机器学习:Python招聘数据可视化分析+薪资预测+推荐系统 大数据毕业设计(建议收藏) ✅
机器学习:Python招聘数据可视化分析+薪资预测+推荐系统 大数据毕业设计(建议收藏) ✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
一、说明
技术栈:
Python语言、Flask框架、Layui前端框架、基于标签的推荐算法、拉钩招聘、7个预测模型、sklearn机器学习、神经网络
1.数据采集和数据预处理获取有效招聘数据,实现数据总览
2.数据可视化生成招聘数据可视化图像;
3.基于Layui框架建立网站前端:
4.采用基于标签的推荐算法,结合基于内容和基于协同过滤的推荐算法实现个性化推荐;
5.基于机器学习建立了7个预测模型,通过最优对比选择了神经网络作为薪资预测模型。
2、项目界面
(1)全国岗位分布分析
(2)岗位数量分析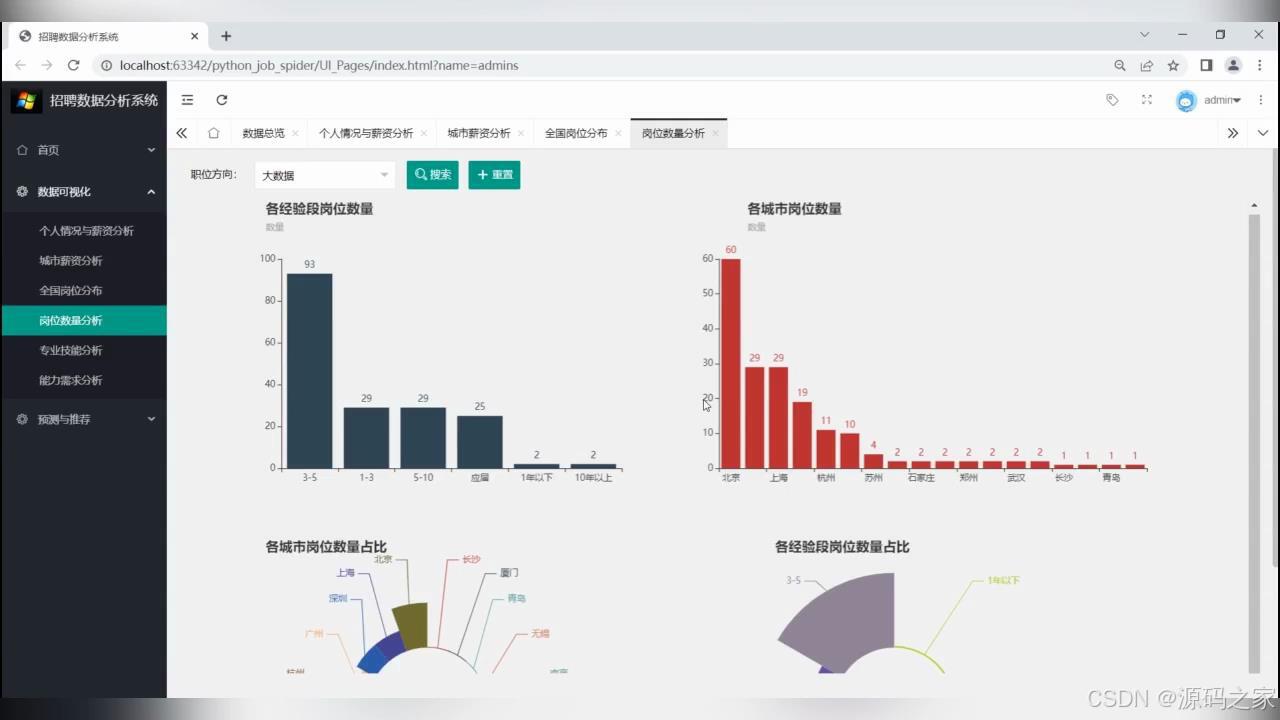
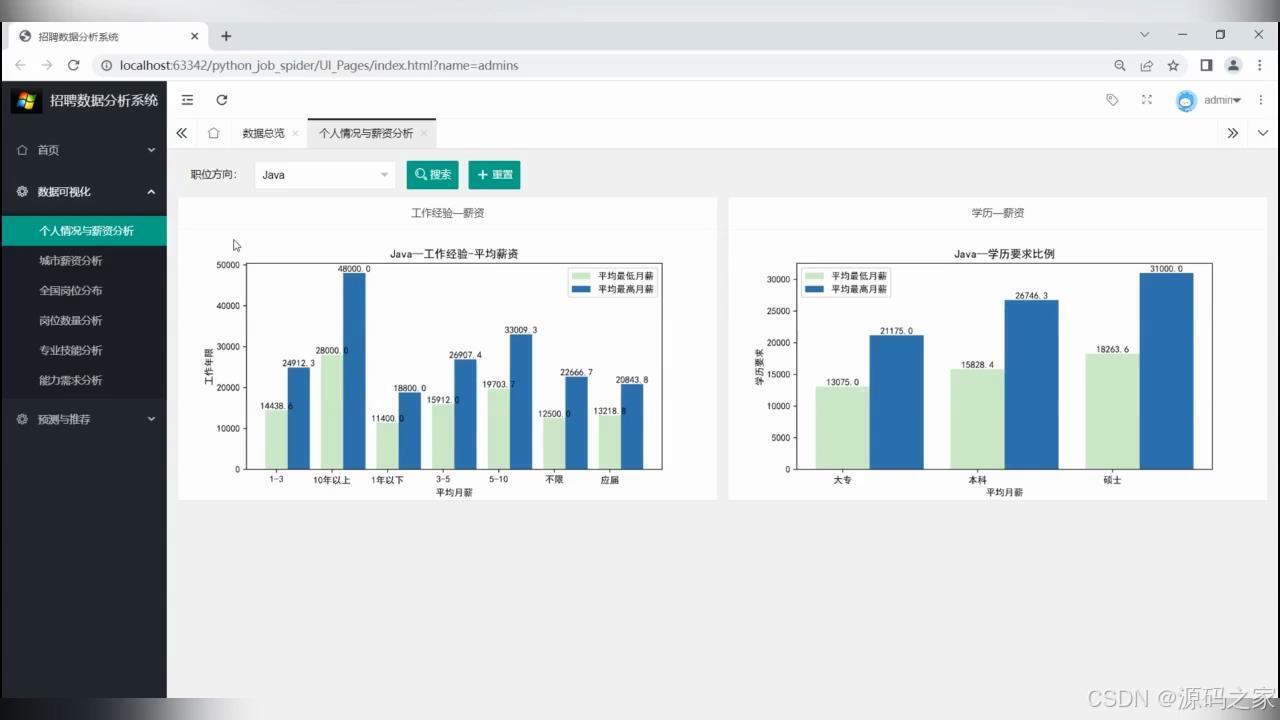
(3)薪资情况分析
(4)能力需求分析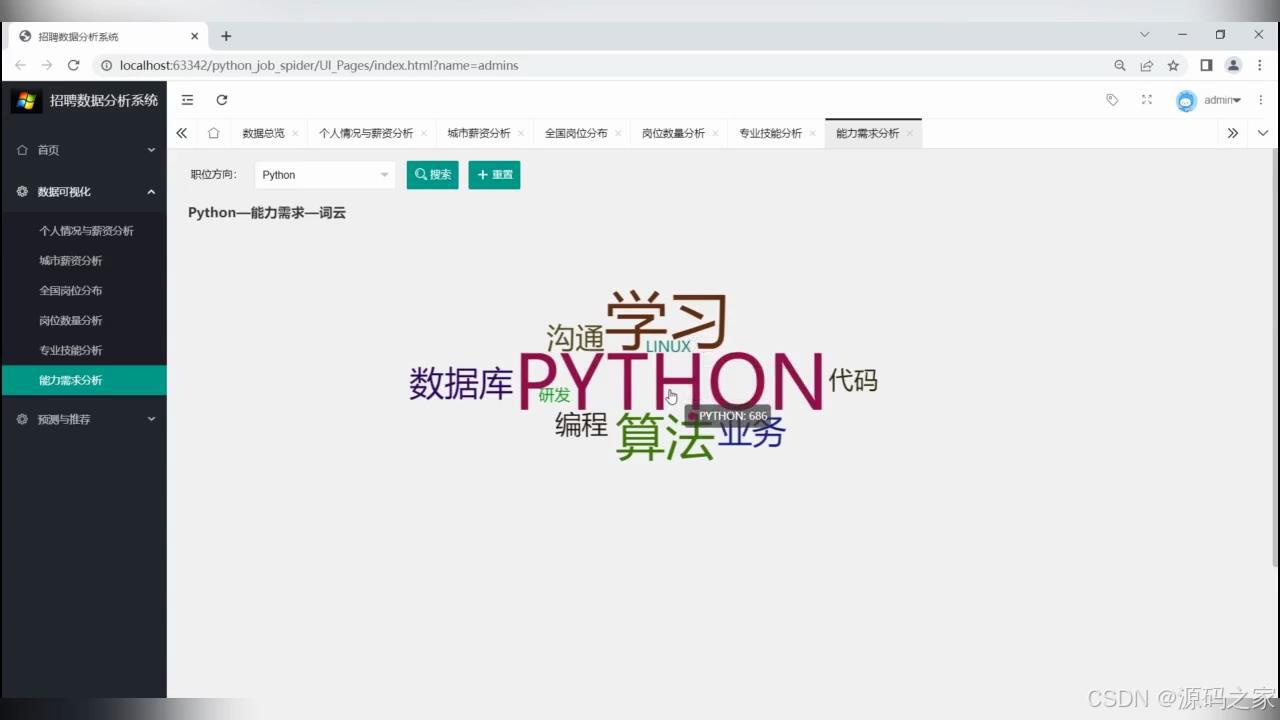
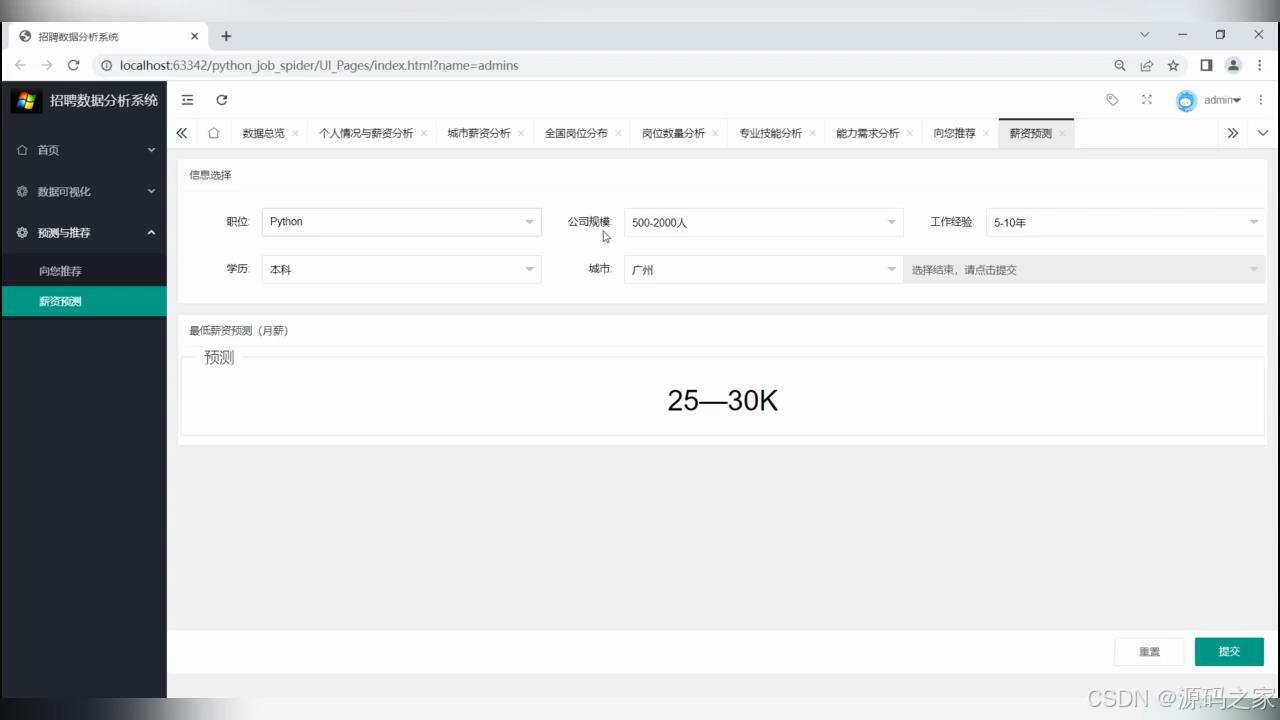
(5)薪资预测
(6)岗位推荐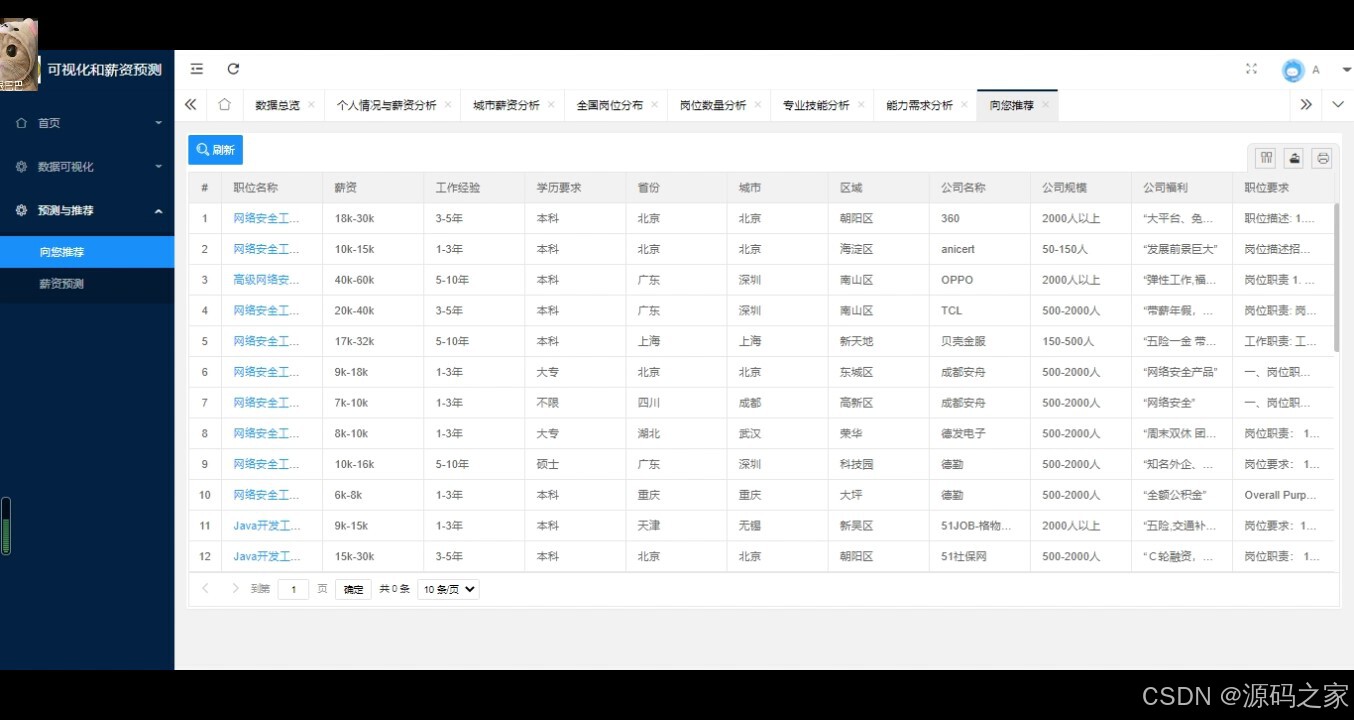
3、项目说明
一、说明
1.数据采集和数据预处理获取有效招聘数据,实现数据总览
2.数据可视化生成招聘数据可视化图像;
3.基于Layui框架建立网站前端:
4.采用基于标签的推荐算法,结合基于内容和基于协同过滤的推荐算法
实现个性化推荐;
5.基于机器学习建立了7个预测模型,通过最优对比选择了神经网络作为薪资预测模型。
二、功能
数据总览:
1.查询所有招聘信息
2.查询指定信息
数据可视化:
1.工作经验-新资
2.学历-薪资
3.岗位数量分析
4.岗位全国分布情况
5.岗位专业技能需求
6.岗位职场能力需求
预测与推荐:
1.根据已知数据预测薪资
2.推荐适合用户的岗位信息
三、基于标签的推荐算法
这个算法结合了基于内容和基于协同过滤两种推荐算法。计算用户对岗位的兴趣度,然后向该用户推荐兴趣度最高的的岗位信息因为热门标签的数据在推荐算法中具有很大的权重,缺少了个性化,用户对物品的兴趣度也会收到影响。这里我们可以通过TF-IDF的思想来改善算法。
四、建立薪资预测模型
系统将招聘数据中的“学历”、“工作经验”、“公司规模”和“城市”作为影响因子,将薪资按照5k为区间进行划分。此外,还需要使用SMOTE算法解决数据样本数量不均衡的问题。SMOTE是一种合成少数群体过采样技术,通过分析少数类样本,并在少数样本的基础上人工合成新样本,并将其添加到数据集中。
评判模型的指标有准确率、精确率、调和平均值以及均方误差等。
4、核心代码
from math import log
from flask import Flask,request,url_for, jsonify
import pymysql
from flask_cors import *
app = Flask(__name__)
app.config['JSON_AS_ASCII'] = False
CORS(app, supports_credentials=True)
from flask.json import JSONEncoder as _JSONEncoder
class JSONEncoder(_JSONEncoder):
def default(self, o):
import decimal
if isinstance(o, decimal.Decimal):
return float(o)
super(JSONEncoder, self).default(o)
app.json_encoder = JSONEncoder
def load_data(file_path):
records = []
f = open(file_path, "r", encoding="utf-8")
for line in f:
info = line.strip().split("\t")
records.append(info)
f.close()
return records
def InitStat(records):
user_tags = dict() # 用户打过标签的次数
tag_items = dict() # 数据被打过标签的次数,代表数据流行度
for user, item, tag in records:
user_tags.setdefault(user, dict())
user_tags[user].setdefault(tag, 0)
user_tags[user][tag] += 1
tag_items.setdefault(tag, dict())
tag_items[tag].setdefault(item, 0)
tag_items[tag][item] += 1
return user_tags, tag_items
def InitStat_update(records):
user_tags = dict() # 用户打过标签的次数
tag_items = dict() # 数据被打过标签的次数,代表数据流行度
tag_user = dict() # 标签被用户标记次数
for user, item, tag in records:
user_tags.setdefault(user, dict())
user_tags[user].setdefault(tag, 0)
user_tags[user][tag] += 1
tag_items.setdefault(tag, dict())
tag_items[tag].setdefault(item, 0)
tag_items[tag][item] += 1
tag_user.setdefault(tag, dict())
tag_user[tag].setdefault(user, 0)
tag_user[tag][user] += 1
return user_tags, tag_items, tag_user
def InitStat_update_2(records):
user_tags = dict() # 用户打过标签的次数
tag_items = dict() # 数据被打过标签的次数,代表数据流行度
tag_user = dict() # 标签被用户标记次数
item_user = dict() # 数据被不同用户标记次数
for user, item, tag in records:
user_tags.setdefault(user, dict())
user_tags[user].setdefault(tag, 0)
user_tags[user][tag] += 1
tag_items.setdefault(tag, dict())
tag_items[tag].setdefault(item, 0)
tag_items[tag][item] += 1
tag_user.setdefault(tag, dict())
tag_user[tag].setdefault(user, 0)
tag_user[tag][user] += 1
item_user.setdefault(item, dict())
item_user[item].setdefault(user, 0)
item_user[item][user] += 1
return user_tags, tag_items, tag_user, item_user
def Recommend(user, K):
recommend_items = dict()
for tag, wut in user_tags[user].items():
for item, wti in tag_items[tag].items():
if item not in recommend_items:
recommend_items[item] = wut * wti # 计算用户对物品兴趣度
else:
recommend_items[item] += wut * wti
rec = sorted(recommend_items.items(), key=lambda x: x[1], reverse=True) # 将推荐数据按兴趣度排名
print(">>>>>>", rec)
recruit = []
for i in range(K):
recruit.append(rec[i][0])
recruit = "/".join(recruit)
return recruit
def Recommend_update(user, K):
recommend_items = dict()
for tag, wut in user_tags[user].items():
for item, wti in tag_items[tag].items():
if item not in recommend_items:
recommend_items[item] = wut * wti / log(1 + len(tag_user[tag])) # 计算用户对物品兴趣度
else:
recommend_items[item] += wut * wti / log(1 + len(tag_user[tag]))
rec = sorted(recommend_items.items(), key=lambda x: x[1], reverse=True) # 将推荐按兴趣度排名
print(">>>>>>", rec)
recruit = []
for i in range(K):
recruit.append(rec[i][0])
recruit = "/".join(recruit)
return recruit
def Recommend_update_2(user, K):
recommend_items = dict()
for tag, wut in user_tags[user].items():
for item, wti in tag_items[tag].items():
if item not in recommend_items:
recommend_items[item] = (wut / log(1 + len(tag_user[tag]))) * (
wti / log(1 + len(item_user[item]))) # 计算用户对物品兴趣度
else:
recommend_items[item] += (wut / log(1 + len(tag_user[tag]))) * (wti / log(1 + len(item_user[item])))
rec = sorted(recommend_items.items(), key=lambda x: x[1], reverse=True) # 将推荐按兴趣度排名
print(">>>>>>", rec)
recruit = []
for i in range(K):
recruit.append(rec[i][0])
recruit = ",".join(recruit)
return recruit
if __name__ == '__main__':
file_path = u"recommend-recruit.txt"
records = load_data(file_path)
user_tags, tag_items, tag_user, item_user = InitStat_update_2(records)
print("用户打过标签的次数: ", user_tags)
print("数据打过标签的次数: ", tag_items)
print("标签被用户使用次数: ", tag_user)
print("数据被用户标记次数: ", item_user)
rec2 = Recommend_update_2("A", 2)
rec=rec2.split(',')
rec_x=[]
for value in rec:
if(value not in rec_x):
rec_x.append(value)
for value in rec_x:
rec_2=value
print("2推荐招聘数据: ", rec_2)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 10
10 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)