强化学习的几个主要方法(策略梯度、PPO、REINFORCE实现等)---上
策略梯度算法在理想情况下,在采样次数足够多的情况下效果是能很不错的,但是当采样不够时就会出现一些问题,例如GtG_tGt的取值是很不稳定的,下图可以形象说明:由于GtG_tGt的取值不稳定,所以(st,at)(s_t, a_t)(st,at)更新也不稳定。由于GGG的值有点太不稳定太玄学了,因此我们可以想办法去用一个神经网络去预测在sss状态下采取行动aaa时对应的GGG期望值,之后再训练
1. 基本概念
1.1 基本流程
强化学习是一种学习框架,其中智能体(Agent) 通过与 环境(Environment) 的交互,在每一步从环境中接收状态(State)和奖励(Reward),并通过选择行动(Action)来学习最优策略(Policy),以最大化其累计奖励。
换句话说,强化学习是让智能体找到一种行为策略,使得它在长期内获得的奖励总和(通常是期望值)最大化。
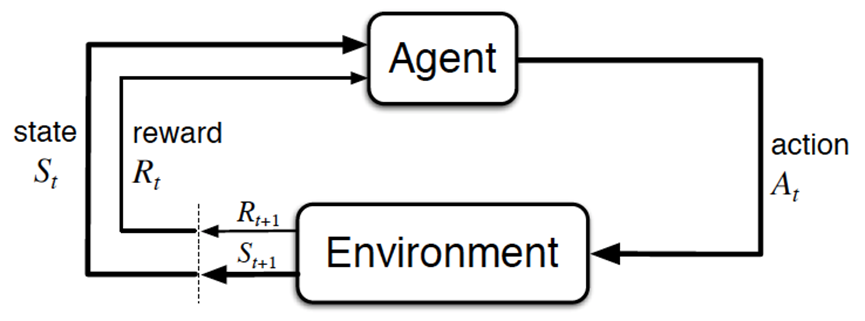
图中的每个元素代表以下含义:
- Agent(智能体):这是我们的学习者,它会根据当前的状态(State)做出一个动作(Action)。
- Environment(环境):这是智能体所处的外部世界,它会根据智能体的动作,给出相应的反馈:
- Reward(奖励):智能体执行动作后,环境会给出一个数值表示的奖励。正奖励表示动作的好坏,负奖励表示动作的坏处。
- Next State(下一个状态):执行动作后,环境的状态会发生变化,进入下一个状态。
- State(状态):环境在某个时刻的具体情况,比如游戏中的分数、机器人的位置等。
- Action(动作):智能体可以采取的各种行为,比如向左走、开火等。
1.2 马尔可夫过程
**马尔科夫性质:**一个随机过程的下一个状态只取决于当前状态,而与过去的状态无关。即:
p(Xt+1=xt+1∣X0:t=x0:t)=p(Xt+1=xt+1∣Xt=xt)p(X_{t + 1}=x_{t + 1}|X_{0:t}=x_{0:t}) = p(X_{t + 1}=x_{t + 1}|X_{t}=x_{t}) p(Xt+1=xt+1∣X0:t=x0:t)=p(Xt+1=xt+1∣Xt=xt)
马尔可夫性质也可以描述为给定当前状态时,将来的状态与过去状态是条件独立的。如果某一个过程满足马尔可夫性质,那么未来的转移与过去的是独立的,它只取决于现在。马尔可夫性质是所有马尔可夫过程的基础。
也就是说,满足以下关系,其中ht={s1,s2,s3,…,st}h_t = \{ s_1, s_2, s_3, \ldots, s_t \}ht={s1,s2,s3,…,st},hth_tht包含了之前所有状态
p(st+1∣st)=p(st+1∣ht)p(s_{t + 1} | s_{t}) = p(s_{t + 1} | h_{t}) p(st+1∣st)=p(st+1∣ht)
从当前 sts_tst转移到st+1s_{t+1}st+1,它是直接就等于它之前所有的状态转移到 st+1s_{t+1}st+1。
**马尔可夫链:**离散时间的马尔可夫过程。其状态是有限的,例如:
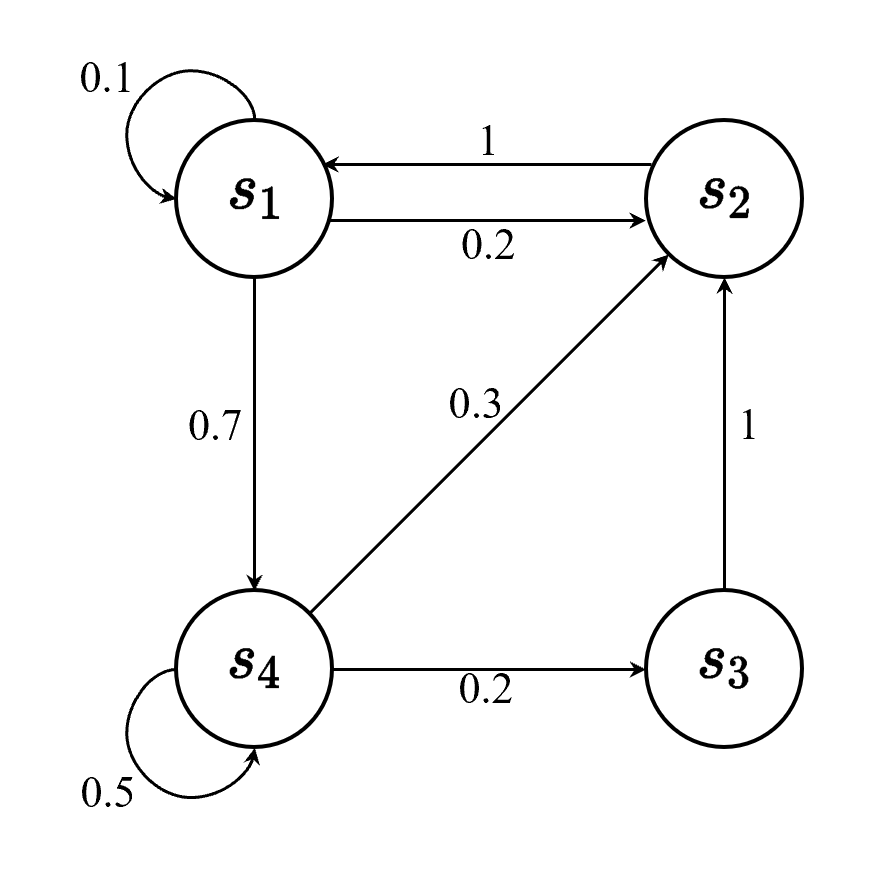
可以用状态转移矩阵来描述状态转移过程
P=[p(s1∣s1)p(s2∣s1)⋯p(sN∣s1)p(s1∣s2)p(s2∣s2)⋯p(sN∣s2)⋮⋮⋱⋮p(s1∣sN)p(s2∣sN)⋯p(sN∣sN)]P = \begin{bmatrix} p(s_1|s_1) & p(s_2|s_1) & \cdots & p(s_N|s_1) \\ p(s_1|s_2) & p(s_2|s_2) & \cdots & p(s_N|s_2) \\ \vdots & \vdots & \ddots & \vdots \\ p(s_1|s_N) & p(s_2|s_N) & \cdots & p(s_N|s_N) \end{bmatrix} P= p(s1∣s1)p(s1∣s2)⋮p(s1∣sN)p(s2∣s1)p(s2∣s2)⋮p(s2∣sN)⋯⋯⋱⋯p(sN∣s1)p(sN∣s2)⋮p(sN∣sN)
状态转移矩阵类似于条件概率(conditional probability),它表示当我们知道当前我们在状态 sts_tst 时,到达下面所有状态的概率。所以它的每一行描述的是从一个节点到达所有其他节点的概率。
1.3 马尔可夫奖励过程
马尔可夫链加上奖励函数。在马尔可夫奖励过程中,状态转移矩阵和状态都与马尔可夫链一样,只是多了奖励函数(reward function)。在强化学习中我们不知要关注过程,还要关注在过程中每一步所能获得到的奖励。
这里我们进一步定义一些概念。范围(horizon) 是指一个回合的长度(每个回合最大的时间步数),它是由有限个步数决定的。 **回报(return)**可以定义为奖励的逐步叠加,假设时刻ttt后的奖励序列为rt+1,rt+2,rt+3,⋯r_{t+1},r_{t+2},r_{t+3},⋯rt+1,rt+2,rt+3,⋯,则回报为
回报(return)GtG_tGt可以表示为从时刻t开始直到回合结束获得的所有奖励的折扣总和:
Gt=rt+1+γrt+2+γ2rt+3+...+γT−t−1rTG_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + ... + \gamma^{T-t-1} r_T Gt=rt+1+γrt+2+γ2rt+3+...+γT−t−1rT
其中,γ∈[0, 1]为折扣因子。随着时间的推移,未来的奖励会打折扣,表示我们更看重当前的奖励。
当我们有了回报的概念后,就可以定义状态价值函数(state-value function)V(s)。状态价值函数表示从状态s出发,按照当前策略一直执行下去,直到回合结束,所能获得的期望回报:
Vπ(s)=E[Gt∣St=s]=E[rt+1+γrt+2+γ2rt+3+⋯+γT−t−1rT∣St=s]=E[rt+1∣St=s]+γE[Gt+1∣St=s]=E[rt+1∣St=s]+γE[Vπ(St+1)∣St=s]\begin{align} V^{\pi}(s) &= \mathbb{E}[G_t \mid S_t = s] \\ &= \mathbb{E}[r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \cdots + \gamma^{T-t-1}r_T \mid S_t = s] \\ &= \mathbb{E}[r_{t+1} \mid S_t = s] + \gamma \mathbb{E}[G_{t+1} \mid S_t = s] \\ &= \mathbb{E}[r_{t+1} \mid S_t = s] + \gamma \mathbb{E}[V^{\pi}(S_{t+1}) \mid S_t = s] \end{align} Vπ(s)=E[Gt∣St=s]=E[rt+1+γrt+2+γ2rt+3+⋯+γT−t−1rT∣St=s]=E[rt+1∣St=s]+γE[Gt+1∣St=s]=E[rt+1∣St=s]+γE[Vπ(St+1)∣St=s]
其中,GtG_tGt是之前定义的折扣回报(discounted return)。R(s)R(s)R(s)是奖励函数,我们对GtG_tGt取了一个期望,期望就是从这个状态开始,我们可能获得多大的价值。所以期望也可以看成未来可能获得奖励的当前价值的表现,就是当我们进入某一个状态后,我们现在有多大的价值。
这些话说的有点拗口,通俗来说就是GGG表示当下即时奖励和所有持久奖励等一切奖励的加权和,它是相对与一个序列中的一个状态节点来评估的,而价值函数V(s)V(s)V(s)是对某一个状态来评估而,把这个状态从序列中抽象出来了。
贝尔曼方程
V(s)=R(s)+γ∑s′∈SP(s′∣s)V(s′)V(s) = R(s) + \gamma \sum_{s' \in S} P(s'|s) V(s') V(s)=R(s)+γs′∈S∑P(s′∣s)V(s′)
一种快速求V(s)V(s)V(s)的方法。
1.4 马尔可夫决策过程
马尔可夫决策过程(MDP) = 马尔可夫奖励(MRP) + 智能体动作因素
MDP 的目标是找到一个最优策略 π,使得智能体在给定状态下选择最优的动作,从而最大化长期累积的折扣奖励。
状态价值函数:
Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=Eπ[Rt+1+γVπ(St+1)∣St=s]\begin{align} V_{\pi}(s) &= \mathbb{E}_{\pi}[G_t | S_t = s] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1} | S_t = s] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma V_{\pi}(S_{t+1}) | S_t = s] \end{align} Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=Eπ[Rt+1+γVπ(St+1)∣St=s]
动作价值状态函数:
Qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+1+γGt+1∣St=s,At=a]=Eπ[Rt+1+γQπ(St+1,At+1)∣St=s,At=a]\begin{align} Q_{\pi}(s, a) &= \mathbb{E}_{\pi}[G_t | S_t = s, A_t = a] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1} | S_t = s, A_t = a] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma Q_{\pi}(S_{t+1}, A_{t+1}) | S_t = s, A_t = a] \end{align} Qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+1+γGt+1∣St=s,At=a]=Eπ[Rt+1+γQπ(St+1,At+1)∣St=s,At=a]
AtA_tAt表示t时刻的动作,QQQ函数相对上面的VVV函数来说多考虑进去了一个动作的因素,而不只是单纯的状态。
马尔可夫决策的贝尔曼方程
Vπ(s)=∑a∈Aπ(a∣s)[R(s,a)+γ∑s′∈SP(s′∣s,a)Vπ(s′)]V_{\pi}(s) = \sum_{a \in A} \pi(a|s) \left[ R(s, a) + \gamma \sum_{s' \in S} P(s'|s, a) V_{\pi}(s') \right] Vπ(s)=a∈A∑π(a∣s)[R(s,a)+γs′∈S∑P(s′∣s,a)Vπ(s′)]
Qπ(s,a)=R(s,a)+γ∑s′∈SP(s′∣s,a)[∑a′∈Aπ(a′∣s′)Qπ(s′,a′)]Q_{\pi}(s, a) = R(s, a) + \gamma \sum_{s' \in S} P(s'|s, a) \left[ \sum_{a' \in A} \pi(a'|s') Q_{\pi}(s', a') \right] Qπ(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)[a′∈A∑π(a′∣s′)Qπ(s′,a′)]
2. REINFORCE
2.1 策略梯度算法
由于REINFORCE是最简单的侧率梯度算法,所以这里先介绍策略梯度算法
强化学习有 3 个组成部分:演员(actor)、环境和奖励函数。显然我们能控制的只有演员,环境和奖励函数是客观存在的。智能体玩视频游戏时,演员负责操控游戏的摇杆, 比如向左、向右、开火等操作;环境就是游戏的主机,负责控制游戏的画面、负责控制怪兽的移动等;奖励函数就是当我们做什么事情、发生什么状况的时候,可以得到多少分数, 比如打败一只怪兽得到 20 分等。在强化学习里,环境与奖励函数不是我们可以控制的,它们是在开始学习之前给定的。我们唯一需要做的就是调整演员里面的策略,使得演员可以得到最大的奖励。演员里面的策略决定了演员的动作,即给定一个输入,它会输出演员现在应该要执行的动作。
在下面的例子中,我们会用一个神经网络来当做演员,把环境输入,由神经网络给出动作。例如玩一个走格子的游戏,游戏规则如下,创建一个n×nn \times nn×n的棋盘,旗子在(0,0)(0, 0)(0,0)处,要到达(n,n)(n, n)(n,n)处,并用最少的步数走到。(也可以为了增加难度在中间设置一点障碍)棋子有四种动作,分别是“上、下、左、右”。
有四个动作,所以神经网络有四个输出,根据四个输出的概率进行采样选择下一步的动作。
智能体的每一步动作都会有一个奖励,为了让他能尽快走到终点,因此它每走到一个格子,除非那个格子是终点,我们就把那个格子的奖励设置为-1,终点的奖励可以设置为10,中间也可以设置障碍,例如将某个点的奖励设置为-100,这样就让模型学会避开这个点。
我们的游戏过程应该是这样的:
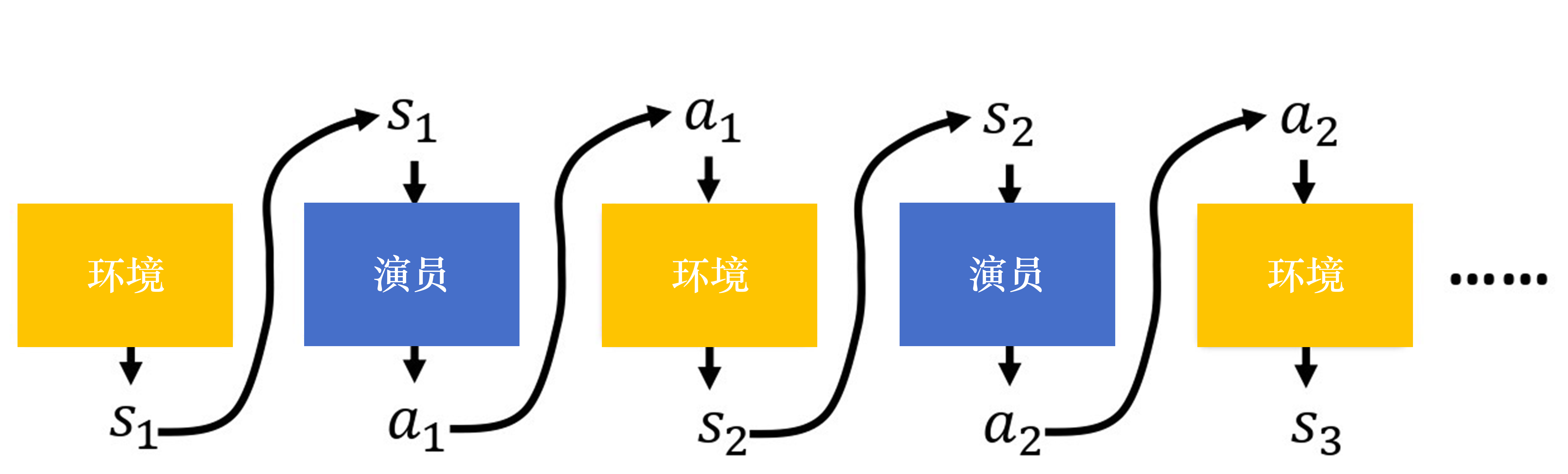
在一场游戏里面,我们把环境输出的sss与演员输出的动作 aaa 全部组合起来,就是一个轨迹
τ={s1,a1,s2,a2,…,st,at}\tau = \{s_1, a_1, s_2, a_2, \dots, s_t, a_t\} τ={s1,a1,s2,a2,…,st,at}
给定演员的参数 θθθ(就是提到的神经网络的参数),我们可以计算某个轨迹τ\tauτ发生的概率为
pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣s1,a1)pθ(a2∣s2)p(s3∣s2,a2)⋯=p(s1)∏t=1Tpθ(at∣st)p(st+1∣st,at)\begin{align} p_{\theta}(\tau) &= p(s_1) p_{\theta}(a_1|s_1) p(s_2|s_1, a_1) p_{\theta}(a_2|s_2) p(s_3|s_2, a_2) \cdots \\ &= p(s_1) \prod_{t=1}^{T} p_{\theta}(a_t|s_t) p(s_{t+1}|s_t, a_t) \end{align} pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣s1,a1)pθ(a2∣s2)p(s3∣s2,a2)⋯=p(s1)t=1∏Tpθ(at∣st)p(st+1∣st,at)
这个计算是一步一步的,并不是并行的。其中p(st+1∣st,at)p(s_{t+1} \mid s_t, a_t)p(st+1∣st,at)意思是在环境为sts_tst, 演员采取动作ata_tat的情况下环境变成st+1s_{t+1}st+1的概率。
那既然每一把游戏都是一个轨迹τ\tauτ,每一把游戏都会有一个得分,这个得分按照我之前设定的规则应该是每个动作的回报GtG_tGt然后求和,由于整局游戏我已经玩完了,所以之后的动作是什么奖励是什么我也知道,因此我们能算出这个GtG_tGt。
Gt=rt+1+γrt+2+γ2rt+3+...+γT−t−1rTG_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + ... + \gamma^{T-t-1} r_T Gt=rt+1+γrt+2+γ2rt+3+...+γT−t−1rT
我们把这局游戏每一步走完之后的GtG_tGt都存下来,如果这个GtG_tGt大于零,就说明这个动作有好处,可以增大采样采到这个动作的概率,注意,增加的是pθ(at∣st)p_{\theta}(a_t|s_t)pθ(at∣st)的概率,而不是pθ(at)p_{\theta}(a_t)pθ(at)的值,需要联系环境来考虑问题。就跟人斗地主一样,你是农民,你的队友手里只剩下两张王了,这个时候最好的决策就是将自己手里的炸弹打出来增加奖励。你出炸弹的概率就几乎是百分之百,p(出炸弹∣队友手里只剩下两张王了)=0.99p(出炸弹 \mid 队友手里只剩下两张王了) = 0.99p(出炸弹∣队友手里只剩下两张王了)=0.99,而在别的情况下你出炸弹的概率就没必要这么高,毕竟很少有人开局就出炸弹。所以模型要提高的是p(出炸弹∣队友手里只剩下两张王了)p(出炸弹 \mid 队友手里只剩下两张王了)p(出炸弹∣队友手里只剩下两张王了)的值,而不是p(出炸弹)p(出炸弹)p(出炸弹)。这个GtG_tGt暂时不会用到,后面会用到。
在强化学习里面,除了环境与演员以外,还有奖励函数。如下图所示,奖励函数根据在某一个状态采取的某一个动作决定这个动作可以得到的分数。对奖励函数输入s1,a1s_1, a_1s1,a1,它会输出r1r_1r1,输入 s2,a2s_2, a_2s2,a2,它会输出r2r_2r2。 我们把轨迹所有的奖励 rrr都加起来,就得到了R(τ)R(\tau)R(τ),其代表某一个轨迹 τ\tauτ的奖励。
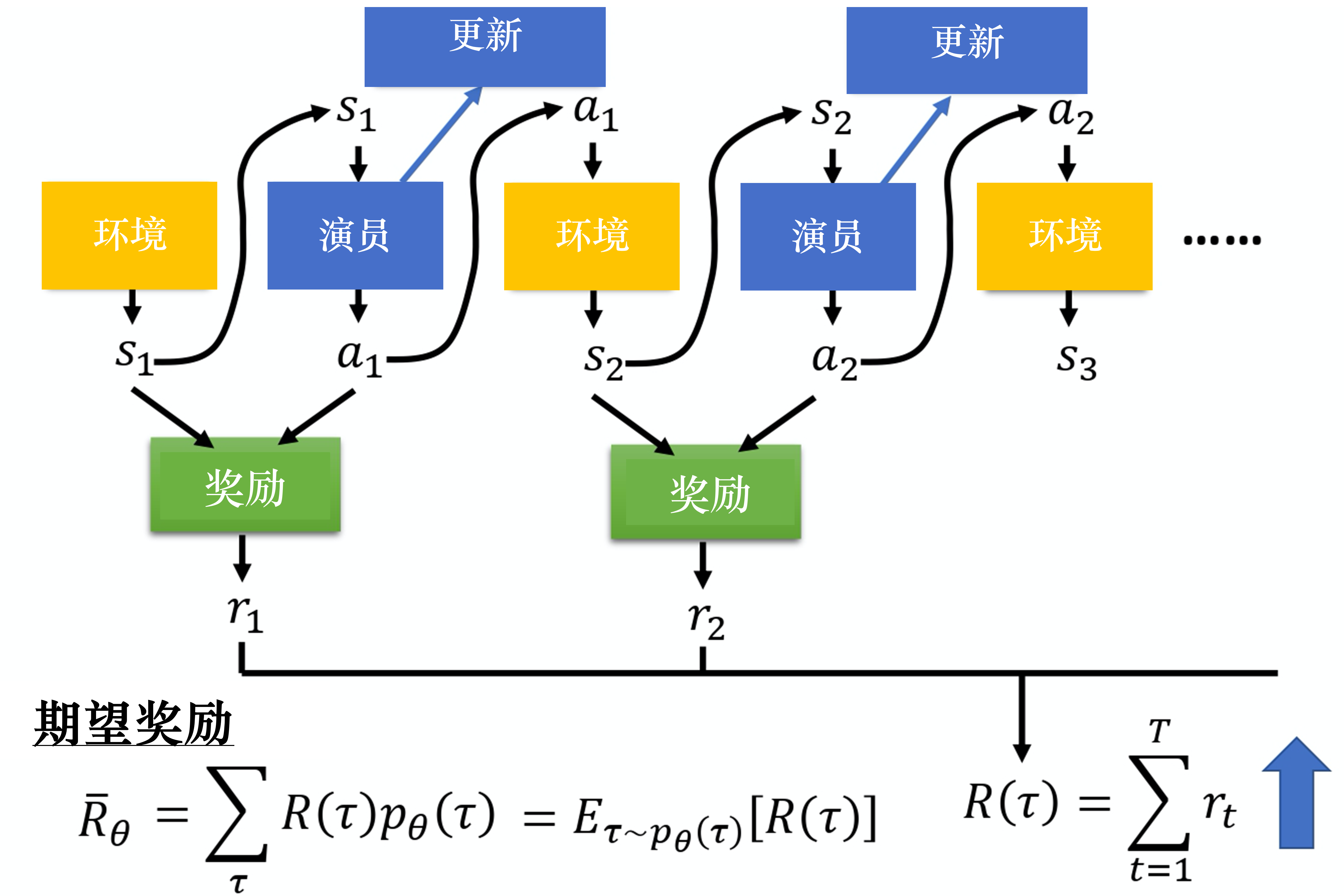
那一把游戏能不能衡量一个演员(智能体)的能力呢,可能不行,因为你有可能是蒙的,那我们如何评价一个演员的能力呢,多玩几次,求期望:
Rˉθ=∑τR(τ)pθ(τ)\bar{R}_{\theta} = \sum_{\tau} R(\tau) p_{\theta}(\tau) Rˉθ=τ∑R(τ)pθ(τ)
那么这个Rˉθ\bar{R}_{\theta}Rˉθ就是我们要优化的目标了。也可以表达成这样:
Rˉθ=∑τR(τ)pθ(τ)=Eτ∼pθ(τ)[R(τ)]\bar{R}_{\theta} = \sum_{\tau} R(\tau) p_{\theta}(\tau) = \mathbb{E}_{\tau \sim p_{\theta}(\tau)}[R(\tau)] Rˉθ=τ∑R(τ)pθ(τ)=Eτ∼pθ(τ)[R(τ)]
因为我们要让奖励越大越好,所以可以使用梯度上升(gradient ascent)来最大化期望奖励。要进行梯度上升,我们先要计算期望奖励 Rˉθ\bar{R}_{\theta}Rˉθ的梯度。我们对Rˉθ\bar{R}_{\theta}Rˉθ做梯度运算。
Rˉθ=∑τR(τ)pθ(τ)\bar{R}_{\theta} = \sum_{\tau} R(\tau) p_{\theta}(\tau) Rˉθ=τ∑R(τ)pθ(τ)
对θ\thetaθ求偏导:
∇Rˉθ=∑τR(τ)∇pθ(τ)\nabla \bar{R}_{\theta} = \sum_{\tau} R(\tau) \nabla p_{\theta}(\tau) ∇Rˉθ=τ∑R(τ)∇pθ(τ)
由于∇loga(f(x))=∇f(x)f(x)lna\nabla log_a(f(x)) = \frac{\nabla f(x)}{f(x)lna}∇loga(f(x))=f(x)lna∇f(x),lnalnalna是常数,可以忽略(直接将底数看做是e更好理解下面的公式):
∇pθ(τ)=pθ(τ)∇logpθ(τ)∇pθ(τ)pθ(τ)=∇logpθ(τ)\nabla p_{\theta}(\tau) = p_{\theta}(\tau) \nabla \log p_{\theta}(\tau) \\ \\ \frac{\nabla p_{\theta}(\tau)}{p_{\theta}(\tau)} = \nabla \log p_{\theta}(\tau) ∇pθ(τ)=pθ(τ)∇logpθ(τ)pθ(τ)∇pθ(τ)=∇logpθ(τ)
带入∇Rˉθ\nabla \bar{R}_{\theta}∇Rˉθ得:
∇Rˉθ=∑τR(τ)∇pθ(τ)=∑τR(τ)pθ(τ)∇pθ(τ)pθ(τ)=∑τR(τ)pθ(τ)∇logpθ(τ)=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]\begin{align} \nabla \bar{R}_{\theta} &= \sum_{\tau} R(\tau) \nabla p_{\theta}(\tau) \\ &= \sum_{\tau} R(\tau) p_{\theta}(\tau) \frac{\nabla p_{\theta}(\tau)}{p_{\theta}(\tau)} \\ &= \sum_{\tau} R(\tau) p_{\theta}(\tau) \nabla \log p_{\theta}(\tau) \\ &= \mathbb{E}_{\tau \sim p_{\theta}(\tau)} \left[ R(\tau) \nabla \log p_{\theta}(\tau) \right] \end{align} ∇Rˉθ=τ∑R(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)pθ(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)∇logpθ(τ)=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]
由于轨迹是采不完的,因此Eτ∼pθ(τ)\mathbb{E}_{\tau \sim p_{\theta}(\tau)}Eτ∼pθ(τ)无法计算,我们只能以部分估计总体,这也是统计学的精髓,多采几次样,这里假设采样NNN个τ\tauτ并计算每一个τ\tauτ的[R(τ)∇logpθ(τ)]\left[ R(\tau) \nabla \log p_{\theta}(\tau) \right][R(τ)∇logpθ(τ)]值,再将其求和取平均,用来近似Eτ∼pθ(τ)\mathbb{E}_{\tau \sim p_{\theta}(\tau)}Eτ∼pθ(τ)。
那如何处理logpθ(τ)\log p_{\theta}(\tau)logpθ(τ)呢?
∇logpθ(τ)=∇(logp(s1)+∑t=1Tlogpθ(at∣st)+∑t=1Tlogp(st+1∣st,at))=∇logp(s1)+∇∑t=1Tlogpθ(at∣st)+∇∑t=1Tlogp(st+1∣st,at)=∑t=1T∇logpθ(at∣st)=∑t=1T∇logpθ(at∣st)\begin{aligned} \nabla \log p_{\theta}(\tau) &= \nabla \left( \log p(s_1) + \sum_{t=1}^T \log p_{\theta}(a_t|s_t) + \sum_{t=1}^T \log p(s_{t+1}|s_t, a_t) \right) \\ &= \nabla \log p(s_1) + \nabla \sum_{t=1}^T \log p_{\theta}(a_t|s_t) + \nabla \sum_{t=1}^T \log p(s_{t+1}|s_t, a_t) \\ &= \sum_{t=1}^T \nabla \log p_{\theta}(a_t|s_t) \\ &= \sum_{t=1}^T \nabla \log p_{\theta}(a_t|s_t) \end{aligned} ∇logpθ(τ)=∇(logp(s1)+t=1∑Tlogpθ(at∣st)+t=1∑Tlogp(st+1∣st,at))=∇logp(s1)+∇t=1∑Tlogpθ(at∣st)+∇t=1∑Tlogp(st+1∣st,at)=t=1∑T∇logpθ(at∣st)=t=1∑T∇logpθ(at∣st)
第二部中有一些与θ\thetaθ无关的项直接被求偏导变成零了。因为ppp表示的是根据动作和前面的场景生成的场景为st+1s_{t+1}st+1的概率,与演员无关。
由上式和之前分析的由部分代替总体的思想一起带入∇Rˉθ\nabla \bar{R}_{\theta}∇Rˉθ可得:
Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]≈1N∑n=1NR(τn)∇logpθ(τn)=1N∑n=1N∑t=1TnR(τn)∇logpθ(atn∣stn)\begin{aligned} \mathbb{E}_{\tau \sim p_{\theta}(\tau)}[R(\tau) \nabla \log p_{\theta}(\tau)] &\approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log p_{\theta}(\tau^n) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log p_{\theta}(a_t^n|s_t^n) \end{aligned} Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]≈N1n=1∑NR(τn)∇logpθ(τn)=N1n=1∑Nt=1∑TnR(τn)∇logpθ(atn∣stn)
那我们就可以将∇Rˉθ\nabla \bar{R}_{\theta}∇Rˉθ当做损失函数:
∇Rˉθ=1N∑n=1N∑t=1TnR(τn)∇logpθ(atn∣stn)\nabla \bar{R}_{\theta} = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log p_{\theta}(a_t^n|s_t^n) ∇Rˉθ=N1n=1∑Nt=1∑TnR(τn)∇logpθ(atn∣stn)
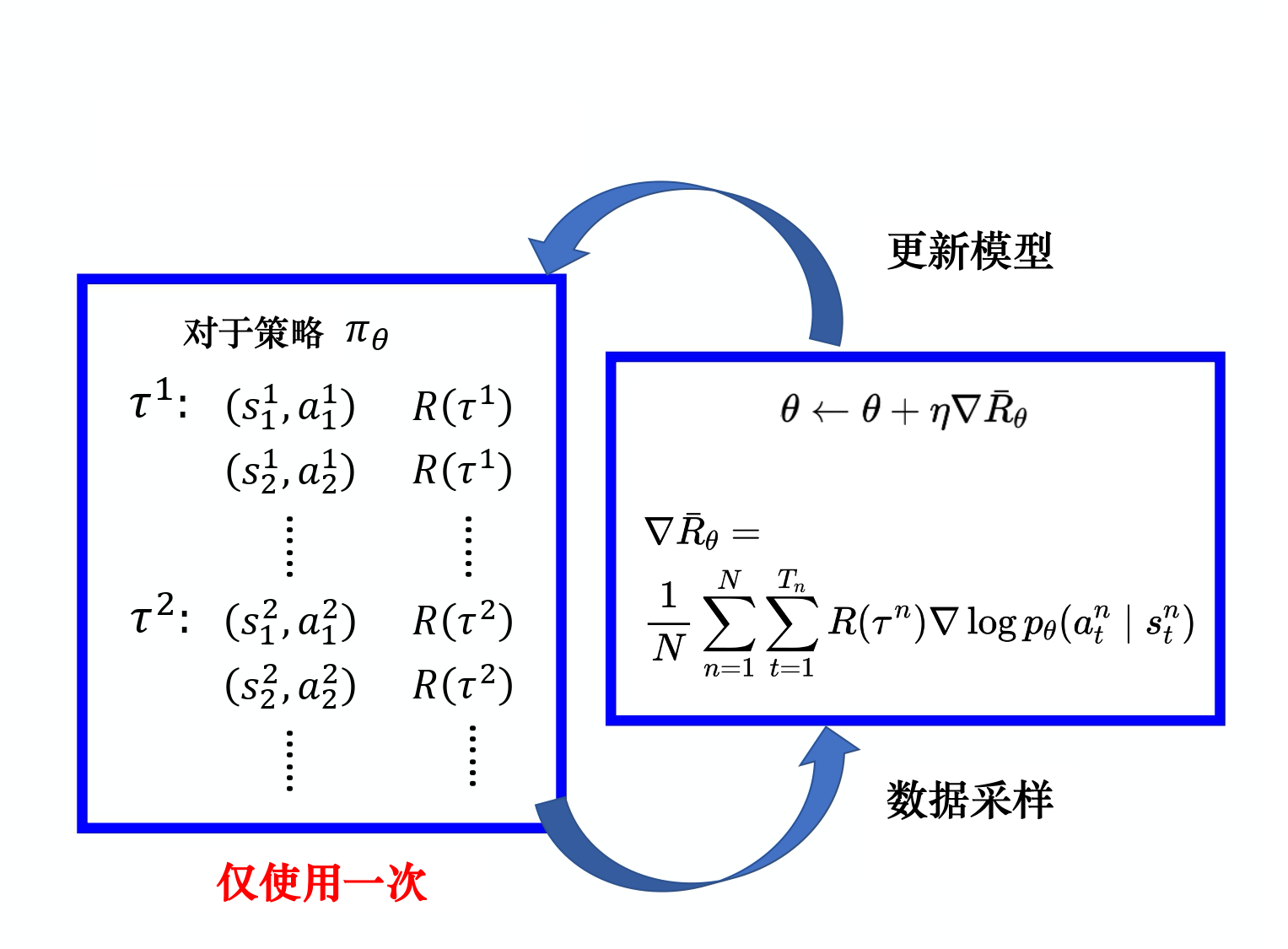
既然有了损失函数,那就可以直接套用深度学习神经网络那一套东西,更新参数:
θ←θ+η∇Rˉθ\theta \leftarrow \theta + \eta \nabla \bar{R}_{\theta} θ←θ+η∇Rˉθ
那么网络的训练步骤就非常的简单:
采集数据 ——> 更新参数——>采集数据——>……
值得注意的是采集到的数据只会用一次就丢掉,这显然是一个可以优化的点,之后在PPO算法中会对其进行优化。
2.2 策略梯度算法的一些实现技巧
2.2.1 基线
如果奖励一直是正的,∇Rˉθ\nabla \bar{R}_{\theta}∇Rˉθ就会一直是正的,那概率就只会增加不会减少,什么意思呢?
如图所示: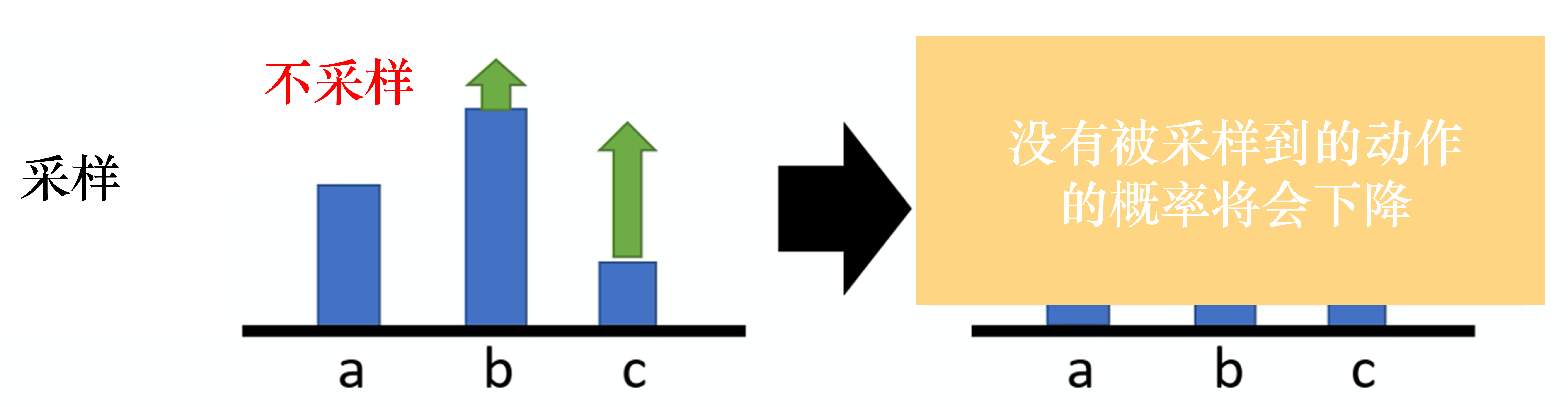
在某一个状态有 3 个动作 a、b、c可以执行,b的奖励最大,c的奖励最小。但是如果采样没有采到a,只采到了b、c,那么b、c的概率就会增大(因为奖励是正的),因为a、b、c的概率和是1,b、c概率增大了,a的概率就会减小,这显然是不科学的。
因此我们可以引入一个基线,就是把奖励统一减去bbb,让奖励有正有负,即:
∇Rˉθ≈1N∑n=1N∑t=1Tn(R(τn)−b)∇logpθ(atn∣stn)\nabla \bar{R}_{\theta} \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (R(\tau^n) - b) \nabla \log p_{\theta}(a_t^n|s_t^n) ∇Rˉθ≈N1n=1∑Nt=1∑Tn(R(τn)−b)∇logpθ(atn∣stn)
2.2.2 分配合适的分数
观察损失函数:
∇Rˉθ≈1N∑n=1N∑t=1Tn(R(τn)−b)∇logpθ(atn∣stn)\nabla \bar{R}_{\theta} \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (R(\tau^n) - b) \nabla \log p_{\theta}(a_t^n|s_t^n) ∇Rˉθ≈N1n=1∑Nt=1∑Tn(R(τn)−b)∇logpθ(atn∣stn)
在同一场游戏里面,在同一场游戏里面,所有的状态-动作对就使用同样的奖励项进行加权。
这显然是不公平的例如:
假设游戏都很短,只有 3 ~ 4 个交互,在 sas_asa 执行 a1a_1a1得到 5 分,在sbs_bsb执行a2a_2a2得到 0 分,在scs_csc执行a3a_3a3得到 −2 分。 整场游戏下来,我们得到 +3 分,那我们得到 +3 分 代表在sbs_bsb执行a2a_2a2 是好的吗? 这并不一定代表在sbs_bsb执行a2a_2a2是好的。因为这个正的分数,主要来自在sas_asa执行了a1a_1a1,与在sbs_bsb执行a2a_2a2是没有关系的,也许在sbs_bsb执行a2a_2a2反而是不好的, 因为它导致我们接下来会进入scs_csc,执行a3a_3a3被扣分。所以整场游戏得到的结果是好的, 并不代表每一个动作都是好的。
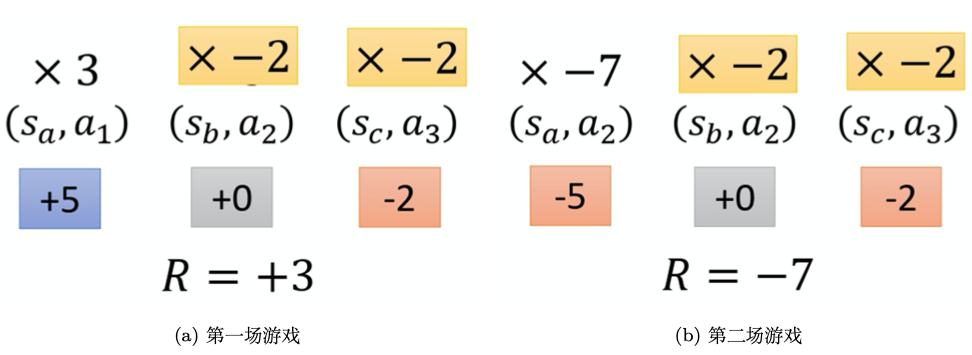
理想情况下这种情况不会发生,只要采样足够多,多次遇到(sa,a1)(s_a, a_1)(sa,a1)的情况,我们就能通过梯度更新来合理评估它的概率,但是问题是采样成本很高,采样那么多次不太现实,因此我们可以为每个状态-动作对分配合理的分数,要让大家知道它合理的贡献。
我们之前谈到过GtG_tGt
Gt=rt+1+γrt+2+γ2rt+3+...+γT−t−1rTG_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + ... + \gamma^{T-t-1} r_T Gt=rt+1+γrt+2+γ2rt+3+...+γT−t−1rT
它就能很好的反应每个状态的价值即:
∇Rˉθ≈1N∑n=1N∑t=1Tn(∑t′=tTnγt′−trt′n−b)∇logpθ(atn∣stn)=1N∑n=1N∑t=1Tn(Gt−b)∇logpθ(atn∣stn)\begin{align} \nabla \bar{R}_{\theta} &\approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} \left( \sum_{t'=t}^{T_n} \gamma^{t'-t} r_{t'}^n - b \right) \nabla \log p_{\theta}(a_t^n|s_t^n) \\ &=\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} \left( G_t - b \right) \nabla \log p_{\theta}(a_t^n|s_t^n) \end{align} ∇Rˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnγt′−trt′n−b)∇logpθ(atn∣stn)=N1n=1∑Nt=1∑Tn(Gt−b)∇logpθ(atn∣stn)
说明:
事实上bbb通常是一个网络估计出来的,它是一个网络的输出。我们把R−bR-bR−b这一项称为优势函数(advantage function), 用Aθ(st,at)A^{\theta}(s_t, a_t)Aθ(st,at)来代表优势函数。优势函数取决于sss和aaa,我们就是要计算在某个状态sss采取某个动作aaa的时候,优势函数的值。在计算优势函数值时,我们要计算∑t′=tTnrt′n\sum_{t'=t}^{T_n} r_{t'}^n∑t′=tTnrt′n,需要有一个模型与环境交互,才能知道接下来得到的奖励。优势函数Aθ(st,at)A^{\theta}(s_t, a_t)Aθ(st,at)的上标是θ\thetaθ,θ\thetaθ 代表用模型θ\thetaθ与环境交互。从时刻ttt开始到游戏结束为止,所有rrr的加和减去bbb,这就是优势函数。优势函数的意义是,假设我们在某一个状态sts_tst执行某一个动作ata_tat,相较于其他可能的动作,ata_tat有多好。优势函数在意的不是绝对的好,而是相对的好,即相对优势(relative advantage)。因为在优势函数中,我们会减去一个基线bbb,所以这个动作是相对的好,不是绝对的好。Aθ(st,at)A^{\theta}(s_t, a_t)Aθ(st,at)通常可以由一个网络估计出来,这个网络称为评论员(critic)。
2.3 REINFORCE算法实现
由于在游戏中我的策略是每个格子如果不是终点,奖励分数就是-1,因此无需使用基线,但是代码中使用了“分配合适分数”方法,所有函数作用代码中有详细注释,因此不再赘述。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 环境定义
class GridWorldEnv:
def __init__(self, size=5):
# 初始化网格世界环境
self.size = size # 网格的大小
self.state = (0, 0) # 初始状态
self.goal = (size - 1, size - 1) # 目标状态
self.actions = ['up', 'down', 'left', 'right'] # 可用的动作
self.action_space = len(self.actions) # 动作空间的大小
def reset(self):
# 重置环境到初始状态
self.state = (0, 0)
return self.state
def step(self, action):
# 根据动作更新状态,并返回新的状态、奖励和是否完成
x, y = self.state
if action == 0: # 向上
x = max(0, x - 1)
elif action == 1: # 向下
x = min(self.size - 1, x + 1)
elif action == 2: # 向左
y = max(0, y - 1)
elif action == 3: # 向右
y = min(self.size - 1, y + 1)
self.state = (x, y)
reward = -1 # 默认奖励
if x == 2 and y != 2:
reward = -10
done = self.state == self.goal # 检查是否到达目标
if done:
reward = 10 # 到达目标的奖励
return self.state, reward, done
def render(self):
# 渲染当前状态的网格世界
grid = np.zeros((self.size, self.size)) # 创建一个全零的网格
x, y = self.state
grid[x, y] = 1 # 将当前状态的位置设为1
print(grid)
# 策略网络
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
# 初始化策略网络
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(input_dim, 24) # 第一层全连接层
self.fc2 = nn.Linear(24, 128) # 第二层全连接层
self.fc3 = nn.Linear(128, output_dim) # 第三层全连接层
self.relu = nn.ReLU() # ReLU激活函数
self.softmax = nn.Softmax(dim=-1) # Softmax输出层
def forward(self, x):
# 前向传播
x = self.relu(self.fc1(x)) # 第一层激活
x = self.relu(self.fc2(x)) # 第二层激活
x = self.softmax(self.relu(self.fc3(x))) # 第三层激活
return x
# REINFORCE算法
class REINFORCE:
def __init__(self, state_space, action_space, learning_rate=0.01, gamma=0.99):
# 初始化REINFORCE算法
self.policy_network = PolicyNetwork(state_space, action_space) # 策略网络
self.optimizer = optim.Adam(self.policy_network.parameters(), lr=learning_rate) # Adam优化器
self.gamma = gamma # 折扣因子
def choose_action(self, state):
# 根据状态选择动作
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) # 将状态转换为张量
action_probs = self.policy_network(state).detach().numpy()[0] # 获取动作概率
action = np.random.choice(len(action_probs), p=action_probs) # 根据概率选择动作
return action
def compute_discounted_rewards(self, rewards):
# 计算折扣奖励
discounted_rewards = np.zeros_like(rewards, dtype=np.float32) # 初始化折扣奖励
cumulative = 0
for i in reversed(range(len(rewards))):
cumulative = cumulative * self.gamma + rewards[i] # 计算累计折扣奖励
discounted_rewards[i] = cumulative
return discounted_rewards
def train(self, states, actions, rewards):
# 训练策略网络
discounted_rewards = self.compute_discounted_rewards(rewards) # 计算折扣奖励
# 归一化奖励
discounted_rewards = (discounted_rewards - np.mean(discounted_rewards)) / (np.std(discounted_rewards) + 1e-8)
discounted_rewards = torch.tensor(discounted_rewards, dtype=torch.float32)
states = torch.tensor(states, dtype=torch.float32) # 将状态转换为张量
actions = torch.tensor(actions, dtype=torch.long) # 将动作转换为张量
# 计算损失
log_probs = torch.log(self.policy_network(states)) # 计算对数概率
selected_log_probs = log_probs[range(len(actions)), actions] # 选择执行动作的对数概率
loss = -torch.mean(selected_log_probs * discounted_rewards) # 计算损失
# 优化网络
self.optimizer.zero_grad() # 清零梯度
loss.backward() # 反向传播
self.optimizer.step() # 更新参数
# 主程序
def main():
env = GridWorldEnv(size=5) # 创建网格世界环境
agent = REINFORCE(state_space=10, action_space=4, learning_rate=0.01) # 创建REINFORCE智能体
episodes = 1000 # 训练回合数
reward_history = [] # 奖励历史
state = env.reset() # 重置环境
env.render() # 渲染初始状态
for episode in range(episodes):
state = env.reset() # 重置环境
states, actions, rewards = [], [], [] # 初始化状态、动作和奖励列表
done = False
while not done:
# 状态转换为独热向量
state_onehot = np.eye(env.size)[state[0]].tolist() + np.eye(env.size)[state[1]].tolist()
action = agent.choose_action(state_onehot) # 选择动作
next_state, reward, done = env.step(action) # 执行动作
states.append(state_onehot) # 记录状态
actions.append(action) # 记录动作
rewards.append(reward) # 记录奖励
state = next_state # 更新状态
agent.train(states, actions, rewards) # 训练智能体
reward_history.append(sum(rewards)) # 记录总奖励
if episode % 100 == 0:
print(f"Episode {episode}, Total Reward: {sum(rewards)}") # 每100回合打印一次总奖励
# 绘制奖励曲线
plt.plot(reward_history)
plt.xlabel("Episodes")
plt.ylabel("Total Reward")
plt.show()
if __name__ == "__main__":
main()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)