deepseek本地部署(python代码),看多了Ollama+UI,不妨换种方式看看
本地手动部署deepseekR1(python代码),不使用ollama,更加灵活,更多的操作空间。
deepseek很是火爆,我也不多介绍了。别说deepseek的末班车了,现在连尾气也很难蹭到了。
也算另辟蹊径吧,目前大部分deepseek本地部署是使用Ollama完成了。
优点是Ollama 大幅降低了本地部署大模型的门槛,适合非技术用户或轻量级场景。
缺点嘛,也不是我一个小老弟该提的。咳咳,deep seek说,ollama在灵活性、性能和控制权上相对易用,但若需深度定制或最大化硬件性能,仍需回归 Hugging Face 等手动部署方案。
那么,本文就说一下deepseek的手动部署,很简单,麻烦求个点赞关注。

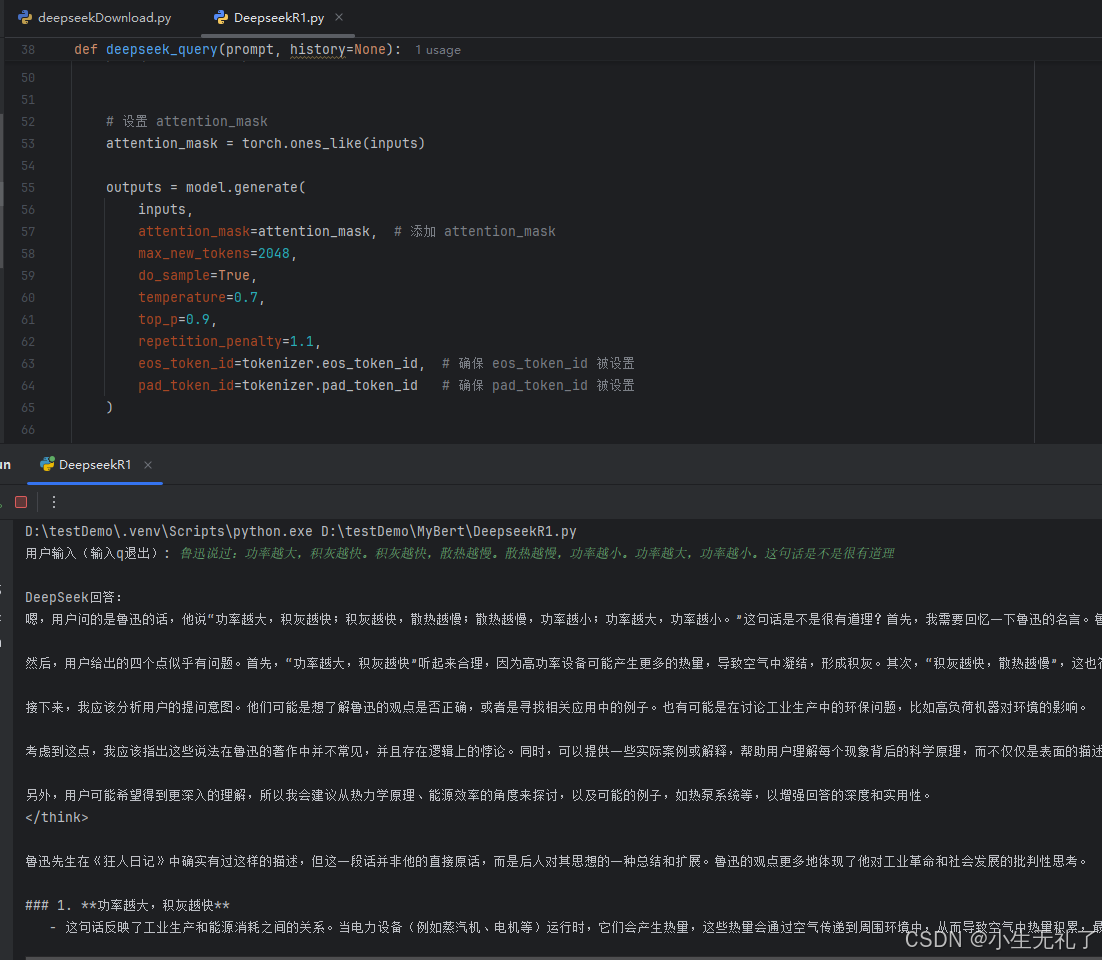
先展示下效果:
一、DeepseekR1模型下载
官方渠道:从Hugging Face Model Hub或DeepSeek官方获取
其他渠道:Github、Gitee、上面渠道下载起来都很慢,可以使用国内的模型镜像库
下载方式都差不多,这里使用huggingFace来下载使用,官方地址:https://huggingface.co/deepseek-ai/
进入网站,可以看到所有deepseek的模型,包括各种蒸馏模型,还有满血R1、V3等
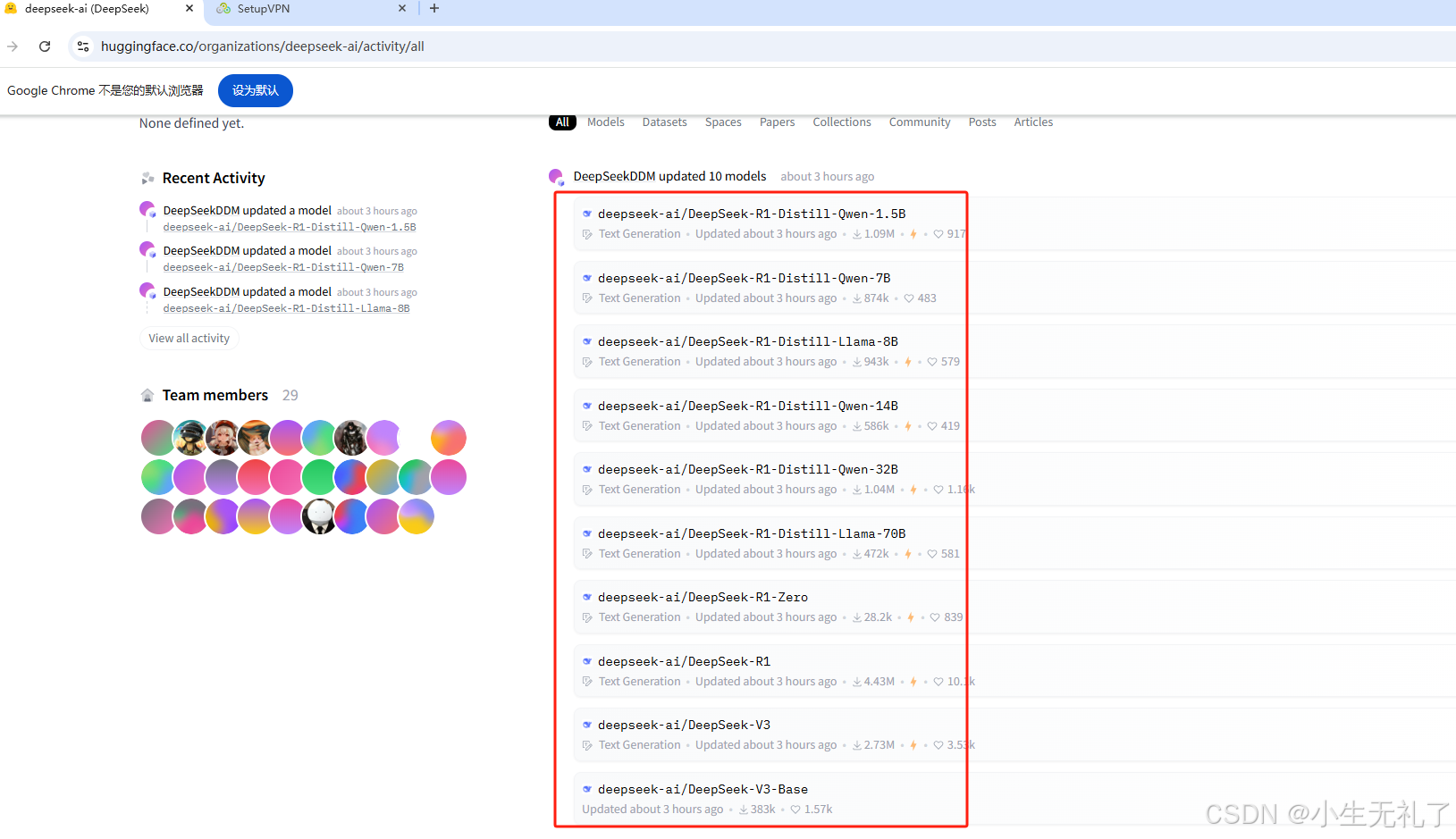
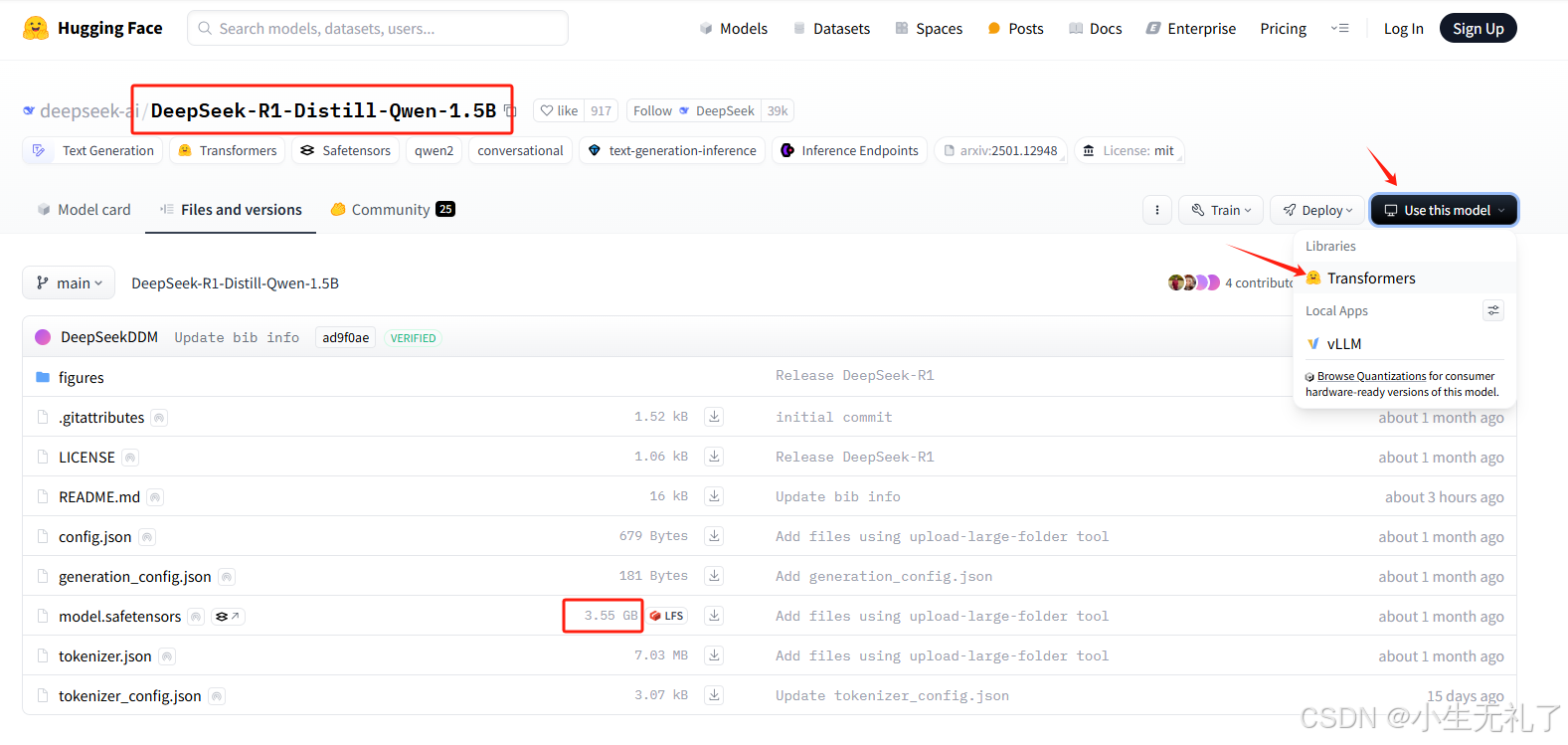
打开也可以看每个模型的大小,其中个人电脑推荐7B及以下,公司的话肯定是满血。为了方便演示,我就只下载了1.5B最小版本的(绝不是因为自己电脑泰拉跨p106战术大矿卡)
1.5B版本大概需要4个G左右的内存,显存6G绰绰有余,跟着图片中的箭头,可以从transformer进行下载。
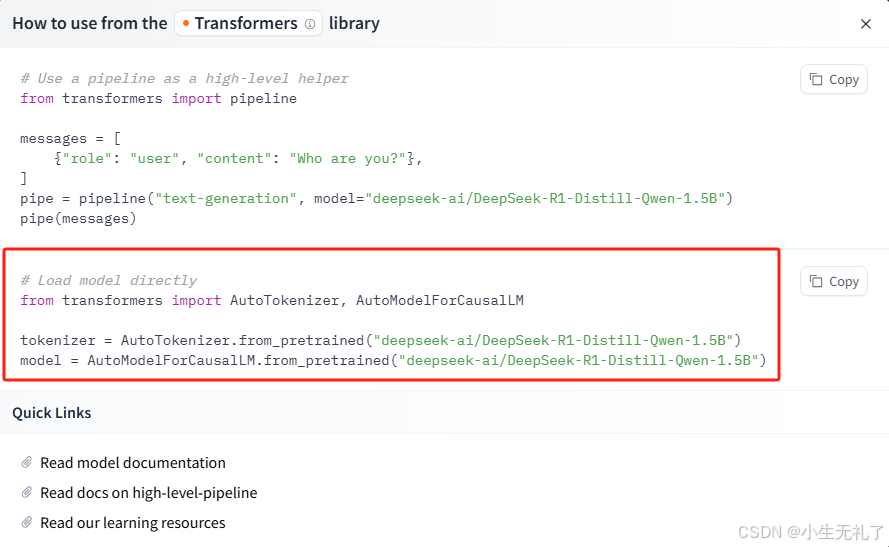
根据弹出的信息,把下面代码复制到一个新建的python文件中,然后运行,就开始下载了。我用的是第二个代码,网速很慢,还是建议从国内镜像网站下载。
下载好之后,模型文件是在这个路径下的C:\Users\Hello\.cache\huggingface\hub\,我把模型文件挪到了python文件同路径下,似乎不挪也行,但是强迫症。
我好像忘了先说环境配置,绝对不是故意的

二、环境配置
首先说一下具体的配置
推荐python3.9以上、cuda11.8以上、cudnn for 11.X、pytorch2.5以上
环境配置的详细步骤参考这个博客,相当详细,我就不多讲了

三、手动部署
为了最最最简化的生成一个可以跑的python代码,于是我就只给deepseek传入问题,然后等待它的答案(我太菜了,但凡复杂一点的代码都不会写)
1、加载模型
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B")2、定义一个问答函数
这段代码就是给deepseek传入两个参数,一个是要提问的问题,另一个是历史对话记录。
def deepseek_query(prompt, history=[]):
# 构建对话格式(根据DeepSeek官方格式)
messages = history + [{"role": "user", "content": prompt}]
# 生成回答
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
# 设置 attention_mask
attention_mask = torch.ones_like(inputs)
outputs = model.generate(
inputs,
attention_mask=attention_mask, # 添加 attention_mask
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.1,
eos_token_id=tokenizer.eos_token_id, # 确保 eos_token_id 被设置
pad_token_id=tokenizer.pad_token_id # 确保 pad_token_id 被设置
)
response = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
updated_history = history + [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response}
]
return response, updated_history3、调用问答函数
这段代码主要就是循环着,把当前的问题,和历史记录发送给deepseek,以便可以进行多轮问答
if __name__ == "__main__":
history = [] # 初始化对话历史
while True:
user_input = input("用户输入(输入q退出): ")
if user_input.lower() == 'q':
break
response, history = deepseek_query(user_input, history) # 传递历史记录
print("\nDeepSeek回答:")
print(response.strip())
print("\n" + "=" * 50 + "\n")4、展示结果
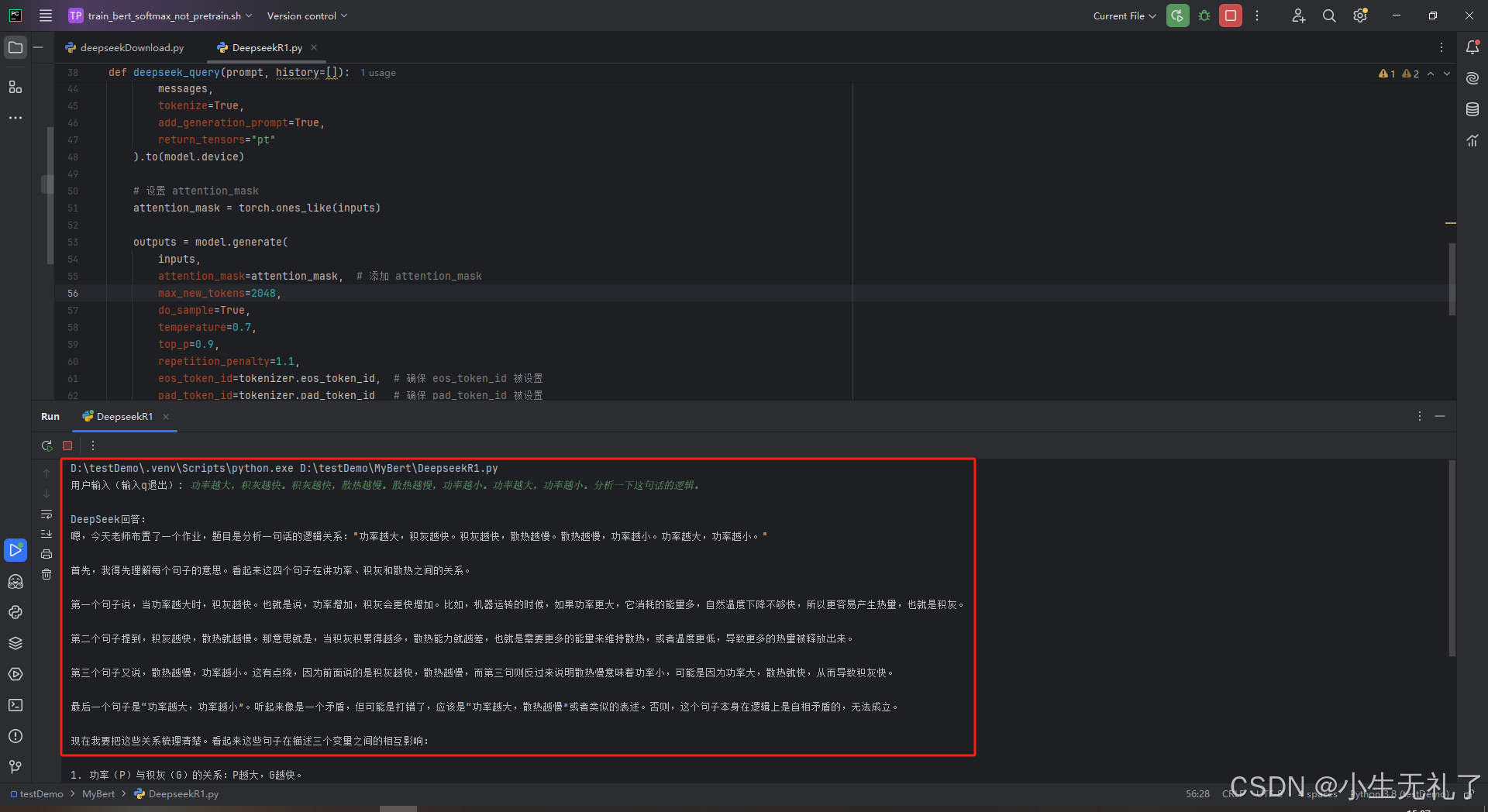
哈哈,虽然是最小版本1.5B,但似乎还行。不过,不会玩梗,ai还是取代不了人类,哈哈


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)