图像生成模型-李宏毅
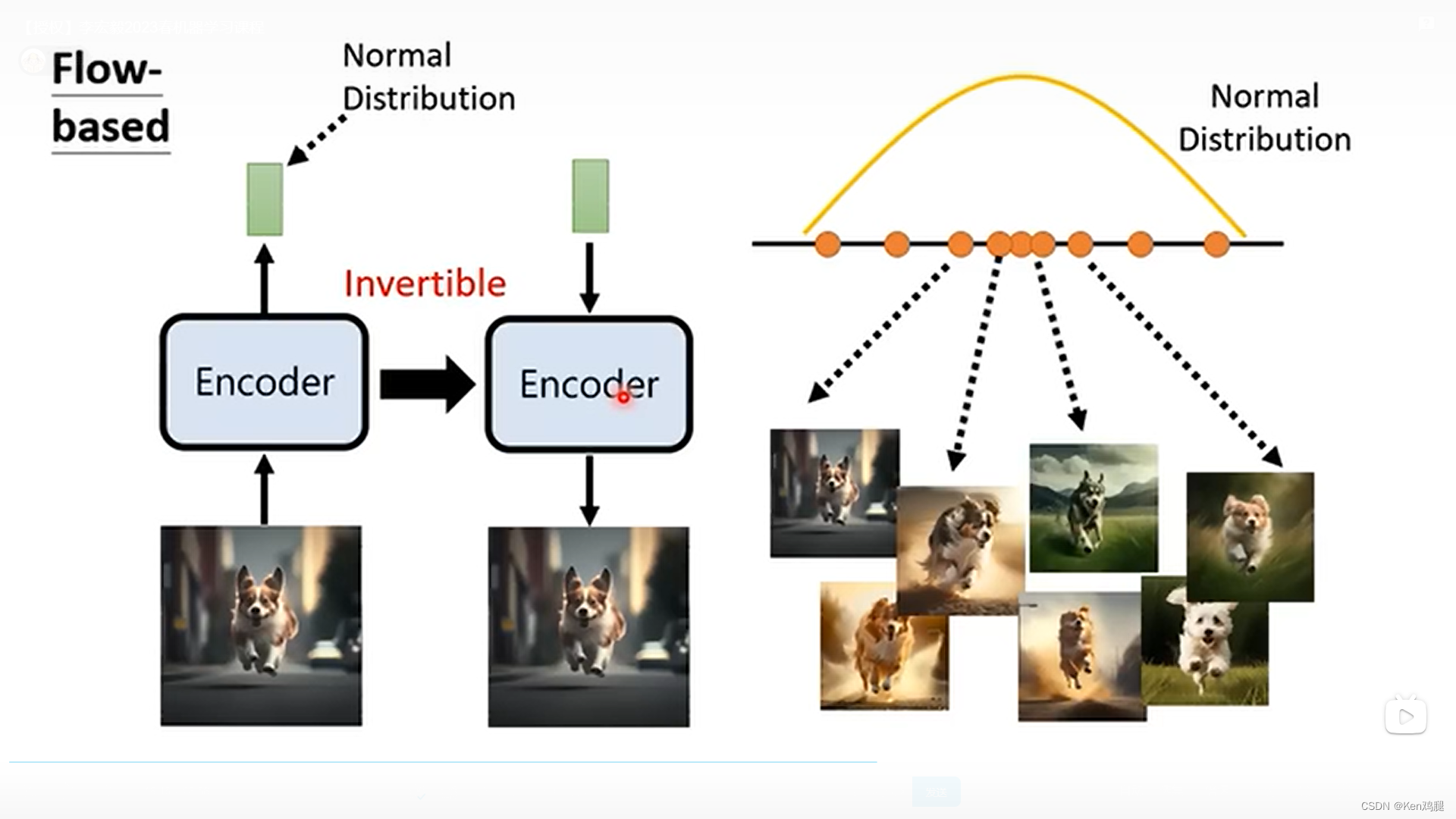
flow-based是将一张图片进行了encoder,是正态分布的,也可以反过来用,放一个向量到encoder,生成一张图片,这个向量是可以invertible。1.对于文字生成,有逐个击破和一次到位两种,映像生成也可以是逐个击破,比如预测下一个颜色,通常是RGB三原色,一个颜色又是有0-255组成,所以可以使256。3.gan是通过正态分布的向量进行decoder生成一张图片,同时训练discr
1.对于文字生成,有逐个击破和一次到位两种,映像生成也可以是逐个击破,比如预测下一个颜色,通常是RGB三原色,一个颜色又是有0-255组成,所以可以使256256256。
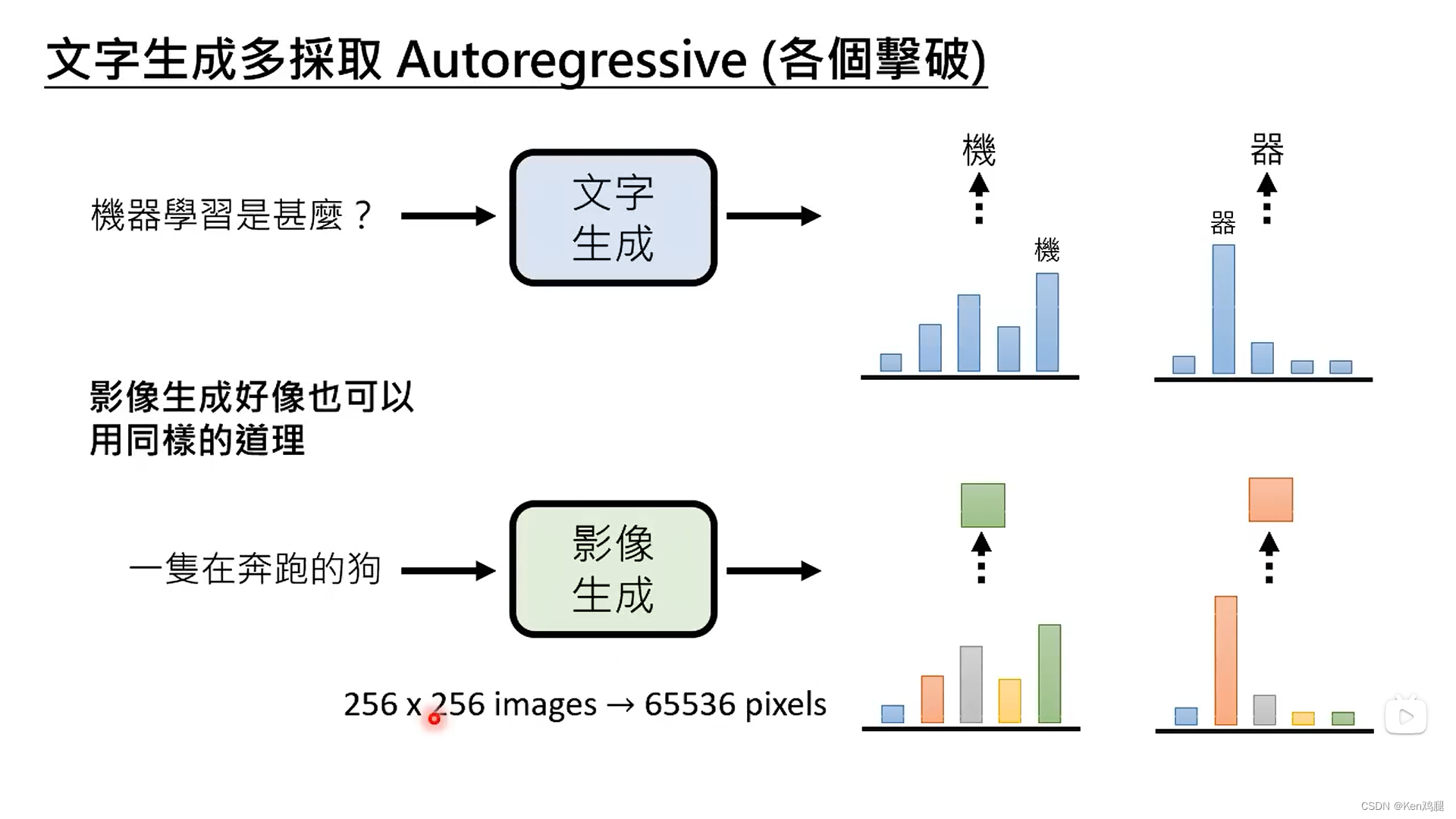
直接将颜色拉直,逐个进行预测,这样生成的图片是一行一行的,但是这样太耗费时间了

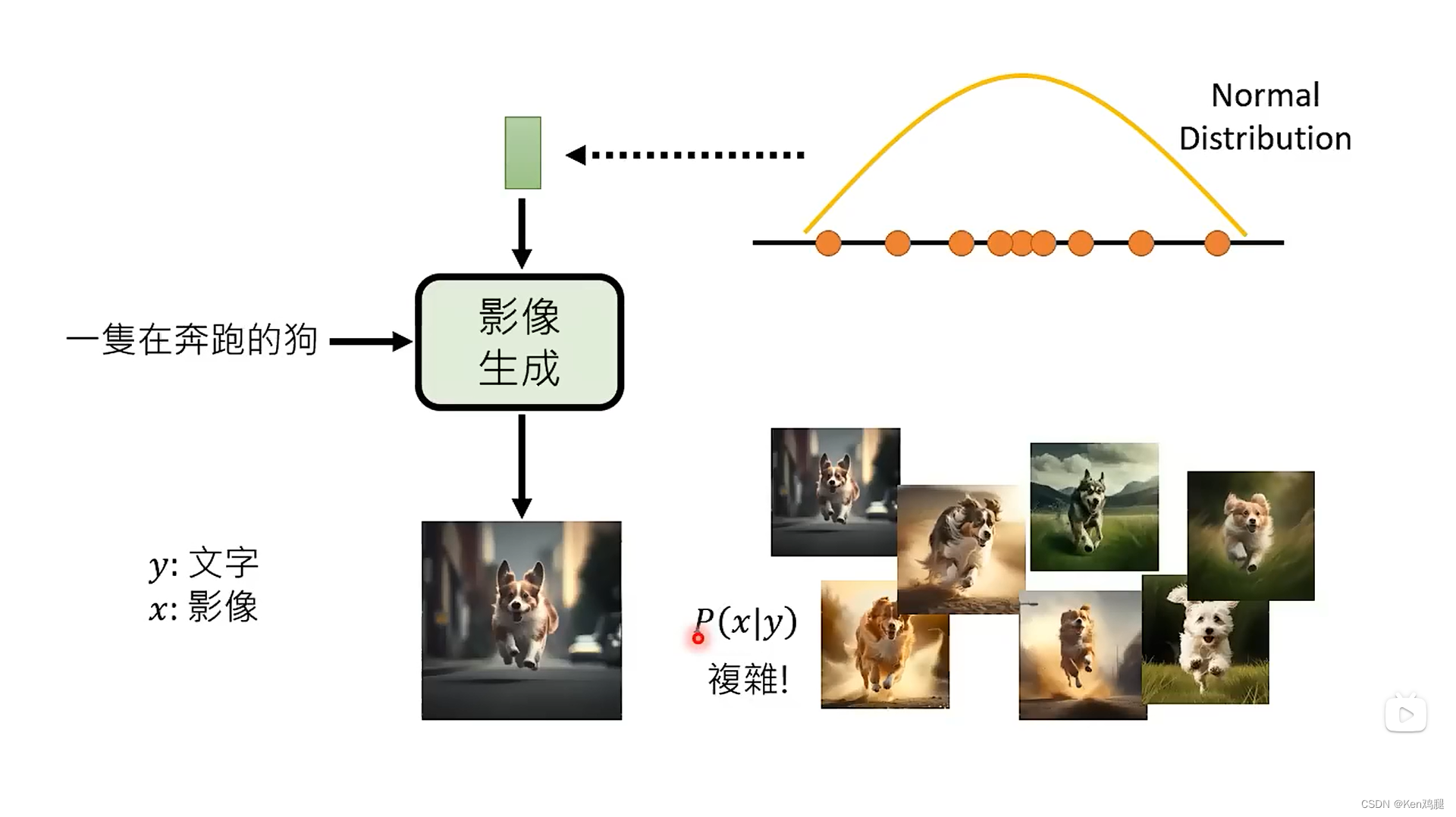
今天我们的主要方法是从一个高维的正态分布中取出一个高维的向量,放到影像生成中,这里将文字用y表示,影像用x表示。一段文字可以生成很多的图像,p(x/y)非常的复杂,
这几个是常用的影像生成的模型
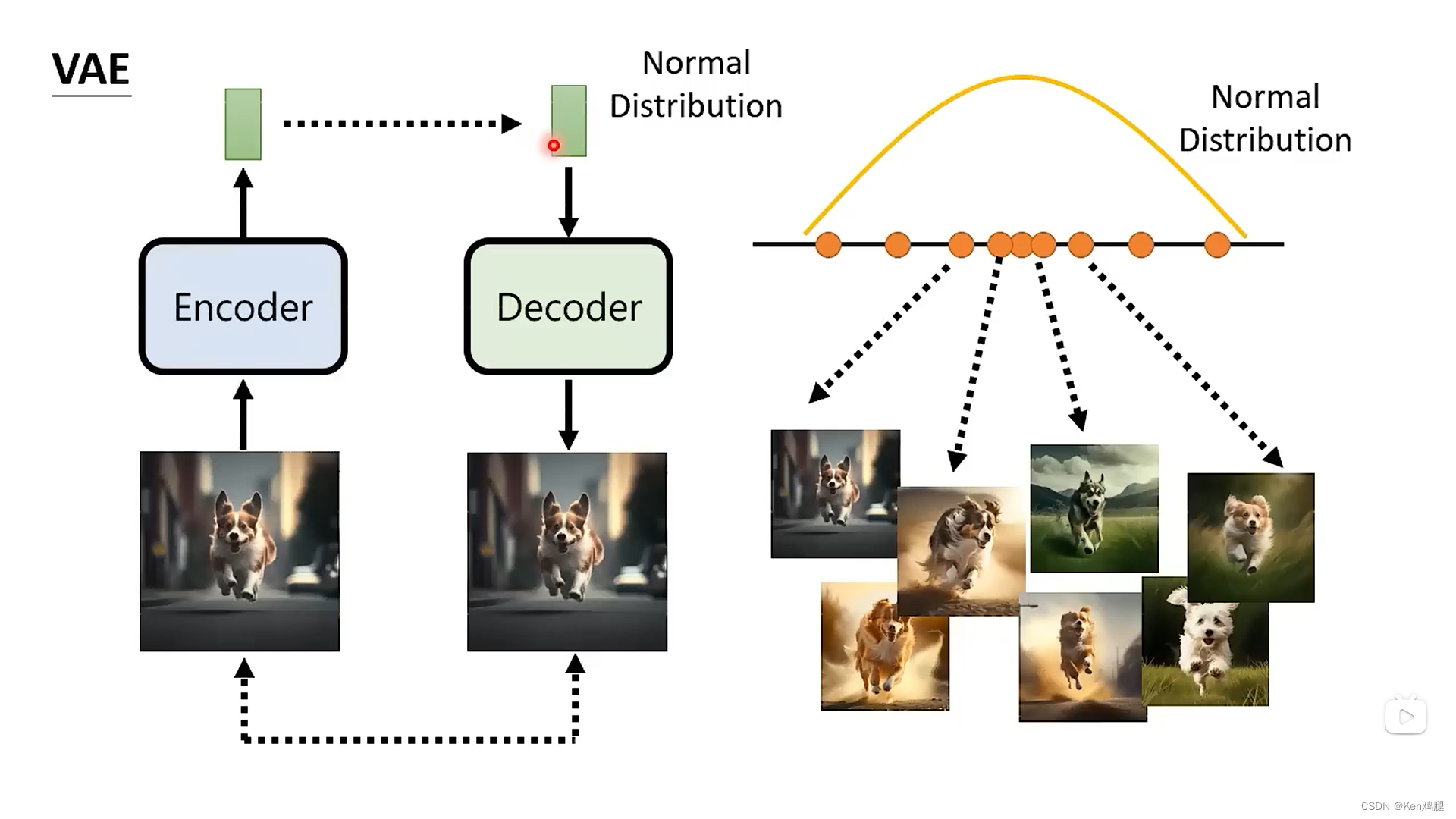
1.vae是将一张图片进行了encoder编程了一个向量,让向量变成正态分布的,再进行decoder,变成一张图片
flow-based是将一张图片进行了encoder,是正态分布的,也可以反过来用,放一个向量到encoder,生成一张图片,这个向量是可以invertible
3.gan是通过正态分布的向量进行decoder生成一张图片,同时训练discriminator,来分辨产生的图片和真实图片,如果分不清了,就进行迭代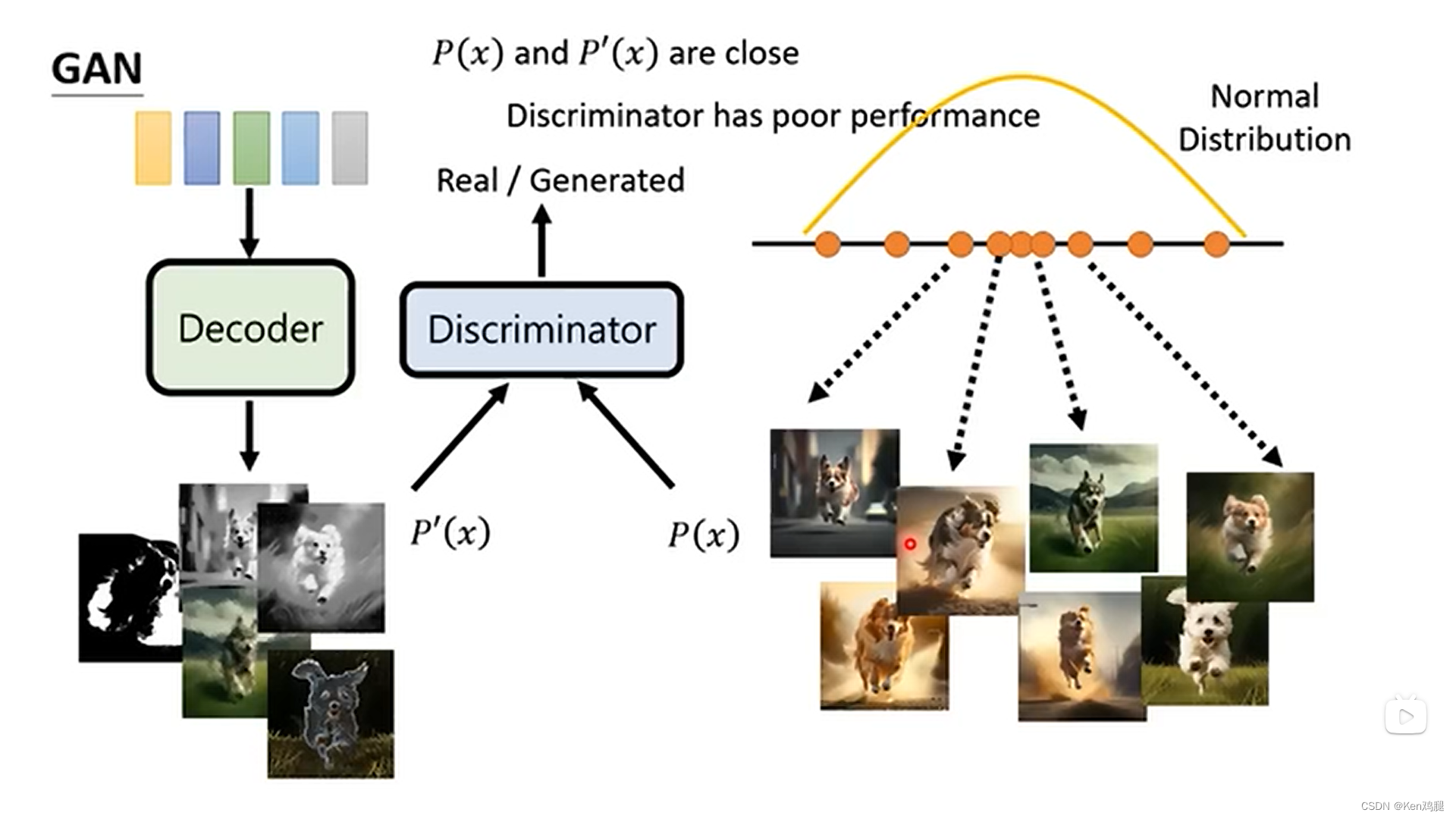
4.diffusion 模型,是通过加上迭代的参数不断地去除噪声,来达到最好的效果
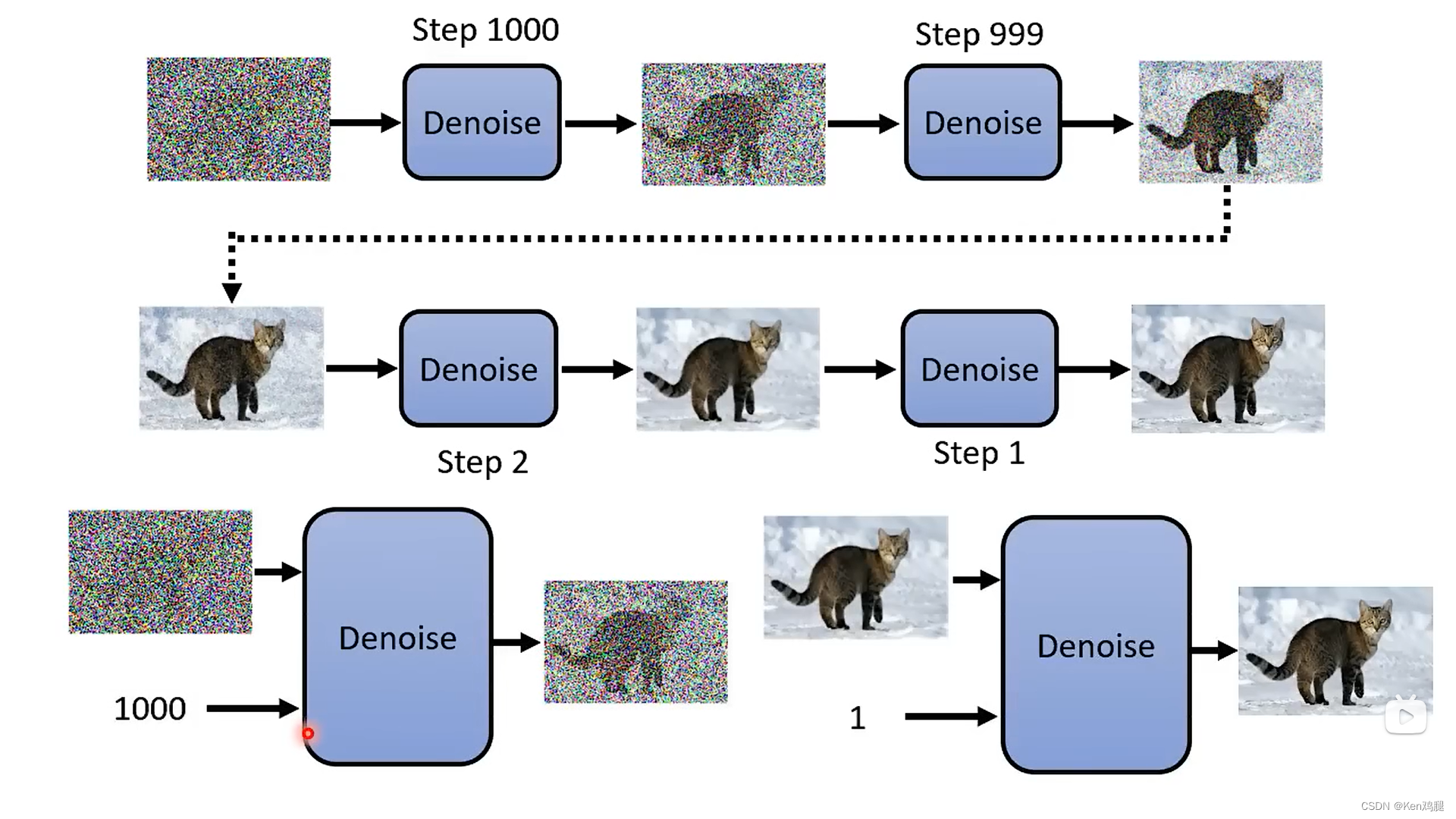
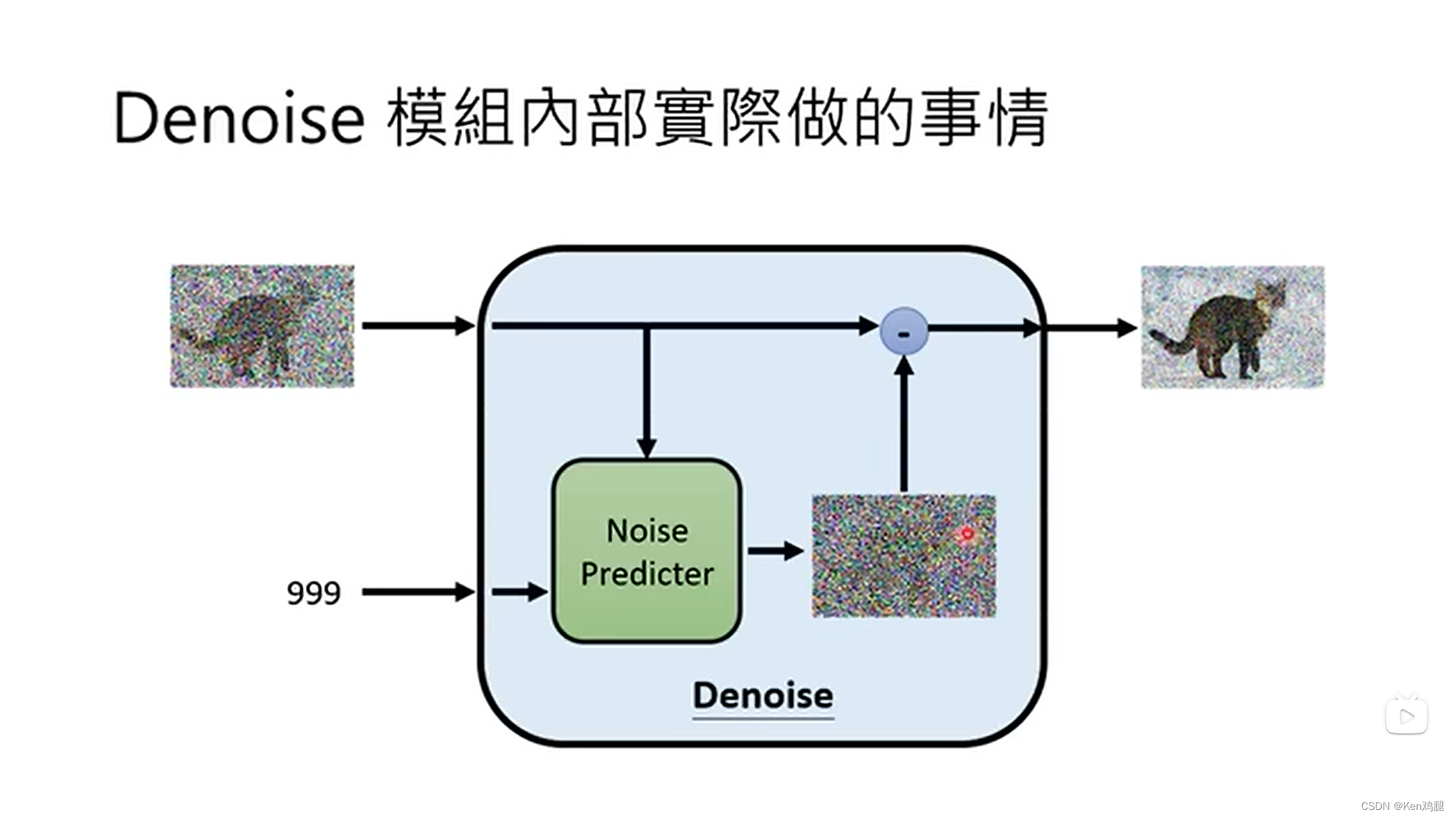
4.1 Denoise模组内部做的事情是通过迭代的次数预测噪点是什么样的,将原图和噪点相减。
这里训练文字生成图片还是需要成对的资料,一般图片是从laion上面找
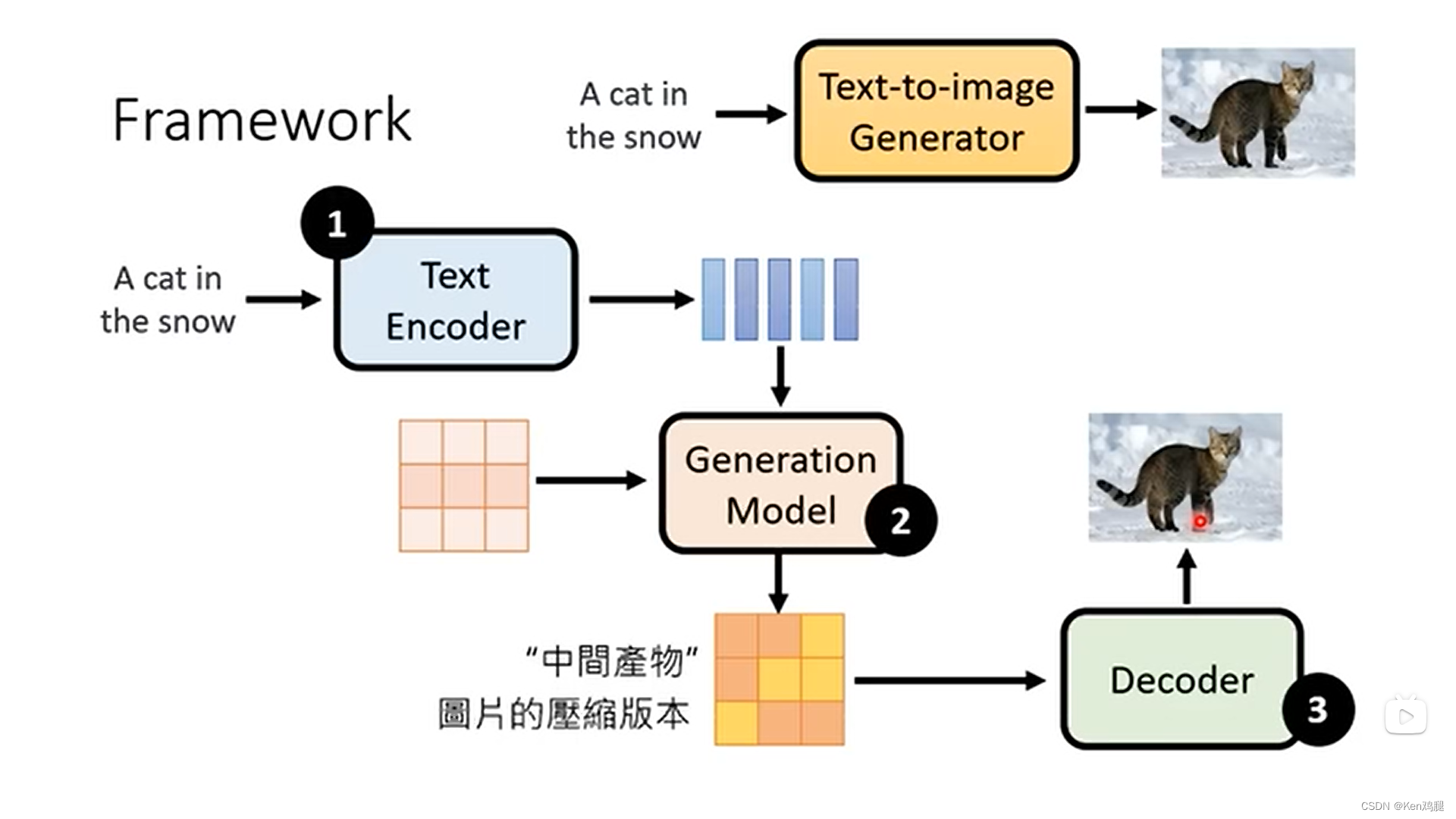
1.现在的diffusion model是将文字放到encoder中,生成向量和噪点一起加入到generation model中,生成一个中间产物,再进行decoder生成最后的图片
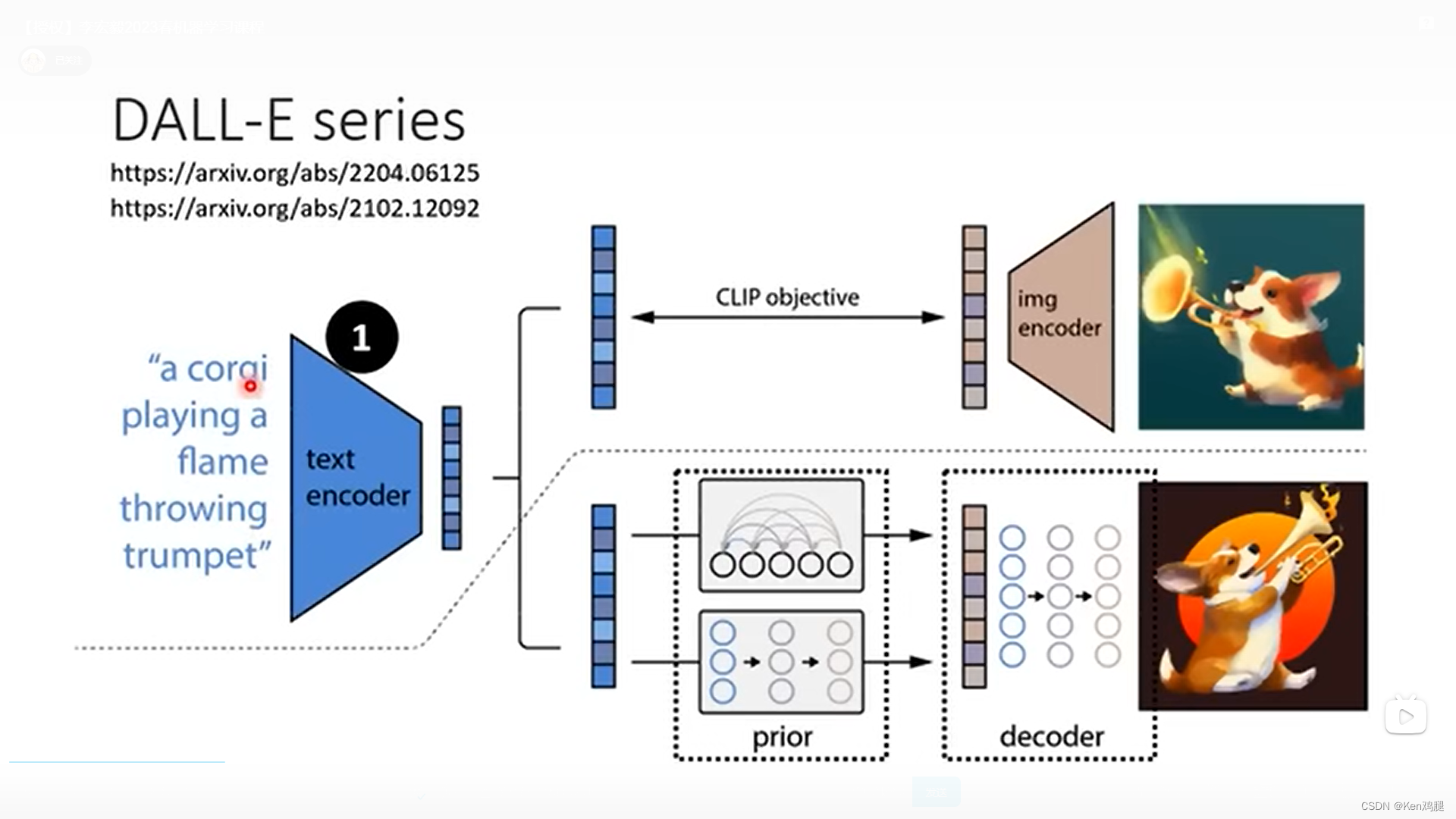
2.DALL-E系列也是输入文字,生成向量,可以有两种生成器的方法,再进行decoder生成中间产物
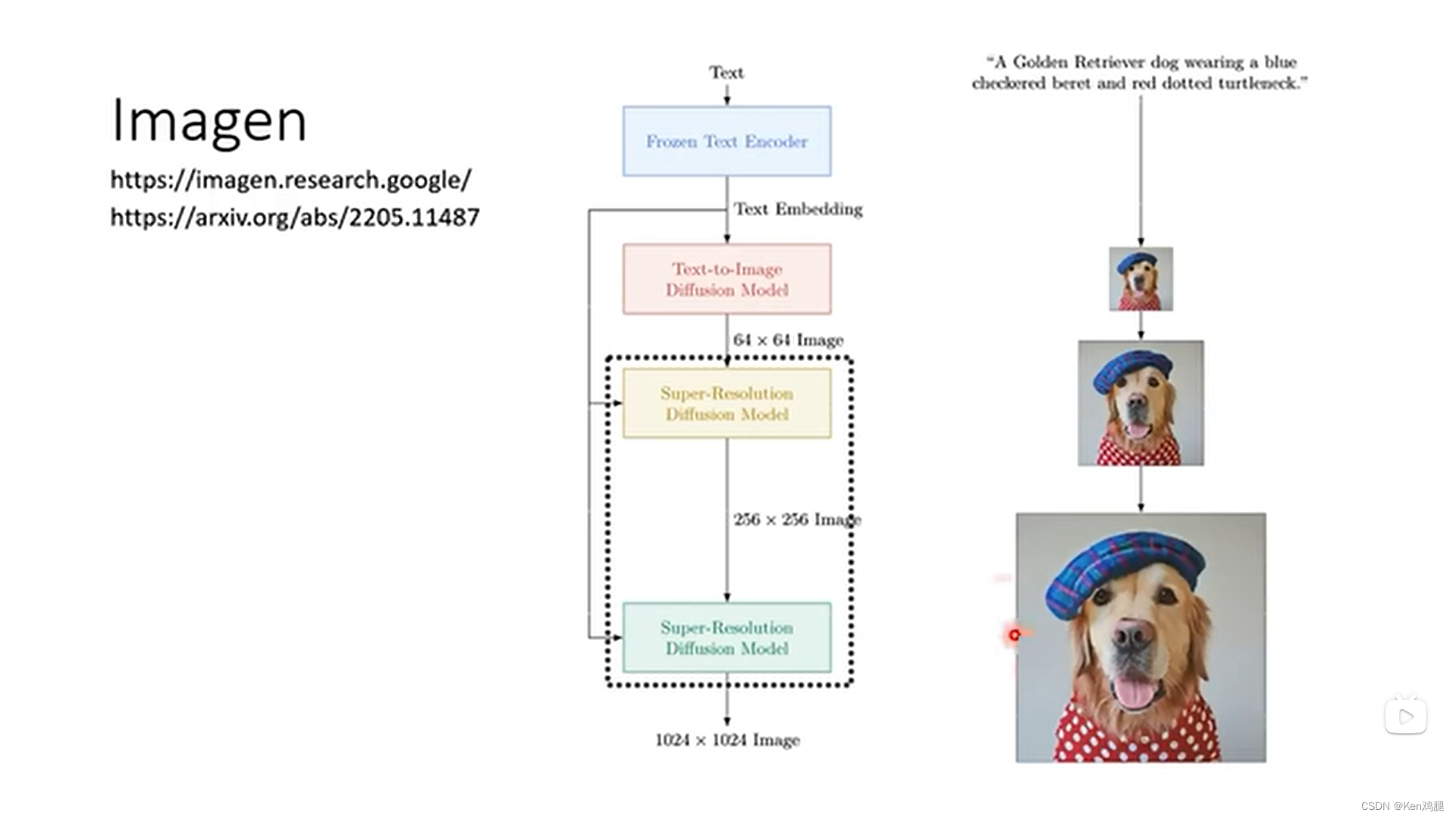
Google 的Imagen技术,

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)