南航无人机大规模户外环境视觉导航框架!SM-CERL:基于语义地图与认知逃逸强化学习的无人机户外视觉导航
本文提出的SM-CERL框架通过构建语义地图和认知逃逸机制,有效解决了无人机在大规模户外环境中视觉导航中的部分可观察性和局部最优陷阱问题,显著提升了导航性能。
·

- 作者: Shijin Zhao, Fuhui Zhou, Qihui Wu
- 单位:南京航空航天大学电子信息工程学院
- 论文标题: UAV Visual Navigation in the Large-Scale Outdoor Environment: A Semantic Map-Based Cognitive Escape Reinforcement Learning Method
- 论文链接:https://ieeexplore.ieee.org/abstract/document/10847926
- 出版信息:IEEE Internet of Things Journal (IOT) 20 January 2025
主要贡献
- 提出SM-CERL框架:针对无人机视觉导航中的部分可观察性和局部最优陷阱问题,提出了语义地图基础的认知逃逸强化学习(SM-CERL)框架。
- 知识驱动的导航性能提升:在SM-CERL框架中引入导航先验知识和规则知识,帮助无人机更高效地推断目标位置并逃逸局部最优,显著提升导航性能。
- 卓越的实验性能:通过大量实验验证,SM-CERL在导航准确性和效率方面均优于经典和现有的先进方法,展现出高效的导航能力和对新场景的良好泛化能力。
研究背景
- 无人机技术的快速发展:
- 无人机技术在物联网(IoT)生态系统中的应用日益广泛,如应急救援、农作物保护和交通监控等。
- 无人机视觉导航技术作为关键支撑,能够利用机载相机获取的第一人称视觉输入(实时视频或图像)精准导航至用户指定目标,助力无人机在复杂IoT生态系统中成为智能自主节点,推动智慧城市建设。
- 传统导航方法的局限性:
- 传统的无人机导航方法主要依赖于同时定位与建图(SLAM)技术,通过构建环境地图实现路径规划导航。
- 然而,在大规模户外环境中,SLAM技术因主动构建地图计算效率低,且目标驱动视觉导航更关注达到视觉定义的目标而非构建详细环境地图,导致SLAM难以直接应用。
- 深度强化学习(DRL)的挑战:
- DRL作为一种新兴的导航方法,将导航决策问题建模为马尔可夫决策过程(MDP),利用深度神经网络直接基于输入图像做出导航决策,无需详细环境地图。
- 但DRL在复杂环境中学习有效导航策略面临两大挑战,即部分可观察性和局部最优陷阱。部分可观察性导致无人机难以全面理解环境,局部最优陷阱则使无人机在训练过程中因稀疏或欺骗性奖励而陷入局部最优解,难以找到全局最优策略。
问题描述与马尔可夫决策过程
问题表述
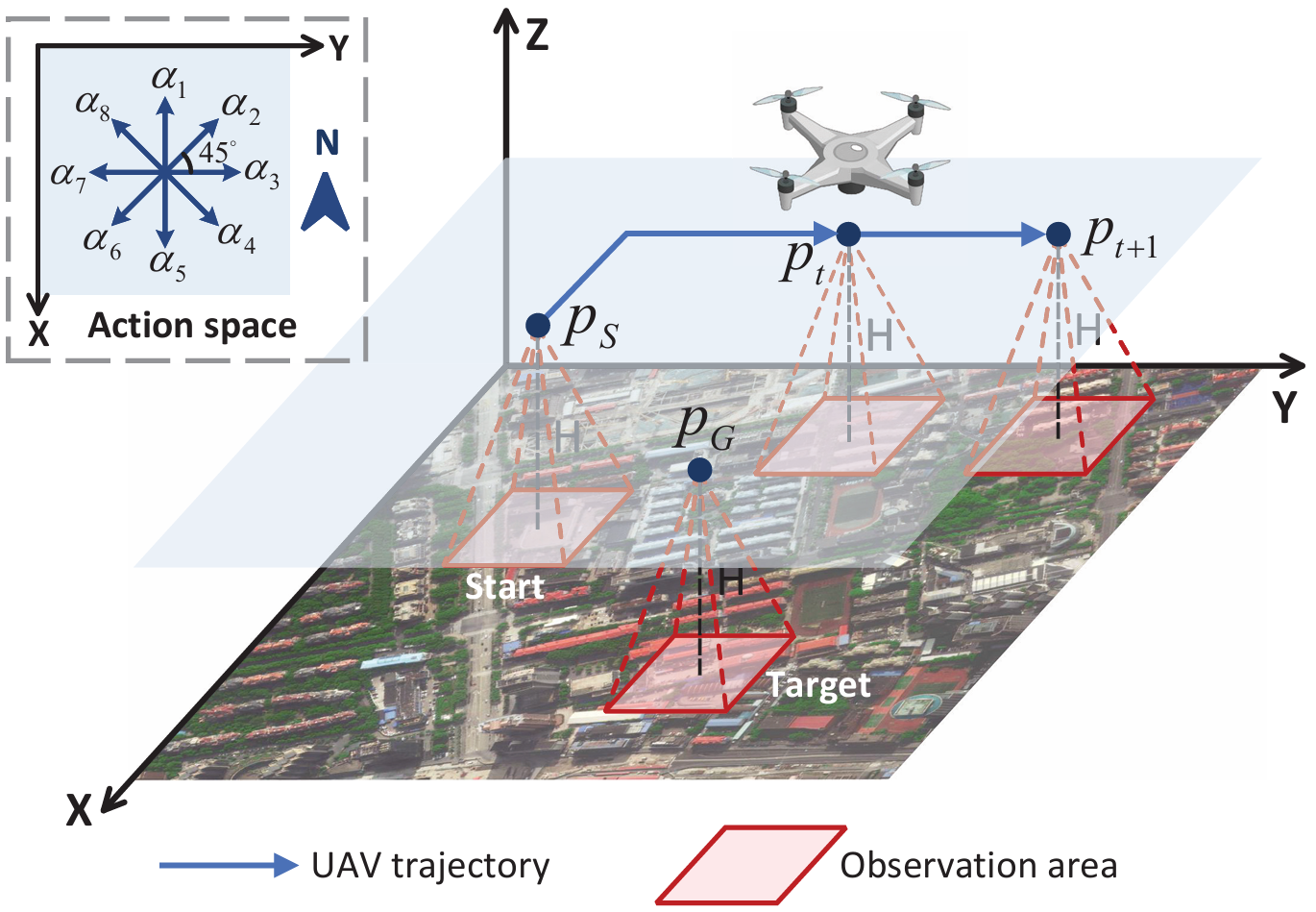
- 任务描述:研究目标驱动的无人机视觉导航任务,无人机在指定空域内导航至未知目标位置。导航过程中,无人机利用机载相机获取的实时观测图像和目标图像(均来自卫星地图)进行导航。
- 飞行环境:假设无人机在高度为 HHH 的水平面上飞行,飞行区域为 [0,D]×[0,D][0, D] \times [0, D][0,D]×[0,D]。导航任务包含 TTT 个时间步,无人机从随机起点 pS=(xS,yS)p_S = (x_S, y_S)pS=(xS,yS) 飞往目标点 pG=(xG,yG)p_G = (x_G, y_G)pG=(xG,yG)。
- 动作空间:无人机的飞行方向被离散化为八个选项,分别以北方向为基准,按顺时针方向每隔45°划分。
- 目标函数:最小化飞行时间 TTT,即
min{pt,∀t∈[0,T]}T, \min_{\{p_t, \forall t \in [0, T]\}} T, {pt,∀t∈[0,T]}minT,
约束条件为:- p0=pSp_0 = p_Sp0=pS,pT=pGp_T = p_GpT=pG;
- xL≤xt≤xUx_L \leq x_t \leq x_UxL≤xt≤xU,yL≤yt≤yUy_L \leq y_t \leq y_UyL≤yt≤yU,确保无人机在指定区域内飞行。
基于MDP的无人机导航建模
- MDP定义:将无人机视觉导航问题建模为马尔可夫决策过程(MDP),其中无人机作为智能体(agent)与环境进行交互。
- 状态(State):定义为基于观测的语义地图 Mt∈R2×Ng×NgM_t \in \mathbb{R}^{2 \times N_g \times N_g}Mt∈R2×Ng×Ng,包含两个通道:
- 探索地图通道 Met∈R1×Ng×NgM_e^t \in \mathbb{R}^{1 \times N_g \times N_g}Met∈R1×Ng×Ng,存储已探索、未探索和当前位置的信息(分别用0、-1和1表示)。
- 相似度地图通道 Mst∈R1×Ng×NgM_s^t \in \mathbb{R}^{1 \times N_g \times N_g}Mst∈R1×Ng×Ng,存储与目标图像相似度值(已探索区域的相似度值为 vst∈{0,1}v_s^t \in \{0, 1\}vst∈{0,1},未探索区域为-1)。
- 动作(Action):无人机的飞行方向,动作空间为 A={α1,α2,…,α8}A = \{\alpha_1, \alpha_2, \dots, \alpha_8\}A={α1,α2,…,α8}。
- 奖励函数(Reward Function):
rt={rg,if pt=pG,rb,if xt∉[0,D] or yt∉[0,D],rp,else. r_t = \begin{cases} r_g, & \text{if } p_t = p_G, \\ r_b, & \text{if } x_t \notin [0, D] \text{ or } y_t \notin [0, D], \\ r_p, & \text{else}. \end{cases} rt=⎩ ⎨ ⎧rg,rb,rp,if pt=pG,if xt∈/[0,D] or yt∈/[0,D],else.
其中,rgr_grg 为目标奖励,rbr_brb 为越界惩罚,rpr_prp 为时间惩罚,激励无人机快速到达目标。
- 状态(State):定义为基于观测的语义地图 Mt∈R2×Ng×NgM_t \in \mathbb{R}^{2 \times N_g \times N_g}Mt∈R2×Ng×Ng,包含两个通道:
SM-CERL框架
框架概述
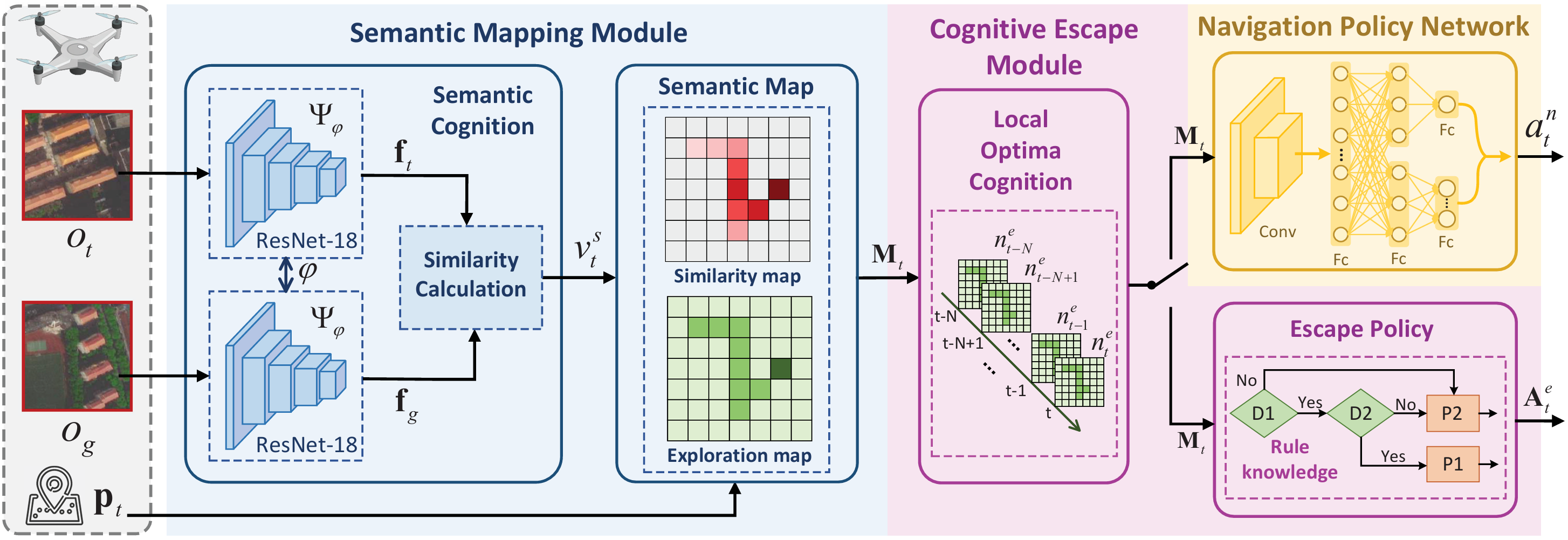
- 框架组成:SM-CERL框架包含三个模块:
- 语义映射模块(SMM):替代传统DRL模型中的感知层,从原始图像中提取语义信息并构建语义地图。
- 认知逃逸模块(CEM):主动识别局部最优并制定逃逸策略。
- 导航策略网络(NPN):基于语义地图生成导航动作,相当于传统DRL模型中的决策层。
语义映射模块(SMM)
- 语义认知子模块:
- 使用预训练的孪生网络(每个分支为ResNet-18)提取当前观测图像 oto_tot 和目标图像 oGo_GoG 的特征向量 ftf_tft 和 fGf_GfG。
- 通过相似性计算组件(SCC)计算特征距离 dft=∥ft−fG∥2d_f^t = \|f_t - f_G\|_2dft=∥ft−fG∥2,进而得到相似度 vst=max(0,1−dftdfmax)v_s^t = \max(0, 1 - \frac{d_f^t}{d_f^{\text{max}}})vst=max(0,1−dfmaxdft),其中 dfmaxd_f^{\text{max}}dfmax 为最大阈值。
- 语义地图子模块:
- 根据相似度 vstv_s^tvst 和当前位置 ptp_tpt 更新探索地图和相似度地图,构建语义地图 MtM_tMt,为无人机提供环境语义信息和导航先验知识。
认知逃逸模块(CEM)
- 局部最优认知(LOC):
- 通过跟踪语义地图中已探索位置的数量,判断无人机是否陷入局部最优。若连续多个时间步中探索位置数量未增加,则认定无人机陷入局部最优。
- 逃逸策略(EP):
- 将语义地图划分为多个子区域,计算各子区域的最大相似度值和探索网格数量。
- 根据规则选择目标子区域(优先选择相似度高且未充分探索的区域),并在其中随机选取未访问位置作为子目标,生成逃逸动作序列,直至到达子目标完成逃逸。
导航策略网络(NPN)
- 网络结构:采用Dueling Double Deep Q Network(D3QN)算法作为基础算法。
- 输入语义地图 MtM_tMt,通过两个卷积层提取特征(第一个卷积层有16个4×4滤波器,步长为2;第二个卷积层有32个2×2滤波器,步长为2),每个卷积层后接ReLU激活函数。
- 提取的特征输入到Dueling网络中,分别估计价值函数和优势函数,最终输出8维Q值向量,依据贪婪策略选择动作。
SM-CERL的训练
训练过程概述
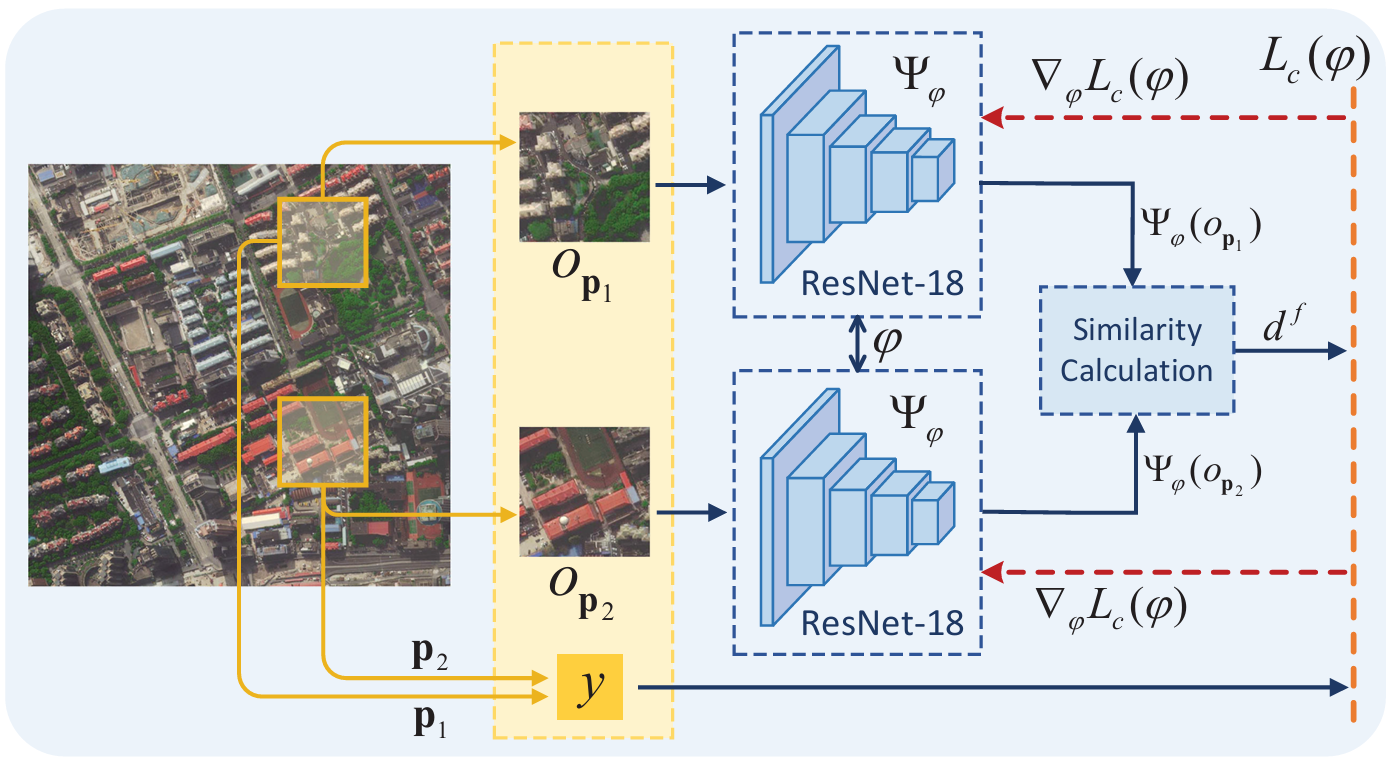
- 独立训练:SM-CERL的训练分为两个独立阶段,即语义认知网络的训练和导航策略网络的训练,两个网络可以独立训练。
语义认知网络训练
- 孪生网络训练目标:学习参数 ϕ\phiϕ,使网络能够将高维图像空间转换为低维特征空间,特征向量的欧几里得距离与原始图像空间中的相似度呈负相关。
- 训练数据:从不同城市的卫星地图中创建数据对 (op1,op2,y)(o_{p1}, o_{p2}, y)(op1,op2,y),根据图像中心点距离判断相似性(距离小于 kkk 为正样本,大于 λk\lambda kλk 为负样本)。
- 对比损失函数:
Lc(ϕ)=12y(df)2+12(1−y)max(dm−df,0)2, L_c(\phi) = \frac{1}{2} y (d_f)^2 + \frac{1}{2} (1 - y) \max(d_m - d_f, 0)^2, Lc(ϕ)=21y(df)2+21(1−y)max(dm−df,0)2,
其中 dmd_mdm 为安全阈值,通过梯度优化方法最小化损失函数,使网络能够有效捕捉图像的相似性结构。
导航策略网络训练
- 训练算法:基于SM-CERL的导航策略网络训练过程如算法1所示。
- 初始化地图、起点和目标点,构建语义地图 MtM_tMt 作为状态 sts_tst。
- 若无人机未陷入局部最优,则利用NPN选择动作并执行,存储训练经验 (st,at,rt,st+1)(s_t, a_t, r_t, s_{t+1})(st,at,rt,st+1) 到回放缓冲区 DDD,随机采样进行网络训练。
- 若无人机陷入局部最优,则利用CEM生成逃逸策略并执行逃逸动作,直至逃逸完成,随后继续利用NPN进行导航和训练。
- 目标Q值计算:
yi={ri,if doneri+γ⋅Q(si+1,argmaxaQ(si+1,a;θ);θ−),otherwise y_i = \begin{cases} r_i, & \text{if done} \\ r_i + \gamma \cdot Q(s_{i+1}, \arg\max_a Q(s_{i+1}, a; \theta); \theta^-), & \text{otherwise} \end{cases} yi={ri,ri+γ⋅Q(si+1,argmaxaQ(si+1,a;θ);θ−),if doneotherwise
其中 θ−\theta^-θ− 为目标网络参数,每 NuN_uNu 步更新一次。 - 损失函数:
LQ(θ)=E(si,ai,ri,si+1)[(yi−Q(si,ai;θ))2], L_Q(\theta) = \mathbb{E}_{(s_i, a_i, r_i, s_{i+1})} \left[ (y_i - Q(s_i, a_i; \theta))^2 \right], LQ(θ)=E(si,ai,ri,si+1)[(yi−Q(si,ai;θ))2],
通过梯度下降法更新网络参数 θ\thetaθ。
实验
- 实验设置:选择六个不同区域的卫星地图,大小为3km×3km,均匀划分为30×30网格作为导航地图,每个网格单元对应100m×100m的物理区域。在训练过程中,为D3QN的训练策略添加随机性,使无人机有一定概率选择随机动作,而在评估时,无人机始终使用测试策略贪婪地选择最优行为。
- 对比方法:
- 随机动作(RA):无人机在每个时间步从动作空间中随机选择动作。
- CRL:与SM-CERL相比,CRL去除了SMM和CEM组件,仅使用语义认知网络生成的相似性信息作为状态,其策略网络训练过程如算法2所示,作为基线方法比较记忆增强和局部最优逃逸机制的效果。
- SM-CRL:保留SM-CERL的状态,但去除了CEM,在训练中不包含识别和逃逸局部最优的步骤,用于评估CEM对导航性能的贡献。
- LSTM-CRL:在CRL基础上引入LSTM网络,增强无人机的记忆能力,其训练过程与算法2相同,作为对比基线评估不同记忆增强机制(LSTM与SMM)对导航性能的影响。
- CERL-old:采用早期的CERL框架,基于已探索区域的信息随机逃逸至未访问区域,未利用探索相似性信息,用于评估增强型认知逃逸机制在逃逸局部最优方面的优势。
- CERL:与SM-CERL相比,CERL去除了SMM,使用与CRL相同的状态,在训练中不包含语义映射过程,用于评估语义地图对导航性能的影响。
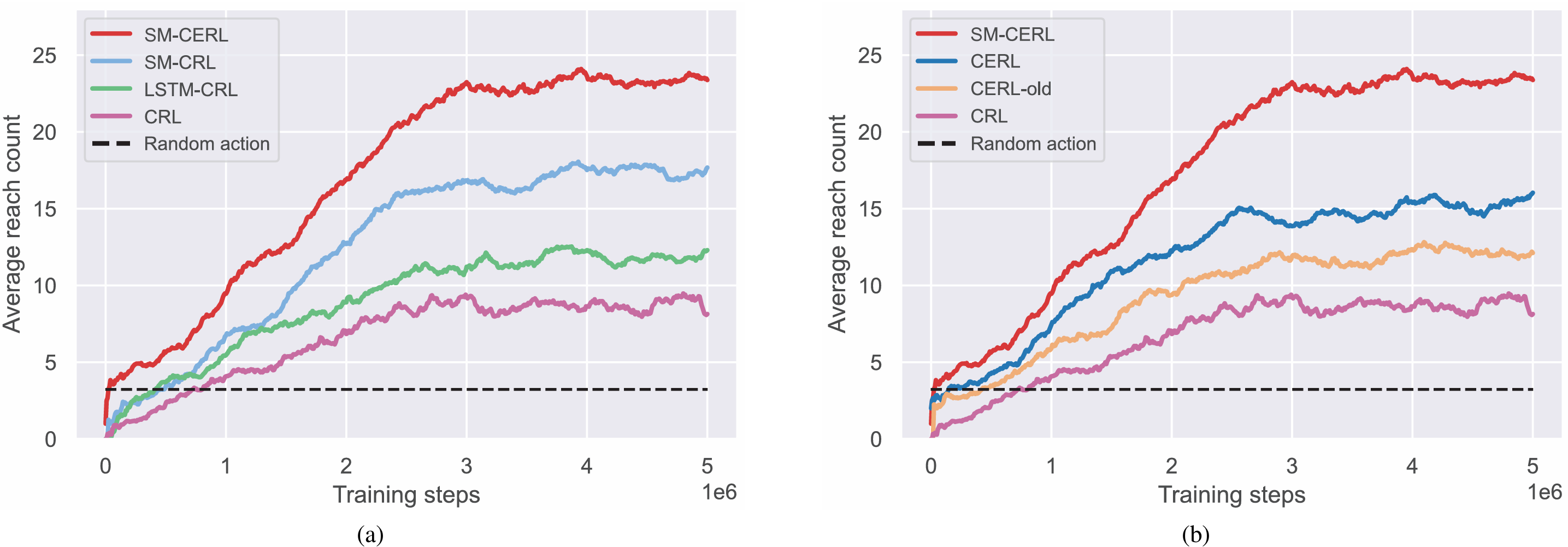
- 训练性能评估:
- 通过在训练过程中定期评估测试策略来衡量不同方法的训练性能,以平均到达次数作为评估指标。
- SM-CERL方法在训练过程中平均到达次数最高,表明其学习到了更有效的导航策略,能够更频繁地在规定时间步内到达目标。
- 导航性能比较:
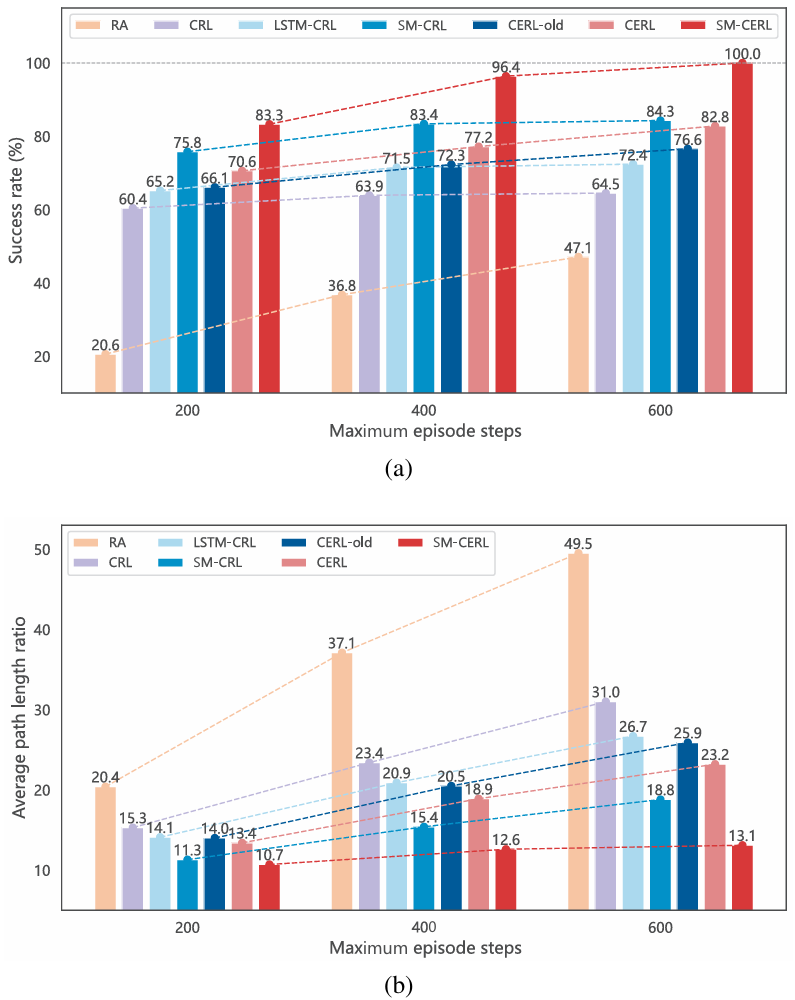
- 在训练五百万步后,对各模型进行1000次导航测试,以成功率(SR)和平均路径长度比(APLR)衡量导航性能。
- SM-CERL方法在所有测试方法中均实现了最高的成功率和最短的平均路径长度比,证明了其在导航准确性和效率方面的优越性。
- 此外,通过对比CRL、LSTM-CRL和SM-CRL方法,验证了SMM在记忆增强方面的优势;通过对比CRL、CERL-old和CERL方法,证明了增强型CEM在逃逸局部最优方面的有效性。
-
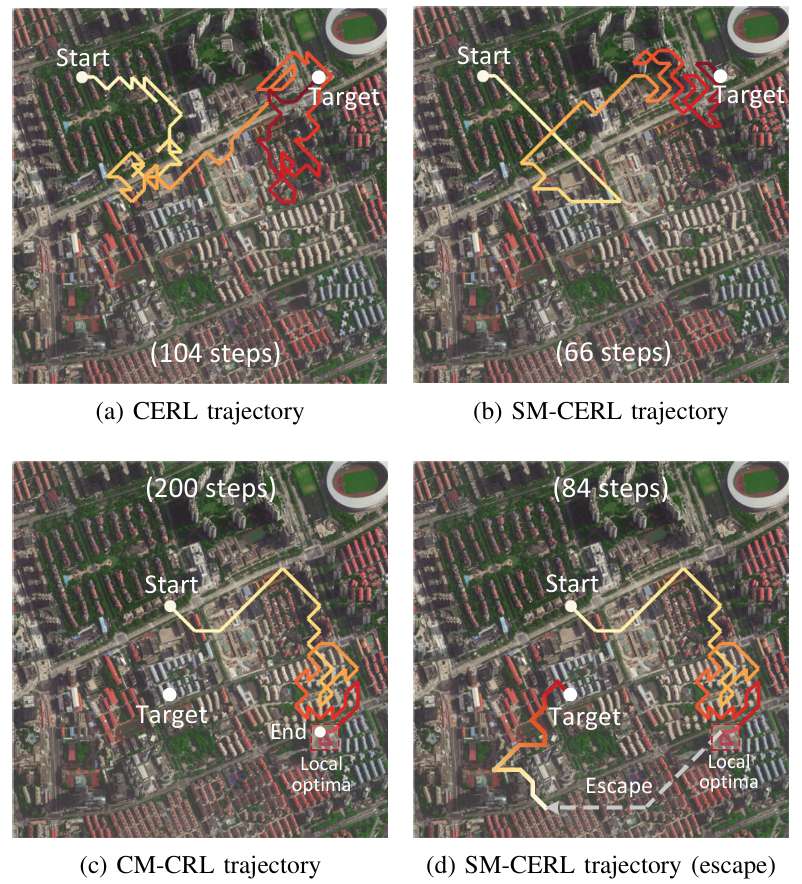
导航行为分析:
- SM-CERL方法的轨迹更高效,避免了重复探索,并能有效逃逸局部最优。
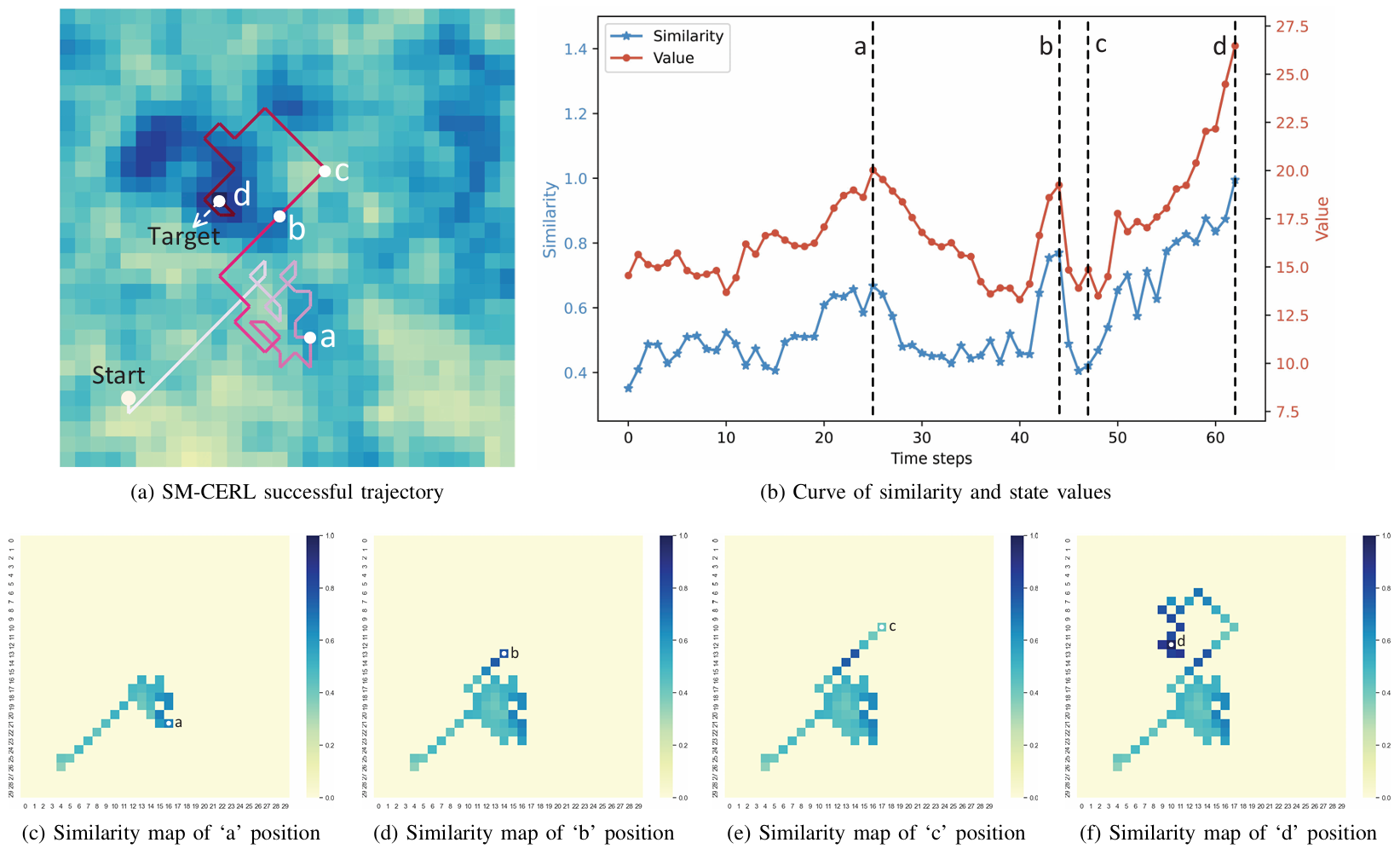
- 下图进一步展示了SM-CERL方法在无局部最优陷阱时的导航轨迹以及相似度和状态值的变化,表明无人机学习到了基于相似度的导航策略,倾向于向相似度更高的区域移动。
- 泛化能力分析:
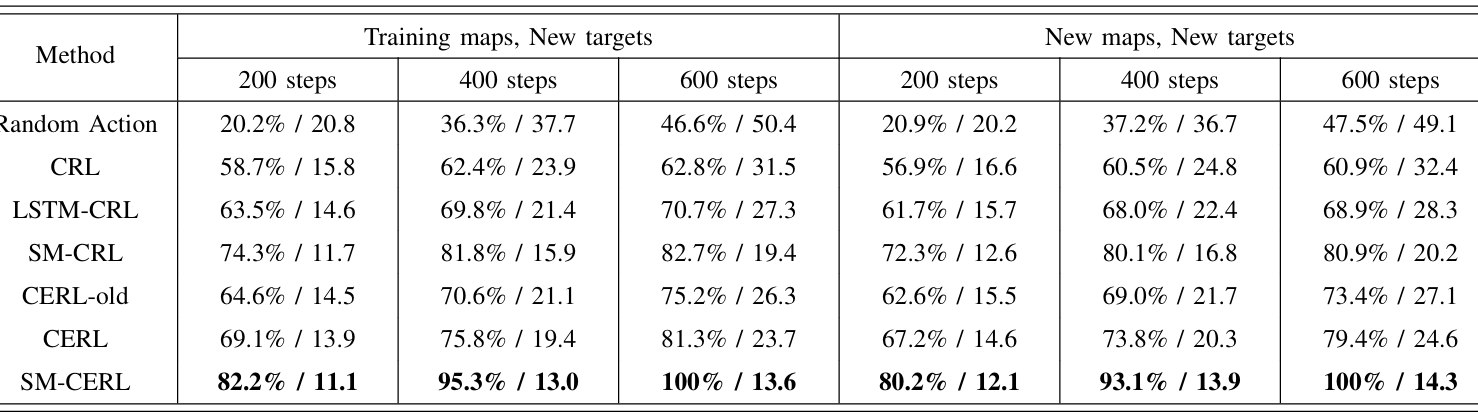
- 在训练地图上设置新目标以及在未见过的地图上设置新目标两种测试场景下,评估不同方法的泛化性能。
- 下表显示,SM-CERL方法在两种场景下均实现了最高的成功率和最短的平均路径长度比,证明了其在新场景下的良好泛化能力。
结论与未来工作
- 结论:
- 本文提出的SM-CERL导航框架通过构建语义地图作为无人机的记忆,并开发针对性的逃逸策略,有效解决了DRL在大规模户外环境中无人机视觉导航所面临的部分可观察性和局部最优陷阱两大挑战。
- 实验结果表明,SM-CERL方法在导航成功率和效率方面优于现有的经典和先进方法,能够使无人机学习到令人满意的导航能力,朝着尚未探索但相似度高的区域飞行,并有效逃逸局部最优,在新场景下也展现出良好的泛化能力,为无人机在各种实际应用中的大规模户外导航提供了有力支持。
- 未来工作:
- 未来的发展可以聚焦于两个主要方面,即跨平台适应性和任务场景多样化。对于跨平台适应性,可以将框架扩展以支持不同类型的无人机(如旋翼和固定翼平台)、实现多无人机协作以及整合额外的传感器(如雷达、激光雷达和热像仪)。
- 对于任务场景多样化,可以将框架扩展以支持各种任务,包括搜索与救援、环境监测和基础设施检查等。此外,还可以通过充分利用集成环境传感器的全面数据、为动态环境开发自适应导航策略以及为各种天气和光照条件建立稳健解决方案来增强框架性能。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)