强化学习(三)—— Model-Free Prediction
强化学习基础——model based prediction
文章目录
Reference
[1] David Silver: https://www.youtube.com/watch?v=PnHCvfgC_ZA&t=2938s
在强化学习(二)中,我们学习了使用动态规划法进行策略评估。DP策略评估通过循环迭代贝尔曼期望方程直至收敛,来获得最优价值函数。
但是在model-based环境下,我们无法得知即时奖励以及状态转移概率。所以也就不能通过DP策略评估来获得最优价值函数值了。这种情况下我们可以通过大量的采样来近似模拟最优价值函数值。
1. 蒙特卡洛策略评估(Monte-Carlo Learning)
(1)定义
蒙特卡洛策略评估通过采用多条完整的轨迹,然后使用轨迹回报的经验均值来预估状态价值函数。MC只能从完整的轨迹序列中学习。
1.1 First-Visit MC

1.2 Every-Visit MC

1.3 Incremental MC
增量均值
经验均值 1 k ∑ j = 1 k x j \frac{1}{k}\sum_{j=1}^{k}x_j k1∑j=1kxj也可以通过增量形式表示: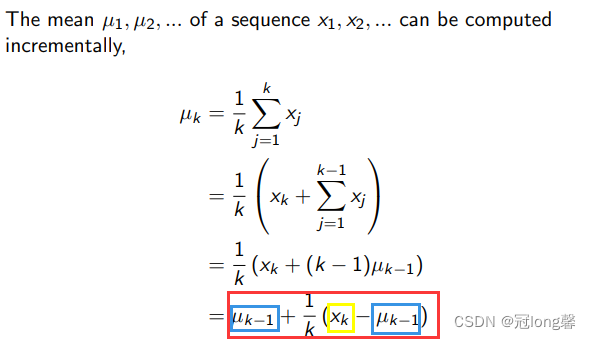
因此蒙特卡洛策略评估也可以通过增量形式表示:
理解: 轨迹回报的均值 V ( S t ) V(S_t) V(St)可以通过采样轨迹的回报与当前均值的差值乘上学习率予以修正。
2. 时序差分策略评估(Temporal-Difference Learning)
(1)定义
时序差分法可以在不完整的序列上进行学习。TD方法通过预测对预测进行更新(updates a guess towards guess)。
相比于蒙特卡洛方法,TD(0)通过本身对下一个状态价值函数的预测和即时奖励代替了轨迹回报 G t G_t Gt。通过TD-error和学习率的成绩对价值函数的预测值进行修正。
3. 比较MC&TD(0)
(1)MC
- MC必须在完整轨迹上学习
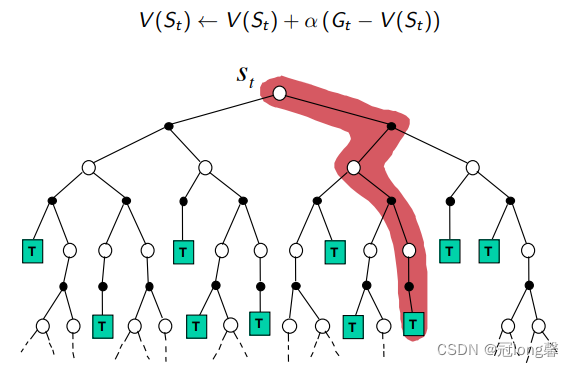
- MC方法是无偏估计,但方差较高。
①通过计算每段完整轨迹的奖励来更新获得价值函数,相比于TD具有更多的随机性与方差。
(2)TD
- TD可以在不完整的轨迹上学习
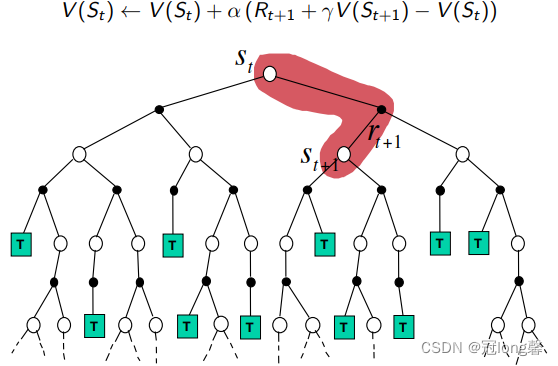
- TD方法方差较低,但是有偏估计。
①在每一个时间步上,通过奖励以及下一状态的预估值对价值函数进行更新。 - TD相对于MC算法运行效率更高。
(3)DP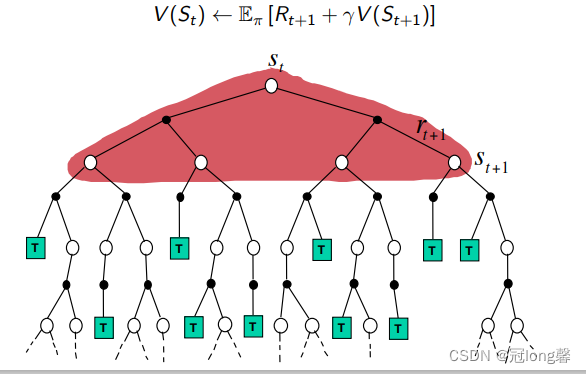

3. TD( λ \lambda λ)
3.1 n-Step TD
TD(0)算法仅考虑了未来采取一步动作后获得的回报(1-Step)。同理我们可以考虑未来采取n步动作后能采取的回报,利用n步回报作为TD target更新价值函数。因此也就可以获得n步时序差分学习方式。
我们可以通过加权求和的方式,获得从1-n步TD-Targe的均值 G t λ G_t^\lambda Gtλ。
3.2 λ \lambda λ-return
令 λ ∈ [ 0 , 1 ] \lambda \in[0,1] λ∈[0,1],对从0-1步的TD-Target进行加权。使用加权后的均值更新价值函数的方法,也就是 T D ( λ ) TD(\lambda) TD(λ)。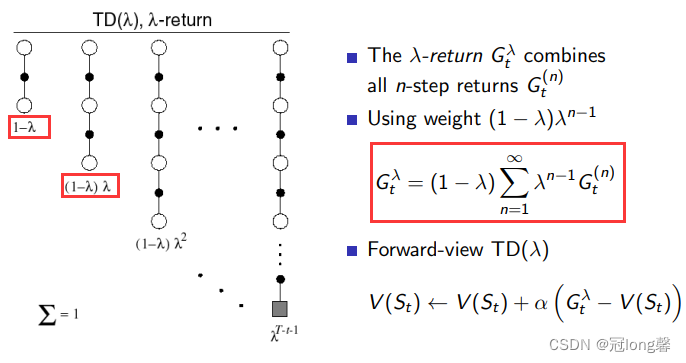
- 当 λ = 0 \lambda=0 λ=0时,也就是采用了时序差分方法TD(0)。
- 当 λ = 1 \lambda=1 λ=1时,也就是采用了蒙特卡洛方法MC。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)