Sparse4D系列算法:迈向长时序稀疏化3D目标检测的新实践
本文探讨了自动驾驶视觉感知系统中多摄像头融合的两种范式:后融合与BEV特征融合。BEV方法虽为主流,但存在感知范围、精度与效率难以平衡的问题,且无法直接处理2D感知任务。针对BEV的局限性,作者提出纯稀疏融合感知算法Sparse4D系列,通过改进Query构建、特征采样和时序融合等机制,在nuScenes检测任务中达到SOTA效果,超越了BEVFormer等稠密方法。文章详细介绍了Sparse4D
文章目录
在自动驾驶视觉感知系统中,为了获得环绕车辆范围的感知结果,通常需要融合多摄像头的感知结果。比较早期的感知架构中,通常采用后融合的范式,即先获得每个摄像头的感知结果,再进行结果层面的融合。后融合范式主要的问题在于难以处理跨摄像头的目标(如大卡车),同时后处理的负担也比较大。而目前更加主流的感知架构则是选择在特征层面进行多摄像头融合。其中比较有代表性的路线就是这两年很火的BEV方法,继Tesla Open AI Day公布其BEV感知算法之后,相关研究层出不穷,感知效果取得了显著提升,BEV也几乎成为了多传感器特征融合的代名词。但是,随着大家对BEV研究和部署的深入,BEV范式也逐渐暴露出来了一些缺陷:
- 感知范围、感知精度、计算效率难平衡:从图像空间到BEV空间的转换,是稠密特征到稠密特征的重新排列组合,计算量比较大,与图像尺寸以及BEV 特征图尺寸成正相关。在大家常用的nuScenes 数据中,感知范围通常是长宽 [-50m, +50m] 的方形区域,然而在实际场景中,我们通常需要达到单向100m,甚至200m的感知距离。 若要保持BEV Grid 的分辨率不变,则需要大大增加BEV 特征图的尺寸,从而使得端上计算负担和带宽负担都过重;若保持BEV特征图的尺寸不变,则需要使用更粗的BEV Grid,感知精度就会下降。因此,在车端有限的算力条件下,BEV 方案通常难以实现远距离感知和高分辨率特征的平衡;
- 无法直接完成图像域的2D感知任务:BEV 空间可以看作是压缩了高度信息的3D空间,这使得BEV范式的方法难以直接完成2D相关的任务,如标志牌和红绿灯检测等,感知系统中仍然要保留图像域的感知模型;
实际上,我们感兴趣的目标(如动态目标和车道线)在空间中的分布通常很稀疏,BEV范式中有大量的计算都被浪费了。因此,**基于BEV的稠密融合算法或许并不是最优的多摄融合感知框架。同时特征级的多摄融合也并不等价于BEV。**这两年,PETR系列(PETR, PETR-v2, StreamPETR) 也取得了卓越的性能,并且其输出空间是稀疏的。在PETR系列方法中,对于每个instance feature,采用global cross attention来实现多视角的特征融合。由于融合模块计算复杂度仍与特征图尺寸相关,因此其仍然属于稠密算法的范畴,对高分辨率的图像特征输入不够友好。
因此,我们希望实现一个高性能高效率的长时序纯稀疏融合感知算法,一方面能加速2D->3D 的转换效率,另外一方面在图像空间直接捕获目标跨摄像头的关联关系更加容易,因为在2D->BEV的环节不可避免存在大量信息丢失。这条技术路线代表性的方法是基于deformable attention 的DETR3D算法。然而从开源数据集指标来看,DETR3D的性能距离其他稠密类型的算法存在较大差距。为了Make 纯稀疏感知 Great Again,我们近期提出了Sparse4D及其进化版本Sparse4D v2,从Query构建方式、特征采样方式、特征融合方式、时序融合方式等多个方面提升了模型的效果。当前,Sparse4D V2 在nuScenes detection 3d排行榜来看,达到了SOTA的效果,超越了包括SOLOFusion、BEVFormer v2和StreamPETR在内的一众最新方法,并且在推理效率上也具备显著优势。本文主要介绍了Sparse4D 和 Sparse4D V2 方案的细节实践。
我们的Sparse4D 和Sparse4D-V2 代码( https://github.com/linxuewu/Sparse4D),以及Sparse4D-V3(https://github.com/HorizonRobotics/Sparse4D)都已经开源欢迎试用!
一、Sparse4D:纯稀疏感知方案的全面改进
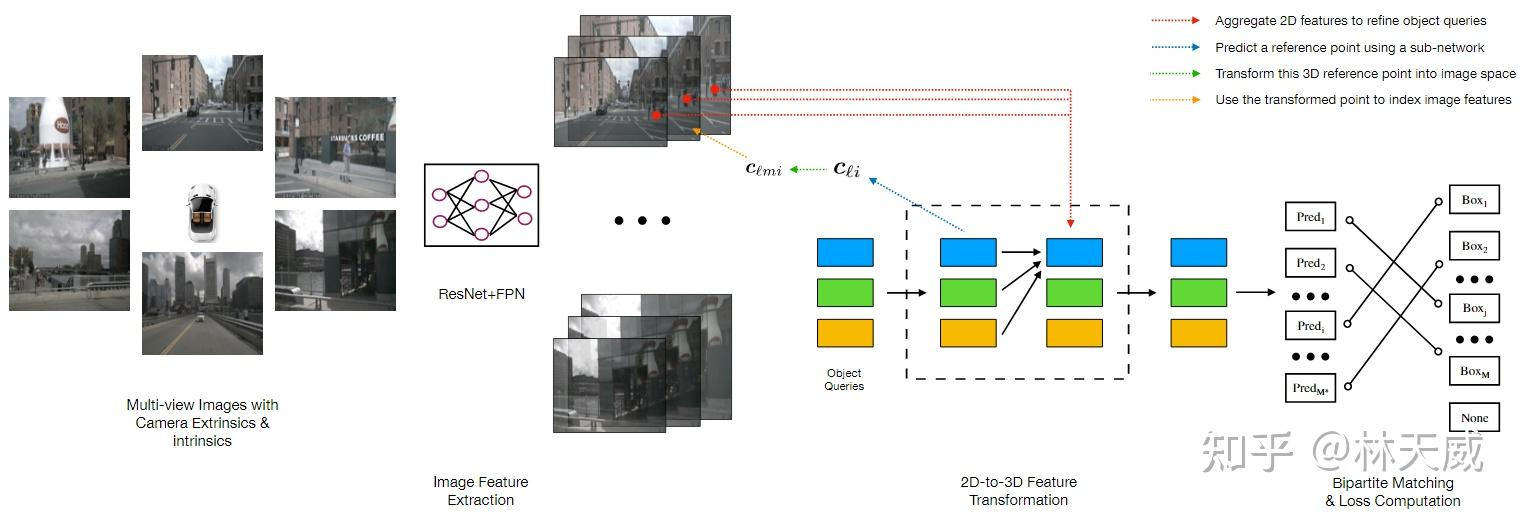
首先,我们先简单回顾一下DETR3D算法(图1)。DETR3D 算法可以概括为如下几个步骤:
- 多尺度特征提取:对于多摄像头图像,采用ResNet + FPN 提取图像的多尺度特征;
- Query 初始化:初始化若干Object Queries(以特征编码的形式)
- Query 特征更新:基于Query 特征,采用一个MLP Decoder 获得其对应的3D 空间参考点坐标,将这个点通过相机内外参投影到图像平面上,并采样多尺度特征,最后融合这些采样特征来更新Query 特征;
- 预测与loss:基于多轮更新后的Query 特征,预测每个Query 对应的bounding box,并通过Bipartite 匹配的方式与真值进行匹配并计算损失函数;
DETR3D 搭建了纯稀疏感知的基本框架,即稀疏Query + 稀疏特征采样的范式,但存在一些不足:
- 每个Query 仅对应一个Reference Point,不能够有效采样目标的特征,特别对于较大的目标;
- 从Learnable Query 来decode 获得Reference Point 的方式,并不能非常有效的定位roi 区域,且会存在退化解,多模式等诸多的问题。这个问题在Anchor-DETR和 DAB-DETR等方法中都有过讨论;
- 不支持对于时序信息的融合;
由于上述的这些原因,DETR3D 网络整体的学习能力偏弱,指标在当前显著弱于BEV 范式的方法。在Sparse4D-V1 中,我们主要通过instance 构建方式,特征采样、特征融合和时序融合等方面改进了现有的框架。
1.1 Sparse4D 算法框架
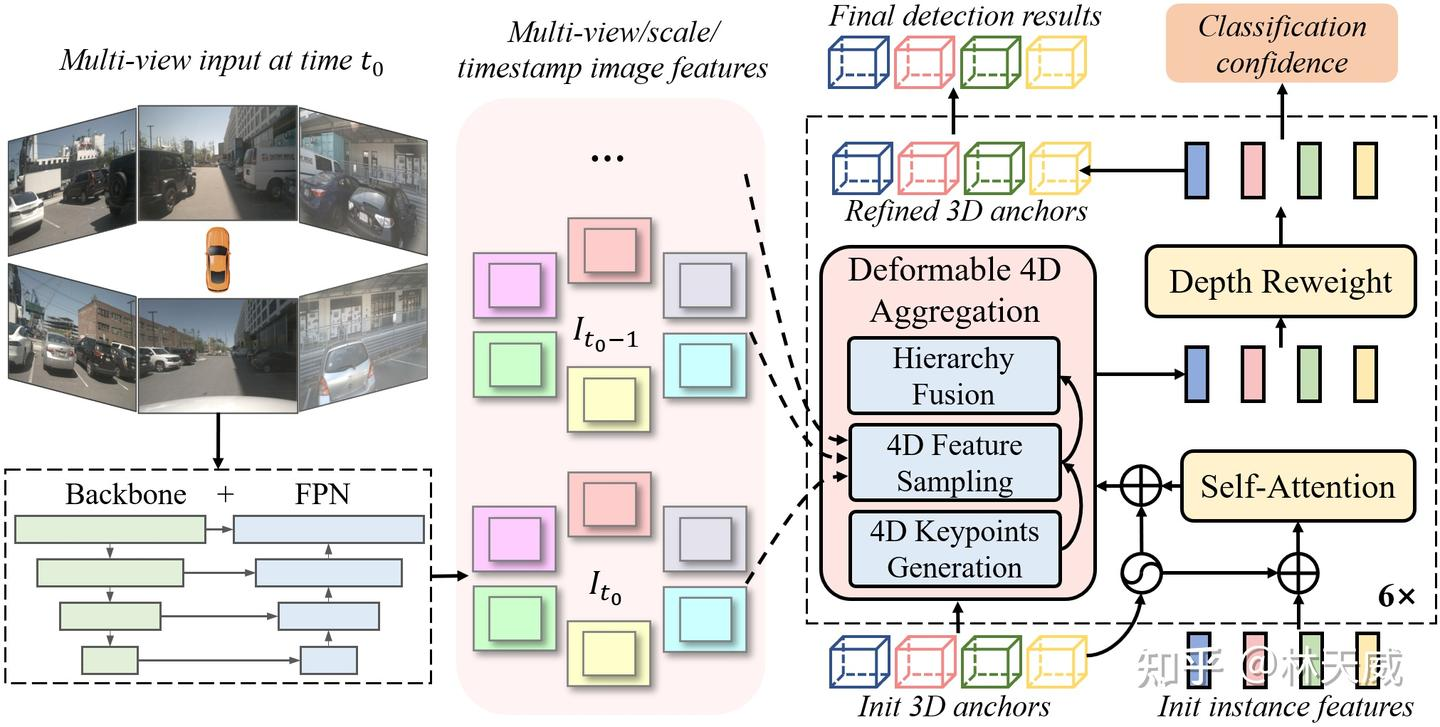
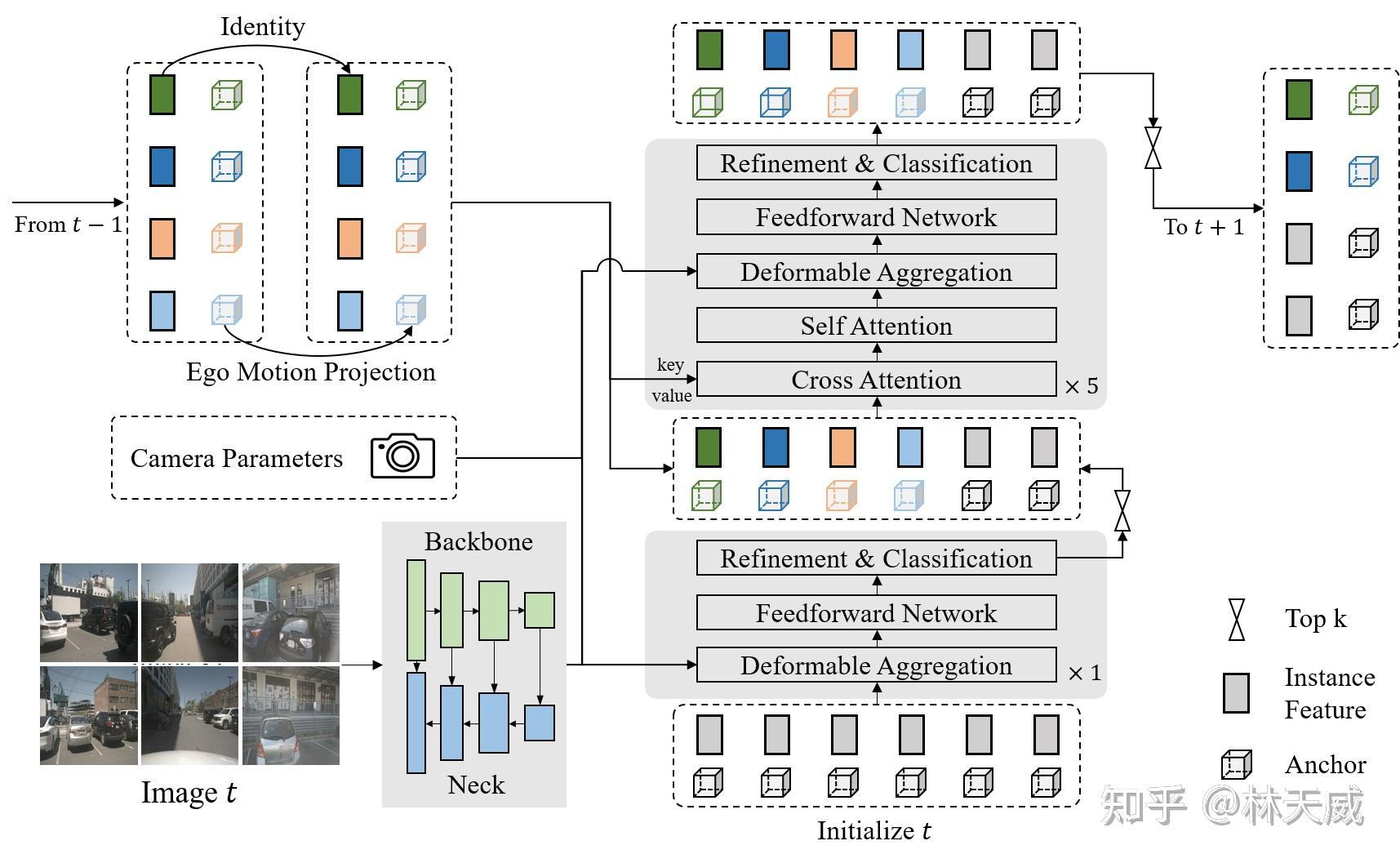
如图1所示,Sparse4D 也采用了Encoder-Decoder 结构。其中Encoder包括image backbone和neck,用于对多视角图像进行特征提取,得到多视角多尺度特征图。同时,我们会cache 多历史帧的图像特征,用于在decoder 中提取时序特征;Decoder为多层级联形式,输入时序多尺度图像特征图和初始化instance,输出精细化后的instance,每层decoder包含self-attention、deformable aggregation和refine module三个主要部分。
学习2D检测领域DETR改进的经验,我们也重新引入了Anchor的使用,并将待感知的目标定义为instance,每个instance主要由两个部分构成:
- Instance feature F:目标的高维特征,在decoder 中不断由来自于图像特征的采样特征所更新;
- 3D Anchor A:目标结构化的状态信息,比如3D检测中的目标3D框(x, y, z, w, l, h, yaw, vx, vy);我们通过kmeans 算法来对anchor 的中心点分布进行初始化;同时,在网络中我们会基于一个MLP网络来对anchor的结构化状态进行高维空间映射得到 Anchor Embed E,并与instance feature 相融合。
基于以上定义,我们可以初始化一系列instance,经过每一层decoder都会对instance 进行调整,包括instance feature的更新,和anchor的refine。基于每个instance 最终预测的bounding box,Sparse4D 中同样通过Bipartite 匹配的方式与真值进行匹配并计算损失函数。
1.2 Deformable 4D Aggregation 模块
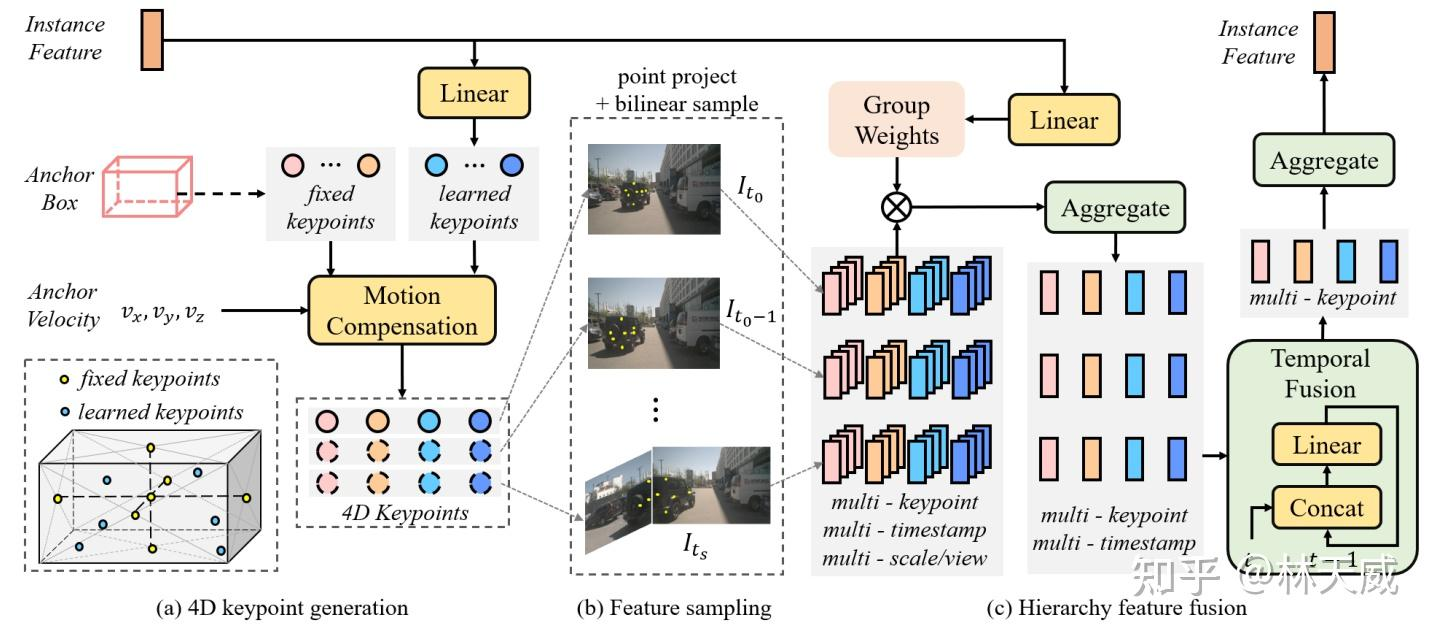
在Sparse4D 的decoder 中,最重要的是Deformable 4D Aggreagation 模块。这个模块主要负责instance 与时序图像特征之间的交互,如图3所示,主要包括三个步骤:
4D 关键点生成:首先,基于每个instance 的3D anchor信息, 我们可以生成一系列3D关键点,分为固定关键点和可学习关键点。我们将固定关键点设置为anchor box的各面中心点及其立体中心点,可学习关键点坐标通过instance feature接一层全连接网络得到。在Sparse4D 中,我们采用了7个固定关键点 + 6个可学习关键点的配置。然后,我们结合instance 自身的速度信息以及自车的速度信息,对这些3D关键点进行运动补偿,获得其在历史时刻中的位置。结合当前帧和历史帧的3D关键点,我们获得了每个instance 的4D 关键点。
4D 特征采样:在获得每个instance 在当前帧和历史帧的3D关键点后,我们根据相机的内外参将其投影到对应的多视角多尺度特征图上进行双线性插值采样。从而得到Multi-Keypoint,Multi-Timestamp, Multi-Scale, Multi-View 的特征表示;
层级化特征融合:在采样得到多层级的特征表示后,需要进行层级化的特征融合,我们分为了三层:
- Fuse Multi-Scale/View:对于一个关键点在不同特征尺度和视角上的投影,我们采用了加权求和的方式,权重系数通过将instance feature和anchor embed输入至全连接网络中得到;
- Fuse Multi-Timestamp:对于时序特征,我们采用了简单的recurrent策略(concat + linear)来融合;
- Fuse Multi-Keypoint:最后,我们采用求和的方式融合同一个instance 不同keypoint 的特征;
1.3 实验验证
我们在nuScenes 数据集上对Sparse4D 方法展开了很多实验验证,这里列举几个主要的实验。
运动补偿:Sparse4D针对自车运动和instance运动都进行了补偿。目前,大多数算法仅显式考虑了自车运动。我们通过实验分析了运动补偿的作用,如下表所示。对于NDS指标来说,自车运动和他车运动分别带来了6.4%和0.7%的提升,他车运动补偿对检测精度无提升,但是对速度估计精度的提升非常显著(mAVE指标)。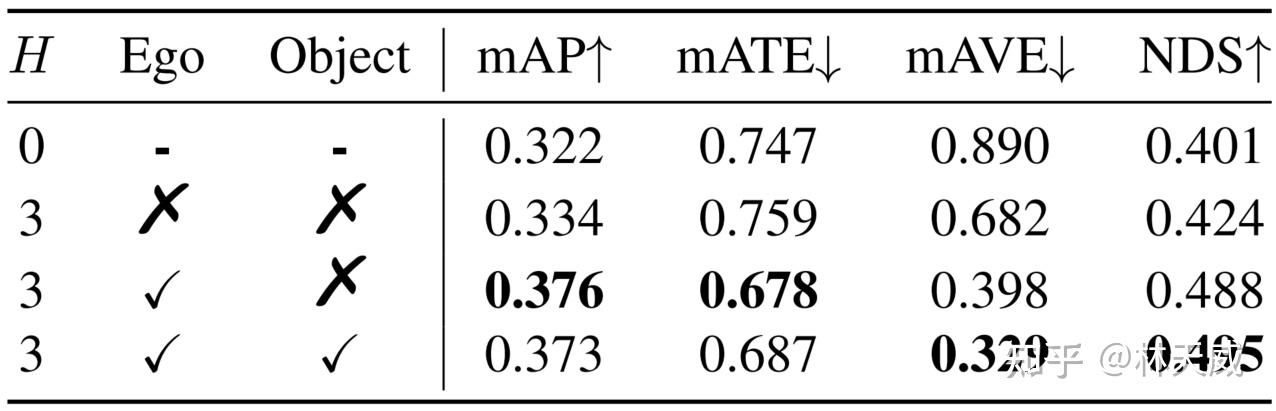
多层次特征融合:在deformable aggregation中,我们需要对多尺度、多视角和多关键点的特征进行融合。为了分析各个层级融合的重要程度,我们分别将各层的加权方式改为直接求和,可以看到多尺度的影响小于多视角,而多关键点的融合最为重要。此外,将三个层级的融合全部改为求和的形式,模型将难以收敛,指标也会显著降低。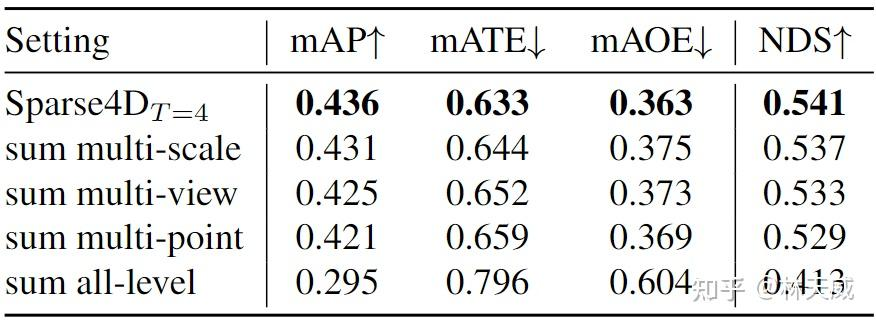
采样时序融合帧数:Spase4D v1中,采用多帧采样的方式实现时序融合,其中采样帧数对感知性能的影响显著。我们将帧数从0逐步增加至10,感知性能一直在稳步提升,说明长时序融合对检测性能有很大帮助。但是由于显存限制,我们仅验证到了10帧。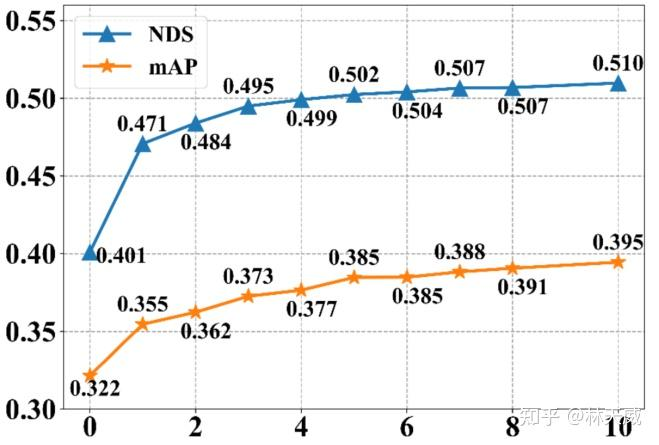
效率与指标分析:如下表所示,在单帧配置下,我们的方法速度与DETR3D持平,且指标显著优于DETR3D。但在时序配置下,Sparse4D的效率出现了显著的下降。这是因为对于每一帧的检测,我们都需要进行当前帧和历史多帧的特征采样和特征融合。这里包含了很多冗余的计算,使得多帧效率显著低于单帧效率。针对这个问题,我们在最近对时序策略进行了优化,提出了Sparse4D-V2 方案,使得其时序推理效率和单帧推理基本一致。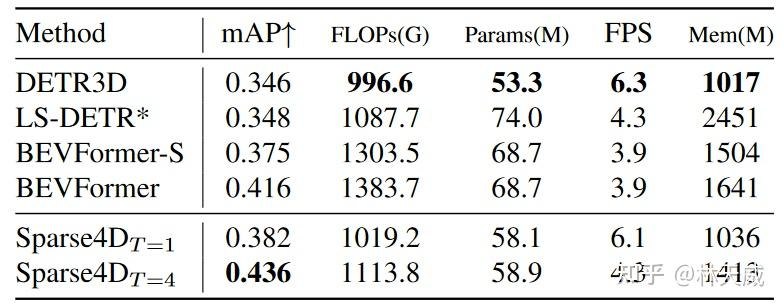
二、Sparse4D-V2:Recurrent 时序方案 & 进一步效率优化
为了避免多帧采样,进而提升时序特征融合的效率,我们在Sparse4D v2中采用了recurrent的方式来实现时序信息的传递。具体而言,如下图所示,Sparse4D v2中以instance作为时序信息传递的媒介。此外,我们还提出了更高效的Deformable Aggregation 模块,并引入了辅助训练loss。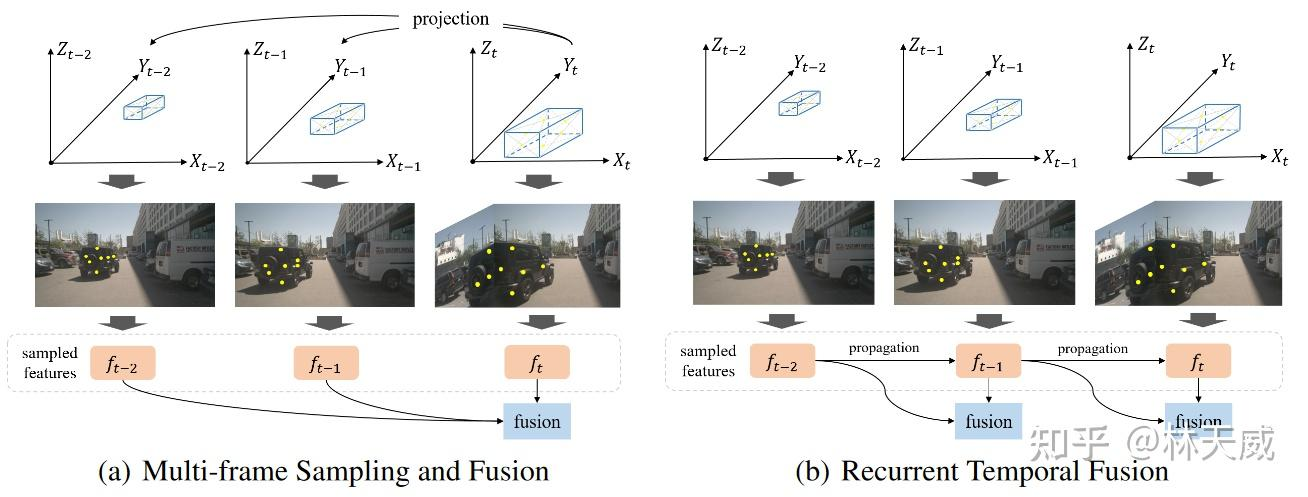
2.1 基于稀疏实例的Recurrent 时序方案
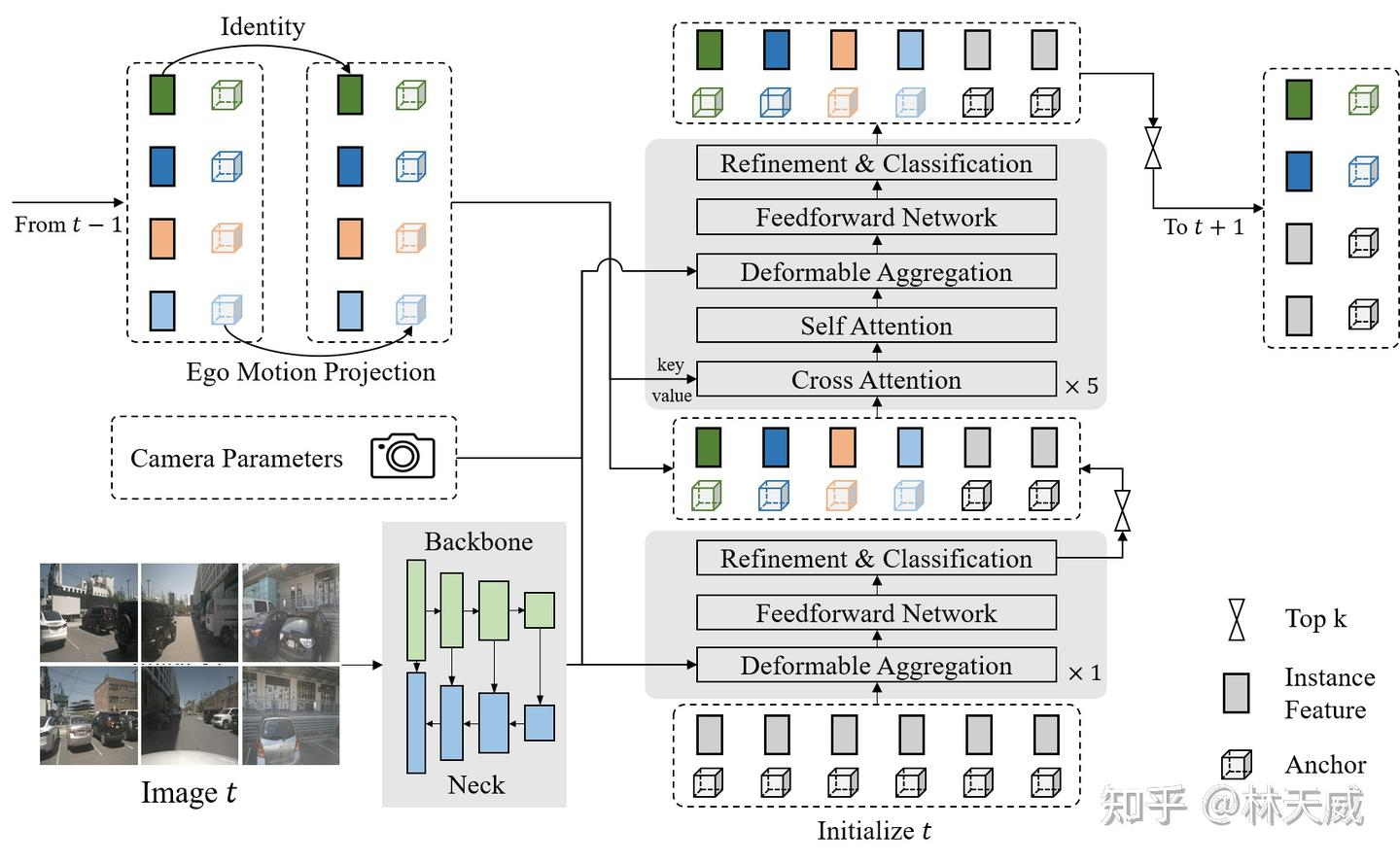
在Sparse4D-V2中,我们将decoder分为单帧层和时序层。单帧层以新初始化的instance作为输入,输出一部分高置信度的instance至时序层;时序层的instance除了来自于单帧层的输出以外,还来自于历史帧(上一帧)。我们将历史帧的instance投影至当前帧,其中,instance feature保持不变,anchor box通过自车运动和目标速度投影至当前帧,anchor embed通过对投影后的anchor进行编码得到,如公式1。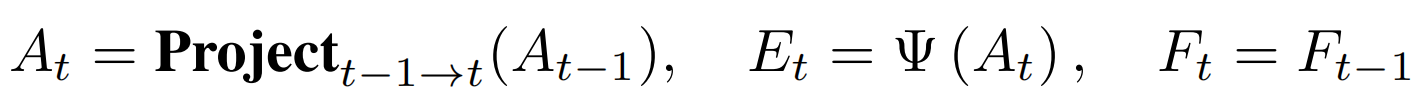
其中投影公式与anchor定义相关,对于3D 检测任务,我们使用的投影公式如公式2。
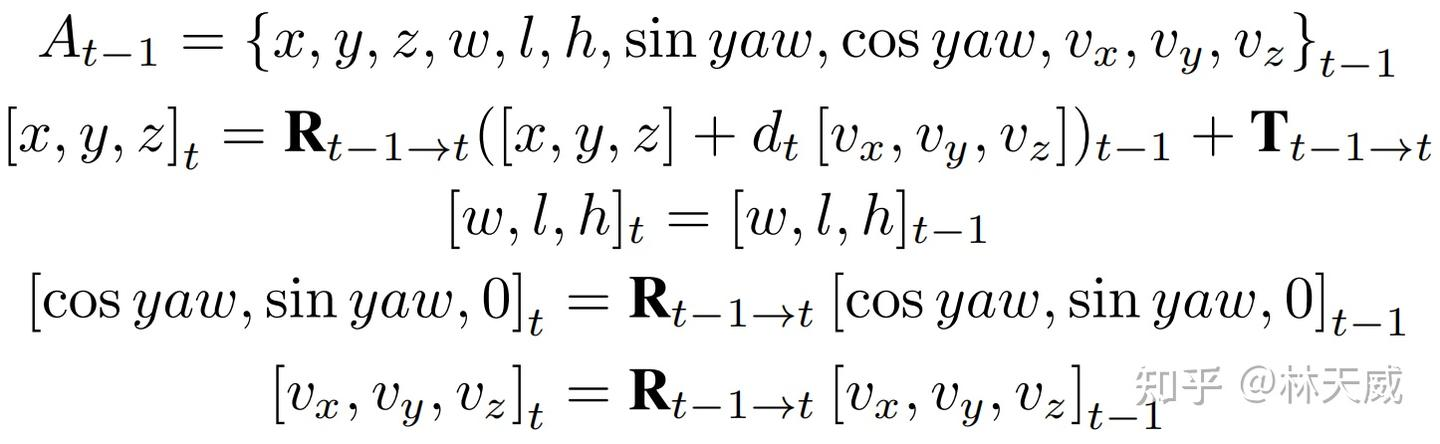
近期效果很好的方法StreamPETR也采用了稀疏的Recurrent 时序框架,Sparse4D V2与其的区别主要在于:
- Instance 表示方式:PETR系列中,query instance 采用的是 “Anchor Point -> Query 特征”的方式。即将均匀分布在3D 空间中的anchor point(learnable)用MLP编码成Query 特征。比起Sparse4D instance 中显式分离feature (纹理语义信息) 和3D anchor(几何运动信息) 的方式,PETR的instance 表示方式更加隐式一些。我们认为feature + anchor box的显式instance表示方式,在稀疏3D检测任务中更加简洁有效,也更易于训练;
- 时序转换方式:与instance 表示方法相对应的是稀疏Reccurent 的方式。StreamPETR 中,采用了隐式的query时序转换方式,即把velocity、ego pose、timestamp都编码成特征,然后再和query feature做一些乘加操作;Sparse4d-V2 则采用了显式的时序转换方式,对于历史帧的instance,直接将其3D anchor基于自车和instance 运动投影到当前帧,而保持其instance feature不变。
- 历史帧数量:StreamPETR 中 cache了历史N帧的query,再与当前帧进行attention。Sparse4d-v2 则只cache了上一帧的query。当然,StreamPETR 也可以只cache 一帧,只是效果会略略有下降。在实际的业务实践中,较少的历史帧cache 有助于减少端上的带宽占用,进一步提升系统整体性能。
2.2 Efficient Deformable Aggregation
此外,在Sparse4D v2中,我们还对deformable aggregation模块进行了底层的分析和优化,让其并行计算效率显著提升,显存占用大幅降低。基于pytorch op组合的Basic Deformable Aggregation 计算逻辑实现如下图所示。
可以发现其会生成多个中间变量,需要对显存进行多次访问和存储,降低了推理速度,且中间变量 f f f尺寸较大,从而导致显存占用量显著增加,并且反向传播过程中的显存消耗会进一步提升。
为了提升该op的计算效率,降低显存占用,我们将上述实现中的双线性特征插值和加权求和融合为一个op,如下图所示,我们称之为Efficient Deformable Aggregation(EDA)。EDA的关键在于将“先采样所有特征再融合”的方式变成了“并行地边采样边融合”,其允许在关键点 K 维度和特征 C 维度上实现完全的并行化,每个线程的计算复杂度仅与相机数量和特征尺度数量相关: Ncam × \times ×S。此外,在某些场景中,3D空间中的一个点最多被投影到两个视图,使得计算复杂度可以进一步降低至 2 × \times ×S 。EDA可以作为一种基础性的算子操作,可以适用于需要多图像和多尺度融合的各种应用。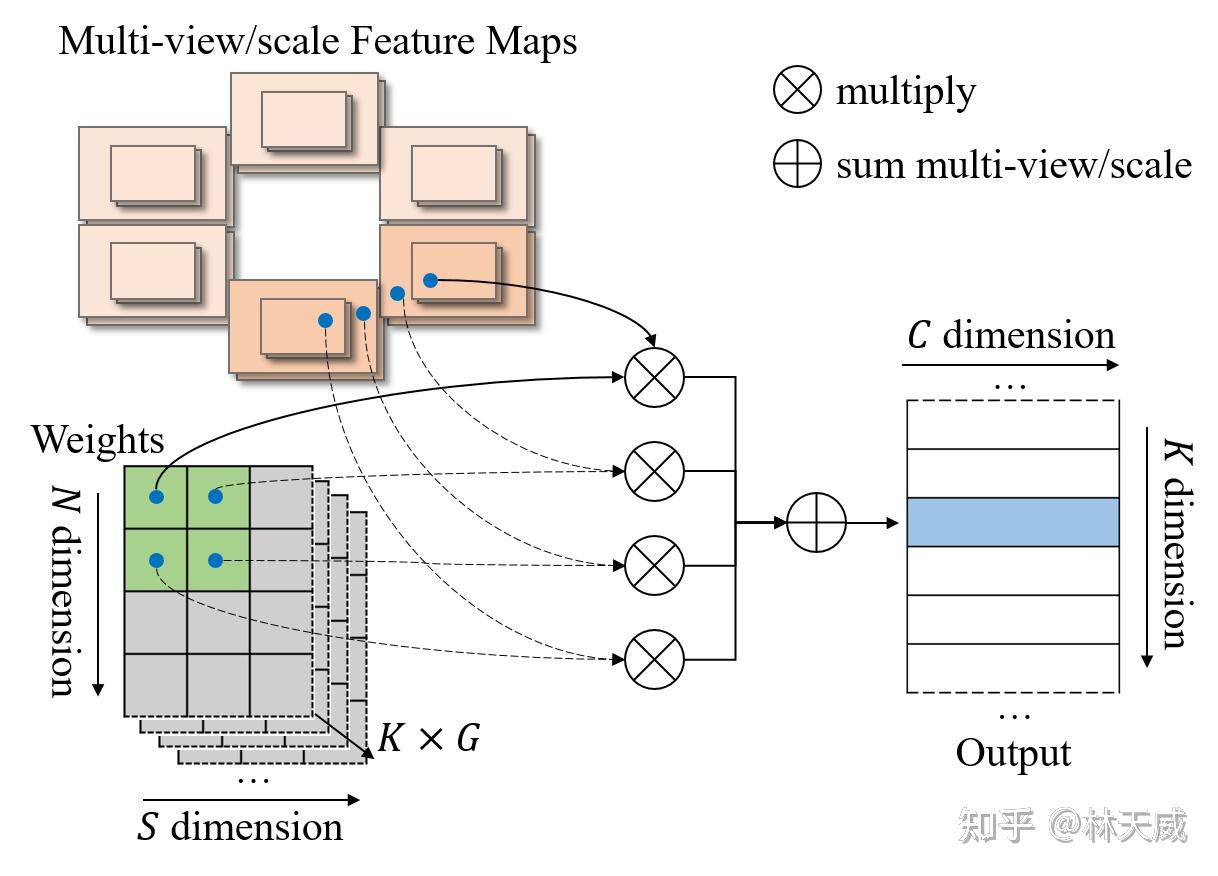
我们在3090上对EDA模块进行了性能测试。EDA对显存占用和推理速度都有很大的优化效果。加上EDA之后,Sparse4Dv2在nuScenes单次实验训练时间只需要14.5小时(8 GPUs),推理速度可达20.3FPS,且batch size=1时训练显存仅为3100M。
2.3 相机编码的加入 & 辅助训练任务
为了提高模型对相机内外参泛化性,我们在Sparse4D v2中加入了内外参的编码,将相机投影矩阵通过全连接网络映射到高维特征空间得到camera embed。在计算deformable aggregation中的attention weights W时,我们不仅考虑instance feature和anchor embed,还加上了camera embed。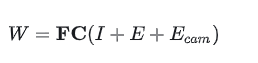
在实验中,我们发现基于稀疏的方法在早期训练阶段缺乏足够的收敛能力和速度。为了缓解这一问题,我们还引入了以点云为监督的多尺度密集深度估计方法作为辅助训练任务。而在推理过程中,这个分支网络将不会被激活,不影响推理效率。
2.4 实验验证
Ablation Study
我们首先基于Resnet50 + 256x704 分辨率的配置展开了消融实验。如下表所示:
- 对比Exp1 和Exp5可以看出,采用recurrent instance的形式来实现长时序融合,相比单帧提升非常大;
- 对比Exp4 和Exp5可以看出,深度监督模块,有效降低了Sparse4D-V2的收敛难度,如果去掉该模块,模型训练过程会出现梯度崩溃的现象,从而使得mAP降低了8.5%。(在不具备深度监督条件的情况下,也可以考虑使用2D 的检测head 作为辅助loss,如FCOS Head,YoloX等)
- 对比Exp2 和Exp3可以看出,单帧层 + 时序层的组合方式比起只使用时序层的效果要好很多;
- 对比Exp3 和Exp5可以看出,相机参数编码也带来了可观的提升,mAP和NDSf分别提升了2.0%和1.5%;
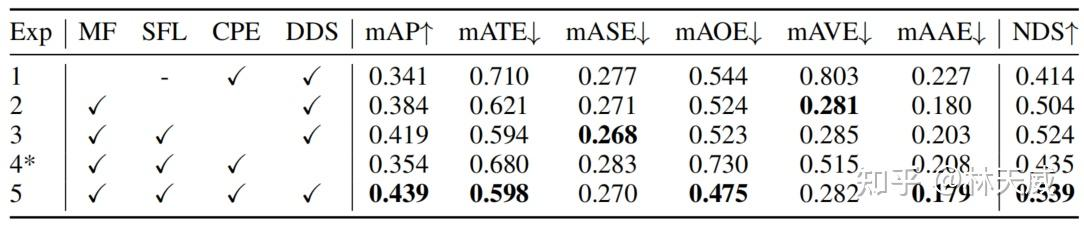
此外,Exp1 (单帧)在3090 上的推理速度为21.0 FPS,Exp5(时序)的推理速度则为20.3 FPS。可以看出,在recurrent 时序融合框架下,其推理速度和单帧推理基本一致,增加了少量历史instance 映射的耗时。
Compare with SOTA
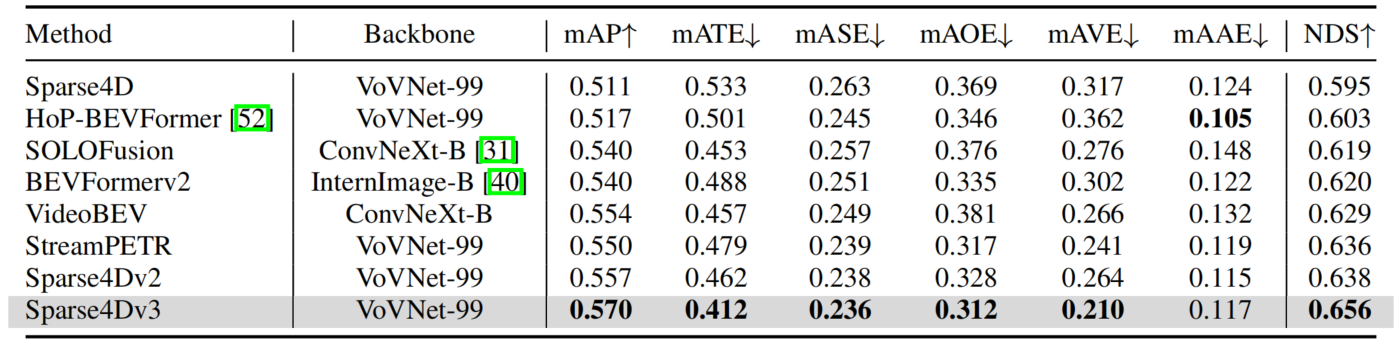
我们先在nuScenes validation数据集上进行了对比,可以无论是在低分辨率+ResNet50还是高分辨率+ResNet101的配置下,Sparse4D v2都取得了SOTA的指标,超过了SOLOFusion、VideoBEV和StreamPETR等算法。
从推理速度来看,在256X704的图像分辨率下,Sparse4Dv2超过了LSS-Based算法BEVPoolv2,但是低于StreamPETR。但是当图像分辨率提升至512X1408,Sparse4Dv2的推理速度会反超StreamPETR。这主要是因为在低分辨率下直接做global attention的代价较低,但随着特征图尺寸的上升其效率显著下降。而Sparse4D head理论计算量则和特征图尺寸无关,这也展示了纯稀疏范式算法在效率上的优势。实际测定中,当图像分辨率从256x704 提升到512x1408时,Sparse4Dv2 的decoder 部分耗时仅增加15%(从高分辨率特征上进行grid sample,会比从低分辨率特征上进行grid sample 略慢一点)。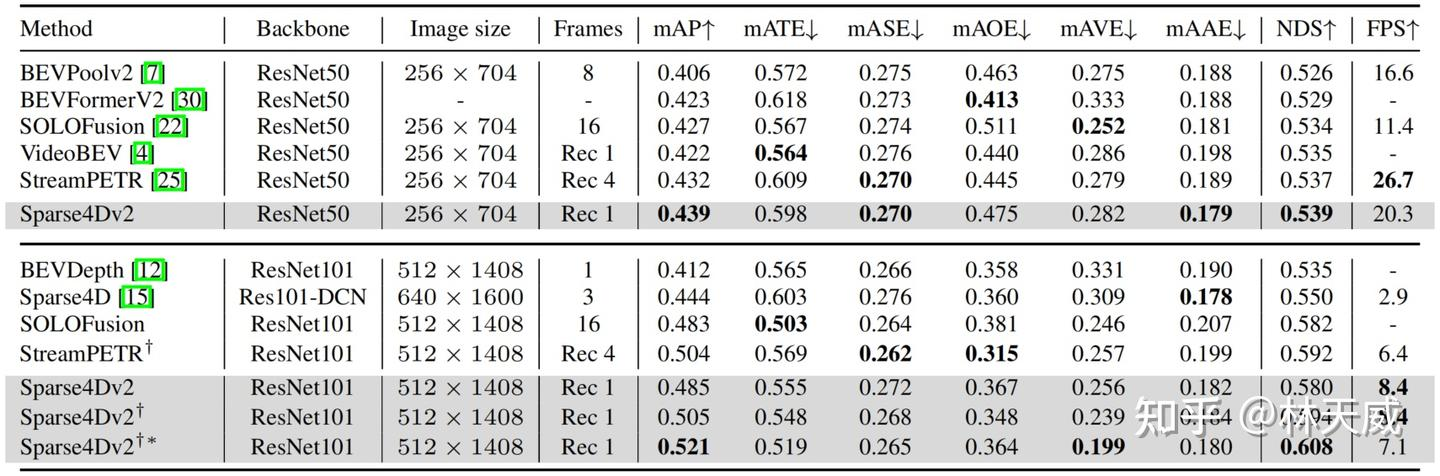
在nuScenes test数据集上,Sparse4Dv2同样获得了SOTA的指标,超过了所有BEV-based算法,同时也比目前SOTA的StreamPETR高0.2NDS。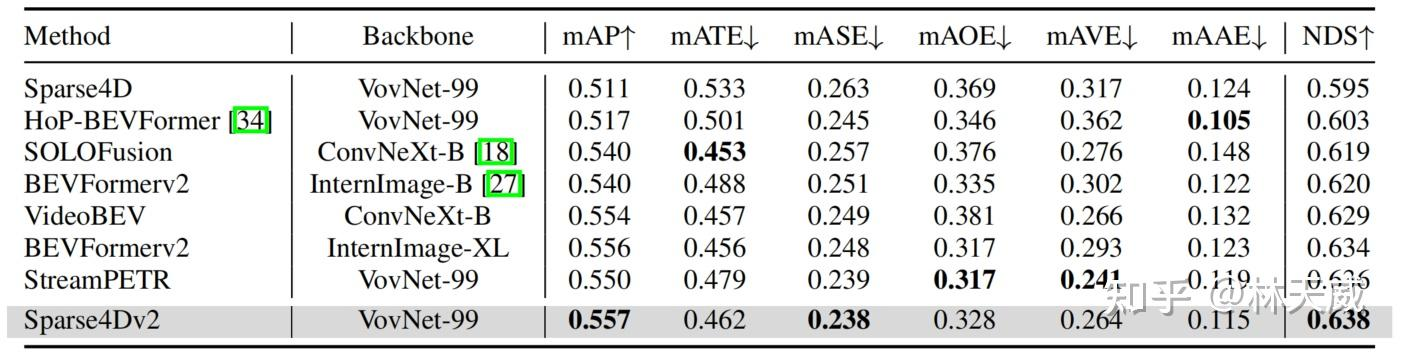
三、Sparse4D-V3: 检测性能的进一步优化及端到端跟踪实现
在完成Sparse4D-V2 的工作后,我们一直在思考一个问题:一个真正完善且在业务场景work 的稀疏动态感知算法应该是怎么样的?在长时间的探索中, 我们将目光聚焦到了两个问题上:
- 收敛困难:稀疏形式的感知算法,大多数都面临这个收敛困难的问题,收敛速度相对较慢、训练不稳定导致最终指标不高;在Sparse4D-V2 中,我们主要采用了额外的深度估计任务来帮助网络训练,但由于用上了额外的点云作为监督,这并不是一种理想的形式。
- 端到端跟踪:在实际业务系统中,在检测模块后,我们总是需要在加入跟踪模块获得目标轨迹。因此一个完善的稀疏动态感知框架应该同时具备端到端跟踪能力。
针对收敛困难的痛点,我们引入了DETR-like 2D 检测论文中最为有效的辅助任务"query denosing"并将其改进成了时序形式,此外我们提出另外一个辅助训练任务 “quality estimation”,这两个任务不仅加速了模型收敛,同时让感知性能更优。同时,针对原来instance attention有可能造成特征混淆的问题, 我们进行了改进并提出了decoupled attention,在几乎不增加推理时延的情况下提升了感知效果。而针对端到端跟踪任务,我们很惊喜得发现无需加入任何训练策略和优化,只需要在测试时引入简单的跟踪策略,仅依赖于Sparse4D 中的实例时序传播策略,即可实现SOTA 的性能指标。
3.1 让模型更快更好的收敛
Temporal Instance Denosing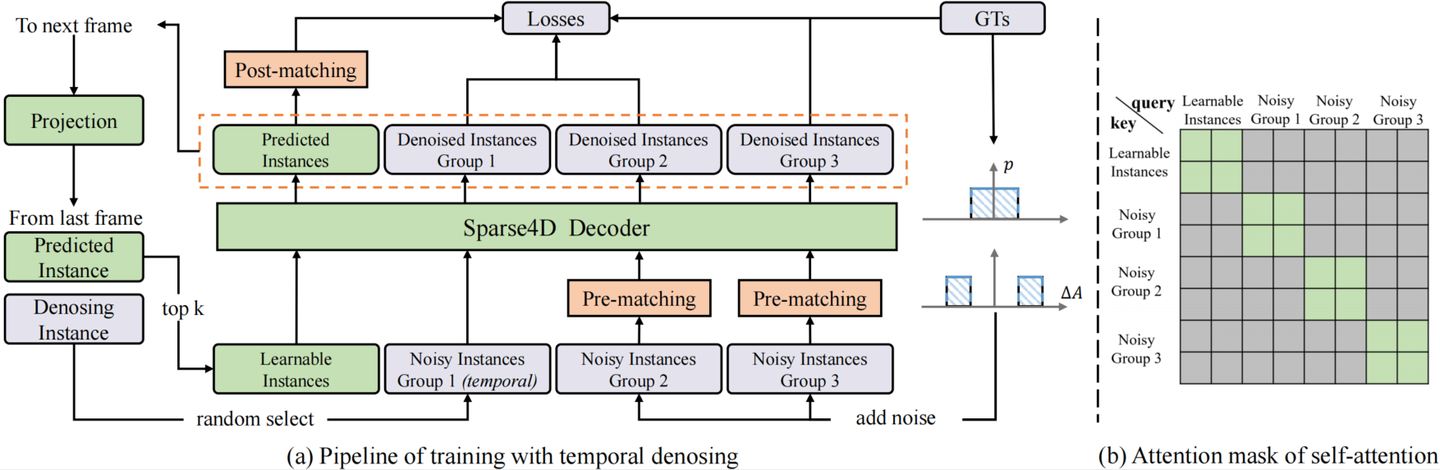
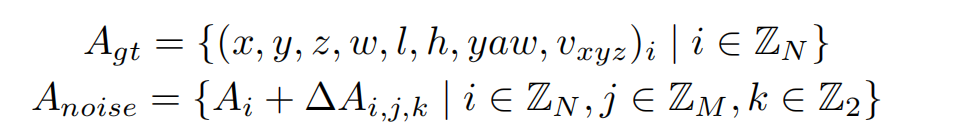
加上噪声的GT框需要重新和原始GT进行one2one匹配,确定正负样本,而并不是直接将加了较大扰动的GT作为负样本,这可以缓解一部分的分配歧义性。噪声GT需要转为instance的形式以输入进网络中,首先噪声GT可以直接作为anchor,把噪声GT编码成高维特征作为anchor embed,相应的instance feature直接以全0来初始化。
为了模拟时序特征传递的过程,让时序模型能得到denoisy任务更多的收益,我们将单帧denosing拓展为时序的形式。具体地,在每个训练step,随机选择部分noisy-instance组,将这些instance通过ego pose和velocity投影到当前帧,投影方式与learnable instance一致。
具体实现中,我们设置了5组noisy-instance,每组最大gt数量限制为32,因此会增加5 * 32 * 2=320个额外的instance。时序部分,每次随机选择2组来投影到下一帧。每组instance使用attention mask完全隔开,与DINO中的实现不一样的是,我们让noisy-instance也无法和learnable instance进行特征交互,如上图(b)。
Quality Estimation
除了denosing,我们引入了第二个辅助监督任务,Quality Estimation,初衷一方面是加入更多信息让模型收敛更平滑,另一方面是让输出的置信度排序更准确。对于第二点,我们在实验过程中,发现两个异常现象:
- 相比dense-based算法,query-based算法的mATE(mean Average-Translation Error)指标普遍较差,即使是confidence高的预测结果也会存在较大的距离误差,如下图(a);
- Sparse4D在行人上的Precision-Recall曲线前半段会迅速降低,如下图(b);
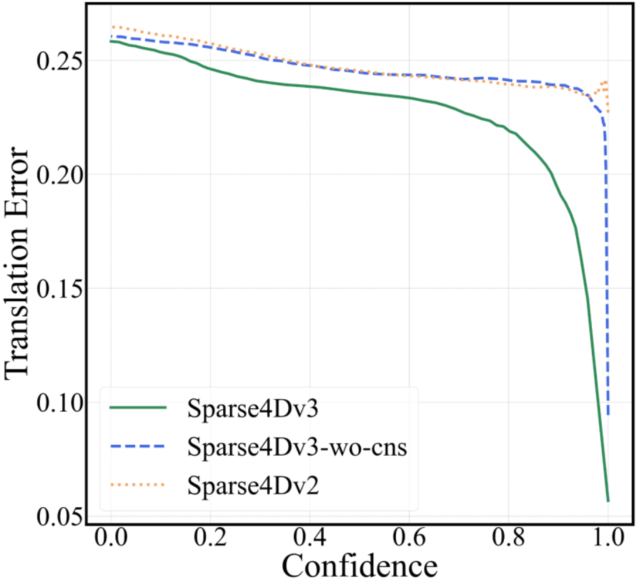
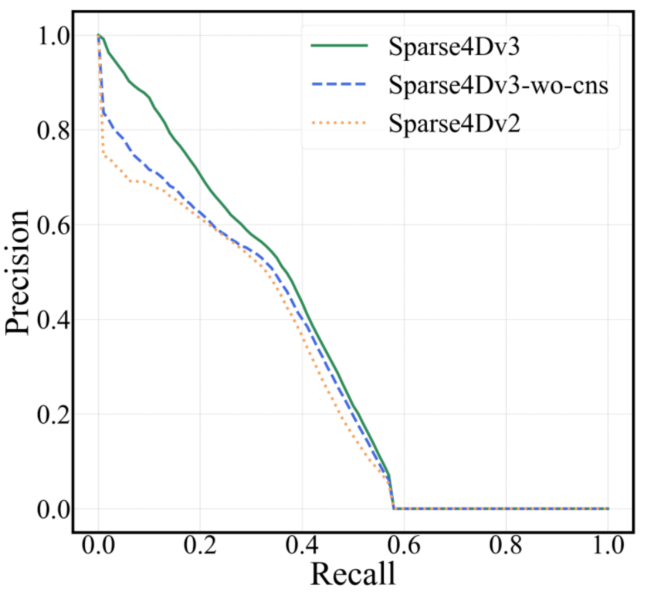
上述现象说明,Sparse4D输出的分类置信度并不适合用来判断框的准确程度,这主要是因为one2one 匈牙利匹配过程中,正样本离GT并不能保证一定比负样本更近,而且正样本的分类loss并不随着匹配距离而改变。而对比dense head,如CenterPoint或BEV3D,其分类label为heatmap,随着离gt距离增大,loss weight会发生变化。
因此,除了一个正负样本的分类置信度以外,还需要一个描述模型结果与GT匹配程度的置信度,也就是进行Quality Estimation。对于3D检测来说,我们定义了两个quality指标,centerness和yawness,公式如下:
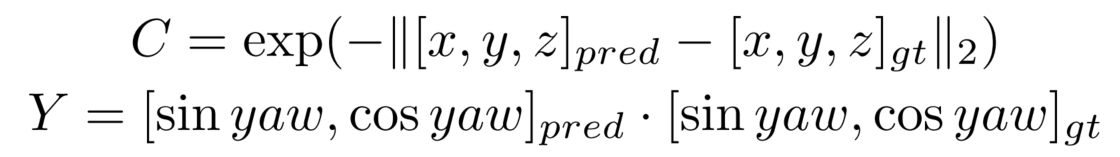
对于centerness和yawness,我们分别用cross entropy loss和focal loss来进行训练。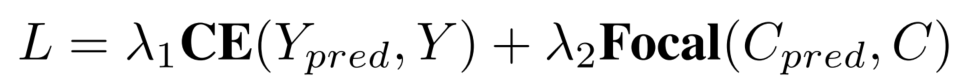
从上图的曲线来看,对比Sparse4D v3和v2,可以看出加入Quality Estimation之后,有效缓解了排序不准确的问题。
3.2 解决实例特征attention 中的混淆问题 - Decopled Attention
Sparse4D中有两个instance attention模块,1)instance self-attention和2)temporal instance cross-attention。在这两个attention模块中,将instance feature和anchor embed相加作为query与key,在计算attention weights时一定程度上会存在特征混淆的问题[7],如图下所示。
为了解决这问题,我们对attention模块进行了简单的改进,将所有特征相加操作换成了拼接,提出了decoupled atttention module,结构如下图所示。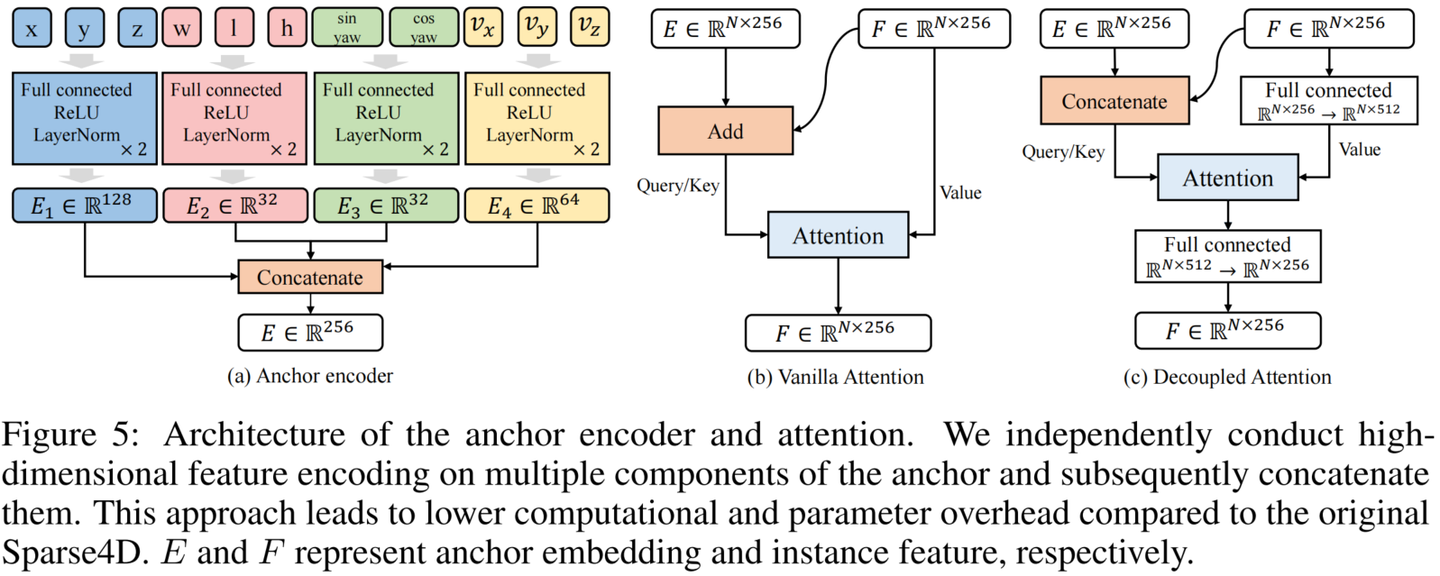
3.3 无需额外训练策略的端到端多目标跟踪能力
由于Sparse4D已经实现了目标检测的端到端(无需dense-to-sparse的解码),进一步的我们考虑将端到端往检测的下游任务进行拓展,即多目标跟踪。我们发现当Sparse4D经过充分检测任务的训练之后,instance在时序上已经具备了目标一致性了,即同一个instance始终检测同一个目标。因此,我们无需对训练流程进行任何修改,只需要在infercence阶段对instance进行ID assign即可,infer pipeline如下所示。
对比如MOTR、TransTrack、TrackFormer等一系列端到端跟踪算法,我们的实现方式具有以下两点不同
- 训练阶段,无需进行任何tracking的约束;
- Temporal instance不需要卡高阈值,大部分temporal instance不表示一个历史帧的检测目标。
3.4 实验验证
Ablation Study
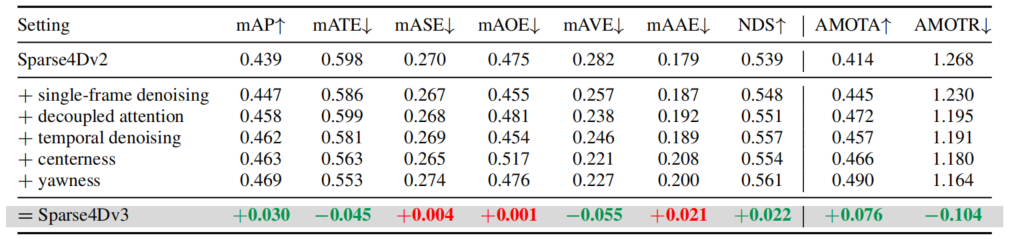
在nuscenes validation数据集上进行了消融实验,可以看出Sparse4D v3的几个改进点(temporal isntance denosing、decoupled attention和quality estimation)对感知性能均有提升。
Compare with SOTA
在nuscenes detection和tracking两个benchmark上,Sparse4D均达到了SOTA水平。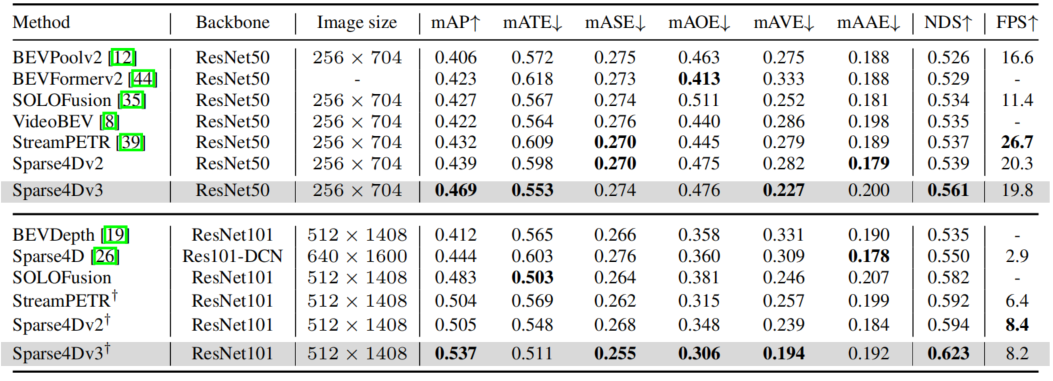
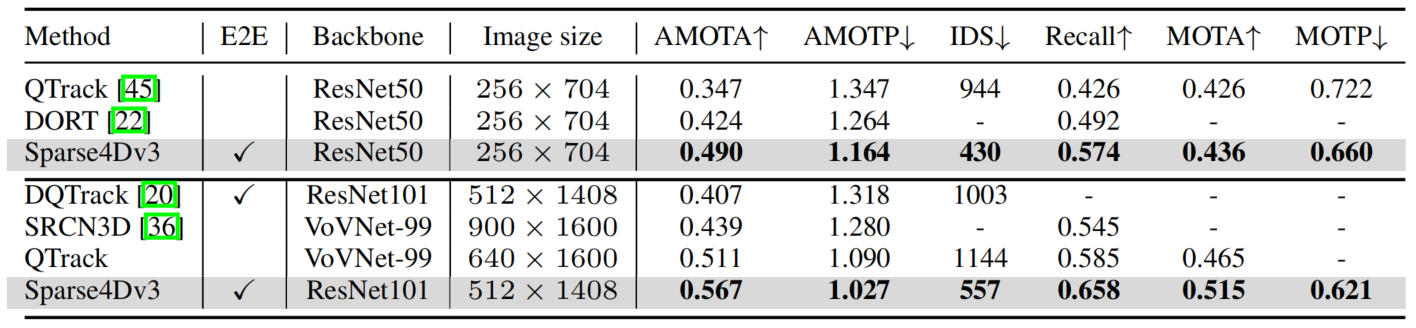

Cloud-Based Performance Boost
针对云端系统,为了进一步提升模型的性能,我们进行了offline 模型和加大backbone的尝试。
- 用Sparse4D v1的多帧采样的方式,我们加入了未来8帧的特征;
- 用EVA02-large作为backbone,EVA02在ImageNet-21k进行了clip+mim的自监督训练,在object365和coco上2D检测的监督训练;
我们最终在nuscenes test数据集上获得了NDS=71.9和AMOTA=67.7,在部分指标上甚至超过了LiDAR-based和multi-modality的模型。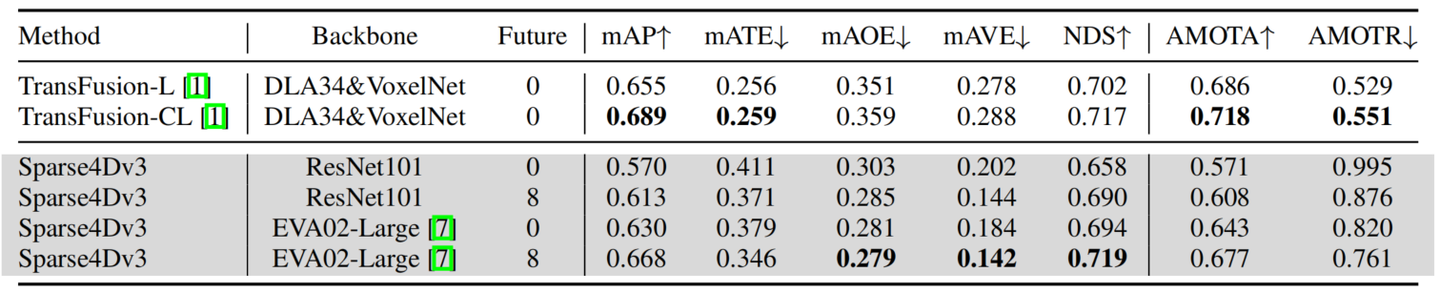
三、总结与展望
总的来说,在长时序稀疏化3D 目标检测的一路探索中,我们主要有如下的收获:
- 显式的稀疏实例表示方式:将待检测的instance 表示为3D anchor 和 instance feature,并不断进行迭代更新来获得检测结果是一种简洁、有效的方式。同时,这种方式也更容易进行时序的运动补偿;
- 高效的Deformable Aggregation 算子:我们提出了针对多视角/多尺度图像特征 + 多关键点的层级化特征采样与融合策略,并进行了大幅的效率优化,使我们能高效获得高质量的特征表示。同时在稀疏化的形式下,decoder 部分的计算量和计算延时受输入图像分辨率的影响不大,能更好处理高分辨率输入;
- Recurrent 的时序稀疏融合框架:基于稀疏实例的时序recurrent 融合框架,使得时序模型基本上具备与单帧模型相同的推理速度,同时在帧间只需要占用少量的带宽(比起bev 的时序方案)。这样轻量且有效的时序方案很适合在真实的车端场景处理多摄视频流数据。
- 端到端多目标跟踪:在无需对训练阶段进行任何修改的情况下,实现了从多视角视频到目标轨迹的端到端感知,进一步减小对后处理的依赖,算法结构和推理流程非常简洁;
- 卓越的感知性能:我们在稀疏感知框架下进行了一系列性能优化,在不增加推理计算量的前提下,让Sparse4D在检测和跟踪任务上都取得了SOTA的水平。
基于稀疏范式的感知算法仍然有很多未解决的问题,也具有很大的发展空间。首先,如何将Sparse的框架应用到更广泛的感知任务上是下一步需要探索的,例如道路元素的感知任务(HD map construction、 topology等)、预测规控任务(trajectory prediction、end-to-end planning等);其次,我们需要对稀疏感知算法进行更充足的验证,保证其具备量产能力,例如远距离检测效果、相机内外参泛化能力及多模态融合感知性能等。我们希望Sparse4D(v3)可以作为稀疏感知方向新的baseline,推动该领域的进步。
四、参考文献
[1] Lin X, Lin T, Pei Z, et al. Sparse4D: Multi-view 3D Object Detection with Sparse Spatial-Temporal Fusion[J]. arXiv preprint arXiv:2211.10581, 2022.
[2] Lin X, Lin T, Pei Z, et al. Sparse4D v2: Recurrent Temporal Fusion with Sparse Model[J]. arXiv preprint arXiv:2305.14018, 2023.
[3] Wang Y, Guizilini V C, Zhang T, et al. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries[C]//Conference on Robot Learning. PMLR, 2022: 180-191.
[4] Wang S, Liu Y, Wang T, et al. Exploring Object-Centric Temporal Modeling for Efficient Multi-View 3D Object Detection[J]. arXiv preprint arXiv:2303.11926, 2023.
[5] Wang Y, Zhang X, Yang T, et al. Anchor detr: Query design for transformer-based detector[C]//Proceedings of the AAAI conference on artificial intelligence. 2022, 36(3): 2567-2575.
[6] Liu S, Li F, Zhang H, et al. Dab-detr: Dynamic anchor boxes are better queries for detr[J]. arXiv preprint arXiv:2201.12329, 2022.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)