双塔模型+自监督学习
双塔模型的问题:推荐系统头部效应严重:少部分物品占据大部分点击,大部分物品点击次数不高高点击物品表征学得好,长尾物品表征学的不好自监督学习:做data augmentation,更好的学习长尾物品的向量表征。自监督学习的目的是为了把物品塔学的更好。
·
双塔模型的问题:
- 推荐系统头部效应严重:少部分物品占据大部分点击,大部分物品点击次数不高
- 高点击物品表征学得好,长尾物品表征学的不好
- 自监督学习:做data augmentation,更好的学习长尾物品的向量表征。自监督学习的目的是为了把物品塔学的更好。
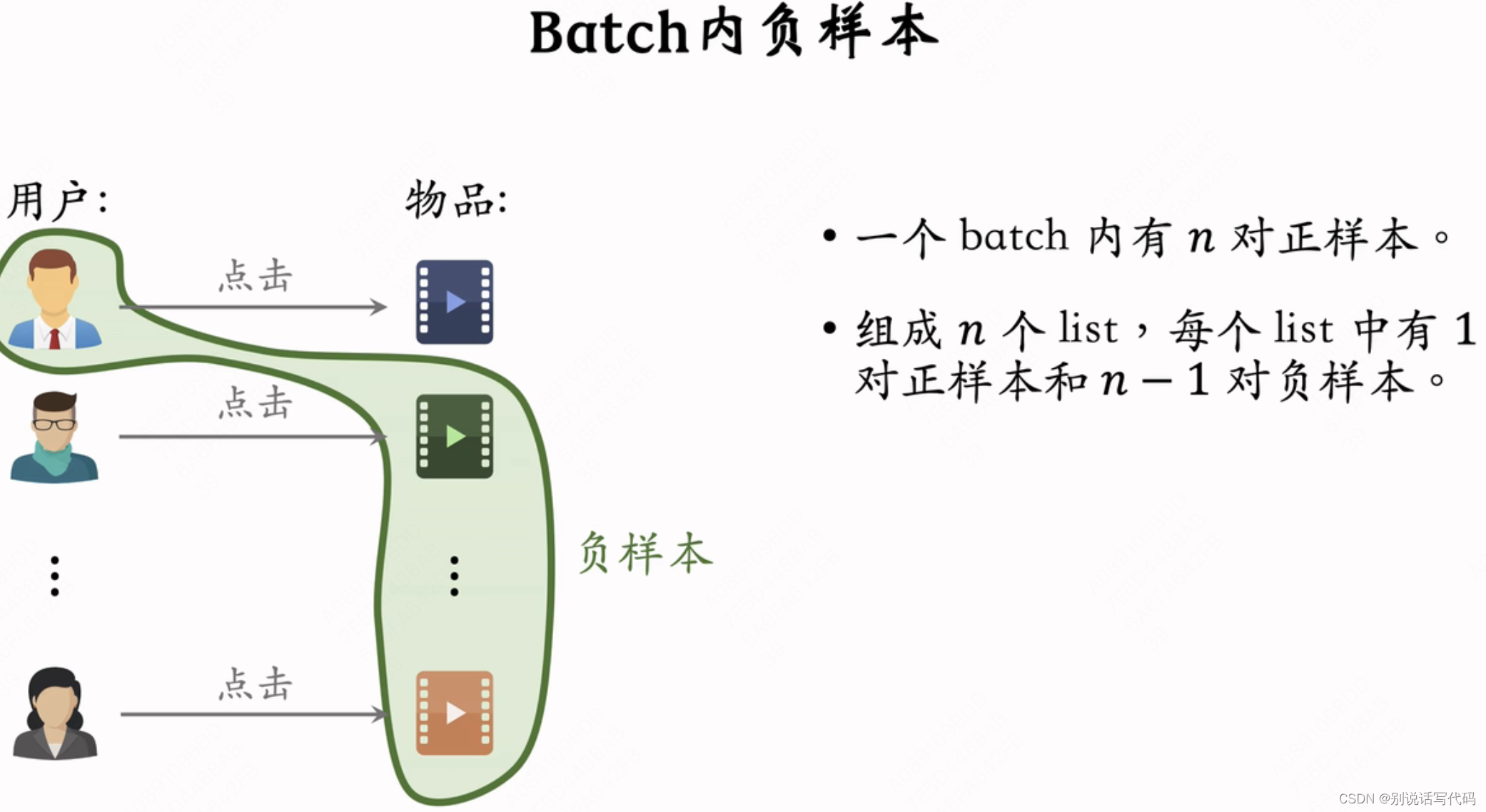
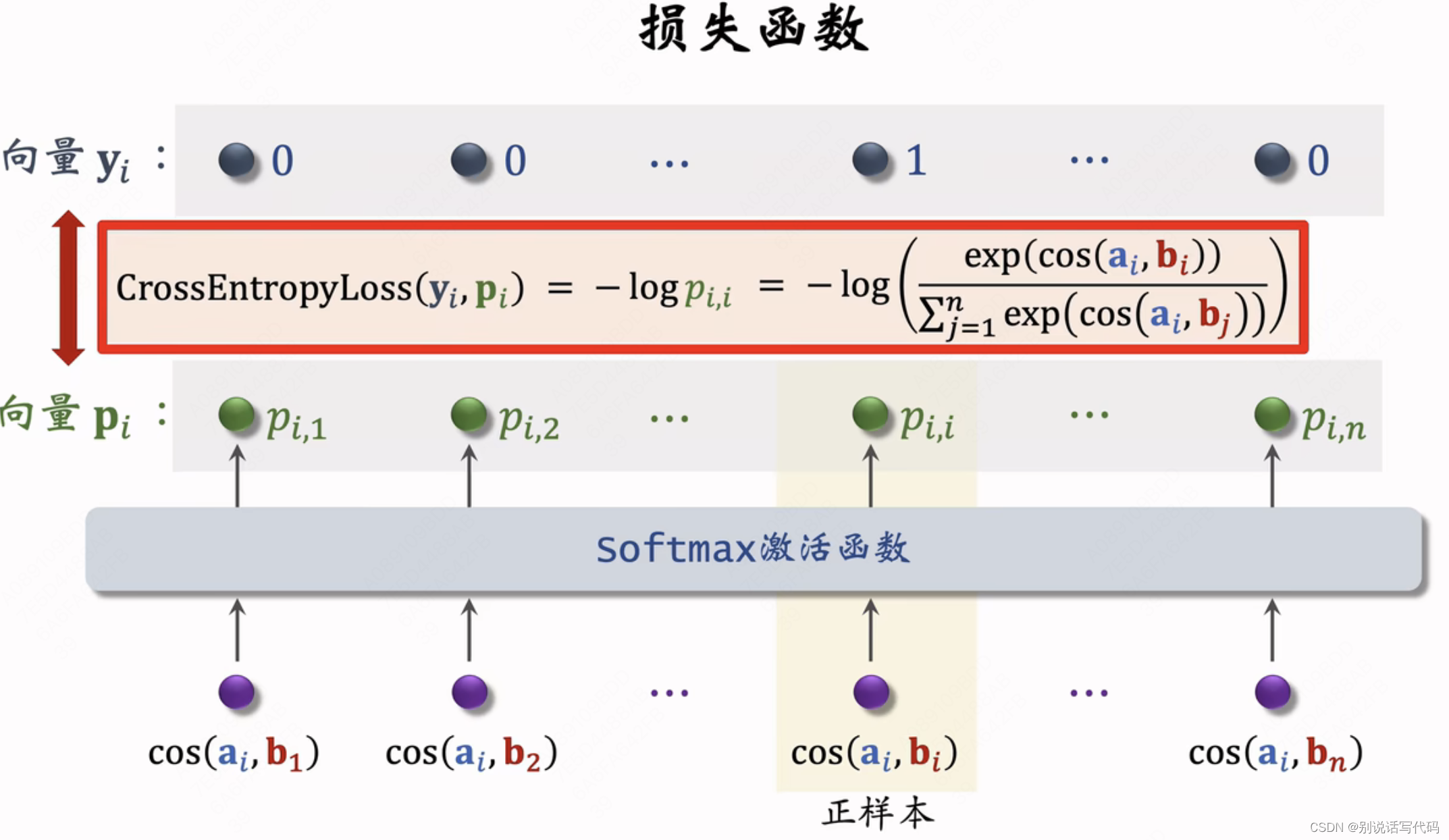
双塔模型用listwise训练,在batch内选取负样本,一个batch内有n对正样本,组成n个list,每个list有一个正样本和n-1对负样本。
- 一个batch有n对正样本(有点击):(a1,b1),(a2,b2),...,(an,bn)
- 负样本:对所有(ai,bj),i≠j
- 鼓励cos(ai,bi)尽量大,cos(ai,bj)尽量小
- 同时要做batch内负样本纠偏,负样本不至于被打压,训练时把cos(ai,bj)替换为cos(ai,bj)-logpj,其中pj表示物品j被抽样到的概率(正比于点击次数)

自监督学习
为了解决双塔模型学不好低曝光物品向量表征。对两个物品特征做随机变化得到两个特征,希望同一个物品的变换有较高相似度(尽管对同一物品进行了不同的特征变换),不同物品表征相似度较低。也就是鼓励cos(bi',bi'')尽量大,cos(bi',bj')尽量小
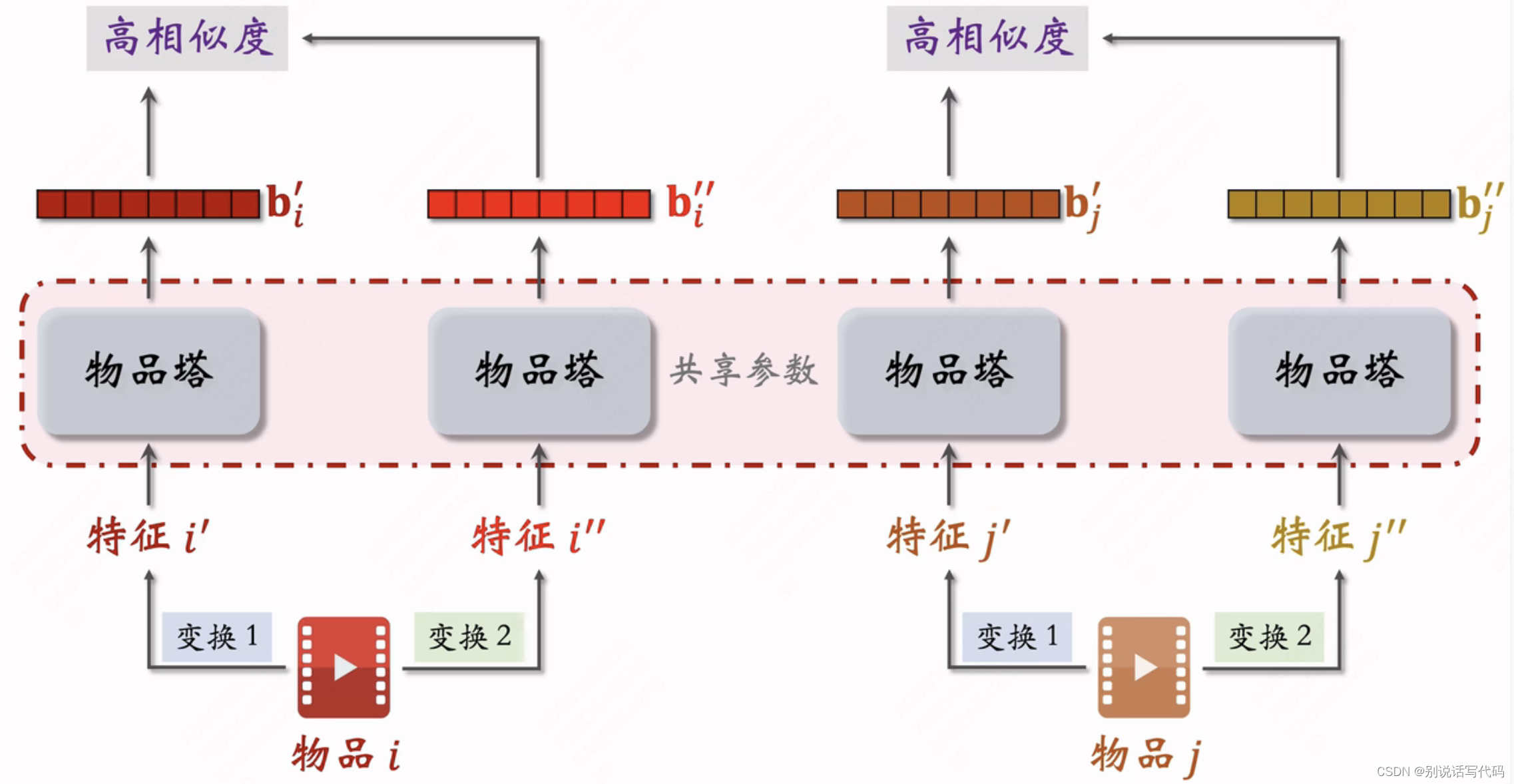
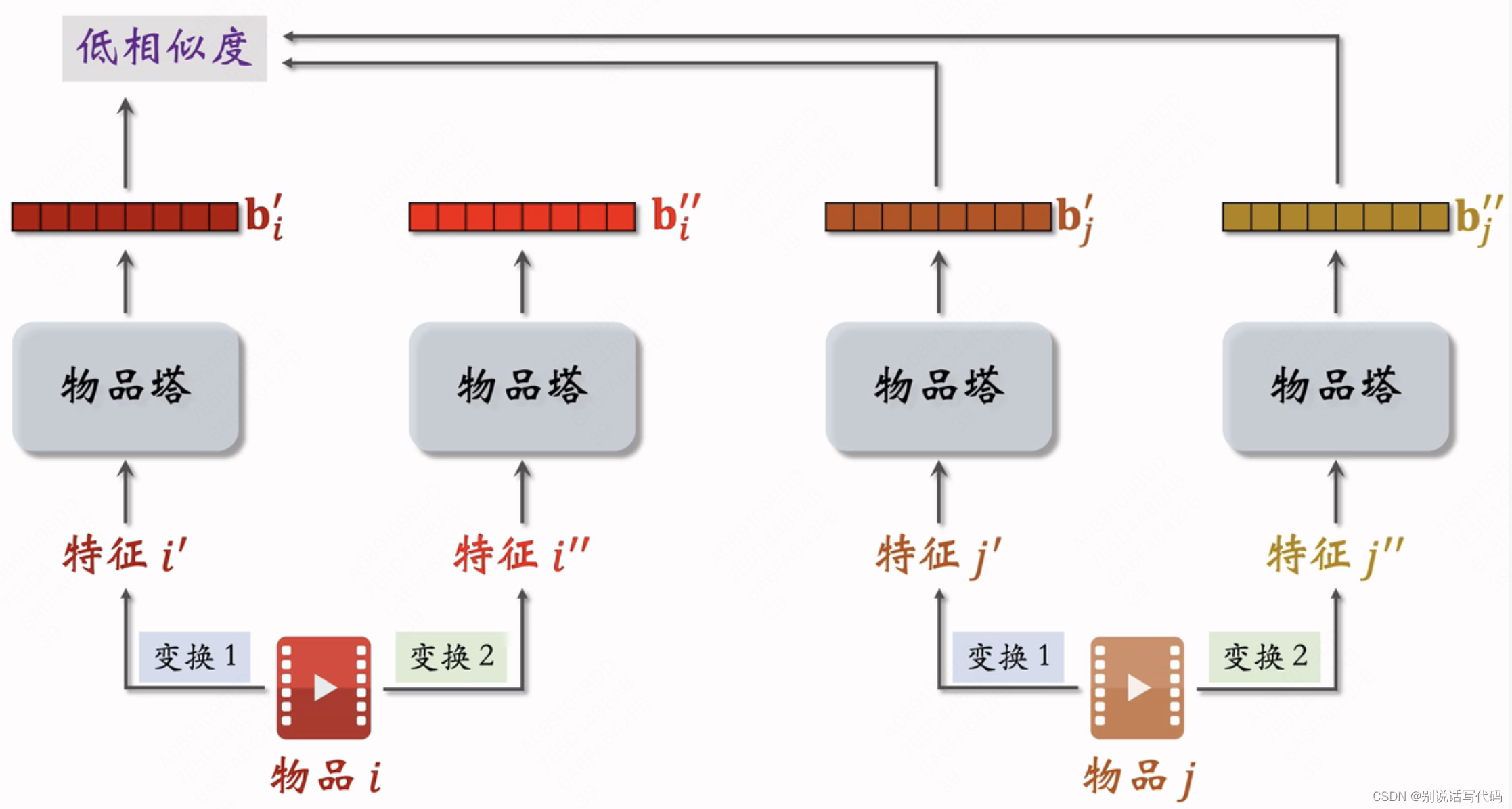
特征变换
- Random Mask:随机选一些离散特征(比如类目),把它遮住,比如物品类目特征原是{数码,摄影},mask后是{default}
- Dropout(仅对多值离散特征生效):一个物品有多个类目,那类目是一个多值离散特征,dropout就是随机丢弃50%的值,比如一个物品类目特征是{美妆,摄影},dropout后的类目特征是{美妆}
- 互补特征:假设一个 物品一共有4种特征(ID,类目,关键词,城市),随机分成两组{ID,关键词}和{类目,城市},就是{ID,default,关键词,default}和{default,类目,default,城市}
- Mask一组关联的特征
训练模型
- 从全体物品中均匀采样得到m个物品作为一个batch
-
Batch用来训练双塔,包括物品塔和用户塔, 根据点击抽样热门物品被抽样概率高,冷门被抽样概率低。每次从全体物品均匀抽样得到m个物品,热门和冷门物品被抽到概率相同,这个batch被用来做自监督学习只训练物品塔,最后做梯度下降,使损失减小。超参决定自监督学习起到的作用。

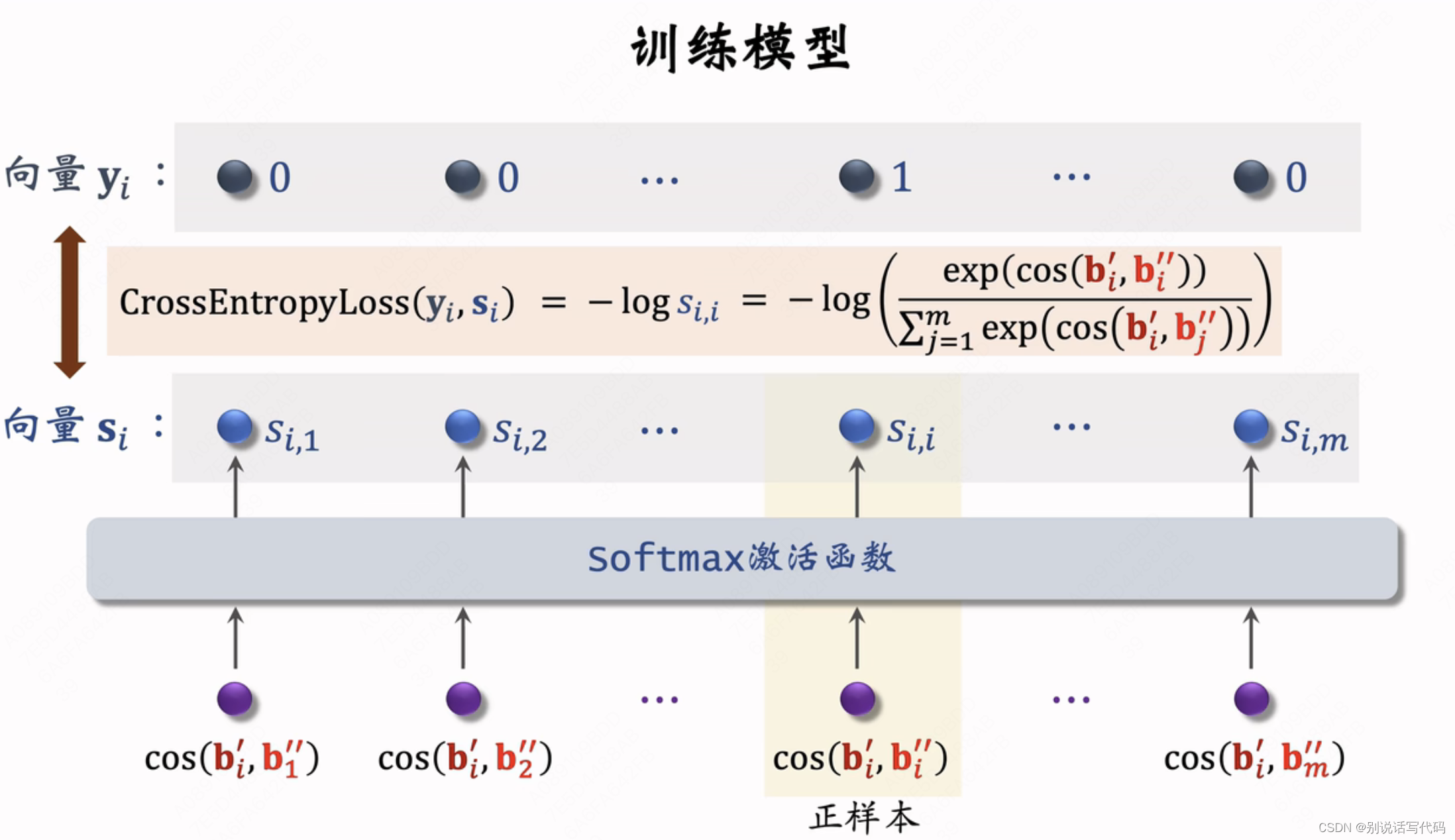


在业界效果还不错,低曝光、新物品推荐变的更准,大盘指标也有提升。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)