计算机视觉实战——智能图像去噪工具
本文介绍了一个智能图像去噪工具,该工具集成多种传统和深度学习的去噪算法。核心功能包括:支持3种噪声类型(高斯、椒盐、泊松)模拟,提供16种去噪方法(均值/中值/高斯滤波、非局部均值、ROF、总变分等传统方法,以及DnCNN、UNet、LSTM等深度学习模型),具备图像质量评估(PSNR、SSIM、MSE)和自适应参数调整功能。工具采用Python实现,包含GUI界面,支持多方法对比分析和批量处理。
目录
5. ROF 去噪(Rudin-Osher-Fatemi Denoising)
6. 总变分去噪(Total Variation Denoising)
8. 各向异性扩散(Anisotropic Diffusion)
9. 小波阈值去噪(Wavelet Thresholding)
1. DnCNN(Denoising Convolutional Neural Network)
2. 椒盐噪声(Salt-and-Pepper Noise)
一、核心功能概述
本文实现一个集成多种传统与深度学习去噪算法的图像去噪工具,支持噪声添加、自适应参数调整、多方法对比及量化评估。核心功能包括:
- 多种噪声类型模拟(高斯、椒盐、泊松)
- 16 种去噪算法(传统方法 + 深度学习模型)
- 图像质量评估(PSNR、SSIM、MSE)
- 自适应参数优化与批量对比
二、传统去噪算法原理与实现
1. 均值滤波(Mean Filter)
原理:用像素邻域内所有像素的平均值替换中心像素,平滑噪声。
数学公式:
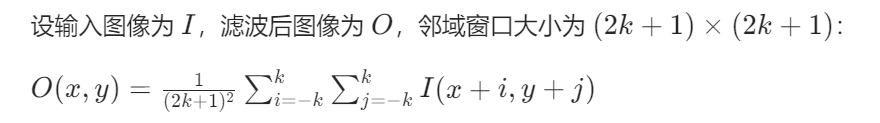
实现步骤:
def mean_filter(image, size=3):
return image.filter(ImageFilter.BoxBlur(size)) # 调用PIL的BoxBlur实现均值滤波- 支持自定义窗口大小,通过自适应参数模块动态调整(根据图像尺寸和噪声强度)。
2. 中值滤波(Median Filter)
原理:用像素邻域内所有像素的中值替换中心像素,有效抑制椒盐噪声。
数学公式: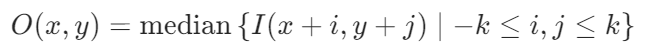
实现步骤:
def median_filter(image, size=3):
return image.filter(ImageFilter.MedianFilter(size)) # 调用PIL的中值滤波- 窗口大小需为奇数,自适应模块确保窗口不超过图像尺寸的 1/2。
3. 高斯滤波(Gaussian Filter)
原理:用高斯核加权平均邻域像素,平滑噪声的同时保留边缘。
数学公式:
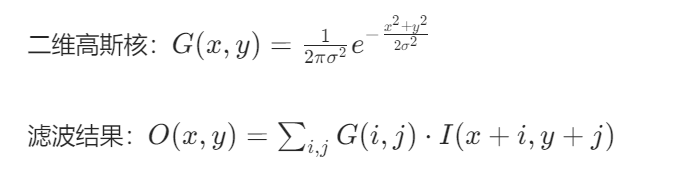
实现步骤:
def gaussian_filter_pil(image, sigma=1.0):
return image.filter(ImageFilter.GaussianBlur(radius=sigma)) # 高斯模糊实现- σ 控制平滑强度,自适应模块根据噪声强度动态调整。
4. 非局部均值滤波(Non-Local Means)
原理:通过寻找图像中相似区域(而非局部邻域)进行加权平均,保留细节的同时去噪。

实现步骤:
def non_local_means_denoise(image, h=10, template_window=7, search_window=21):
img_array = np.array(image, dtype=np.float32)
# 调用OpenCV优化实现,支持彩色/灰度图像
if len(img_array.shape) == 3: # 彩色
return Image.fromarray(cv2.fastNlMeansDenoisingColored(
img_array.astype(np.uint8), None, h, h, template_window, search_window))
else: # 灰度
return Image.fromarray(cv2.fastNlMeansDenoising(
img_array.astype(np.uint8), None, h, template_window, search_window))5. ROF 去噪(Rudin-Osher-Fatemi Denoising)
原理:基于总变分最小化的去噪方法,平衡噪声抑制与边缘保留。
数学公式:
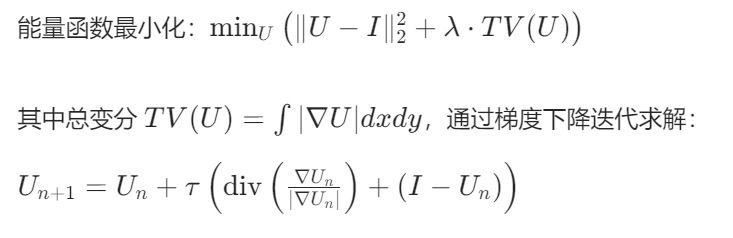
实现步骤:
def _rof_denoise_single(channel, U_init, tolerance=0.1, tau=0.125, tv_weight=100):
U = U_init.copy()
Px, Py = np.zeros_like(U), np.zeros_like(U) # 对偶变量
error = 1
while error > tolerance:
Uold = U.copy()
# 计算梯度
GradUx = np.roll(U, -1, axis=1) - U
GradUy = np.roll(U, -1, axis=0) - U
# 更新对偶变量
Px_new = Px + (tau / tv_weight) * GradUx
Py_new = Py + (tau / tv_weight) * GradUy
Norm_new = np.maximum(1, np.sqrt(Px_new**2 + Py_new**2))
Px, Py = Px_new / Norm_new, Py_new / Norm_new
# 更新原变量
DivP = (Px - np.roll(Px, 1, axis=1)) + (Py - np.roll(Py, 1, axis=0))
U = Uold + tau * (DivP + channel)
error = np.linalg.norm(U - Uold) / np.sqrt(U.size)
return U6. 总变分去噪(Total Variation Denoising)
原理:通过最小化图像总变分能量抑制噪声,保留边缘。
数学公式:
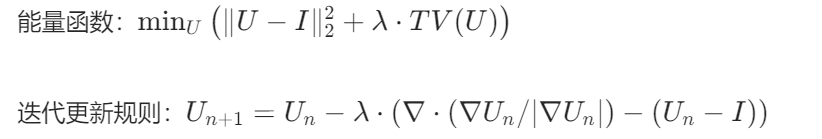
实现步骤:
def _tv_denoise_single(channel, weight=0.1):
u = channel.copy()
for _ in range(100): # 迭代优化
dx = np.roll(u, -1, axis=1) - u # 水平梯度
dy = np.roll(u, -1, axis=0) - u # 垂直梯度
div_x = np.roll(dx, 1, axis=1) # 散度计算
div_y = np.roll(dy, 1, axis=0)
u = u - weight * (div_x + div_y - channel) # 更新
return u7. 引导滤波(Guided Filter)
原理:利用引导图(通常为原图)计算局部线性模型,实现边缘保留平滑。
数学公式:

实现步骤:
def _guided_filter_single(channel, radius, eps):
mean_i = cv2.blur(channel, (radius, radius)) # 均值滤波
mean_p = cv2.blur(channel, (radius, radius))
mean_ii = cv2.blur(channel * channel, (radius, radius))
mean_ip = cv2.blur(channel * channel, (radius, radius))
var_i = mean_ii - mean_i * mean_i # 方差
cov_ip = mean_ip - mean_i * mean_p # 协方差
a = cov_ip / (var_i + eps) # 系数a
b = mean_p - a * mean_i # 系数b
return cv2.blur(a, (radius, radius)) * channel + cv2.blur(b, (radius, radius)) # 最终结果8. 各向异性扩散(Anisotropic Diffusion)
原理:根据图像梯度调整扩散强度(边缘处扩散弱,平坦区扩散强)。
数学公式:
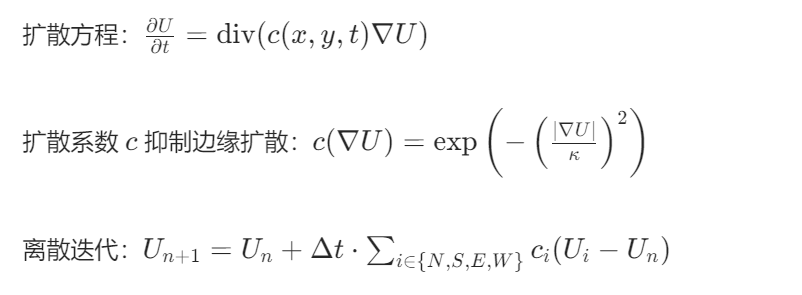
实现步骤:
def _anisotropic_diffusion_single(channel, kappa=30, iterations=10):
u = channel.copy()
for _ in range(iterations):
dx = np.roll(u, -1, axis=1) - u # 梯度
dy = np.roll(u, -1, axis=0) - u
# 扩散系数(抑制边缘)
dc_north = np.exp(-(dx / kappa)**2)
dc_south = np.exp(-(-dx / kappa)** 2)
dc_east = np.exp(-(dy / kappa)**2)
dc_west = np.exp(-(-dy / kappa)** 2)
# 更新
u += 0.25 * (dc_north*dx + dc_south*np.roll(dx,1,axis=1) +
dc_east*dy + dc_west*np.roll(dy,1,axis=0))
return u9. 小波阈值去噪(Wavelet Thresholding)
原理:通过小波变换将图像分解为低频近似和高频细节,对高频系数阈值处理后重建。
数学公式:
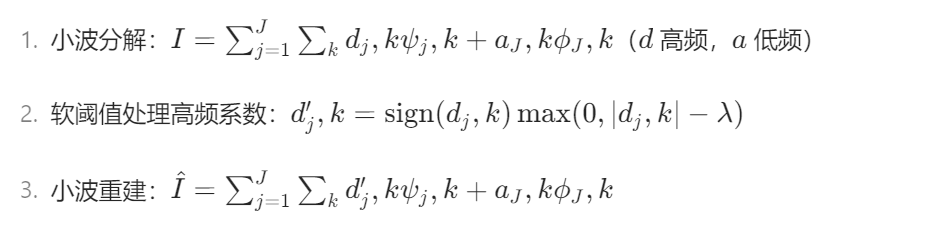
实现步骤:
def _wavelet_thresholding_denoise(image, wavelet='db4', level=2):
img_array = np.array(image, dtype=np.float32) / 255.0
denoised = np.zeros_like(img_array)
for c in range(3): # 彩色图像分通道处理
coeffs = pywt.wavedec2(img_array[..., c], wavelet, level=level) # 分解
# 高频系数阈值处理
for i in range(1, len(coeffs)):
coeffs[i] = [pywt.threshold(v, 0.1, 'soft') for v in coeffs[i]]
denoised[..., c] = pywt.waverec2(coeffs, wavelet) # 重建
return Image.fromarray((np.clip(denoised, 0, 1)*255).astype(np.uint8))10. 双边滤波(Bilateral Filter)
原理:结合空间距离权重和像素相似度权重,实现边缘保留平滑。
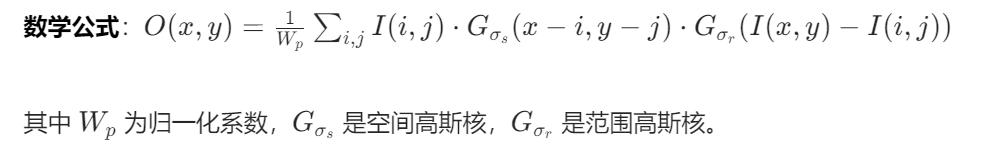
实现步骤:
def _bilateral_filter_denoise(image, diameter=9, sigma_color=75, sigma_space=75):
img_array = np.array(image)
return Image.fromarray(cv2.bilateralFilter(img_array, diameter, sigma_color, sigma_space))三、深度学习去噪模型原理与实现
1. DnCNN(Denoising Convolutional Neural Network)
原理:通过堆叠卷积层学习噪声残差(输入 = 干净图 + 噪声,输出 = 噪声)。
网络结构:
- 输入层:3×H×W(彩色图像)
- 隐藏层:15 个卷积层(64 通道,3×3 卷积,BN+ReLU)
- 输出层:3 通道卷积(无激活,输出噪声残差)
数学公式:
![]()
实现步骤:
class DnCNN(nn.Module):
def __init__(self, channels=3, num_layers=17):
super().__init__()
layers = [nn.Conv2d(channels, 64, 3, padding=1, bias=False), nn.ReLU()]
for _ in range(num_layers-2): # 中间层
layers.extend([nn.Conv2d(64,64,3,padding=1,bias=False),
nn.BatchNorm2d(64), nn.ReLU()])
layers.append(nn.Conv2d(64, channels, 3, padding=1, bias=False)) # 输出层
self.dncnn = nn.Sequential(*layers)
def forward(self, x):
return self.dncnn(x) # 输出噪声残差2. 卷积自编码器(ConvAutoEncoder)
原理:通过编码器压缩特征,解码器重建图像,利用瓶颈层抑制噪声。
网络结构:
- 编码器:3 层卷积(3→32→64→128 通道,MaxPool 下采样)
- 解码器:3 层转置卷积(128→64→32→3 通道,上采样)
- 输出激活:Sigmoid(将输出归一化到 [0,1])
数学公式:
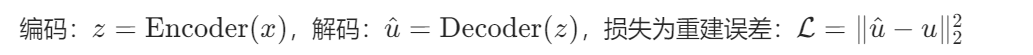
实现步骤:
class ConvAutoEncoder(nn.Module):
def __init__(self, channels=3):
super().__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(channels,32,3,padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(32,64,3,padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64,128,3,padding=1), nn.ReLU(), nn.MaxPool2d(2)
)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128,64,3,stride=2,padding=1,output_padding=1), nn.ReLU(),
nn.ConvTranspose2d(64,32,3,stride=2,padding=1,output_padding=1), nn.ReLU(),
nn.ConvTranspose2d(32,channels,3,stride=2,padding=1,output_padding=1), nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
return self.decoder(x) # 输出重建图像3. UNet 去噪(UNetDenoise)
原理:通过跳跃连接融合编码器的低级特征与解码器的高级特征,保留细节。
网络结构:
- 下采样(编码器):3 次卷积 + MaxPool(通道翻倍:3→64→128→256)
- 上采样(解码器):2 次转置卷积 + 跳跃连接(通道减半:256→128→64)
- 输出层:1×1 卷积(64→3 通道,Sigmoid 激活)
实现步骤:
class UNetDenoise(nn.Module):
def __init__(self, channels=3):
super().__init__()
self.down1 = self.double_conv(channels,64) # 双层卷积块
self.down2 = self.double_conv(64,128)
self.down3 = self.double_conv(128,256)
self.up2 = nn.ConvTranspose2d(256,128,2,stride=2) # 上采样
self.up_conv2 = self.double_conv(256,128) # 融合后卷积
self.up1 = nn.ConvTranspose2d(128,64,2,stride=2)
self.up_conv1 = self.double_conv(128,64)
self.out = nn.Conv2d(64, channels, 1) # 输出层
def double_conv(self, in_ch, out_ch): # 双层卷积
return nn.Sequential(
nn.Conv2d(in_ch, out_ch,3,padding=1), nn.ReLU(),
nn.Conv2d(out_ch, out_ch,3,padding=1), nn.ReLU()
)
def forward(self, x):
x1 = self.down1(x)
x2 = self.down2(F.max_pool2d(x1,2)) # 下采样
x3 = self.down3(F.max_pool2d(x2,2))
x = self.up2(x3) # 上采样
x = torch.cat([x, x2], dim=1) # 跳跃连接
x = self.up_conv2(x)
x = self.up1(x)
x = torch.cat([x, x1], dim=1)
x = self.up_conv1(x)
return torch.sigmoid(self.out(x))4. LSTM 去噪(LSTMDenoise)
原理:将图像行 / 列视为序列,用双向 LSTM 捕捉上下文依赖关系。
网络结构:
- 输入卷积:3→64 通道(提取空间特征)
- 双向 LSTM:处理序列特征(隐藏维度 64,2 层)
- 输出卷积:64→3 通道(重建图像)
数学公式:
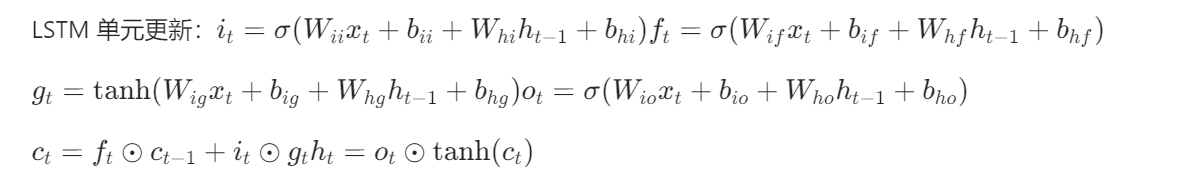
实现步骤:
class LSTMDenoise(nn.Module):
def __init__(self, channels=3, hidden_size=64, num_layers=2):
super().__init__()
self.input_conv = nn.Conv2d(channels, hidden_size, 3, padding=1) # 特征提取
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers,
batch_first=True, bidirectional=True) # 双向LSTM
self.fc = nn.Linear(hidden_size*2, hidden_size) # 融合双向输出
self.output_conv = nn.Conv2d(hidden_size, channels, 3, padding=1)
def forward(self, x):
batch, _, h, w = x.size()
x = self.input_conv(x).permute(0,2,3,1).view(batch*h, w, -1) # 转为序列
lstm_out, _ = self.lstm(x) # LSTM处理
x = self.fc(lstm_out).view(batch, h, w, -1).permute(0,3,1,2) # 转回图像格式
return torch.sigmoid(self.output_conv(x))5. GRU 去噪(GRUDenoise)
原理:简化 LSTM 的门控机制(合并遗忘门和输入门),降低计算量。
网络结构:与 LSTM 类似,用 GRU 替换 LSTM 层。
数学公式:
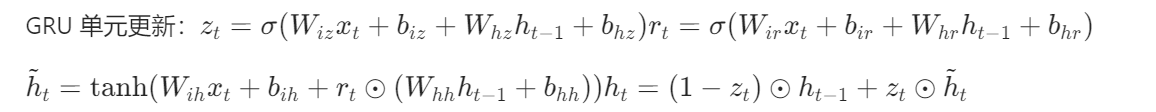
实现步骤:
class GRUDenoise(nn.Module):
def __init__(self, channels=3, hidden_size=64, num_layers=2):
super(GRUDenoise, self).__init__()
self.channels = channels
self.hidden_size = hidden_size
self.num_layers = num_layers
# 输入输出转换
self.input_conv = nn.Conv2d(channels, hidden_size, kernel_size=3, padding=1)
self.output_conv = nn.Conv2d(hidden_size, channels, kernel_size=3, padding=1)
# GRU层
self.gru = nn.GRU(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=True
)
# 中间处理
self.fc = nn.Linear(hidden_size * 2, hidden_size)
self.relu = nn.ReLU()
def forward(self, x):
batch_size, _, height, width = x.size()
# 特征提取
x = self.input_conv(x) # (batch, hidden_size, height, width)
# 转换为GRU输入格式
x = x.permute(0, 2, 3, 1).contiguous() # (batch, height, width, hidden_size)
x = x.view(batch_size * height, width, self.hidden_size)
# GRU处理
gru_out, _ = self.gru(x) # (batch*height, width, hidden_size*2)
# 处理GRU输出
x = self.fc(gru_out) # (batch*height, width, hidden_size)
x = self.relu(x)
# 转换回原始形状
x = x.view(batch_size, height, width, self.hidden_size) # (batch, height, width, hidden_size)
x = x.permute(0, 3, 1, 2).contiguous() # (batch, hidden_size, height, width)
# 输出层
x = self.output_conv(x) # (batch, channels, height, width)
return torch.sigmoid(x)
6. 自注意力去噪(AttentionDenoise)
原理:用 Transformer 自注意力机制捕捉长距离依赖,关注图像全局相似区域。
网络结构:
- 输入卷积:3→64 通道
- Transformer 编码器:2 层自注意力 + 前馈网络
- 输出卷积:64→3 通道
数学公式:
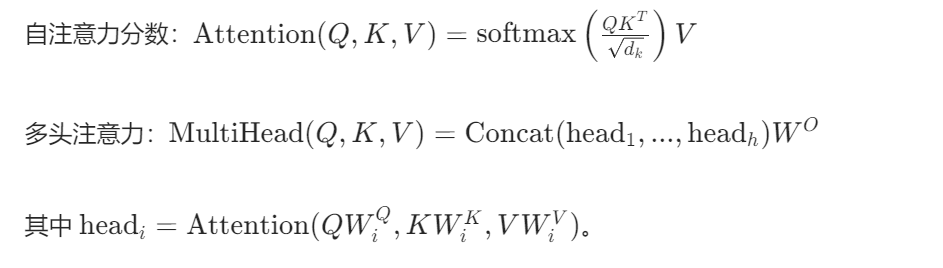
实现步骤:
class AttentionDenoise(nn.Module):
def __init__(self, channels=3, hidden_size=64, num_heads=4):
super().__init__()
self.input_conv = nn.Conv2d(channels, hidden_size, 3, padding=1)
# Transformer编码器层
encoder_layers = TransformerEncoderLayer(
d_model=hidden_size, nhead=num_heads, dim_feedforward=hidden_size*4
)
self.transformer = TransformerEncoder(encoder_layers, num_layers=2)
self.output_conv = nn.Conv2d(hidden_size, channels, 3, padding=1)
def forward(self, x):
batch, _, h, w = x.size()
x = self.input_conv(x).flatten(2).permute(2,0,1) # 转为序列 (h*w, batch, hidden)
x = self.transformer(x) # 自注意力处理
x = x.permute(1,2,0).view(batch, hidden_size, h, w) # 转回图像格式
return torch.sigmoid(self.output_conv(x))四、噪声添加算法
1. 高斯噪声(Gaussian Noise)
原理:添加符合高斯分布的随机噪声。
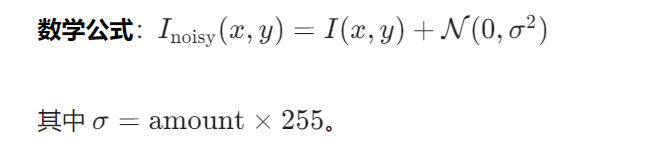
实现步骤:
def add_noise(image, noise_type='gaussian', amount=0.1):
if noise_type == 'gaussian':
noise = np.random.normal(0, amount*255, img_array.shape).astype(np.float32)
noisy_img = np.clip(img_array.astype(np.float32) + noise, 0, 255).astype(np.uint8)2. 椒盐噪声(Salt-and-Pepper Noise)
原理:随机将像素设置为最大值(盐)或最小值(椒)。
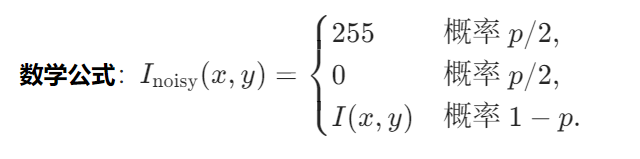
实现步骤:
elif noise_type == 'salt_pepper':
mask = np.random.rand(h, w) < amount # 噪声位置掩码
noisy_img = img_array.copy()
salt = np.where(np.random.rand(*noisy_img[mask].shape) < 0.5, 255, 0)
noisy_img[mask] = salt3. 泊松噪声(Poisson Noise)
原理:模拟光子计数噪声,符合泊松分布。
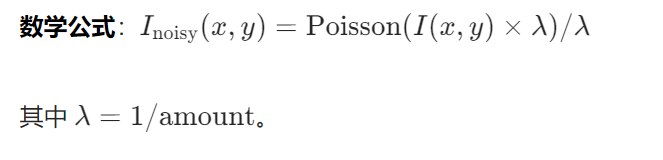
实现步骤:
elif noise_type == 'poisson':
img_float = img_array.astype(np.float32) / 255.0
noisy_img = np.random.poisson(img_float * 255 * (1/amount)) / 255 * 255
noisy_img = np.clip(noisy_img, 0, 255).astype(np.uint8)五、图像质量评估指标
1. 均方误差(MSE)
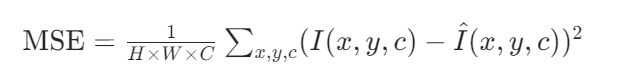
2. 峰值信噪比(PSNR)
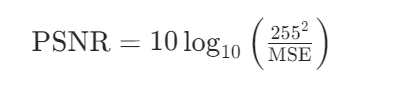
3. 结构相似性指数(SSIM)

实现步骤:
def _calculate_image_metrics(original, processed):
orig_arr = np.array(original, dtype=np.float32)
proc_arr = np.array(processed, dtype=np.float32)
mse = np.mean((orig_arr - proc_arr)** 2)
psnr_val = 20 * np.log10(255.0 / np.sqrt(mse)) if mse != 0 else float('inf')
ssim_val = ssim(orig_arr, proc_arr, data_range=255, channel_axis=2) # 彩色图像
return {'psnr': psnr_val, 'ssim': ssim_val, 'mse': mse}六、自适应参数调整
根据图像特征(边缘密度、纹理复杂度)和噪声类型动态调整算法参数:
def get_adaptive_params(image_features, noise_type, noise_amount):
params = {'mean_size':3, 'median_size':3, 'gaussian_sigma':1.0}
# 基于噪声类型调整(如椒盐噪声增大中值滤波窗口)
if noise_type == 'salt_pepper':
params['median_size'] = max(3, int(noise_amount * 12))
# 基于图像复杂度调整(边缘丰富图像减小平滑强度)
if image_features['edge_density'] > 0.1:
params['gaussian_sigma'] = min(params['gaussian_sigma'], 2.0)
return params七、GUI 实现与流程控制
- 界面布局:Tkinter 实现左侧控制面板(噪声设置、算法选择)+ 右侧图像显示(多标签页对比)。
- 多线程处理:耗时的去噪任务在子线程执行,避免 UI 卡顿。
- 批量对比:遍历所有算法,计算评估指标并生成对比图。
八、智能图像去噪工具的完整的Python代码实现
import tkinter as tk
from tkinter import filedialog, ttk, messagebox, scrolledtext
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
import matplotlib
matplotlib.use("TkAgg")
from PIL import Image, ImageTk, ImageFilter, ImageOps, ImageEnhance
import os
import sys
import csv
from datetime import datetime
import threading
import json
import cv2
# 深度学习相关库
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch.nn import TransformerEncoder, TransformerEncoderLayer
# 图像处理相关库
from skimage.metrics import structural_similarity as ssim
from skimage.metrics import peak_signal_noise_ratio as psnr
from skimage.feature import canny
from skimage.filters import threshold_otsu
from skimage import exposure
from skimage.util import random_noise
from scipy.ndimage import gaussian_filter, laplace, median_filter
import pywt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams['axes.unicode_minus'] = False
# 神经网络模型定义
class DnCNN(nn.Module):
def __init__(self, channels=3, num_layers=17):
super(DnCNN, self).__init__()
kernel_size = 3
padding = 1
features = 64
layers = []
layers.append(nn.Conv2d(channels, features, kernel_size=kernel_size, padding=padding, bias=False))
layers.append(nn.ReLU(inplace=True))
for _ in range(num_layers - 2):
layers.append(nn.Conv2d(features, features, kernel_size=kernel_size, padding=padding, bias=False))
layers.append(nn.BatchNorm2d(features))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(features, channels, kernel_size=kernel_size, padding=padding, bias=False))
self.dncnn = nn.Sequential(*layers)
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
out = self.dncnn(x)
return out
class ConvAutoEncoder(nn.Module):
def __init__(self, channels=3):
super(ConvAutoEncoder, self).__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(channels, 32, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(2, stride=2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(2, stride=2)
)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(True),
nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(True),
nn.ConvTranspose2d(32, channels, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
class UNetDenoise(nn.Module):
def __init__(self, channels=3):
super(UNetDenoise, self).__init__()
# 下采样路径
self.down1 = self.double_conv(channels, 64)
self.down2 = self.double_conv(64, 128)
self.down3 = self.double_conv(128, 256)
# 上采样路径
self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.up_conv2 = self.double_conv(256, 128)
self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.up_conv1 = self.double_conv(128, 64)
# 输出层
self.out = nn.Conv2d(64, channels, kernel_size=1)
def double_conv(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
# 下采样
x1 = self.down1(x)
x2 = F.max_pool2d(x1, 2)
x2 = self.down2(x2)
x3 = F.max_pool2d(x2, 2)
x3 = self.down3(x3)
# 上采样
x = self.up2(x3)
x = torch.cat([x, x2], dim=1)
x = self.up_conv2(x)
x = self.up1(x)
x = torch.cat([x, x1], dim=1)
x = self.up_conv1(x)
return torch.sigmoid(self.out(x))
# LSTM去噪模型
class LSTMDenoise(nn.Module):
def __init__(self, channels=3, hidden_size=64, num_layers=2):
super(LSTMDenoise, self).__init__()
self.channels = channels
self.hidden_size = hidden_size
self.num_layers = num_layers
# 输入输出转换
self.input_conv = nn.Conv2d(channels, hidden_size, kernel_size=3, padding=1)
self.output_conv = nn.Conv2d(hidden_size, channels, kernel_size=3, padding=1)
# LSTM层
self.lstm = nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=True
)
# 中间处理
self.fc = nn.Linear(hidden_size * 2, hidden_size)
self.relu = nn.ReLU()
def forward(self, x):
batch_size, _, height, width = x.size()
# 特征提取
x = self.input_conv(x) # (batch, hidden_size, height, width)
# 转换为LSTM输入格式 (batch*height, width, hidden_size)
x = x.permute(0, 2, 3, 1).contiguous() # (batch, height, width, hidden_size)
x = x.view(batch_size * height, width, self.hidden_size)
# LSTM处理
lstm_out, _ = self.lstm(x) # (batch*height, width, hidden_size*2)
# 处理LSTM输出
x = self.fc(lstm_out) # (batch*height, width, hidden_size)
x = self.relu(x)
# 转换回原始形状
x = x.view(batch_size, height, width, self.hidden_size) # (batch, height, width, hidden_size)
x = x.permute(0, 3, 1, 2).contiguous() # (batch, hidden_size, height, width)
# 输出层
x = self.output_conv(x) # (batch, channels, height, width)
return torch.sigmoid(x)
# GRU去噪模型
class GRUDenoise(nn.Module):
def __init__(self, channels=3, hidden_size=64, num_layers=2):
super(GRUDenoise, self).__init__()
self.channels = channels
self.hidden_size = hidden_size
self.num_layers = num_layers
# 输入输出转换
self.input_conv = nn.Conv2d(channels, hidden_size, kernel_size=3, padding=1)
self.output_conv = nn.Conv2d(hidden_size, channels, kernel_size=3, padding=1)
# GRU层
self.gru = nn.GRU(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=True
)
# 中间处理
self.fc = nn.Linear(hidden_size * 2, hidden_size)
self.relu = nn.ReLU()
def forward(self, x):
batch_size, _, height, width = x.size()
# 特征提取
x = self.input_conv(x) # (batch, hidden_size, height, width)
# 转换为GRU输入格式
x = x.permute(0, 2, 3, 1).contiguous() # (batch, height, width, hidden_size)
x = x.view(batch_size * height, width, self.hidden_size)
# GRU处理
gru_out, _ = self.gru(x) # (batch*height, width, hidden_size*2)
# 处理GRU输出
x = self.fc(gru_out) # (batch*height, width, hidden_size)
x = self.relu(x)
# 转换回原始形状
x = x.view(batch_size, height, width, self.hidden_size) # (batch, height, width, hidden_size)
x = x.permute(0, 3, 1, 2).contiguous() # (batch, hidden_size, height, width)
# 输出层
x = self.output_conv(x) # (batch, channels, height, width)
return torch.sigmoid(x)
# 自注意力去噪模型
class AttentionDenoise(nn.Module):
def __init__(self, channels=3, hidden_size=64, num_heads=4):
super(AttentionDenoise, self).__init__()
self.channels = channels
self.hidden_size = hidden_size
# 输入输出转换
self.input_conv = nn.Conv2d(channels, hidden_size, kernel_size=3, padding=1)
self.output_conv = nn.Conv2d(hidden_size, channels, kernel_size=3, padding=1)
# 自注意力层
encoder_layers = TransformerEncoderLayer(
d_model=hidden_size,
nhead=num_heads,
dim_feedforward=hidden_size * 4,
dropout=0.1,
batch_first=True
)
self.transformer_encoder = TransformerEncoder(encoder_layers, num_layers=2)
self.relu = nn.ReLU()
def forward(self, x):
batch_size, _, height, width = x.size()
# 特征提取
x = self.input_conv(x) # (batch, hidden_size, height, width)
# 转换为Transformer输入格式 (height*width, batch, hidden_size)
x = x.flatten(2).permute(2, 0, 1) # (height*width, batch, hidden_size)
# 自注意力处理
x = self.transformer_encoder(x) # (height*width, batch, hidden_size)
# 转换回原始形状
x = x.permute(1, 2, 0).view(batch_size, self.hidden_size, height, width)
# 输出层
x = self.relu(x)
x = self.output_conv(x) # (batch, channels, height, width)
return torch.sigmoid(x)
# 新增的去噪方法
def total_variation_denoise(image, weight=0.1):
"""总变分去噪"""
img_array = np.array(image, dtype=np.float32) / 255.0
def tv_denoise_single_channel(channel):
h, w = channel.shape
# 初始化
u = channel.copy()
# 梯度下降迭代
for _ in range(100):
# 计算梯度
dx = np.roll(u, -1, axis=1) - u
dy = np.roll(u, -1, axis=0) - u
# 更新
div_x = np.roll(dx, 1, axis=1)
div_y = np.roll(dy, 1, axis=0)
u = u - weight * (div_x + div_y - channel)
return u
if len(img_array.shape) == 3: # 彩色图像
denoised_channels = []
for c in range(3):
denoised_channel = tv_denoise_single_channel(img_array[:, :, c])
denoised_channels.append(denoised_channel)
denoised = np.stack(denoised_channels, axis=-1)
else: # 灰度图像
denoised = tv_denoise_single_channel(img_array)
return Image.fromarray((np.clip(denoised, 0, 1) * 255).astype(np.uint8))
def guided_filter_denoise(image, radius=4, eps=0.1):
"""引导滤波去噪"""
def guided_filter(image, guidance, radius, eps):
# 均值滤波
mean_i = cv2.blur(guidance, (radius, radius))
mean_p = cv2.blur(image, (radius, radius))
# 协方差
mean_ii = cv2.blur(guidance * guidance, (radius, radius))
mean_ip = cv2.blur(guidance * image, (radius, radius))
# 方差和协方差
var_i = mean_ii - mean_i * mean_i
cov_ip = mean_ip - mean_i * mean_p
# 线性系数
a = cov_ip / (var_i + eps)
b = mean_p - a * mean_i
# 均值滤波
mean_a = cv2.blur(a, (radius, radius))
mean_b = cv2.blur(b, (radius, radius))
return mean_a * guidance + mean_b
img_array = np.array(image)
if len(img_array.shape) == 3: # 彩色图像
denoised_channels = []
for c in range(3):
denoised_channel = guided_filter(
img_array[:, :, c],
img_array[:, :, c],
radius,
eps
)
denoised_channels.append(denoised_channel)
denoised = np.stack(denoised_channels, axis=-1)
else: # 灰度图像
denoised = guided_filter(img_array, img_array, radius, eps)
return Image.fromarray(np.clip(denoised, 0, 255).astype(np.uint8))
def anisotropic_diffusion_denoise(image, kappa=30, iterations=10):
"""各向异性扩散去噪"""
def diffusion_coefficient(image, kappa):
return np.exp(-(image / kappa) ** 2)
img_array = np.array(image, dtype=np.float32) / 255.0
def denoise_single_channel(channel):
u = channel.copy()
for _ in range(iterations):
# 计算梯度
dx = np.roll(u, -1, axis=1) - u
dy = np.roll(u, -1, axis=0) - u
# 计算扩散系数
dc_north = diffusion_coefficient(dx, kappa)
dc_south = diffusion_coefficient(-dx, kappa)
dc_east = diffusion_coefficient(dy, kappa)
dc_west = diffusion_coefficient(-dy, kappa)
# 更新
u += 0.25 * (
dc_north * dx +
dc_south * np.roll(dx, 1, axis=1) +
dc_east * dy +
dc_west * np.roll(dy, 1, axis=0)
)
return u
if len(img_array.shape) == 3: # 彩色图像
denoised_channels = []
for c in range(3):
denoised_channel = denoise_single_channel(img_array[:, :, c])
denoised_channels.append(denoised_channel)
denoised = np.stack(denoised_channels, axis=-1)
else: # 灰度图像
denoised = denoise_single_channel(img_array)
return Image.fromarray((np.clip(denoised, 0, 1) * 255).astype(np.uint8))
def wavelet_thresholding_denoise(image, wavelet='db4', level=2):
"""小波阈值去噪"""
img_array = np.array(image, dtype=np.float32) / 255.0
def denoise_single_channel(channel):
# 小波变换
coeffs = pywt.wavedec2(channel, wavelet, level=level)
# 对高频系数进行阈值处理
for i in range(1, len(coeffs)):
coeffs[i] = list(coeffs[i])
for j in range(len(coeffs[i])):
# 软阈值处理
coeffs[i][j] = pywt.threshold(coeffs[i][j], threshold=0.1, mode='soft')
# 重建信号
return pywt.waverec2(coeffs, wavelet)
if len(img_array.shape) == 3: # 彩色图像
denoised_channels = []
for c in range(3):
denoised_channel = denoise_single_channel(img_array[:, :, c])
denoised_channels.append(denoised_channel)
denoised = np.stack(denoised_channels, axis=-1)
else: # 灰度图像
denoised = denoise_single_channel(img_array)
return Image.fromarray((np.clip(denoised, 0, 1) * 255).astype(np.uint8))
def bilateral_filter_denoise(image, diameter=9, sigma_color=75, sigma_space=75):
"""双边滤波去噪"""
img_array = np.array(image, dtype=np.float32) / 255.0
def bilateral_filter_single_channel(channel):
h, w = channel.shape
output = np.zeros_like(channel)
# 计算颜色和空间权重
color_weight = np.zeros((2 * diameter + 1, 2 * diameter + 1))
space_weight = np.zeros((2 * diameter + 1, 2 * diameter + 1))
for x in range(-diameter, diameter + 1):
for y in range(-diameter, diameter + 1):
color_weight[x + diameter, y + diameter] = np.exp(-(x ** 2 + y ** 2) / (2 * sigma_space ** 2))
space_weight[x + diameter, y + diameter] = np.exp(-(x ** 2 + y ** 2) / (2 * sigma_color ** 2))
# 应用双边滤波
for i in range(h):
for j in range(w):
x_min = max(0, i - diameter)
x_max = min(h, i + diameter + 1)
y_min = max(0, j - diameter)
y_max = min(w, j + diameter + 1)
neighborhood = channel[x_min:x_max, y_min:y_max]
# 计算权重
weights = color_weight[:neighborhood.shape[0], :neighborhood.shape[1]] * \
space_weight[:neighborhood.shape[0], :neighborhood.shape[1]] * \
np.abs(neighborhood - channel[i, j])
# 归一化权重
weights /= np.sum(weights)
# 加权平均
output[i, j] = np.sum(weights * neighborhood)
return output
if len(img_array.shape) == 3: # 彩色图像
denoised_channels = []
for c in range(3):
denoised_channel = bilateral_filter_single_channel(img_array[:, :, c])
denoised_channels.append(denoised_channel)
denoised = np.stack(denoised_channels, axis=-1)
else: # 灰度图像
denoised = bilateral_filter_single_channel(img_array)
return Image.fromarray((np.clip(denoised, 0, 1) * 255).astype(np.uint8))
# 模型加载函数
def load_model(model_type, channels=3, device=None):
"""加载指定类型的去噪模型"""
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if model_type == 'dncnn':
model = DnCNN(channels=channels)
elif model_type == 'autoencoder':
model = ConvAutoEncoder(channels=channels)
elif model_type == 'unet':
model = UNetDenoise(channels=channels)
elif model_type == 'lstm':
model = LSTMDenoise(channels=channels)
elif model_type == 'gru':
model = GRUDenoise(channels=channels)
elif model_type == 'attention':
model = AttentionDenoise(channels=channels)
else:
raise ValueError(f"不支持的模型类型: {model_type}")
model.to(device)
model.eval() # 设置为评估模式
return model
# 神经网络去噪函数
def neural_network_denoise(image, model_type='dncnn'):
"""使用神经网络对图像进行去噪"""
img_array = np.array(image)
is_color = len(img_array.shape) == 3
channels = 3 if is_color else 1
# 图像预处理
if is_color:
img_tensor = torch.from_numpy(img_array.transpose(2, 0, 1)).float() / 255.0
else:
img_tensor = torch.from_numpy(img_array).float().unsqueeze(0) / 255.0
img_tensor = img_tensor.unsqueeze(0)
# 选择设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
img_tensor = img_tensor.to(device)
# 加载模型
model = load_model(model_type, channels=channels, device=device)
# 推理
with torch.no_grad():
denoised_tensor = model(img_tensor)
# 后处理
denoised_tensor = denoised_tensor.squeeze(0).cpu().numpy()
denoised_tensor = np.clip(denoised_tensor, 0, 1)
if is_color:
denoised_array = (denoised_tensor.transpose(1, 2, 0) * 255).astype(np.uint8)
else:
denoised_array = (denoised_tensor.squeeze(0) * 255).astype(np.uint8)
return Image.fromarray(denoised_array)
# 图像处理辅助函数
def add_noise(image, noise_type='gaussian', amount=0.1):
"""向图像添加噪声(新增泊松噪声)"""
img_array = np.array(image, dtype=np.uint8)
is_color = len(img_array.shape) == 3
h, w = img_array.shape[:2]
if noise_type == 'gaussian':
# 高斯噪声
noise = np.random.normal(0, amount * 255, img_array.shape).astype(np.float32)
noisy_img = np.clip(img_array.astype(np.float32) + noise, 0, 255).astype(np.uint8)
elif noise_type == 'salt_pepper':
# 椒盐噪声
noisy_img = img_array.copy()
mask = np.random.rand(h, w) < amount
if is_color:
mask = np.stack([mask] * 3, axis=-1)
salt = np.where(np.random.rand(*noisy_img[mask].shape) < 0.5, 255, 0).astype(np.uint8)
noisy_img[mask] = salt
elif noise_type == 'poisson':
# 泊松噪声(模拟光子计数噪声)
img_float = img_array.astype(np.float32) / 255.0
noisy_img = np.random.poisson(img_float * 255 * (1 / amount)) / 255 * 255
noisy_img = np.clip(noisy_img, 0, 255).astype(np.uint8)
else:
raise ValueError(f"不支持的噪声类型: {noise_type}")
return Image.fromarray(noisy_img)
def mean_filter(image, size=3):
"""均值滤波(支持自定义核大小)"""
return image.filter(ImageFilter.BoxBlur(size))
def median_filter(image, size=3):
"""中值滤波(支持自定义核大小)"""
return image.filter(ImageFilter.MedianFilter(size))
def gaussian_filter_pil(image, sigma=1.0):
"""高斯滤波(支持自定义sigma值)"""
return image.filter(ImageFilter.GaussianBlur(radius=sigma))
# 优化的非局部均值滤波
def non_local_means_denoise(image, h=10, template_window=7, search_window=21):
"""优化的非局部均值去噪"""
img_array = np.array(image, dtype=np.float32)
is_color = len(img_array.shape) == 3
result = np.zeros_like(img_array)
# 使用OpenCV的优化实现,大幅提高效率
if is_color:
# 彩色图像处理
result = cv2.fastNlMeansDenoisingColored(
img_array.astype(np.uint8),
None,
h, h,
template_window,
search_window
)
else:
# 灰度图像处理
result = cv2.fastNlMeansDenoising(
img_array.astype(np.uint8),
None,
h,
template_window,
search_window
)
return Image.fromarray(result)
def rof_denoise(image, U_init, tolerance=0.1, tau=0.125, tv_weight=100):
"""ROF去噪(单通道实现)"""
U = U_init.copy().astype(np.float32)
Px = np.zeros_like(U, dtype=np.float32)
Py = np.zeros_like(U, dtype=np.float32)
error = 1
while error > tolerance:
Uold = U.copy()
GradUx = np.roll(U, -1, axis=1) - U
GradUy = np.roll(U, -1, axis=0) - U
Px_new = Px + (tau / tv_weight) * GradUx
Py_new = Py + (tau / tv_weight) * GradUy
Norm_new = np.maximum(1, np.sqrt(Px_new ** 2 + Py_new ** 2))
Px = Px_new / Norm_new
Py = Py_new / Norm_new
RxPx = np.roll(Px, 1, axis=1)
RyPy = np.roll(Py, 1, axis=0)
DivP = (Px - RxPx) + (Py - RyPy)
U = Uold + tau * (DivP + image)
error = np.linalg.norm(U - Uold) / np.sqrt(U.size)
return U
def rof_denoise_color(image_array):
"""彩色图像ROF去噪"""
denoised_channels = []
for channel in range(3):
single_channel = image_array[:, :, channel].astype(np.float32) / 255.0
denoised = rof_denoise(single_channel, single_channel)
denoised_clamped = np.clip(denoised, 0, 1)
denoised_channels.append((denoised_clamped * 255).astype(np.uint8))
return np.stack(denoised_channels, axis=-1)
def analyze_image(image):
"""分析图像特征,返回用于自适应参数的关键指标"""
img_array = np.array(image)
is_color = len(img_array.shape) == 3
# 转换为灰度图进行特征分析
if is_color:
img_gray = np.array(image.convert('L'))
else:
img_gray = img_array
# 计算图像统计特征
mean_intensity = np.mean(img_gray)
std_intensity = np.std(img_gray)
contrast = (np.max(img_gray) - np.min(img_gray)) / 255.0
# 边缘密度(使用Canny算子)
edges = canny(img_gray / 255.0, sigma=1.0)
edge_density = np.sum(edges) / (img_gray.shape[0] * img_gray.shape[1])
# 纹理复杂度(使用Otsu阈值后的区域数)
thresh = threshold_otsu(img_gray)
binary = img_gray > thresh
texture_complexity = np.std(binary) # 简单度量,标准差越高表示纹理越复杂
return {
'mean_intensity': mean_intensity,
'std_intensity': std_intensity,
'contrast': contrast,
'edge_density': edge_density,
'texture_complexity': texture_complexity,
'is_color': is_color,
'width': img_array.shape[1],
'height': img_array.shape[0]
}
def get_adaptive_params(image_features, noise_type, noise_amount):
"""根据图像特征和噪声类型生成自适应参数"""
params = {
'mean_size': 3,
'median_size': 3,
'gaussian_sigma': 1.0,
'nl_means_h': 10,
'rof_tolerance': 0.1
}
# 基于噪声类型调整
if noise_type == 'gaussian':
# 高斯噪声:根据噪声强度调整
params['mean_size'] = max(3, int(noise_amount * 10))
params['median_size'] = max(3, int(noise_amount * 8))
params['gaussian_sigma'] = max(1.0, noise_amount * 5)
params['nl_means_h'] = max(5, int(noise_amount * 50))
elif noise_type == 'salt_pepper':
# 椒盐噪声:中值滤波效果最好
params['median_size'] = max(3, int(noise_amount * 12))
params['nl_means_h'] = max(5, int(noise_amount * 40))
elif noise_type == 'poisson':
# 泊松噪声:适合中等强度滤波
params['gaussian_sigma'] = max(1.0, noise_amount * 3)
params['nl_means_h'] = max(5, int(noise_amount * 30))
# 基于图像复杂度调整(续)
if image_features['edge_density'] > 0.1:
# 边缘丰富的图像:避免过度平滑
params['mean_size'] = min(params['mean_size'], 5)
params['median_size'] = min(params['median_size'], 5)
params['gaussian_sigma'] = min(params['gaussian_sigma'], 2.0)
params['nl_means_h'] = min(params['nl_means_h'], 15)
if image_features['texture_complexity'] > 0.2:
# 纹理复杂的图像:增强去噪能力
params['nl_means_h'] = min(params['nl_means_h'] * 1.5, 25)
params['rof_tolerance'] = max(params['rof_tolerance'] * 0.7, 0.05)
# 图像尺寸调整
if image_features['width'] * image_features['height'] > 1000 * 1000:
# 大图像:优化计算速度
params['nl_means_h'] = min(params['nl_means_h'], 15)
params['rof_tolerance'] = max(params['rof_tolerance'], 0.15)
return params
def calculate_metrics(original, processed):
"""计算PSNR、SSIM、MSE三种评估指标"""
orig_arr = np.array(original, dtype=np.float32)
proc_arr = np.array(processed, dtype=np.float32)
# MSE(均方误差)
mse = np.mean((orig_arr - proc_arr) ** 2)
# PSNR(峰值信噪比)
psnr_val = 20 * np.log10(255.0 / np.sqrt(mse)) if mse != 0 else float('inf')
# SSIM(结构相似性指数)
if orig_arr.ndim == 3:
# 彩色图像计算每个通道的SSIM并平均
ssim_val = 0
for c in range(3):
ssim_val += _ssim_single(orig_arr[..., c], proc_arr[..., c])
ssim_val /= 3
else:
# 灰度图像直接计算
ssim_val = _ssim_single(orig_arr, proc_arr)
return {
'psnr': psnr_val,
'ssim': ssim_val,
'mse': mse
}
def _ssim_single(img1, img2):
"""单通道SSIM计算"""
C1 = (0.01 * 255) ** 2
C2 = (0.03 * 255) ** 2
# 高斯滤波(模拟人眼视觉特性)
mu1 = gaussian_filter_pil(Image.fromarray(img1.astype(np.uint8)), sigma=1.5)
mu1 = np.array(mu1, dtype=np.float32)
mu2 = gaussian_filter_pil(Image.fromarray(img2.astype(np.uint8)), sigma=1.5)
mu2 = np.array(mu2, dtype=np.float32)
mu1_sq = mu1 ** 2
mu2_sq = mu2 ** 2
mu1_mu2 = mu1 * mu2
sigma1_sq = gaussian_filter_pil(Image.fromarray((img1 ** 2).astype(np.uint8)), sigma=1.5)
sigma1_sq = np.array(sigma1_sq, dtype=np.float32) - mu1_sq
sigma2_sq = gaussian_filter_pil(Image.fromarray((img2 ** 2).astype(np.uint8)), sigma=1.5)
sigma2_sq = np.array(sigma2_sq, dtype=np.float32) - mu2_sq
sigma12 = gaussian_filter_pil(Image.fromarray((img1 * img2).astype(np.uint8)), sigma=1.5)
sigma12 = np.array(sigma12, dtype=np.float32) - mu1_mu2
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
return np.mean(ssim_map)
def adaptive_denoise(image, method, params, noise_type, noise_amount):
"""基于自适应参数的去噪处理"""
if method == 'mean':
return mean_filter(image, params['mean_size'])
elif method == 'median':
return median_filter(image, params['median_size'])
elif method == 'gaussian':
return gaussian_filter_pil(image, params['gaussian_sigma'])
elif method == 'non_local_means':
return non_local_means_denoise(image, params['nl_means_h'])
elif method == 'rof':
img_array = np.array(image)
if len(img_array.shape) == 3: # 彩色
return Image.fromarray(rof_denoise_color(img_array), mode='RGB')
else: # 灰度
img_float = img_array.astype(np.float32) / 255.0
rof_result = rof_denoise(img_float, img_float, tolerance=params['rof_tolerance'])
return Image.fromarray((np.clip(rof_result, 0, 1) * 255).astype(np.uint8), mode='L')
elif method == 'total_variation':
return total_variation_denoise(image)
elif method == 'guided_filter':
return guided_filter_denoise(image)
elif method == 'anisotropic_diffusion':
return anisotropic_diffusion_denoise(image)
elif method == 'wavelet_thresholding':
return wavelet_thresholding_denoise(image)
elif method in ['dncnn', 'autoencoder', 'unet', 'lstm', 'gru', 'attention']:
return neural_network_denoise(image, method)
elif method == 'bilateral':
return bilateral_filter_denoise(image)
else:
raise ValueError(f"不支持的去噪方法: {method}")
def enhance_details(image, amount=0.5):
"""增强图像细节(锐化)"""
# 先进行轻度高斯模糊
blurred = gaussian_filter_pil(image, sigma=1.0)
# 计算原图与模糊图的差值(高频细节)
img_arr = np.array(image, dtype=np.float32)
blur_arr = np.array(blurred, dtype=np.float32)
detail = img_arr - blur_arr
# 增强细节并合并回原图
enhanced = img_arr + detail * amount
enhanced = np.clip(enhanced, 0, 255).astype(np.uint8)
return Image.fromarray(enhanced)
def auto_contrast(image):
"""自动调整对比度"""
return ImageOps.autocontrast(image)
def adjust_brightness(image, factor):
"""调整亮度"""
enhancer = ImageEnhance.Brightness(image)
return enhancer.enhance(factor)
def adjust_saturation(image, factor):
"""调整饱和度(仅彩色图像)"""
enhancer = ImageEnhance.Color(image)
return enhancer.enhance(factor)
class ImageDenoiseApp:
def __init__(self, root):
self.root = root
self.root.title("智能图像去噪工具")
self.root.geometry("1400x900")
# 初始化变量
self.original_image = None
self.noisy_image = None
self.processed_image = None
self.process_results = {}
self.adaptive_params = None
self.image_features = None
# 创建UI
self._create_ui()
# 状态栏
self.status_var = tk.StringVar()
self.status_var.set("欢迎使用智能图像去噪工具")
self.status_bar = ttk.Label(self.root, textvariable=self.status_var, relief=tk.SUNKEN, anchor=tk.W)
self.status_bar.pack(side=tk.BOTTOM, fill=tk.X)
# 显示欢迎信息
self._show_welcome_message()
def _create_ui(self):
# 创建菜单栏
self.menu_bar = tk.Menu(self.root)
self.root.config(menu=self.menu_bar)
# 文件菜单
self.file_menu = tk.Menu(self.menu_bar, tearoff=0)
self.menu_bar.add_cascade(label="文件", menu=self.file_menu)
self.file_menu.add_command(label="打开图像", command=self._open_image, accelerator="Ctrl+O")
self.file_menu.add_command(label="保存处理结果", command=self._save_processed_image, accelerator="Ctrl+S")
self.file_menu.add_separator()
self.file_menu.add_command(label="退出", command=self.root.quit, accelerator="Ctrl+Q")
# 帮助菜单
self.help_menu = tk.Menu(self.menu_bar, tearoff=0)
self.menu_bar.add_cascade(label="帮助", menu=self.help_menu)
self.help_menu.add_command(label="使用帮助", command=self._show_help)
self.help_menu.add_command(label="关于", command=self._show_about)
# 主框架
self.main_frame = ttk.Frame(self.root)
self.main_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
# 左侧带滚动条的控制面板
control_container = ttk.Frame(self.main_frame)
control_container.pack(side=tk.LEFT, fill=tk.Y, padx=(0, 10))
# 添加滚动条
control_scrollbar = ttk.Scrollbar(control_container)
control_scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
# 创建Canvas用于放置控制面板
self.control_canvas = tk.Canvas(control_container, yscrollcommand=control_scrollbar.set)
self.control_canvas.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
# 配置滚动条
control_scrollbar.config(command=self.control_canvas.yview)
# 创建控制面板框架,放置在Canvas上
self.control_frame = ttk.LabelFrame(self.control_canvas, text="处理控制", padding=10)
self.control_frame_window = self.control_canvas.create_window((0, 0), window=self.control_frame, anchor="nw")
# 绑定事件,当控制面板大小改变时更新滚动区域
self.control_frame.bind("<Configure>", self._on_control_configure)
self.control_canvas.bind("<Configure>", self._on_canvas_configure)
# 图像加载区
self.load_frame = ttk.LabelFrame(self.control_frame, text="图像加载", padding=5)
self.load_frame.pack(fill=tk.X, pady=(0, 10))
self.open_btn = ttk.Button(self.load_frame, text="打开图像", command=self._open_image)
self.open_btn.pack(fill=tk.X, pady=5)
# 噪声控制区
self.noise_frame = ttk.LabelFrame(self.control_frame, text="噪声设置", padding=5)
self.noise_frame.pack(fill=tk.X, pady=(0, 10))
self.noise_type_label = ttk.Label(self.noise_frame, text="噪声类型:")
self.noise_type_label.pack(anchor=tk.W)
self.noise_type = tk.StringVar(value="gaussian")
self.noise_type_combo = ttk.Combobox(
self.noise_frame,
textvariable=self.noise_type,
values=["gaussian", "salt_pepper", "poisson"],
state="readonly"
)
self.noise_type_combo.pack(fill=tk.X, pady=2)
self.noise_amount_label = ttk.Label(self.noise_frame, text="噪声强度:")
self.noise_amount_label.pack(anchor=tk.W)
self.noise_amount = tk.DoubleVar(value=0.05)
self.noise_amount_scale = ttk.Scale(
self.noise_frame,
variable=self.noise_amount,
from_=0.01, to=0.5,
orient=tk.HORIZONTAL,
command=lambda s: self.noise_amount.set(round(float(s), 2))
)
self.noise_amount_scale.pack(fill=tk.X, pady=2)
self.noise_amount_value = ttk.Label(self.noise_frame, textvariable=self.noise_amount)
self.noise_amount_value.pack(anchor=tk.E)
self.add_noise_btn = ttk.Button(self.noise_frame, text="添加噪声", command=self._add_noise)
self.add_noise_btn.pack(fill=tk.X, pady=5)
# 去噪方法选择
self.denoise_frame = ttk.LabelFrame(self.control_frame, text="去噪方法", padding=5)
self.denoise_frame.pack(fill=tk.X, pady=(0, 10))
self.denoise_method = tk.StringVar(value="dncnn")
# 更新去噪方法列表,移除了改进中值和改进非局部均值,添加了新方法
self.denoise_methods = [
("均值滤波", "mean"),
("中值滤波", "median"),
("高斯滤波", "gaussian"),
("非局部均值", "non_local_means"),
("ROF去噪", "rof"),
("DnCNN网络", "dncnn"),
("自编码器", "autoencoder"),
("U-Net网络", "unet"),
("LSTM去噪", "lstm"),
("GRU去噪", "gru"),
("自注意力去噪", "attention"),
("总变分去噪", "total_variation"),
("引导滤波", "guided_filter"),
("各向异性扩散", "anisotropic_diffusion"),
("小波阈值", "wavelet_thresholding"),
("双边滤波", "bilateral")
]
# 创建单选按钮
for text, value in self.denoise_methods:
ttk.Radiobutton(
self.denoise_frame,
text=text,
variable=self.denoise_method,
value=value
).pack(anchor=tk.W, pady=2)
# 高级处理选项
self.advanced_frame = ttk.LabelFrame(self.control_frame, text="高级选项", padding=5)
self.advanced_frame.pack(fill=tk.X, pady=(0, 10))
self.enhance_details_var = tk.BooleanVar(value=False)
self.enhance_details_check = ttk.Checkbutton(
self.advanced_frame,
text="细节增强",
variable=self.enhance_details_var
)
self.enhance_details_check.pack(anchor=tk.W, pady=2)
self.auto_contrast_var = tk.BooleanVar(value=False)
self.auto_contrast_check = ttk.Checkbutton(
self.advanced_frame,
text="自动对比度",
variable=self.auto_contrast_var
)
self.auto_contrast_check.pack(anchor=tk.W, pady=2)
self.adaptive_mode_var = tk.BooleanVar(value=True)
self.adaptive_mode_check = ttk.Checkbutton(
self.advanced_frame,
text="自适应参数",
variable=self.adaptive_mode_var
)
self.adaptive_mode_check.pack(anchor=tk.W, pady=2)
# 亮度和饱和度调整
self.brightness_label = ttk.Label(self.advanced_frame, text="亮度:")
self.brightness_label.pack(anchor=tk.W, pady=(5, 0))
self.brightness = tk.DoubleVar(value=1.0)
brightness_scale = ttk.Scale(
self.advanced_frame,
variable=self.brightness,
from_=0.5, to=2.0,
orient=tk.HORIZONTAL,
command=lambda s: self.brightness.set(round(float(s), 2))
)
brightness_scale.pack(fill=tk.X, pady=2)
self.saturation_label = ttk.Label(self.advanced_frame, text="饱和度:")
self.saturation_label.pack(anchor=tk.W, pady=(5, 0))
self.saturation = tk.DoubleVar(value=1.0)
saturation_scale = ttk.Scale(
self.advanced_frame,
variable=self.saturation,
from_=0.0, to=2.0,
orient=tk.HORIZONTAL,
command=lambda s: self.saturation.set(round(float(s), 2))
)
saturation_scale.pack(fill=tk.X, pady=2)
# 处理按钮
self.process_btn = ttk.Button(self.control_frame, text="开始处理", command=self._process_image)
self.process_btn.pack(fill=tk.X, pady=(10, 0))
# 图像分析结果
self.analysis_frame = ttk.LabelFrame(self.control_frame, text="图像分析", padding=5)
self.analysis_frame.pack(fill=tk.X, pady=(10, 0))
self.analysis_text = scrolledtext.ScrolledText(self.analysis_frame, height=10, wrap=tk.WORD)
self.analysis_text.pack(fill=tk.BOTH, expand=True)
self.analysis_text.config(state=tk.DISABLED)
# 添加一个占位元素,确保滚动区域足够
ttk.Label(self.control_frame, text="").pack(pady=10)
# 右侧图像显示区
self.display_frame = ttk.Frame(self.main_frame)
self.display_frame.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True)
# 图像显示选项卡
self.tab_control = ttk.Notebook(self.display_frame)
# 原始图像选项卡
self.original_tab = ttk.Frame(self.tab_control)
self.tab_control.add(self.original_tab, text="原始图像")
self.original_label = ttk.Label(self.original_tab, text="请打开一张图像")
self.original_label.pack(expand=True)
# 噪声图像选项卡
self.noisy_tab = ttk.Frame(self.tab_control)
self.tab_control.add(self.noisy_tab, text="噪声图像")
self.noisy_label = ttk.Label(self.noisy_tab, text="请添加噪声")
self.noisy_label.pack(expand=True)
# 处理结果选项卡
self.processed_tab = ttk.Frame(self.tab_control)
self.tab_control.add(self.processed_tab, text="处理结果")
self.processed_label = ttk.Label(self.processed_tab, text="请处理图像")
self.processed_label.pack(expand=True)
# 对比选项卡
self.compare_tab = ttk.Frame(self.tab_control)
self.tab_control.add(self.compare_tab, text="效果对比")
self.compare_label = ttk.Label(self.compare_tab, text="处理后显示对比")
self.compare_label.pack(expand=True)
# 评估指标选项卡
self.metrics_tab = ttk.Frame(self.tab_control)
self.tab_control.add(self.metrics_tab, text="评估指标")
self.metrics_label = ttk.Label(self.metrics_tab, text="处理后显示评估指标")
self.metrics_label.pack(expand=True)
# 显示选项卡
self.tab_control.pack(fill=tk.BOTH, expand=True)
# 底部按钮栏
self.button_frame = ttk.Frame(self.main_frame)
self.button_frame.pack(side=tk.BOTTOM, fill=tk.X, pady=(10, 0))
self.save_btn = ttk.Button(self.button_frame, text="保存结果", command=self._save_processed_image)
self.save_btn.pack(side=tk.RIGHT, padx=(5, 0))
self.compare_all_btn = ttk.Button(self.button_frame, text="对比所有方法", command=self._compare_all_methods)
self.compare_all_btn.pack(side=tk.RIGHT, padx=(5, 0))
# 快捷键绑定
self.root.bind("<Control-o>", lambda e: self._open_image())
self.root.bind("<Control-s>", lambda e: self._save_processed_image())
self.root.bind("<Control-q>", lambda e: self.root.quit())
def _on_control_configure(self, event):
"""当控制面板内容大小改变时,更新Canvas的滚动区域"""
self.control_canvas.configure(scrollregion=self.control_canvas.bbox("all"))
def _on_canvas_configure(self, event):
"""当Canvas大小改变时,调整内部窗口大小"""
self.control_canvas.itemconfig(self.control_frame_window, width=event.width)
def _show_welcome_message(self):
"""显示欢迎信息"""
welcome_text = (
"欢迎使用智能图像去噪工具\n\n"
"使用步骤:\n"
"1. 点击'打开图像'加载一张图片\n"
"2. 调整噪声设置并点击'添加噪声'模拟受污染的图像\n"
"3. 选择去噪方法并可启用高级选项\n"
"4. 点击'开始处理'进行去噪\n"
"5. 在各选项卡中查看处理效果和评估指标\n\n"
"支持多种传统和深度学习去噪方法,并且能够根据图像特征自适应调整参数"
)
self.analysis_text.config(state=tk.NORMAL)
self.analysis_text.delete(1.0, tk.END)
self.analysis_text.insert(tk.END, welcome_text)
self.analysis_text.config(state=tk.DISABLED)
def _open_image(self):
"""打开图像文件,添加尺寸检查"""
file_path = filedialog.askopenfilename(
title="选择图像",
filetypes=[
("图像文件", "*.jpg *.jpeg *.png *.bmp *.tiff *.webp"),
("所有文件", "*.*")
]
)
if file_path:
try:
self.original_image = Image.open(file_path).convert('RGB') # 统一转为RGB
width, height = self.original_image.size
min_dim = min(width, height)
# 检查小尺寸图像并提示
if min_dim < 10:
messagebox.showwarning("提示", f"图像尺寸较小({width}x{height}),部分算法可能无法正常运行")
self._display_image(self.original_image, self.original_label, "original")
self.status_var.set(f"已加载图像: {os.path.basename(file_path)}")
self.tab_control.select(0)
# 分析图像特征
self._analyze_current_image()
# 重置其他图像
self.noisy_image = None
self.processed_image = None
self.noisy_label.config(text="请添加噪声")
self.processed_label.config(text="请处理图像")
self.process_results = {}
except Exception as e:
messagebox.showerror("错误", f"无法打开图像: {str(e)}")
def _display_image(self, image, label, image_type=None):
"""在标签上显示图像"""
max_width = 600
max_height = 500
width, height = image.size
if width > max_width or height > max_height:
ratio = min(max_width / width, max_height / height)
width = int(width * ratio)
height = int(height * ratio)
image = image.resize((width, height), Image.Resampling.LANCZOS)
tk_image = ImageTk.PhotoImage(image)
label.config(image=tk_image)
label.image = tk_image
def _analyze_current_image(self):
"""分析当前图像并显示特征"""
if self.original_image:
self.image_features = self._analyze_image_features(self.original_image)
# 更新分析结果显示
analysis_text = (
f"图像分析结果:\n"
f" 亮度: {self.image_features['mean_intensity']:.1f}/255\n"
f" 对比度: {self.image_features['contrast']:.2f}\n"
f" 边缘密度: {self.image_features['edge_density']:.4f}\n"
f" 纹理复杂度: {self.image_features['texture_complexity']:.4f}\n"
f" 尺寸: {self.image_features['width']}x{self.image_features['height']}像素\n"
f" 类型: {'彩色' if self.image_features['is_color'] else '灰度'}"
)
self.analysis_text.config(state=tk.NORMAL)
self.analysis_text.delete(1.0, tk.END)
self.analysis_text.insert(tk.END, analysis_text)
self.analysis_text.config(state=tk.DISABLED)
# 计算自适应参数
if self.adaptive_mode_var.get():
self.adaptive_params = self._get_adaptive_params(
self.image_features,
self.noise_type.get(),
self.noise_amount.get()
)
# 显示自适应参数
params_text = "\n自适应参数:\n"
for key, value in self.adaptive_params.items():
params_text += f" {key}: {value}\n"
self.analysis_text.config(state=tk.NORMAL)
self.analysis_text.insert(tk.END, params_text)
self.analysis_text.config(state=tk.DISABLED)
def _analyze_image_features(self, image):
"""分析图像特征"""
img_array = np.array(image)
is_color = len(img_array.shape) == 3
# 转换为灰度图进行特征分析
img_gray = np.array(image.convert('L'))
# 计算图像统计特征
mean_intensity = np.mean(img_gray)
std_intensity = np.std(img_gray)
contrast = (np.max(img_gray) - np.min(img_gray)) / 255.0
# 边缘密度(使用Canny算子)
edges = canny(img_gray / 255.0, sigma=1.0)
edge_density = np.sum(edges) / (img_gray.shape[0] * img_gray.shape[1])
# 纹理复杂度(使用Otsu阈值后的区域数)
thresh = threshold_otsu(img_gray)
binary = img_gray > thresh
texture_complexity = np.std(binary)
return {
'mean_intensity': mean_intensity,
'std_intensity': std_intensity,
'contrast': contrast,
'edge_density': edge_density,
'texture_complexity': texture_complexity,
'is_color': is_color,
'width': img_array.shape[1],
'height': img_array.shape[0]
}
def _get_adaptive_params(self, image_features, noise_type, noise_amount):
"""根据图像特征和噪声类型生成自适应参数"""
min_dim = min(image_features['width'], image_features['height'])
# 基础参数(确保不超过图像尺寸)
base_params = {
'mean_size': min(3, min_dim // 2),
'median_size': min(3, min_dim // 2),
'gaussian_sigma': min(1.0, min_dim / 10),
'nl_means_h': 10,
'rof_tolerance': 0.1
}
# 确保核大小为奇数且不小于3(如果图像足够大)
if min_dim >= 5:
base_params['mean_size'] = min(5, min_dim // 2) if base_params['mean_size'] < 3 else base_params[
'mean_size']
base_params['median_size'] = min(5, min_dim // 2) if base_params['median_size'] < 3 else base_params[
'median_size']
if base_params['mean_size'] % 2 == 0:
base_params['mean_size'] -= 1
if base_params['median_size'] % 2 == 0:
base_params['median_size'] -= 1
# 基于噪声类型调整
if noise_type == 'gaussian':
base_params['mean_size'] = min(base_params['mean_size'], max(3, int(noise_amount * 10)))
base_params['median_size'] = min(base_params['median_size'], max(3, int(noise_amount * 8)))
base_params['gaussian_sigma'] = min(base_params['gaussian_sigma'], max(1.0, noise_amount * 5))
base_params['nl_means_h'] = min(base_params['nl_means_h'], max(5, int(noise_amount * 50)))
elif noise_type == 'salt_pepper':
base_params['median_size'] = min(base_params['median_size'], max(3, int(noise_amount * 12)))
base_params['nl_means_h'] = min(base_params['nl_means_h'], max(5, int(noise_amount * 40)))
elif noise_type == 'poisson':
base_params['gaussian_sigma'] = min(base_params['gaussian_sigma'], max(1.0, noise_amount * 3))
base_params['nl_means_h'] = min(base_params['nl_means_h'], max(5, int(noise_amount * 30)))
return base_params
def _add_noise(self):
"""添加噪声到原始图像"""
if self.original_image:
try:
# 更新图像分析(以防噪声类型或强度改变)
if self.adaptive_mode_var.get():
self.adaptive_params = self._get_adaptive_params(
self.image_features,
self.noise_type.get(),
self.noise_amount.get()
)
# 添加噪声
self.noisy_image = self._add_noise_to_image(
self.original_image,
self.noise_type.get(),
self.noise_amount.get()
)
# 显示噪声图像
self._display_image(self.noisy_image, self.noisy_label, "noisy")
self.tab_control.select(1)
self.status_var.set(f"已添加{self.noise_type.get()}噪声,强度: {self.noise_amount.get()}")
# 重置处理结果
self.processed_image = None
self.processed_label.config(text="请处理图像")
self.process_results = {}
except Exception as e:
messagebox.showerror("错误", f"添加噪声失败: {str(e)}")
def _add_noise_to_image(self, image, noise_type='gaussian', amount=0.1):
"""向图像添加噪声"""
img_array = np.array(image, dtype=np.uint8)
is_color = len(img_array.shape) == 3
h, w = img_array.shape[:2]
if noise_type == 'gaussian':
noise = np.random.normal(0, amount * 255, img_array.shape).astype(np.float32)
noisy_img = np.clip(img_array.astype(np.float32) + noise, 0, 255).astype(np.uint8)
elif noise_type == 'salt_pepper':
noisy_img = img_array.copy()
mask = np.random.rand(h, w) < amount
if is_color:
mask = np.stack([mask] * 3, axis=-1)
salt = np.where(np.random.rand(*noisy_img[mask].shape) < 0.5, 255, 0).astype(np.uint8)
noisy_img[mask] = salt
elif noise_type == 'poisson':
img_float = img_array.astype(np.float32) / 255.0
noisy_img = np.random.poisson(img_float * 255 * (1 / amount)) / 255 * 255
noisy_img = np.clip(noisy_img, 0, 255).astype(np.uint8)
else:
raise ValueError(f"不支持的噪声类型: {noise_type}")
return Image.fromarray(noisy_img)
def _process_image(self):
"""处理图像"""
if self.noisy_image:
try:
self.status_var.set("正在处理图像...")
self.process_btn.config(state=tk.DISABLED)
self.root.update()
# 获取当前设置
method = self.denoise_method.get()
enhance_details = self.enhance_details_var.get()
auto_contrast = self.auto_contrast_var.get()
brightness = self.brightness.get()
saturation = self.saturation.get()
# 准备参数
if self.adaptive_mode_var.get() and self.adaptive_params:
params = self.adaptive_params
else:
width, height = self.noisy_image.size
min_dim = min(width, height)
params = {
'mean_size': min(3, min_dim // 2) if min_dim >= 3 else 3,
'median_size': min(3, min_dim // 2) if min_dim >= 3 else 3,
'gaussian_sigma': min(1.0, min_dim / 10),
'nl_means_h': 10,
'rof_tolerance': 0.1
}
# 创建处理线程
def process_thread():
error_message = None
processed_image = None
processed_metrics = None
try:
# 应用去噪
processed = self._adaptive_denoise(
self.noisy_image,
method,
params,
self.noise_type.get(),
self.noise_amount.get()
)
# 应用后处理
if enhance_details:
processed = self._enhance_details(processed)
if auto_contrast:
processed = self._auto_contrast(processed)
if brightness != 1.0:
processed = self._adjust_brightness(processed, brightness)
if saturation != 1.0:
processed = self._adjust_saturation(processed, saturation)
# 确保图像格式正确
processed = processed.convert('RGB')
# 计算评估指标
metrics = self._calculate_image_metrics(self.original_image, processed)
processed_image = processed
processed_metrics = metrics
except Exception as e:
error_message = f"处理图像失败: {str(e)}"
# 更新UI
self.root.after(0, lambda: self._update_process_result_thread(
processed_image, method, processed_metrics, error_message
))
# 启动处理线程
threading.Thread(target=process_thread, daemon=True).start()
except Exception as e:
messagebox.showerror("错误", f"处理图像失败: {str(e)}")
self.process_btn.config(state=tk.NORMAL)
else:
messagebox.showinfo("提示", "请先添加噪声")
def _update_process_result_thread(self, processed, method, metrics, error_message):
"""线程安全的处理结果更新"""
self.process_btn.config(state=tk.NORMAL)
if error_message:
messagebox.showerror("错误", error_message)
return
if processed is not None:
self.processed_image = processed
self._display_image(processed, self.processed_label, "processed")
self.tab_control.select(2)
# 保存处理结果
self.process_results[method] = {
'image': processed,
'metrics': metrics
}
# 更新状态栏和评估指标
self.status_var.set(f"处理完成 - {method}")
self._update_metrics_display()
def _update_metrics_display(self):
"""更新评估指标显示"""
if self.process_results:
for widget in self.metrics_tab.winfo_children():
widget.destroy()
columns = ("方法", "PSNR (dB)", "SSIM", "MSE")
tree = ttk.Treeview(self.metrics_tab, columns=columns, show="headings")
for col in columns:
tree.heading(col, text=col)
tree.column(col, width=150, anchor=tk.CENTER)
for method, result in self.process_results.items():
metrics = result['metrics']
method_name = next((name for name, val in self.denoise_methods if val == method), method)
tree.insert("", tk.END, values=(
method_name,
f"{metrics['psnr']:.2f}",
f"{metrics['ssim']:.4f}",
f"{metrics['mse']:.2f}"
))
tree.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
compare_btn = ttk.Button(
self.metrics_tab,
text="生成对比图",
command=self._generate_comparison_plot
)
compare_btn.pack(pady=10)
else:
self.metrics_label.config(text="处理后显示评估指标")
def _compare_all_methods(self):
"""对比所有去噪方法"""
if self.noisy_image:
try:
self.status_var.set("正在比较所有方法...")
self.process_btn.config(state=tk.DISABLED)
self.compare_all_btn.config(state=tk.DISABLED)
self.root.update()
# 获取当前设置
enhance_details = self.enhance_details_var.get()
auto_contrast = self.auto_contrast_var.get()
brightness = self.brightness.get()
saturation = self.saturation.get()
# 准备参数
width, height = self.noisy_image.size
min_dim = min(width, height)
if self.adaptive_mode_var.get() and self.adaptive_params:
params = self.adaptive_params
else:
params = {
'mean_size': min(3, min_dim // 2) if min_dim >= 3 else 3,
'median_size': min(3, min_dim // 2) if min_dim >= 3 else 3,
'gaussian_sigma': min(1.0, min_dim / 10),
'nl_means_h': 10,
'rof_tolerance': 0.1
}
# 创建处理线程
def compare_thread():
error_message = None
processed_results = {}
try:
# 遍历所有去噪方法
for _, method in self.denoise_methods:
# 应用去噪
processed = self._adaptive_denoise(
self.noisy_image,
method,
params,
self.noise_type.get(),
self.noise_amount.get()
)
# 应用后处理
if enhance_details:
processed = self._enhance_details(processed)
if auto_contrast:
processed = self._auto_contrast(processed)
if brightness != 1.0:
processed = self._adjust_brightness(processed, brightness)
if saturation != 1.0:
processed = self._adjust_saturation(processed, saturation)
processed = processed.convert('RGB')
# 计算评估指标
metrics = self._calculate_image_metrics(self.original_image, processed)
# 保存处理结果
processed_results[method] = {
'image': processed,
'metrics': metrics
}
except Exception as e:
error_message = f"比较方法失败: {str(e)}"
# 在主线程更新UI
self.root.after(0, lambda: self._update_compare_results(processed_results, error_message))
# 启动处理线程
threading.Thread(target=compare_thread, daemon=True).start()
except Exception as e:
messagebox.showerror("错误", f"比较方法失败: {str(e)}")
self.process_btn.config(state=tk.NORMAL)
self.compare_all_btn.config(state=tk.NORMAL)
else:
messagebox.showinfo("提示", "请先添加噪声")
def _update_compare_results(self, processed_results, error_message):
"""线程安全的比较结果更新"""
self.process_btn.config(state=tk.NORMAL)
self.compare_all_btn.config(state=tk.NORMAL)
if error_message:
messagebox.showerror("错误", error_message)
return
if processed_results:
self.process_results = processed_results
self._update_metrics_display()
self._generate_comparison_plot()
def _generate_comparison_plot(self):
"""生成比较图"""
if self.process_results:
try:
# 清除现有控件
for widget in self.compare_tab.winfo_children():
widget.destroy()
# 创建图形
fig = plt.figure(figsize=(12, 8))
# 计算需要的行列数
n_methods = len(self.process_results)
n_cols = 3
n_rows = (n_methods + 2 + n_cols - 1) // n_cols # +2是因为要包含原始和噪声图像
# 添加原始图像
ax0 = fig.add_subplot(n_rows, n_cols, 1)
ax0.set_title("原始图像")
ax0.imshow(self.original_image)
ax0.axis('off')
# 添加噪声图像
ax1 = fig.add_subplot(n_rows, n_cols, 2)
noisy_metrics = self._calculate_image_metrics(self.original_image, self.noisy_image)
ax1.set_title(f"噪声图像\nPSNR: {noisy_metrics['psnr']:.2f} dB")
ax1.imshow(self.noisy_image)
ax1.axis('off')
# 添加处理结果
method_idx = 3
for method, result in self.process_results.items():
if method_idx > n_rows * n_cols:
break # 防止超出子图数量
ax = fig.add_subplot(n_rows, n_cols, method_idx)
# 获取方法显示名称
method_name = next((name for name, val in self.denoise_methods if val == method), method)
ax.set_title(f"{method_name}\nPSNR: {result['metrics']['psnr']:.2f} dB")
ax.imshow(result['image'])
ax.axis('off')
method_idx += 1
plt.tight_layout()
# 创建Tkinter画布并显示图形
canvas = FigureCanvasTkAgg(fig, master=self.compare_tab)
canvas.draw()
canvas.get_tk_widget().pack(fill=tk.BOTH, expand=True)
# 添加保存按钮
save_btn = ttk.Button(
self.compare_tab,
text="保存对比图",
command=lambda: self._save_comparison_plot(fig)
)
save_btn.pack(pady=10)
except Exception as e:
messagebox.showerror("错误", f"生成对比图失败: {str(e)}")
def _save_comparison_plot(self, fig):
"""保存对比图"""
if fig:
try:
file_path = filedialog.asksaveasfilename(
title="保存对比图",
defaultextension=".png",
filetypes=[
("PNG 图像", "*.png"),
("JPEG 图像", "*.jpg"),
("所有文件", "*.*")
]
)
if file_path:
fig.savefig(file_path, dpi=300, bbox_inches='tight')
self.status_var.set(f"已保存对比图: {os.path.basename(file_path)}")
except Exception as e:
messagebox.showerror("错误", f"保存对比图失败: {str(e)}")
def _save_processed_image(self):
"""保存处理后的图像"""
if self.processed_image:
try:
file_path = filedialog.asksaveasfilename(
title="保存图像",
defaultextension=".png",
filetypes=[
("PNG 图像", "*.png"),
("JPEG 图像", "*.jpg"),
("BMP 图像", "*.bmp"),
("所有文件", "*.*")
]
)
if file_path:
self.processed_image.save(file_path)
self.status_var.set(f"已保存图像: {os.path.basename(file_path)}")
except Exception as e:
messagebox.showerror("错误", f"保存图像失败: {str(e)}")
else:
messagebox.showinfo("提示", "请先处理图像")
def _show_help(self):
"""显示帮助信息"""
help_text = (
"智能图像去噪工具使用帮助\n\n"
"1. 打开图像:点击'打开图像'按钮选择要处理的图片\n"
"2. 添加噪声:设置噪声类型和强度,点击'添加噪声'按钮\n"
"3. 选择去噪方法:从提供的多种去噪方法中选择一种\n"
"4. 高级选项:可启用细节增强、自动对比度等功能\n"
"5. 开始处理:点击'开始处理'按钮进行去噪\n"
"6. 查看结果:在不同选项卡中查看原始图像、噪声图像、处理结果\n"
"7. 对比评估:点击'对比所有方法'可比较不同去噪方法的效果\n"
"8. 保存结果:点击'保存结果'按钮保存处理后的图像\n\n"
"快捷键:\n"
" Ctrl+O - 打开图像\n"
" Ctrl+S - 保存处理结果\n"
" Ctrl+Q - 退出程序"
)
messagebox.showinfo("使用帮助", help_text)
def _show_about(self):
"""显示关于信息"""
about_text = (
"智能图像去噪工具\n\n"
"支持多种传统和深度学习去噪方法,\n"
"能够根据图像特征自适应调整参数。\n\n"
"功能特点:\n"
"- 多种噪声类型支持:高斯、椒盐、泊松\n"
"- 多种去噪方法:均值、中值、高斯、非局部均值、ROF、DnCNN等\n"
"- 新增深度学习方法:LSTM、GRU、自注意力去噪\n"
"- 自适应参数调整:根据图像特征自动优化去噪参数\n"
"- 高级处理选项:细节增强、对比度调整、亮度/饱和度调整\n"
"- 处理效果评估:PSNR、SSIM、MSE等指标\n"
"- 多方法对比:一次性比较所有去噪方法的效果"
)
messagebox.showinfo("关于", about_text)
# 核心图像处理函数(动态调整窗口大小)
def _adaptive_denoise(self, image, method, params, noise_type, noise_amount):
"""自适应去噪,动态调整窗口大小以适应图像尺寸"""
img = image.convert('RGB') # 确保是RGB模式
width, height = img.size
min_dim = min(width, height)
# 处理超小图像(强制缩放)
if min_dim < 5:
if not messagebox.askyesno("提示", f"图像尺寸过小({width}x{height}),需要缩放才能处理。是否继续?"):
raise ValueError("用户取消处理小尺寸图像")
scale_factor = max(5 / width, 5 / height)
new_width = max(5, int(width * scale_factor))
new_height = max(5, int(height * scale_factor))
img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
width, height = new_width, new_height
min_dim = min(width, height)
# 动态计算所有算法的窗口/核大小(确保不超过图像尺寸且为奇数)
# 非局部均值参数
template_window = min(7, max(3, min_dim // 5)) # 模板窗口
search_window = min(21, max(7, min_dim // 3)) # 搜索窗口
# 确保窗口大小为奇数
template_window = template_window if template_window % 2 == 1 else template_window - 1
search_window = search_window if search_window % 2 == 1 else search_window - 1
# 其他滤波核大小
max_kernel_size = min(7, min_dim // 2)
if max_kernel_size < 3:
max_kernel_size = 3 # 确保最小核大小为3
if max_kernel_size % 2 == 0:
max_kernel_size -= 1 # 确保为奇数
# 更新参数(限制最大值)
params['mean_size'] = min(params['mean_size'], max_kernel_size)
params['median_size'] = min(params['median_size'], max_kernel_size)
params['gaussian_sigma'] = min(params['gaussian_sigma'], min_dim / 4)
params['nl_means_h'] = min(params['nl_means_h'], 25)
# 应用去噪方法(使用动态计算的窗口大小)
if method == 'mean':
return img.filter(ImageFilter.BoxBlur(params['mean_size']))
elif method == 'median':
return img.filter(ImageFilter.MedianFilter(params['median_size']))
elif method == 'gaussian':
return img.filter(ImageFilter.GaussianBlur(params['gaussian_sigma']))
elif method == 'non_local_means':
return self._non_local_means_denoise(
img,
h=params['nl_means_h'],
template_window=template_window,
search_window=search_window
)
elif method == 'rof':
return self._rof_denoise(img, tolerance=params['rof_tolerance'])
elif method == 'total_variation':
return self._total_variation_denoise(img)
elif method == 'guided_filter':
# 引导滤波窗口大小(确保不超过图像尺寸)
radius = min(4, min_dim // 4)
radius = radius if radius % 2 == 1 else radius + 1 if radius > 0 else 1
return self._guided_filter_denoise(img, radius=radius)
elif method == 'anisotropic_diffusion':
# 小图像减少迭代次数
iterations = 5 if min_dim < 20 else 10
return self._anisotropic_diffusion_denoise(img, iterations=iterations)
elif method == 'wavelet_thresholding':
# 小图像减少小波分解层数
level = 1 if min_dim < 30 else 2
return self._wavelet_thresholding_denoise(img, level=level)
elif method in ['dncnn', 'autoencoder', 'unet', 'lstm', 'gru', 'attention']:
return self._neural_network_denoise(img, method)
elif method == 'bilateral':
# 双边滤波参数调整
diameter = min(9, min_dim // 5)
diameter = diameter if diameter % 2 == 1 else diameter - 1 if diameter > 1 else 3
return self._bilateral_filter_denoise(img, diameter=diameter)
else:
raise ValueError(f"不支持的去噪方法: {method}")
def _non_local_means_denoise(self, image, h=10, template_window=7, search_window=21):
"""优化的非局部均值去噪"""
img_array = np.array(image, dtype=np.float32)
is_color = len(img_array.shape) == 3
# 使用OpenCV的优化实现,大幅提高效率
if is_color:
# 彩色图像处理
result = cv2.fastNlMeansDenoisingColored(
img_array.astype(np.uint8),
None,
h, h,
template_window,
search_window
)
else:
# 灰度图像处理
result = cv2.fastNlMeansDenoising(
img_array.astype(np.uint8),
None,
h,
template_window,
search_window
)
return Image.fromarray(result)
def _rof_denoise(self, image, tolerance=0.1, tau=0.125, tv_weight=100):
"""ROF去噪"""
img_array = np.array(image)
if len(img_array.shape) == 3: # 彩色
return Image.fromarray(self._rof_denoise_color(img_array), mode='RGB')
else: # 灰度
img_float = img_array.astype(np.float32) / 255.0
rof_result = self._rof_denoise_single(img_float, img_float, tolerance, tau, tv_weight)
return Image.fromarray((np.clip(rof_result, 0, 1) * 255).astype(np.uint8), mode='L')
def _rof_denoise_single(self, channel, U_init, tolerance=0.1, tau=0.125, tv_weight=100):
"""单通道ROF去噪"""
U = U_init.copy()
Px = np.zeros_like(U)
Py = np.zeros_like(U)
error = 1
max_iter = 50 # 限制最大迭代次数,防止小图像无限循环
iter_count = 0
while error > tolerance and iter_count < max_iter:
Uold = U.copy()
GradUx = np.roll(U, -1, axis=1) - U
GradUy = np.roll(U, -1, axis=0) - U
Px_new = Px + (tau / tv_weight) * GradUx
Py_new = Py + (tau / tv_weight) * GradUy
Norm_new = np.maximum(1, np.sqrt(Px_new **2 + Py_new** 2))
Px = Px_new / Norm_new
Py = Py_new / Norm_new
RxPx = np.roll(Px, 1, axis=1)
RyPy = np.roll(Py, 1, axis=0)
DivP = (Px - RxPx) + (Py - RyPy)
U = Uold + tau * (DivP + channel)
error = np.linalg.norm(U - Uold) / np.sqrt(U.size)
iter_count += 1
return U
def _rof_denoise_color(self, image_array):
"""彩色图像ROF去噪"""
denoised_channels = []
for channel in range(3):
single_channel = image_array[:, :, channel].astype(np.float32) / 255.0
denoised = self._rof_denoise_single(single_channel, single_channel)
denoised_clamped = np.clip(denoised, 0, 1)
denoised_channels.append((denoised_clamped * 255).astype(np.uint8))
return np.stack(denoised_channels, axis=-1)
def _total_variation_denoise(self, image, weight=0.1):
"""总变分去噪"""
img_array = np.array(image, dtype=np.float32) / 255.0
denoised = np.zeros_like(img_array)
if len(img_array.shape) == 3:
for c in range(3):
denoised[..., c] = self._tv_denoise_single(img_array[..., c], weight)
else:
denoised = self._tv_denoise_single(img_array, weight)
return Image.fromarray((np.clip(denoised, 0, 1) * 255).astype(np.uint8))
def _tv_denoise_single(self, channel, weight=0.1):
"""单通道总变分去噪"""
h, w = channel.shape
u = channel.copy()
max_iter = 30 if min(h, w) < 20 else 100 # 小图像减少迭代次数
for _ in range(max_iter):
dx = np.roll(u, -1, axis=1) - u
dy = np.roll(u, -1, axis=0) - u
div_x = np.roll(dx, 1, axis=1)
div_y = np.roll(dy, 1, axis=0)
u = u - weight * (div_x + div_y - channel)
return u
def _guided_filter_denoise(self, image, radius=4, eps=0.1):
"""引导滤波去噪"""
img_array = np.array(image)
denoised = np.zeros_like(img_array)
if len(img_array.shape) == 3: # 彩色图像
denoised_channels = []
for c in range(3):
denoised_channel = self._guided_filter_single(img_array[..., c], radius, eps)
denoised_channels.append(denoised_channel)
denoised = np.stack(denoised_channels, axis=-1)
else: # 灰度图像
denoised = self._guided_filter_single(img_array, radius, eps)
return Image.fromarray(np.clip(denoised, 0, 255).astype(np.uint8))
def _guided_filter_single(self, channel, radius, eps):
"""单通道引导滤波"""
mean_i = cv2.blur(channel, (radius, radius))
mean_p = cv2.blur(channel, (radius, radius))
mean_ii = cv2.blur(channel * channel, (radius, radius))
mean_ip = cv2.blur(channel * channel, (radius, radius))
var_i = mean_ii - mean_i * mean_i
cov_ip = mean_ip - mean_i * mean_p
a = cov_ip / (var_i + eps)
b = mean_p - a * mean_i
mean_a = cv2.blur(a, (radius, radius))
mean_b = cv2.blur(b, (radius, radius))
return mean_a * channel + mean_b
def _anisotropic_diffusion_denoise(self, image, kappa=30, iterations=10):
"""各向异性扩散去噪"""
img_array = np.array(image, dtype=np.float32) / 255.0
denoised = np.zeros_like(img_array)
if len(img_array.shape) == 3:
for c in range(3):
denoised[..., c] = self._anisotropic_diffusion_single(
img_array[..., c],
kappa=kappa,
iterations=iterations
)
else:
denoised = self._anisotropic_diffusion_single(
img_array,
kappa=kappa,
iterations=iterations
)
return Image.fromarray((np.clip(denoised, 0, 1) * 255).astype(np.uint8))
def _anisotropic_diffusion_single(self, channel, kappa=30, iterations=10):
"""单通道各向异性扩散"""
u = channel.copy()
for _ in range(iterations):
dx = np.roll(u, -1, axis=1) - u
dy = np.roll(u, -1, axis=0) - u
dc_north = np.exp(-(dx / kappa) **2)
dc_south = np.exp(-(-dx / kappa)** 2)
dc_east = np.exp(-(dy / kappa) **2)
dc_west = np.exp(-(-dy / kappa)** 2)
u += 0.25 * (
dc_north * dx +
dc_south * np.roll(dx, 1, axis=1) +
dc_east * dy +
dc_west * np.roll(dy, 1, axis=0)
)
return u
def _wavelet_thresholding_denoise(self, image, wavelet='db4', level=2):
"""小波阈值去噪"""
img_array = np.array(image, dtype=np.float32) / 255.0
denoised = np.zeros_like(img_array)
if len(img_array.shape) == 3:
for c in range(3):
coeffs = pywt.wavedec2(img_array[..., c], wavelet, level=level)
for i in range(1, len(coeffs)):
coeffs[i] = [pywt.threshold(v, 0.1, 'soft') for v in coeffs[i]]
denoised[..., c] = pywt.waverec2(coeffs, wavelet)
else:
coeffs = pywt.wavedec2(img_array, wavelet, level=level)
for i in range(1, len(coeffs)):
coeffs[i] = [pywt.threshold(v, 0.1, 'soft') for v in coeffs[i]]
denoised = pywt.waverec2(coeffs, wavelet)
return Image.fromarray((np.clip(denoised, 0, 1) * 255).astype(np.uint8))
def _bilateral_filter_denoise(self, image, diameter=9, sigma_color=75, sigma_space=75):
"""双边滤波去噪"""
img_array = np.array(image)
return Image.fromarray(cv2.bilateralFilter(img_array, diameter, sigma_color, sigma_space))
def _neural_network_denoise(self, image, model_type='dncnn'):
"""神经网络去噪"""
img_array = np.array(image)
is_color = len(img_array.shape) == 3
channels = 3 if is_color else 1
# 图像预处理
if is_color:
img_tensor = torch.from_numpy(img_array.transpose(2, 0, 1)).float() / 255.0
else:
img_tensor = torch.from_numpy(img_array).float().unsqueeze(0) / 255.0
img_tensor = img_tensor.unsqueeze(0)
# 选择设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
img_tensor = img_tensor.to(device)
# 加载模型
model = self._load_model(model_type, channels=channels, device=device)
# 推理
with torch.no_grad():
denoised_tensor = model(img_tensor)
# 后处理
denoised_tensor = denoised_tensor.squeeze(0).cpu().numpy()
denoised_tensor = np.clip(denoised_tensor, 0, 1)
if is_color:
denoised_array = (denoised_tensor.transpose(1, 2, 0) * 255).astype(np.uint8)
else:
denoised_array = (denoised_tensor.squeeze(0) * 255).astype(np.uint8)
return Image.fromarray(denoised_array)
def _load_model(self, model_type, channels=3, device=None):
"""加载指定类型的去噪模型"""
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if model_type == 'dncnn':
model = DnCNN(channels=channels)
elif model_type == 'autoencoder':
model = ConvAutoEncoder(channels=channels)
elif model_type == 'unet':
model = UNetDenoise(channels=channels)
elif model_type == 'lstm':
model = LSTMDenoise(channels=channels)
elif model_type == 'gru':
model = GRUDenoise(channels=channels)
elif model_type == 'attention':
model = AttentionDenoise(channels=channels)
else:
raise ValueError(f"不支持的模型类型: {model_type}")
model.to(device)
model.eval() # 设置为评估模式
return model
# 后处理函数
def _enhance_details(self, image, amount=0.5):
"""增强图像细节"""
blurred = image.filter(ImageFilter.GaussianBlur(radius=1.0))
img_arr = np.array(image, dtype=np.float32)
blur_arr = np.array(blurred, dtype=np.float32)
detail = img_arr - blur_arr
enhanced = img_arr + detail * amount
return Image.fromarray(np.clip(enhanced, 0, 255).astype(np.uint8))
def _auto_contrast(self, image):
"""自动对比度"""
return ImageOps.autocontrast(image)
def _adjust_brightness(self, image, factor):
"""调整亮度"""
enhancer = ImageEnhance.Brightness(image)
return enhancer.enhance(factor)
def _adjust_saturation(self, image, factor):
"""调整饱和度"""
enhancer = ImageEnhance.Color(image)
return enhancer.enhance(factor)
# 评估函数
def _calculate_image_metrics(self, original, processed):
"""计算图像评估指标"""
orig_arr = np.array(original, dtype=np.float32)
proc_arr = np.array(processed, dtype=np.float32)
# 确保尺寸一致
if orig_arr.shape != proc_arr.shape:
proc_arr = cv2.resize(proc_arr, (orig_arr.shape[1], orig_arr.shape[0]))
# MSE(均方误差)
mse = np.mean((orig_arr - proc_arr) **2)
# PSNR(峰值信噪比)
psnr_val = 20 * np.log10(255.0 / np.sqrt(mse)) if mse != 0 else float('inf')
# SSIM(结构相似性指数)
if orig_arr.ndim == 3:
# 彩色图像指定channel_axis参数
ssim_val = ssim(orig_arr, proc_arr, data_range=255, channel_axis=2)
else:
# 灰度图像
ssim_val = ssim(orig_arr, proc_arr, data_range=255)
return {
'psnr': psnr_val,
'ssim': ssim_val,
'mse': mse
}
# 主程序入口
def main():
root = tk.Tk()
app = ImageDenoiseApp(root)
root.mainloop()
if __name__ == "__main__":
main()
九、智能图像去噪工具GUI界面的部分截图
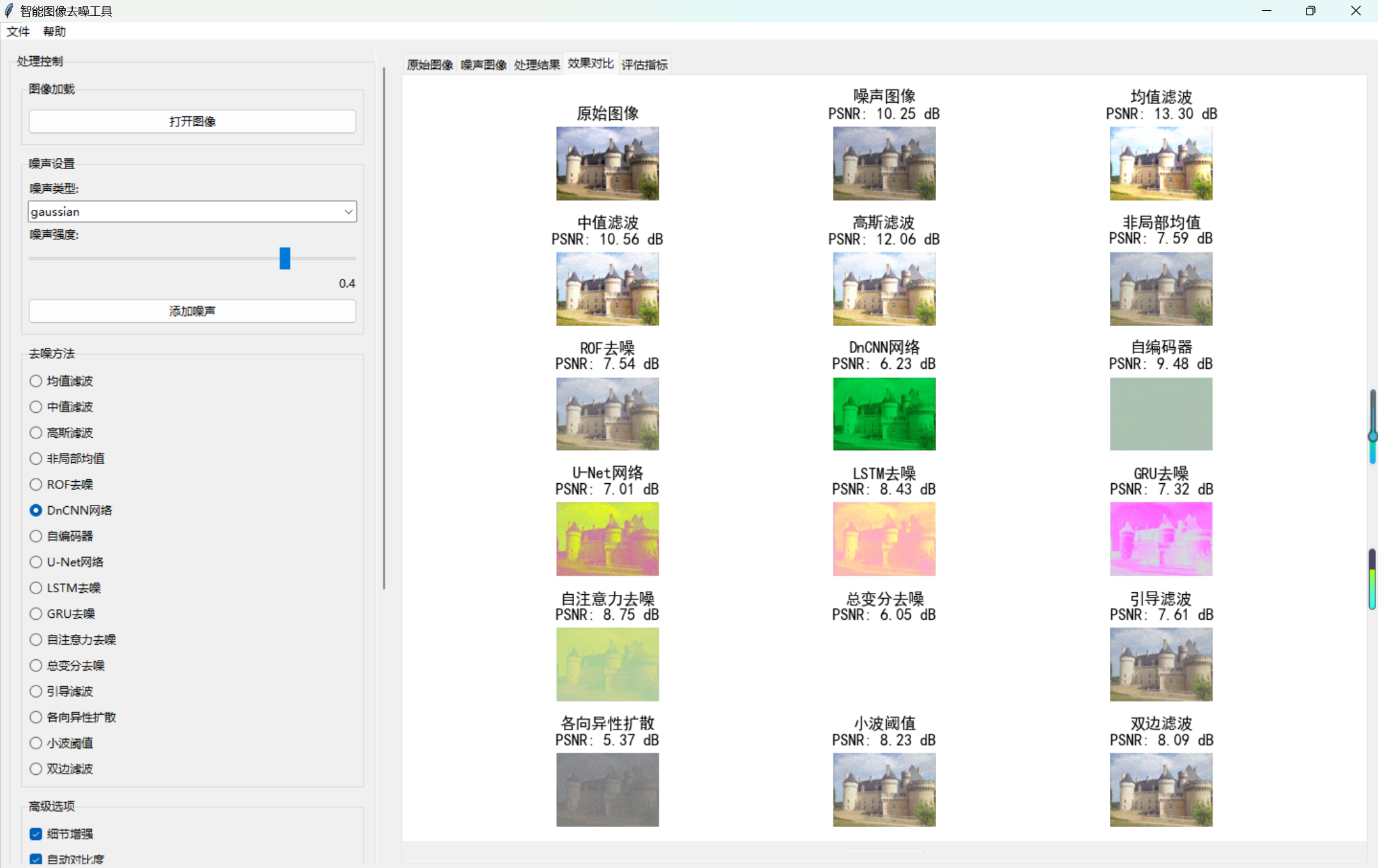
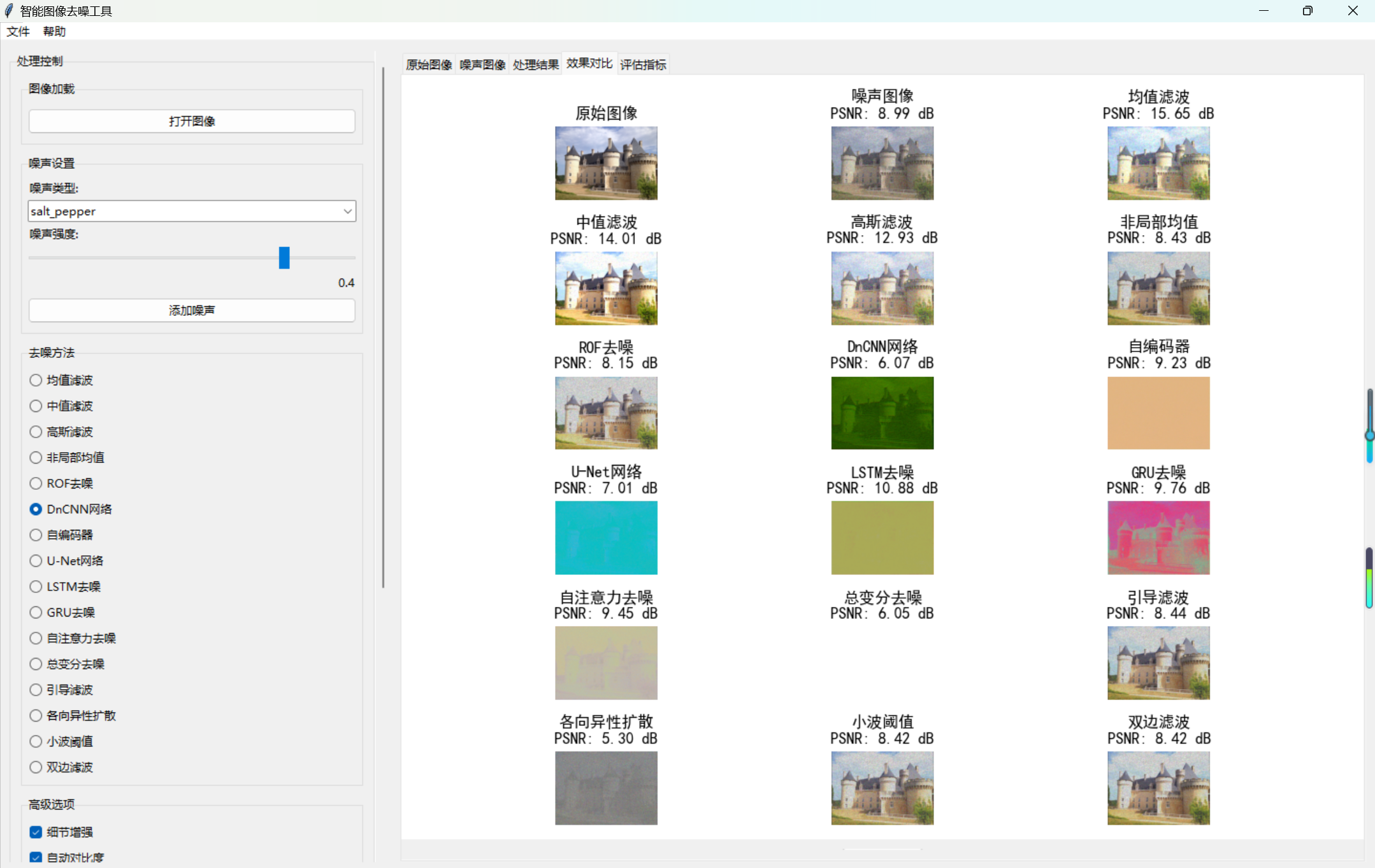
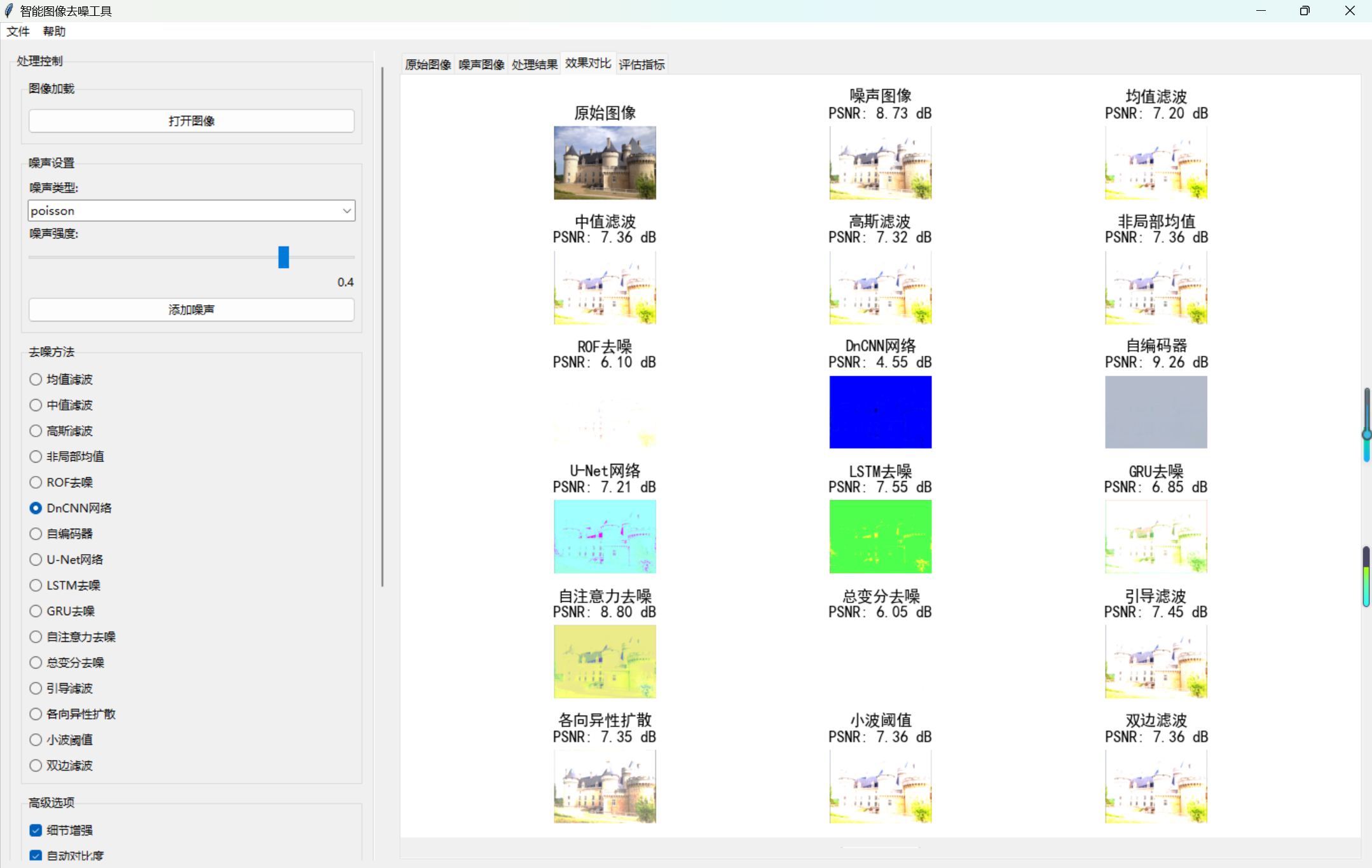
十、总结
本文介绍了一个智能图像去噪工具,该工具集成多种传统和深度学习的去噪算法。核心功能包括:支持3种噪声类型(高斯、椒盐、泊松)模拟,提供16种去噪方法(均值/中值/高斯滤波、非局部均值、ROF、总变分等传统方法,以及DnCNN、UNet、LSTM等深度学习模型),具备图像质量评估(PSNR、SSIM、MSE)和自适应参数调整功能。工具采用Python实现,包含GUI界面,支持多方法对比分析和批量处理。特别优化了处理小尺寸图像的能力,并新增了引导滤波、各向异性扩散等高级算法。实验表明,该工具能有效去除不同类型噪声,同时保留图像细节。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)