集成SwanLab与HuggingFace TRL:跟踪与优化强化学习实验
TRL是一个领先的Python库,旨在通过监督微调(SFT)、近端策略优化(PPO)和直接偏好优化(DPO)等先进技术,对基础模型进行训练后优化。TRL 建立在 🤗 Transformers 生态系统之上,支持多种模型架构和模态,并且能够在各种硬件配置上进行扩展。你可以使用Trl快速进行模型训练,同时使用SwanLab进行实验跟踪与可视化。是适配于Transformers的日志记录类。
·
TRL (Transformers Reinforcement Learning,用强化学习训练Transformers模型) 是一个领先的Python库,旨在通过监督微调(SFT)、近端策略优化(PPO)和直接偏好优化(DPO)等先进技术,对基础模型进行训练后优化。TRL 建立在 🤗 Transformers 生态系统之上,支持多种模型架构和模态,并且能够在各种硬件配置上进行扩展。

你可以使用Trl快速进行模型训练,同时使用SwanLab进行实验跟踪与可视化。
1. 引入SwanLabCallback
from swanlab.integration.transformers import SwanLabCallback
SwanLabCallback是适配于Transformers的日志记录类。
SwanLabCallback可以定义的参数有:
- project、experiment_name、description 等与 swanlab.init 效果一致的参数, 用于SwanLab项目的初始化。
- 你也可以在外部通过
swanlab.init创建项目,集成会将实验记录到你在外部创建的项目中。
2. 传入Trainer
from swanlab.integration.transformers import SwanLabCallback
from trl import SFTConfig, SFTTrainer
...
# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback(project="trl-visualization")
trainer = SFTTrainer(
...
# 传入callbacks参数
callbacks=[swanlab_callback],
)
trainer.train()
3. 完整案例代码
使用Qwen2.5-0.5B-Instruct模型,使用Capybara数据集进行SFT训练:
from trl import SFTConfig, SFTTrainer
from datasets import load_dataset
from swanlab.integration.transformers import SwanLabCallback
dataset = load_dataset("trl-lib/Capybara", split="train")
swanlab_callback = SwanLabCallback(
project="trl-visualization",
experiment_name="Qwen2.5-0.5B-SFT",
description="测试使用trl框架sft训练"
)
training_args = SFTConfig(
output_dir="Qwen/Qwen2.5-0.5B-SFT",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
num_train_epochs=1,
logging_steps=20,
learning_rate=2e-5,
)
trainer = SFTTrainer(
args=training_args,
model="Qwen/Qwen2.5-0.5B-Instruct",
train_dataset=dataset,
callbacks=[swanlab_callback]
)
trainer.train()
DPO、GRPO、PPO等同理,只需要将SwanLabCallback传入对应的Trainer即可。
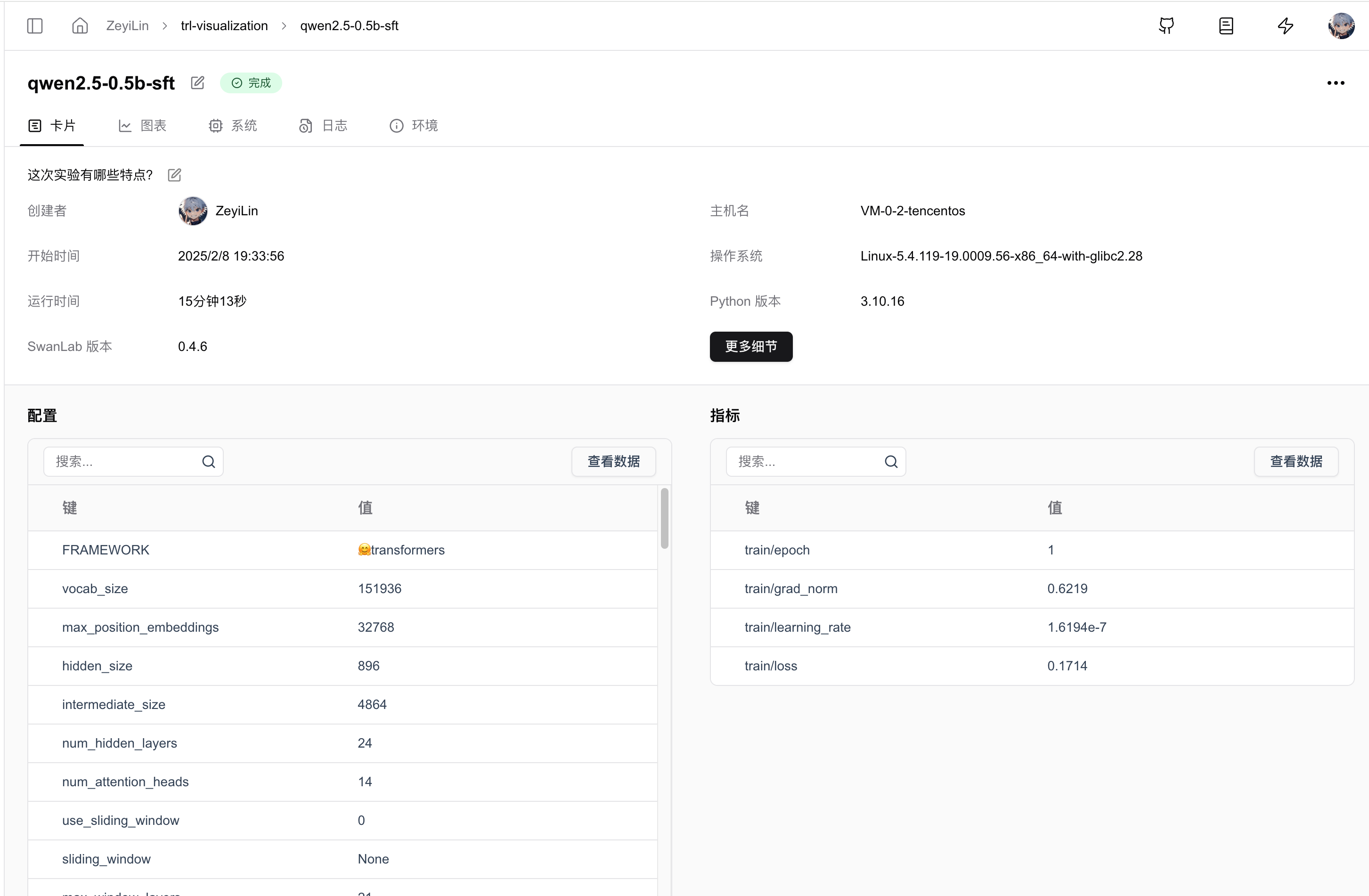
4. GUI效果展示
超参数自动记录:
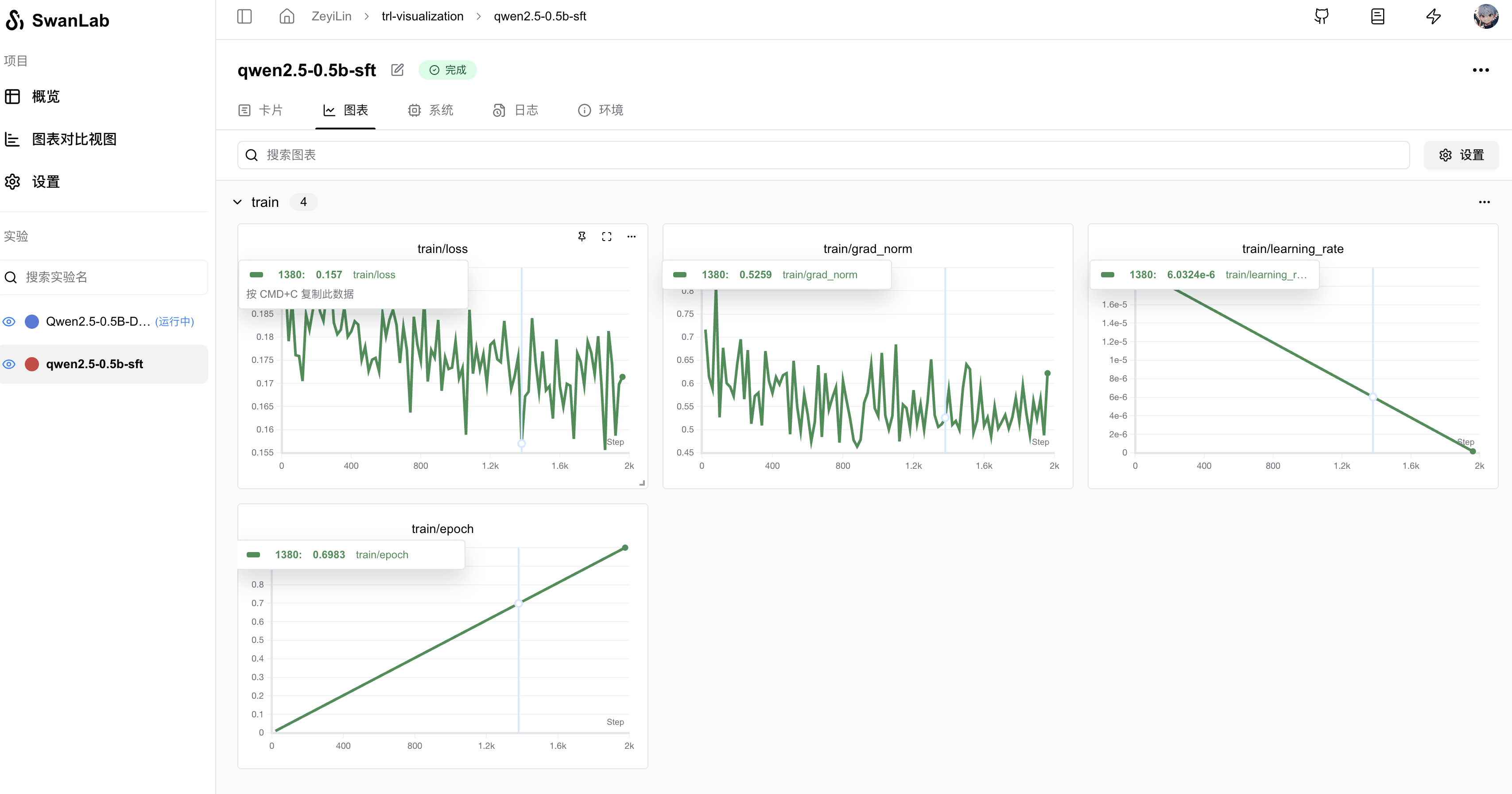
指标记录:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)