而是动态检索最新或特定领域的资料来辅助生成答案。*
**RAG结合了信息检索与生成模型,通过以下三阶段工作:****检索:从外部知识库(如文档、数据库)中搜索与问题相关的信息。****增强:将检索结果作为上下文输入,辅助生成模型理解问题背景。****生成:基于检索内容和模型自身知识,生成连贯、准确的回答。****
* *
*
**Prompt + RAG 如何实战?结合 Prompt 工程与 RAG(检索增强生成) 的实战应用需围绕数据准备、检索优化、生成控制等环节展开。****
一、数据准备与向量化
\1. 文档预处理与分块
文档预处理通过多模态数据清洗、词形还原与依存句法分析实现文本规范化;分块环节采用递归分割与语义边界识别技术,结合知识图谱关联优化,构建动态重叠的上下文连贯单元,以平衡检索效率与信息完整性。
# 依赖安装:pip install langchain langchain-text-splittersfrom langchain_text_splitters import RecursiveCharacterTextSplitter# 示例长文本(替换为实际文本)text = """自然语言处理(NLP)是人工智能领域的重要分支,涉及文本分析、机器翻译和情感分析等任务。分块技术可将长文本拆分为逻辑连贯的语义单元,便于后续处理。"""# 初始化递归分块器(块大小300字符,重叠50字符保持上下文)text_splitter = RecursiveCharacterTextSplitter( chunk_size=300, chunk_overlap=50, separators=["\n\n", "\n", "。", "!", "?"] # 优先按段落/句子分界[2,4](@ref))# 执行分块chunks = text_splitter.split_text(text)# 打印分块结果for i, chunk in enumerate(chunks): print(f"Chunk {i+1}:\n{chunk}\n{'-'*50}")
\2. 向量化与存储
向量化通过Embedding模型将非结构化数据(文本、图像等)映射为高维语义向量,存储则依托专用向量数据库(如ElasticSearch的dense_vector字段、Milvus)构建高效索引(HNSW、FAISS),支持近似最近邻搜索(ANN)实现大规模向量数据的快速相似性匹配。
# 依赖安装:pip install langchain langchain-text-splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 示例长文本(替换为实际文本)
text = """自然语言处理(NLP)是人工智能领域的重要分支,涉及文本分析、机器翻译和情感分析等任务。分块技术可将长文本拆分为逻辑连贯的语义单元,便于后续处理。"""
# 初始化递归分块器(块大小300字符,重叠50字符保持上下文)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?"] # 优先按段落/句子分界[2,4](@ref)
)
# 执行分块
chunks = text_splitter.split_text(text)
# 打印分块结果
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1}:\n{chunk}\n{'-'*50}")
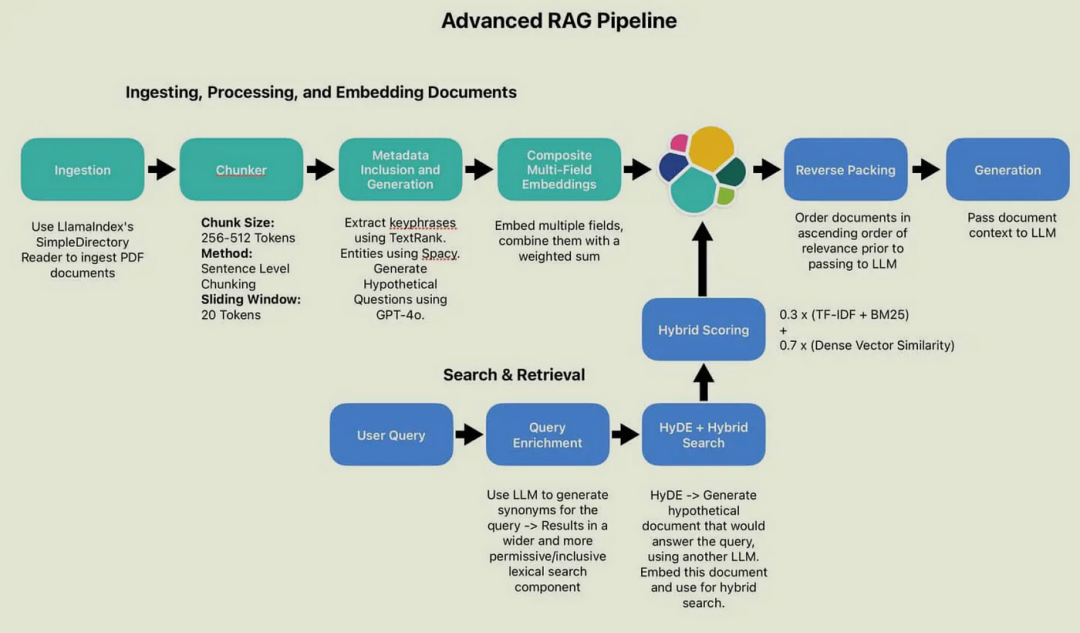
二、检索优化技术
通过多路召回(如混合检索、HyDE改写、动态重排)提升查全率与排序质量,并利用上下文增强(知识图谱补充关系、指令级RAG动态生成Prompt)优化检索结果。
三、Prompt 工程实践
\1. 结构化输入设计
基于角色和场景进行约束,例如法律顾问角色与合同条款咨询场景,结合《民法典》第580条知识单元,通过“用户问题→检索知识→逻辑关联→生成答案”的思维链,分点解释并标注引用来源。
\2. 输出模版控制
通过预设模板化输出框架确保格式规范,并设置动态防护栏机制过滤敏感词与校验事实一致性,实现内容生成的安全性与合规性。
**二、知识库和知识图谱
**
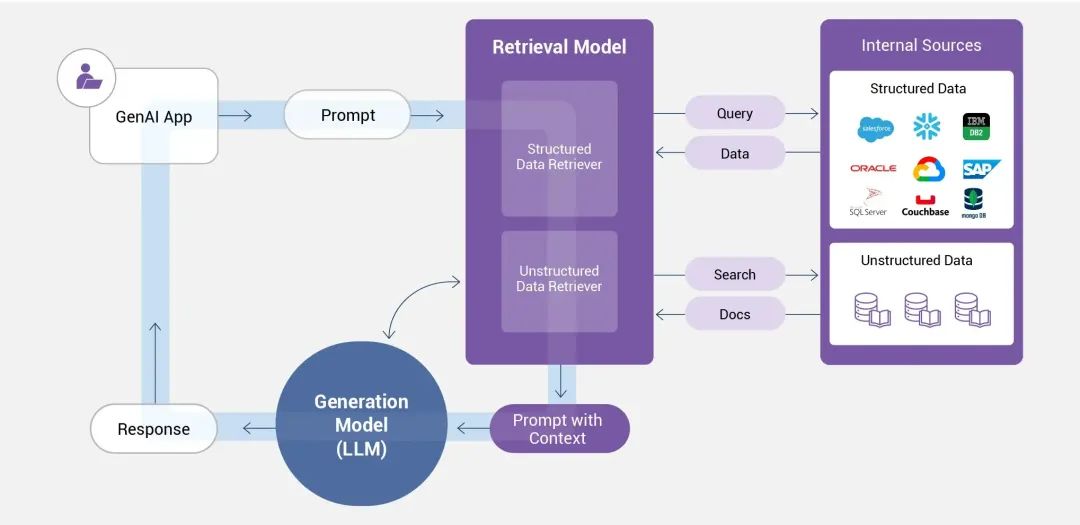
****知识库(Knowledge Base)是什么?****知识库是结构化、易操作的知识集群,通过系统性整合领域相关知识(如理论、事实、规则等),为问题求解、决策支持和知识共享提供基础平台。
RAG构建知识库的核心在于将外部知识检索与大语言模型生成能力结合,通过高效检索为生成提供上下文支持,从而提升答案的准确性和时效性。****(实战的重点在文本分块Chunking和向量化Embedding)
1. 文本分块(Chunking)
文本分块是将长文本分割为较小、可管理的片段,以便更高效地处理和分析。
2. 向量化(Embedding)
向量化是将文本或数据映射为高维向量空间中的数值表示,以捕获语义特征。
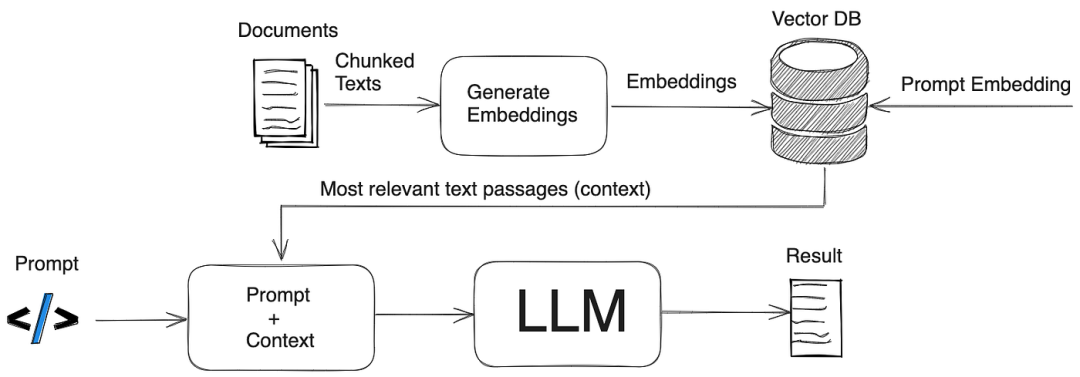
**知识图谱(Knowledge Graph)是什么?**知识图谱是一种通过实体与关系构建的语义化网络结构,支持推理与复杂查询,而传统知识库多以非关联的扁平化方式存储数据。
RAG构建知识图谱的核心是通过结合检索技术与大语言模型(LLM),将外部知识库中的结构化与非结构化数据整合为图谱形式。知识图谱为RAG系统注入结构化推理能力,使其从“信息检索器”进化为“知识推理引擎”。
RAG构建知识图谱的关键在于检索与生成的协同**,其流程包括:**
- *数据预处理:将文档分割为文本块(chunking),**并通过命名实体识别(NER)提取实体与关系**。***
- *知识图谱索引:基于提取的实体与关系,构建初始知识图谱后,运用聚类算法(例如Leiden算法)对图谱中的节点进行社区划分。*
- *检索增强:在用户查询时,通过本地搜索(基于实体)或全局搜索(基于数据集主题)增强上下文,提升生成答案的准确性。*

读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)