强化学习入门笔记
智能体通过试错和奖励反馈不断优化决策策略,以追求最大化累积回报的方法-RL
Review:两种机器学习类型
预测
根据数据预测所需输出(有监督学习)
生成数据实例(无监督学习)
决策
在动态环境中采取行动(强化学习)
转变到新的状态
获得即时奖励
随着时间的推移最大化累计奖励
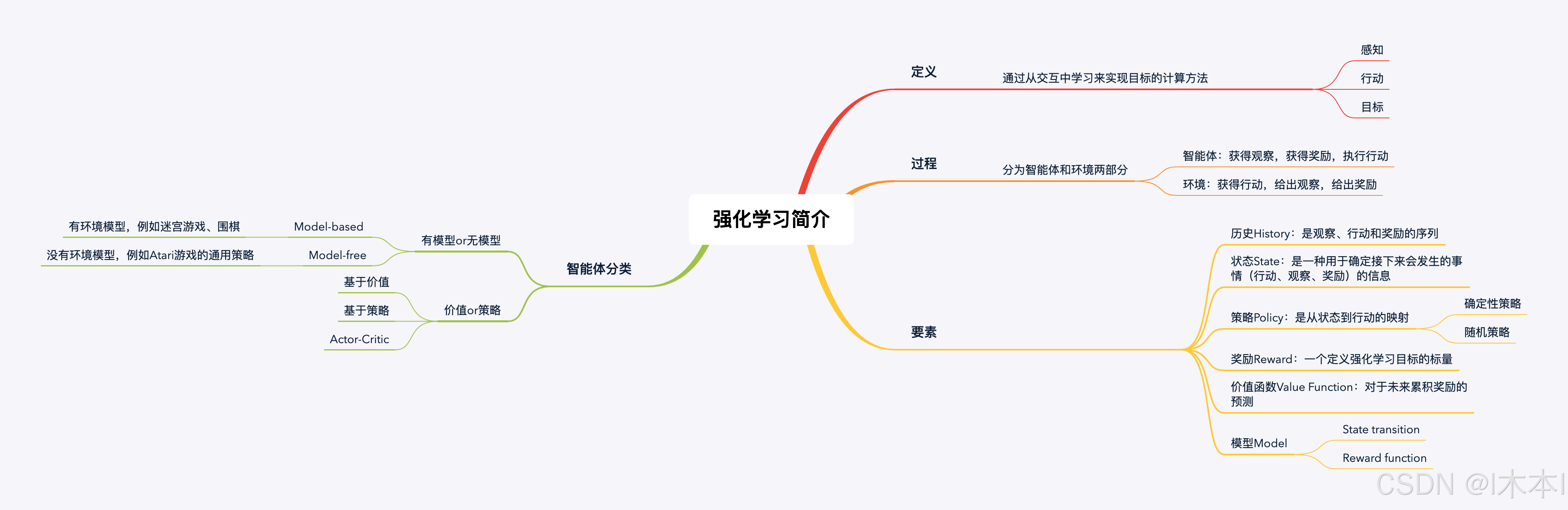
1.强化学习定义
通过从交互中学习来实现目标的计算方法
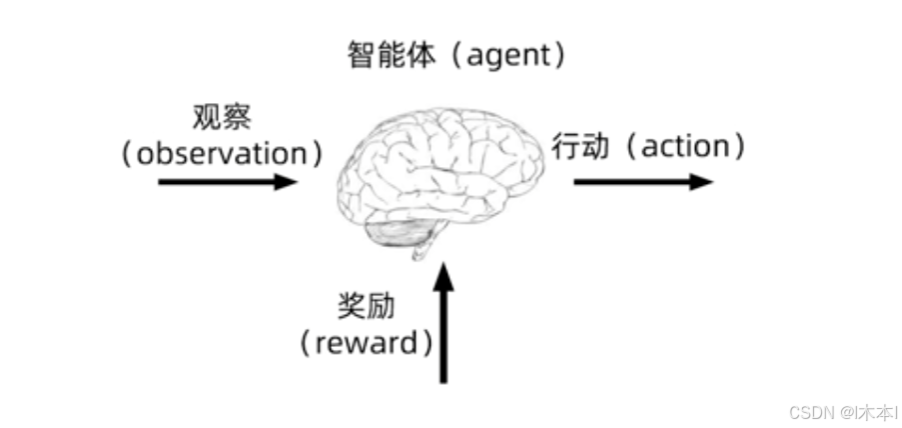
三个方面
感知:在某种程度上感知环境的状态
行动:可以采取行动来影响状态或者达到目标
目标:随着时间推移最大化累计奖励
强化学习的交互过程
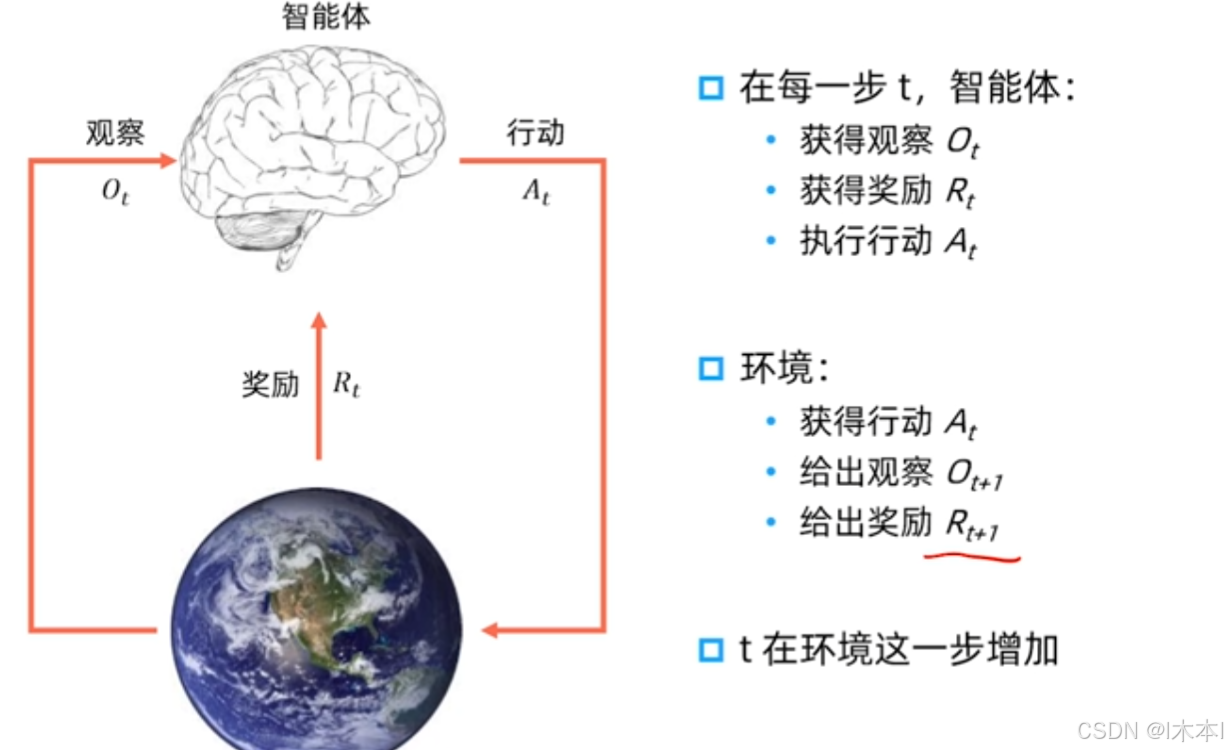
强化学习系统要素
1.历史(History)是观察,行动和奖励的序列

2.状态(state)是一种接下来会发生的事情(行动,观察,奖励)的信息。
~状态是历史的函数
St=f(Ht)
3.策略(policy)是学习智能体在特定时间的行为方式

随机策略本身是一个条件概率分布,确定性策略其实就是实打实的函数。
4.奖励(Reward)
一个定义强化学习目标的标量
能立即感知到什么是“好”的
5.状态价值(Value Function)
状态价值是一个标量,用于定义对于长期来说什么是“好”的

6.环境模型
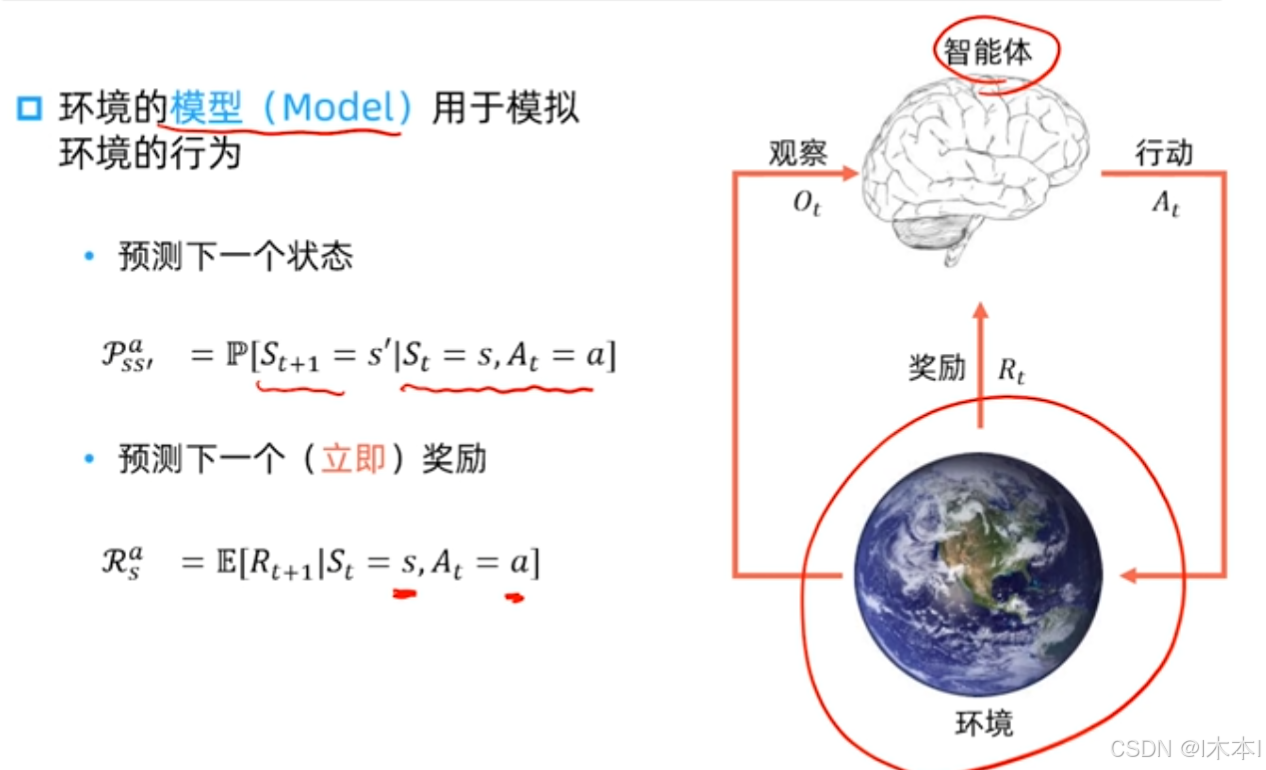
举例:迷宫

强化学习智能体分类
~基于模型的强化学习:有环境模型,例如迷宫游戏,围棋
~模型无关的强化学习:没有环境模型,Atrai Games
~基于价值:没有策略,价值函数
~基于策略:策略,没有价值函数
~Actor-Critic:策略,价值
2.强化学习探索与利用
序列决策任务中的一个基本问题
基于目前策略获取最优收益还是尝试不同的决策
~Expoitation执行能够获取最优收益的决策
~Exporation尝试更多可能得决策,不一定是最优收益

策略探的一些原则

多臂老虎机
多臂老虎机(Multi-Armed Bandit, MAB)是一个经典的理论问题,它在机器学习、统计学和决策理论中都有应用。这个问题的名称来源于赌博中的老虎机,但在这里它是一个比喻,用来描述一个决策过程,其中决策者需要在多个选项中做出选择,以最大化某种收益。
优化策略用来来获得最大化累计时间的收益。
收益估计

Rwgret函数


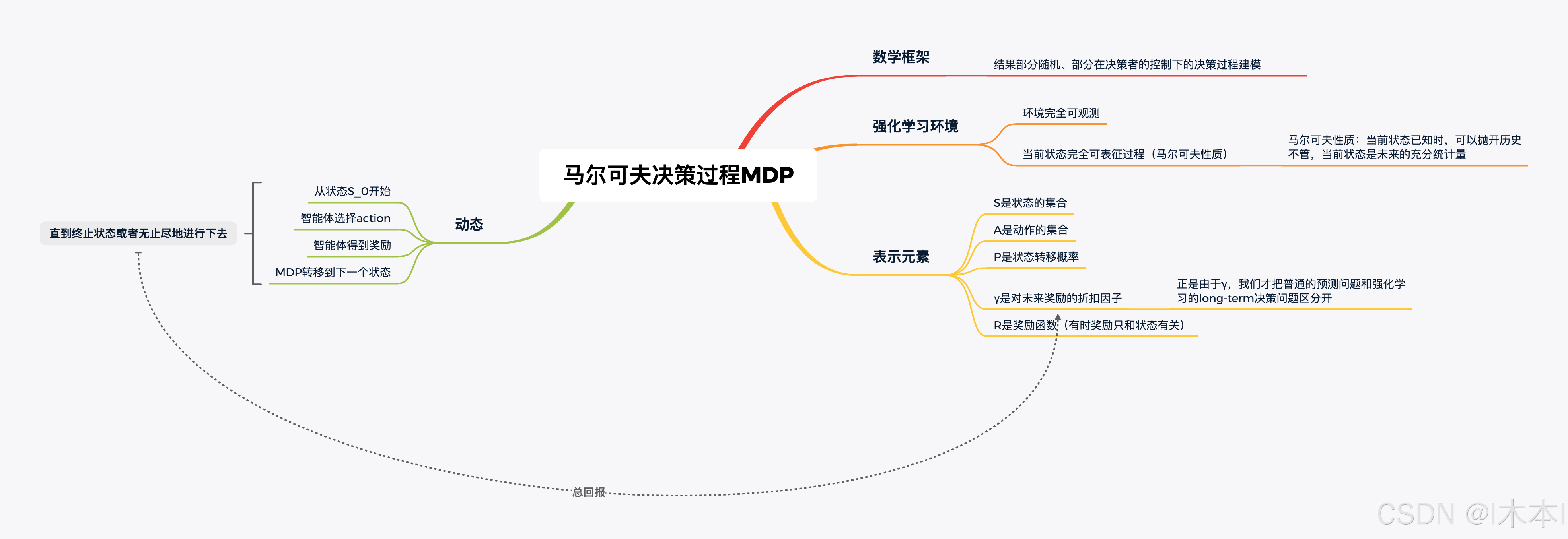
3.MDP
Markov Decision Process
提供了一套为结果部分随机,部分在决策者的控制下的决策过程建模的数学框架
MDP形式化地描述了一种强化学习环境
~环境完全可预测
即,当前状态可以完全表征过程(马尔科夫性质)

MDP五元组

MDP的动态
1.从状态S0开始
2.智能体选择某个动作
3.智能体得到奖励R
4.MDP随机转移到下一个状态S1
~这个过程不断执行,直到终止状态ST出现为止
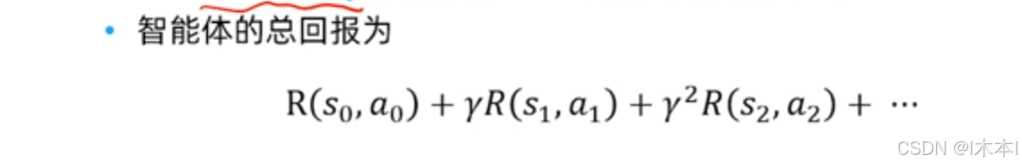
~在大部分情况下,奖励只和状态相关
比如,在迷宫游戏中奖励之和位置相关
在围棋中,奖励只基于最终所围地的大小有关

4.基于动态规划的强化学习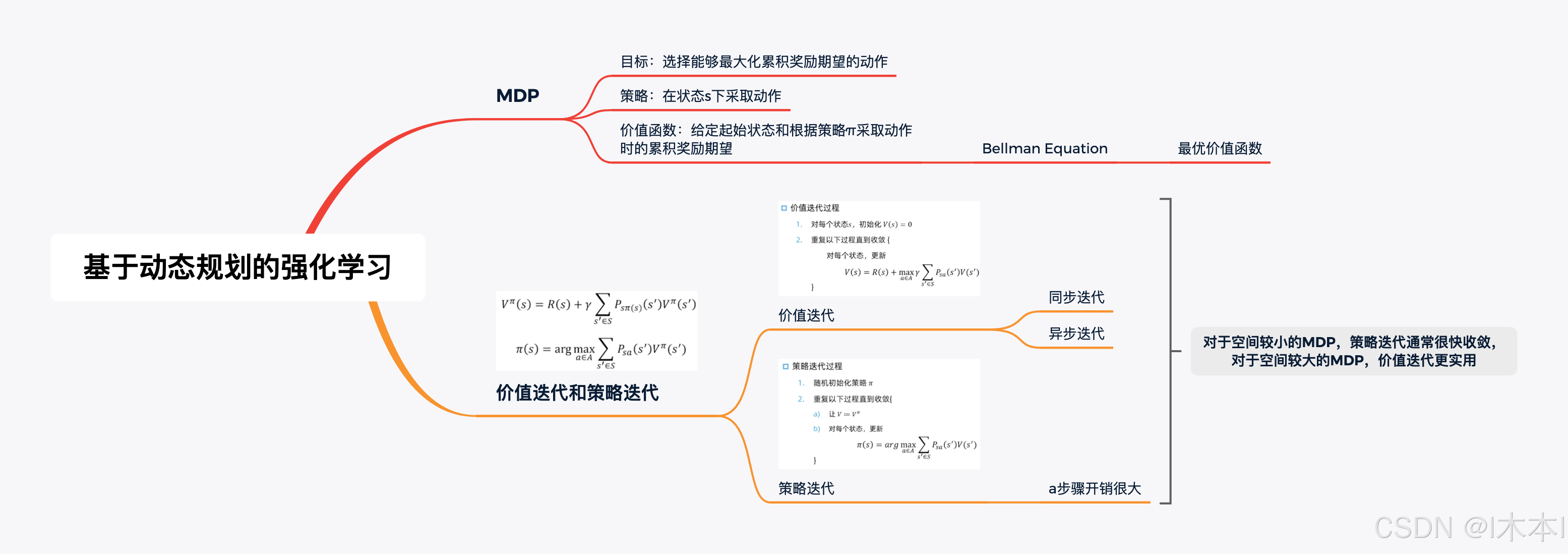
MDP目标和策略
目标:选择能够最大化累计奖励期望的动作


价值函数的Bellman等式
给定起始状态和根据策略π采取动作时的累计奖励期望
最优价值函数
在强化学习(Reinforcement Learning, RL)中,最优价值函数是一个核心概念,它描述了在给定策略下,从某一状态开始所能获得的期望回报的最大化值。

价值迭代和策略迭代

可以对最优价值函数和最优策略执行迭代更新
价值迭代

分为同步和异步价值迭代
~同步的价值迭代会储存两份价值函数的拷贝
~异步的价值迭代只存储一份价值函数
策略迭代

其中a步骤开销很大
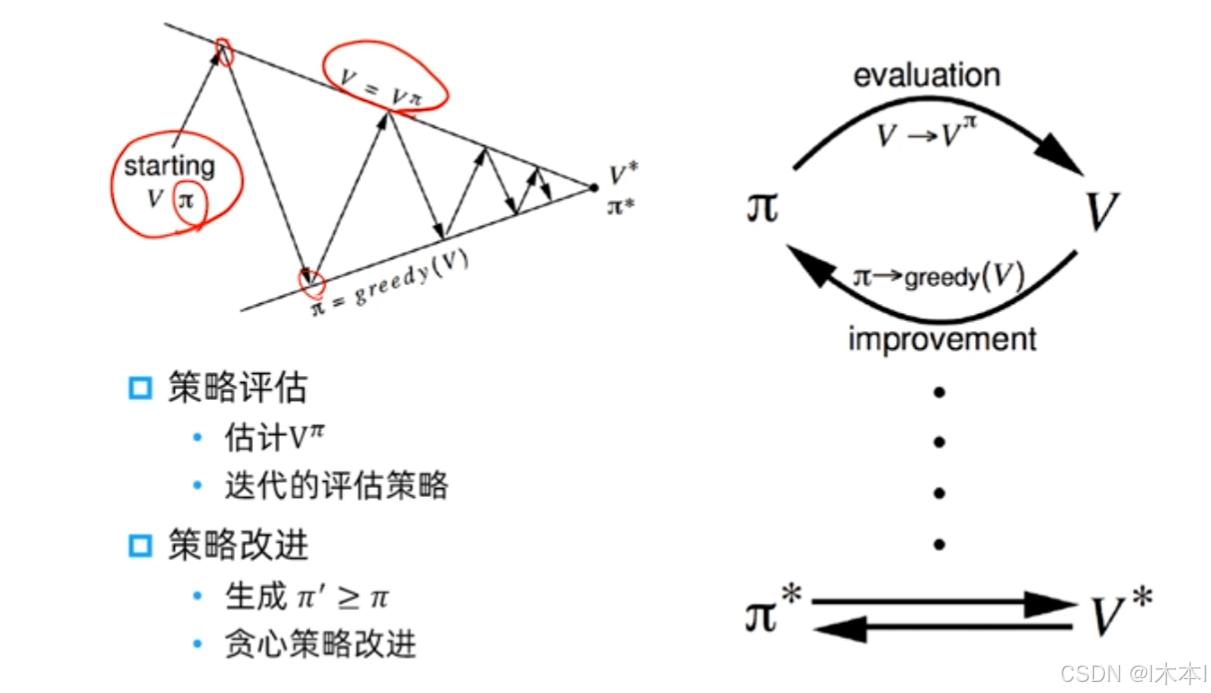
~1.价值迭代是贪心更新法。
2.策略迭代中,用Bellman等式更新价值函数代价很大
3.对于空间较小的MDP,策略迭代通常很快收敛
4.对于空间较大的MDP,价值迭代更实用(效率更高)
5.如果没有状态转移循环,最好使用价值迭代
5.基于模型的强化学习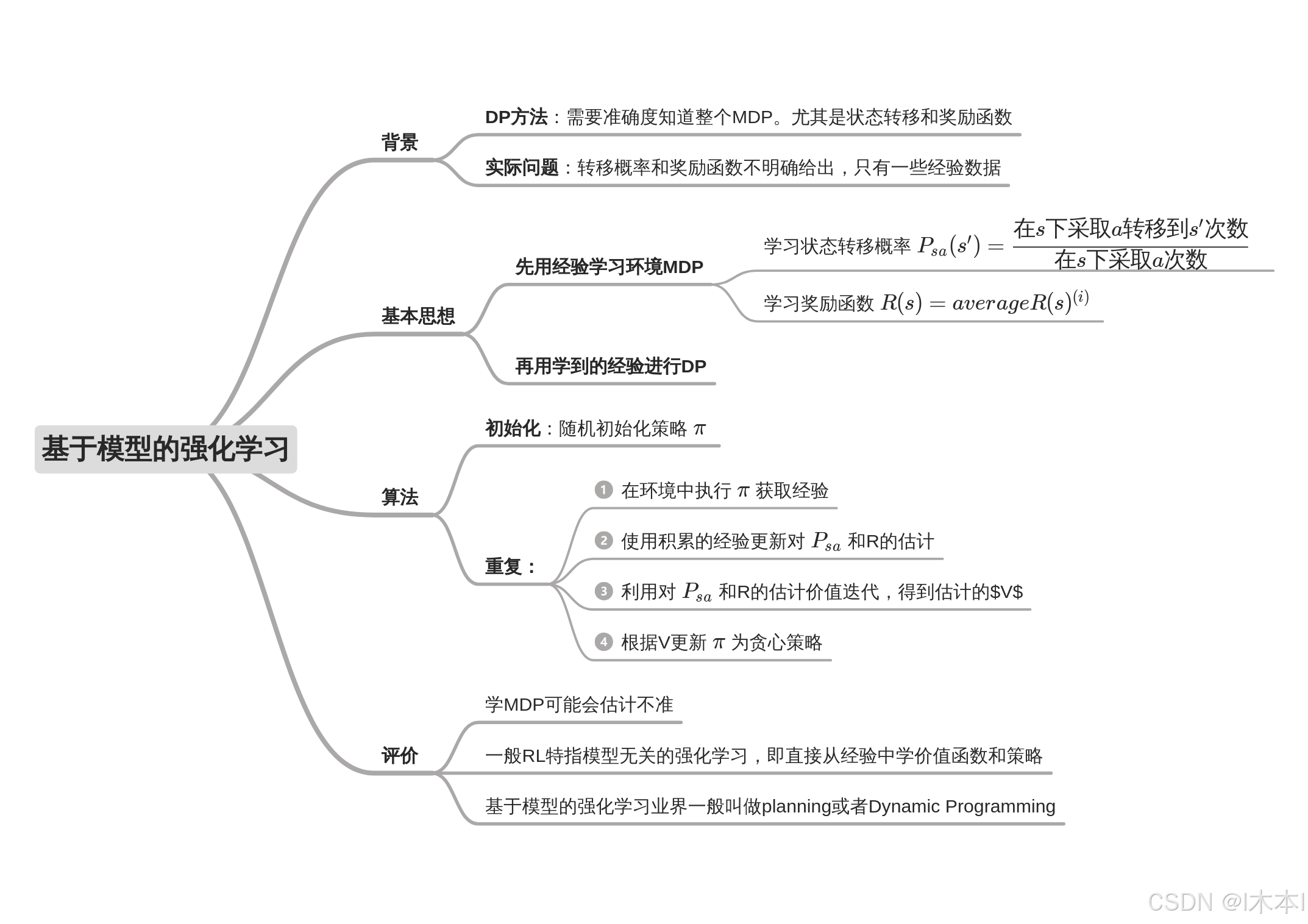
学习一个MDP模型
目前我们关注在给出一个已知MDP模型后:(也就是说,状态转移和奖励函数明确给定后)
~计算最优价值函数
~学习最优策略
在实际问题中,状态转移和奖励函数一般不是明确给出的
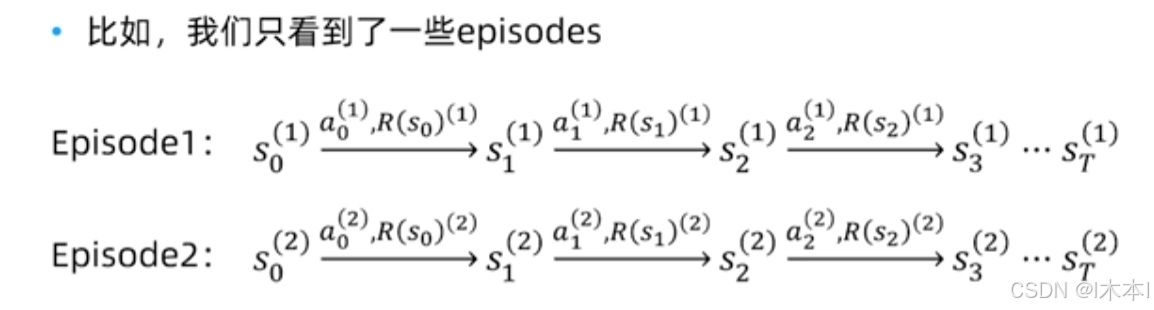
从“经验”中学习一个MDP模型

学习模型&优化策略
算法
1.随机初始化策略π
2.重复一下过程直到收敛

~另一种解决方式是不学习MDP,从经验中直接学习价值函数和策略
~也就是模型无关的强化学习(Model-free Reinforcement Learning)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)