使用DCGAN实现动漫图像生成
王晓睿,男,西安工程大学电子信息学院,2024级研究生,张宏伟人工智能课题组研究方向:智能视觉检测与工业自动化技术电子邮件:3234002295@qq.com。
使用DCGAN实现动漫图像生成
使用DCGAN实现动漫图像生成
1.作者介绍
王晓睿,男,西安工程大学电子信息学院,2024级研究生,张宏伟人工智能课题组
研究方向:智能视觉检测与工业自动化技术
电子邮件:3234002295@qq.com
2.GAN
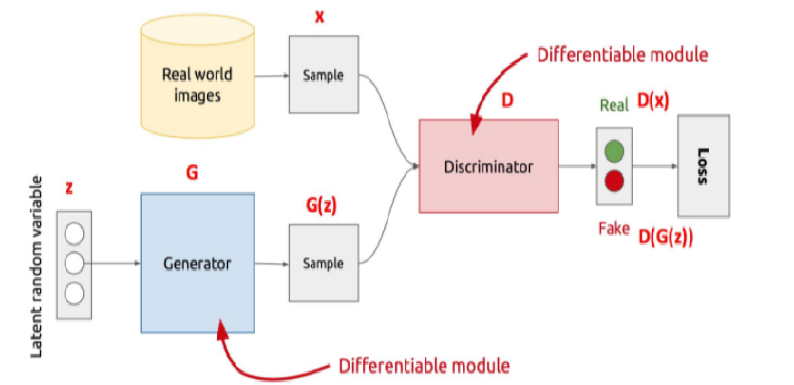
(1)GAN:生成式对抗网络,2014年首次提出。其核心思想是通过对抗训练过程来生成与真实数据相似的假数据。
(2)生成器(Generator):生成器的任务是通过从噪声(通常是一个随机的向量)中生成尽可能真实的假数据。它不断优化,希望生成越来越真实的数据来欺骗判别器。
(3)判别器(Discriminator):判别器的任务是判断输入的数据是真实数据(来自训练集)还是假数据(由生成器生成)。
(4)GAN的训练过程是一个博弈过程,生成器和判别器通过不断的对抗进行优化,最终目的是生成器能够生成与真实数据非常相似的假数据,使得判别器无法区分真伪。
3.DCGAN
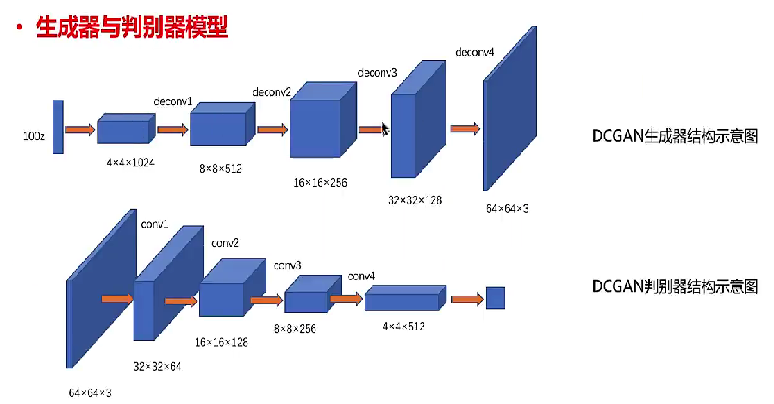
(1)DCGAN:深度卷积生成对抗网络,是 GAN 的一种改进版本,采用了 卷积层和反卷积层(即转置卷积)替代传统的全连接层,来增强生成器和判别器的表现。
(2)生成器:任务是从随机噪声z中生成图像,通过反卷积层逐步增加特征图的尺寸,将低维的潜在空间映射到高维的图像空间。
(3)判别器:由多个卷积层组成,每一层都会对图像进行下采样(即缩小图像尺寸),最后得到一维输出,也就是真假的判别。
3.1相比GAN的改进
(1)使用批量归一化,训练更稳定,加速收敛。
(2)移除全连接层,采用全卷积结构,更适合处理图像数据。
(3)去除了池化层,使用步幅卷积来代替,避免了信息丢失。
(4)生成器的最后一层网络输出使用 Tanh 激活函数,将图像像素值标准化到[-1,1],适配训练数据的归一化要求。
(5)判别器用sigmoid 激活函数,将输出压缩到[0,1],表示真假概率。
4.Anime Faces 数据集
Anime Faces数据集包含了 21551 张动漫面孔图像,是从 www.getchu.com 抓取的动漫面孔组成的数据库,然后使用 https://github.com/nagadomi/lbpcascade_animeface 中的动漫面孔检测算法进行裁剪。所有图像都调整为 64 * 64 来方便使用。
获取链接:https://www.kaggle.com/datasets/soumikrakshit/anime-faces/data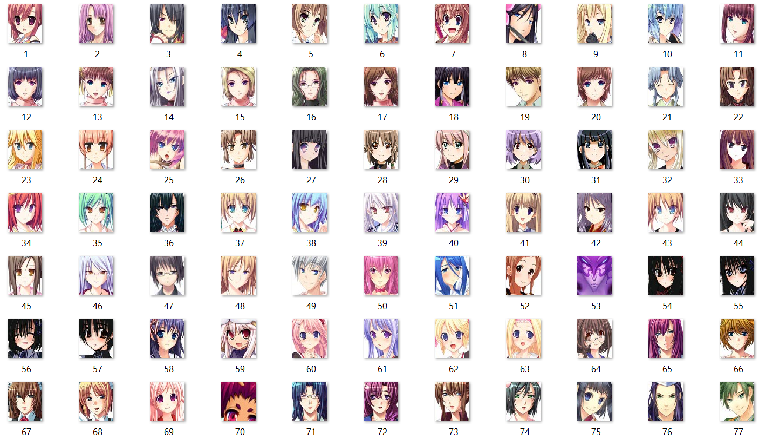
5.代码
model.py
import torch
import torch.nn as nn
#初始化网络中的权重
def apply_weights(model):
classname = model.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
#判别器由多个卷积层(Conv2d)和批量归一化层(BatchNorm2d)组成
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),#激活函数
nn.Conv2d(512, 1, kernel_size=4, stride=2, padding=0),
nn.Sigmoid()#输出概率值
)
def forward(self, x):
return self.model(x)
#生成器由多个转置卷积层(ConvTranspose2d)组成
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.ConvTranspose2d(100, 1024, kernel_size=4, stride=1, padding=0),
nn.BatchNorm2d(1024),
nn.ReLU(),
nn.ConvTranspose2d(1024, 512, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128, 3, kernel_size=4, stride=2, padding=1),
nn.Tanh(),#输出
)
def forward(self, x):
return self.model(x)
#生成器的损失函数
def modified_g_loss(fake_output, eps=1e-6):
loss = (fake_output + eps).log().mean()
return loss.neg()
train.py
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
import argparse
import random
import os
from model import Discriminator, Generator, apply_weights, modified_g_loss
def get_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', dest='dataset', help='Path of the dataset', default=r'/data/students/master/2024/wangxr/archive')
parser.add_argument('--epoch', dest='epoch', help='Number of training epochs', default=200,type=int)
parser.add_argument('--device', dest='device', help='Specify the training device (default: GPU)', default='cuda' if torch.cuda.is_available() else 'cpu')
parser.add_argument('--continue', dest='cont_train', help='Continue training?', default=False)
parser.add_argument('--seed', dest='seed', help='Specify Random Seed', default=None)
options = parser.parse_args()
print(f'Training on {options.device}')
if not options.seed:
options.seed = random.randint(1, 1000)
random.seed(int(options.seed))
torch.manual_seed(int(options.seed))
return options
def load_data(data_dir):
transform = transforms.Compose([
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
dataset = datasets.ImageFolder(data_dir, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, shuffle=True, batch_size=128)
return dataloader
def models_init():
netD = Discriminator()
netG = Generator()
apply_weights(netD)
apply_weights(netG)
return netD, netG
def train(netD, netG, dataloader, num_epochs, device, check=False):
if check:
netD.load_state_dict(torch.load('./Discriminator.pth'))
netG.load_state_dict(torch.load('./Generator.pth'))
print('\nContinuing Training...\n')
else:
print('Starting Training...\n')
netD.to(device)
netG.to(device)
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))
lossD_list = [] # To store lossD values for plotting
lossG_list = [] # To store lossG values for plotting
for epoch in range(num_epochs):
torch.save(netD.state_dict(), f'Discriminator.pth')
torch.save(netG.state_dict(), f'Generator.pth')
for idx, (images, _) in enumerate(dataloader):
images = images.to(device)
optimizerD.zero_grad()
output = netD(images).reshape(-1)
# 解决 smooth_real > 1.0 的问题
smooth_real = round(random.uniform(0.7, 1.0), 2)
labels = (smooth_real * torch.ones(images.shape[0])).to(device)
labels = labels.clamp(0, 1) # 确保 labels 在 [0,1] 之间
lossD_real = criterion(output, labels)
fake = netG(torch.randn(images.shape[0], 100, 1, 1).to(device))
output = netD(fake.detach()).reshape(-1)
smooth_fake = round(random.uniform(0.0, 0.3), 2)
labels = (smooth_fake * torch.ones(images.shape[0])).to(device)
labels = labels.clamp(0, 1) # 确保 labels 在 [0,1] 之间
lossD_fake = criterion(output, labels)
lossD = lossD_real + lossD_fake
lossD.backward()
optimizerD.step()
optimizerG.zero_grad()
output = netD(fake).reshape(-1)
lossG = modified_g_loss(output)
lossG.backward()
optimizerG.step()
if idx % 50 == 0 and idx != 0:
print(f'epoch[{epoch+1:3d}/{num_epochs}]=> lossD: {lossD.item():.4f}\tlossG: {lossG.item():.4f}')
# Save loss values for each epoch
lossD_list.append(lossD.item())
lossG_list.append(lossG.item())
# Plot the loss curves after training
plot_losses(lossD_list, lossG_list)
def plot_losses(lossD_list, lossG_list):
# Create "loss" directory if it doesn't exist
if not os.path.exists('loss'):
os.makedirs('loss')
plt.figure(figsize=(10, 5))
plt.plot(range(len(lossD_list)), lossD_list, label='Discriminator Loss (lossD)', color='blue')
plt.plot(range(len(lossG_list)), lossG_list, label='Generator Loss (lossG)', color='red')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('LossD and LossG Over Epochs')
plt.legend()
plt.grid(True)
plt.savefig('loss/training_loss.png') # Save the loss plot to a file in the "loss" folder
plt.show()
if __name__ == '__main__':
arguments = get_arguments()
dataloader = load_data(arguments.dataset)
netD, netG = models_init()
train(netD, netG, dataloader, int(arguments.epoch), arguments.device, arguments.cont_train)
test.py
import matplotlib.pyplot as plt
import torch
import numpy as np
from model import Discriminator, Generator
import argparse
import os
#获取命令行参数
def get_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--path', dest='path', help='Specify the path to save the images', default='./finally/') # 修改为保存到finally目录
parser.add_argument('--num_images', dest='num_images', help='number of characters to be created', type=int, default=25) # 生成25张图像
options = parser.parse_args()
if not options.path:
options.path = './finally/'
if not options.num_images:
parser.error('[-] Number of characters not defined')
return options
# 创建 finally 目录
def create_directories(path):
if not os.path.exists(path):
os.mkdir(path)
#加载训练好的模型
def load_model():
model = Generator() #创建Generator 模型的实例
model.load_state_dict(torch.load('Generator.pth')) #加载生成器模型权重
return model
#生成图像
def generate(model, num_images):
images = model(torch.randn(num_images, 100, 1, 1)) # 使用噪声生成指定数量的图像
return images.detach().numpy()
#创建并保存5×5图像网格
def save_grid_image(path, images, grid_size=(5, 5)):
fig, axs = plt.subplots(grid_size[0], grid_size[1], figsize=(10, 10))
for i in range(grid_size[0]):
for j in range(grid_size[1]):
img_idx = i * grid_size[1] + j
if img_idx < len(images):
axs[i, j].imshow(images[img_idx].transpose(1, 2, 0))
axs[i, j].axis('off')
else:
axs[i, j].axis('off')
plt.subplots_adjust(wspace=0, hspace=0)
plt.savefig(path + 'anime_grid.png', bbox_inches='tight')
plt.show()
#主程序
if __name__ == '__main__':
arguments = get_arguments()
create_directories(arguments.path) # 创建 finally 目录
model = load_model()
print('Generating Characters...')
images = generate(model, int(arguments.num_images)) # 生成图像
print('Saving Characters as a grid...')
save_grid_image(arguments.path, images, grid_size=(5, 5)) # 保存为 5x5 网格图像
print('Done')
6.运行结果
取lr_D=0.0002;lr_G=0.0002,分别训练50轮、100轮、150轮、200轮,得图像如下所示: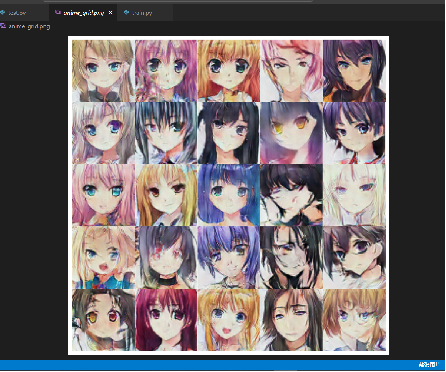
(50轮)
100轮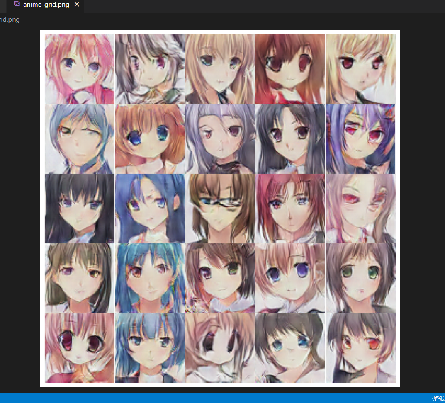
150轮(效果较好)
200轮
7.补充问题
训练轮数(epochs)对模型训练的效果有很大的影响。
(1)训练轮数太少:生成器则没有足够的时间学习真实数据的分布,它生成的假数据可能会相差较大,无法接近真实数据。模型也可能无法达到收敛状态,损失值(loss)可能没有明显下降,甚至没有稳定。
(2)训练轮数太多:可能导致模型在训练集上过拟合,即模型学得过于详细,甚至捕捉到了训练数据中的噪声和无关特征。虽然模型在训练集上的表现很好,但它可能无法泛化到新的数据(测试集),导致生成的图像多样性下降,且质量降低。
学习率(Learning Rate)是深度学习训练过程中非常重要的一个超参数。它决定了每次参数更新的步长,即在优化过程中每次权重更新的幅度。学习率的选择对于模型训练的稳定性和最终结果有着极大的影响。
(1)学习率太高:可能导致模型训练过程中的梯度更新幅度过大,优化过程不稳定。这样可能导致损失函数震荡,甚至发散,无法收敛到最优解。
(2)学习率太低:学习率过低意味着每次参数更新的幅度太小,模型学习进程会变得非常缓慢。虽然训练过程会稳定,但模型收敛的速度较慢,需要更多的训练轮次;模型也可能会陷入局部最优解,而无法跳出这些局部解来找到全局最优解。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 33
33 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)