(RL强化学习)Imitation Learning
文章目录Imitation learningBahavior CloningInverse Reinforcement LearningFrameworkImitation learningactor 可以跟环境互动,actor无法从环境得到reward只有一个expert论证怎么解决这个问题人为设定reward可能造成不可控的问题Bahavior Cloningexpert做什么 actor就做
Imitation learning
-
actor 可以跟环境互动,actor无法从环境得到reward
-
只有一个expert论证怎么解决这个问题
-
人为设定reward可能造成不可控的问题

Bahavior Cloning
-
expert做什么 actor就做什么
-
相当于监督学习 training data需要搜集(s,a)的信息 然后让actor learn 一个Network
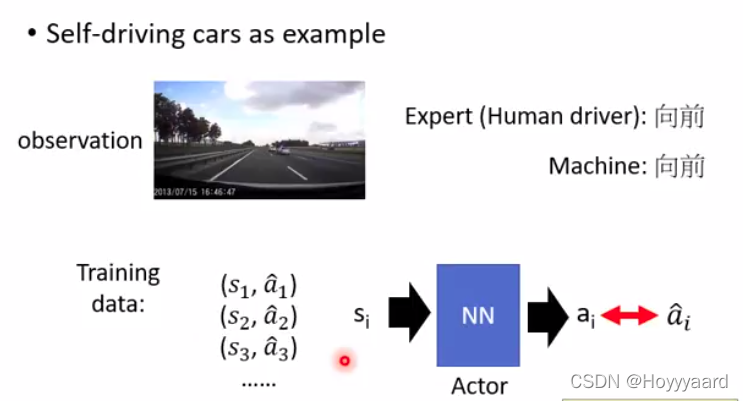
-
但expert只能sample 限量的(s,a),当actor遇到expert没有遇到的问题将会不知道怎么做
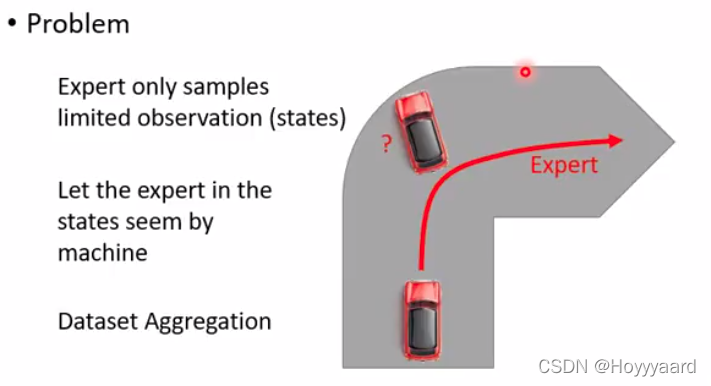
-
所以需要Dataset Aggregation
- 给定一个actor跟环境互动 actor每一步获得的observation都会问expert怎么做 但是这个actor不会听从expert的指令
- 得到一些新的(s,a)成为新的training data
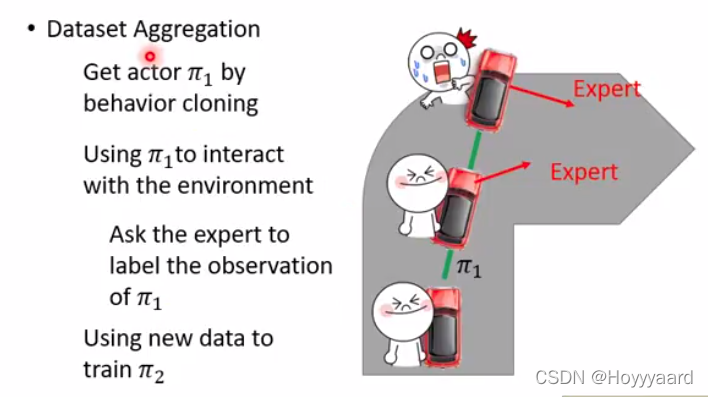
-
expert可能会有多余的动作 希望actor能够只学到必要的东西 而不是expert多余的动作(对接下来没有影响的动作)
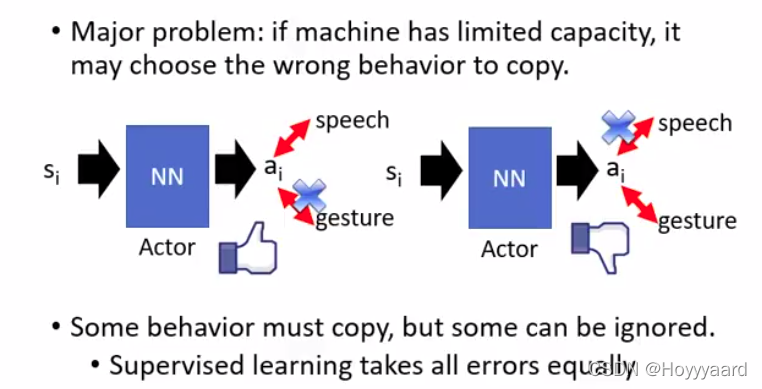
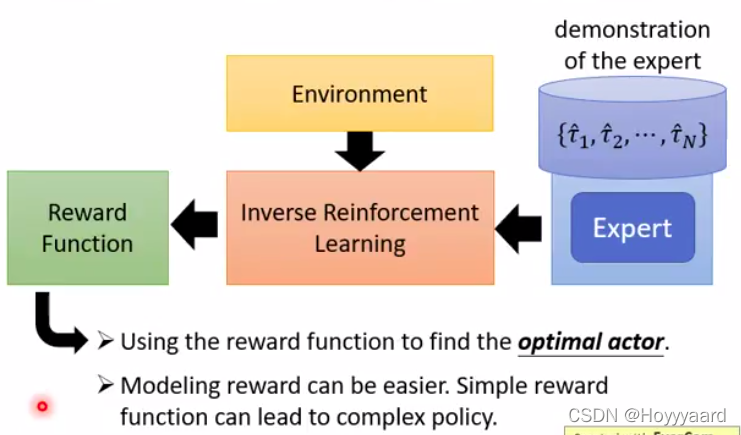
Inverse Reinforcement Learning
- Mismatch
- 监督学习中训练集和测试集分布不一样
- IRL可解决这个问题

- IRL
- 拥有expert反推reward function
- 得出来的reward function可能会是很简单的
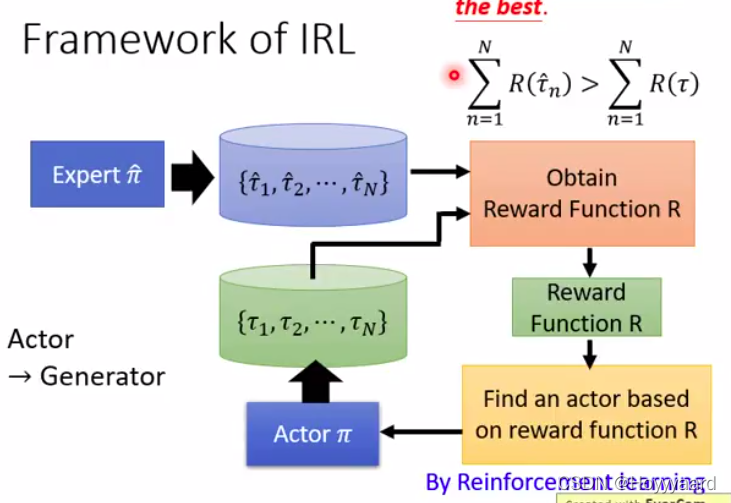
Framework
-
Expert sample data ;Actor sample data
-
reward function原则;expert得到的分数比actor得到的高
-
根据得出来的reward function就可以得到一个actor
-
然后重新定义reward function 继续learn actor

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)