深度强化学习 # DDPG
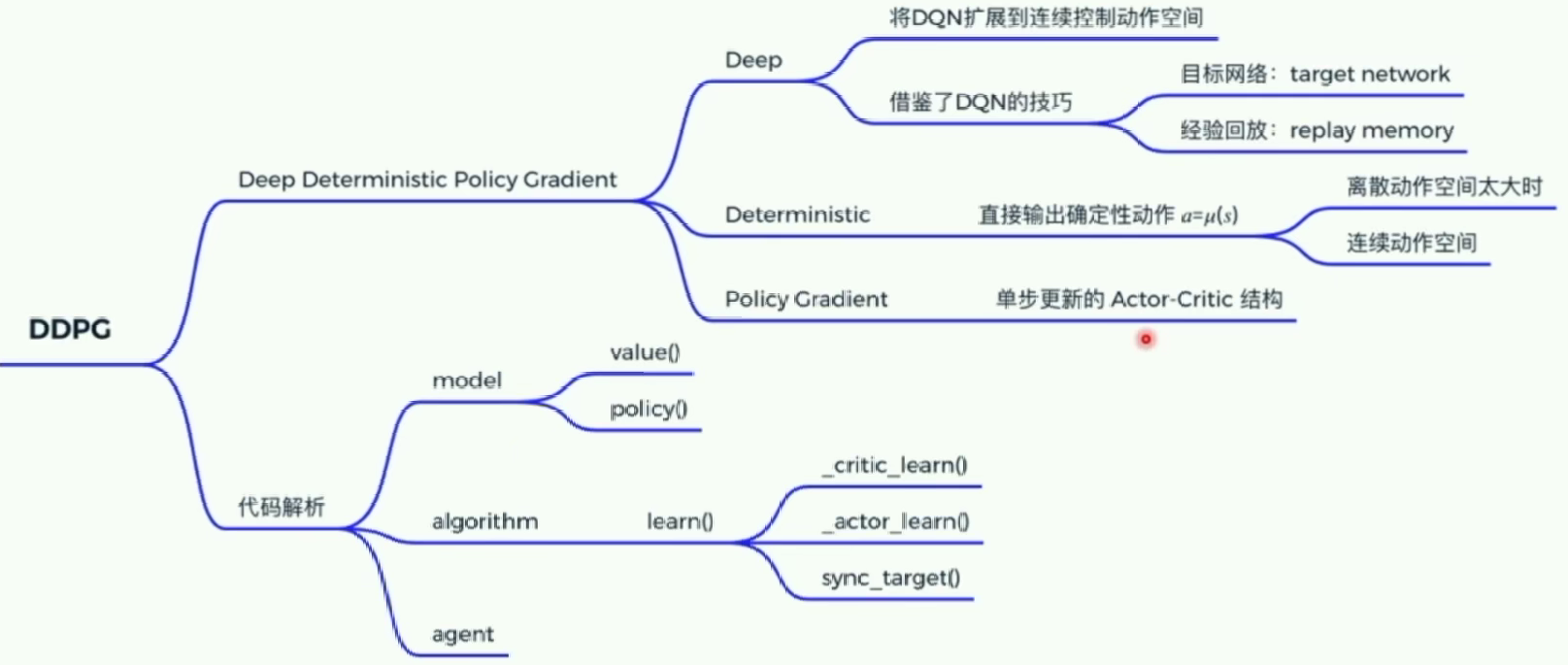
Deep Deterministic Policy Gradient (DDPG)前置基础:policy gradientDDPG是一种Actor-Critic结构。基于PARL实现DDPGReferencehttps://www.bilibili.com/video/BV1yv411i7xd?p=18https://mofanpy.com/tutorials/machine-learning/r
前置基础:
Deep Q Network
Policy gradient
Actor Critic
DPG:Deterministic Policy Gradient
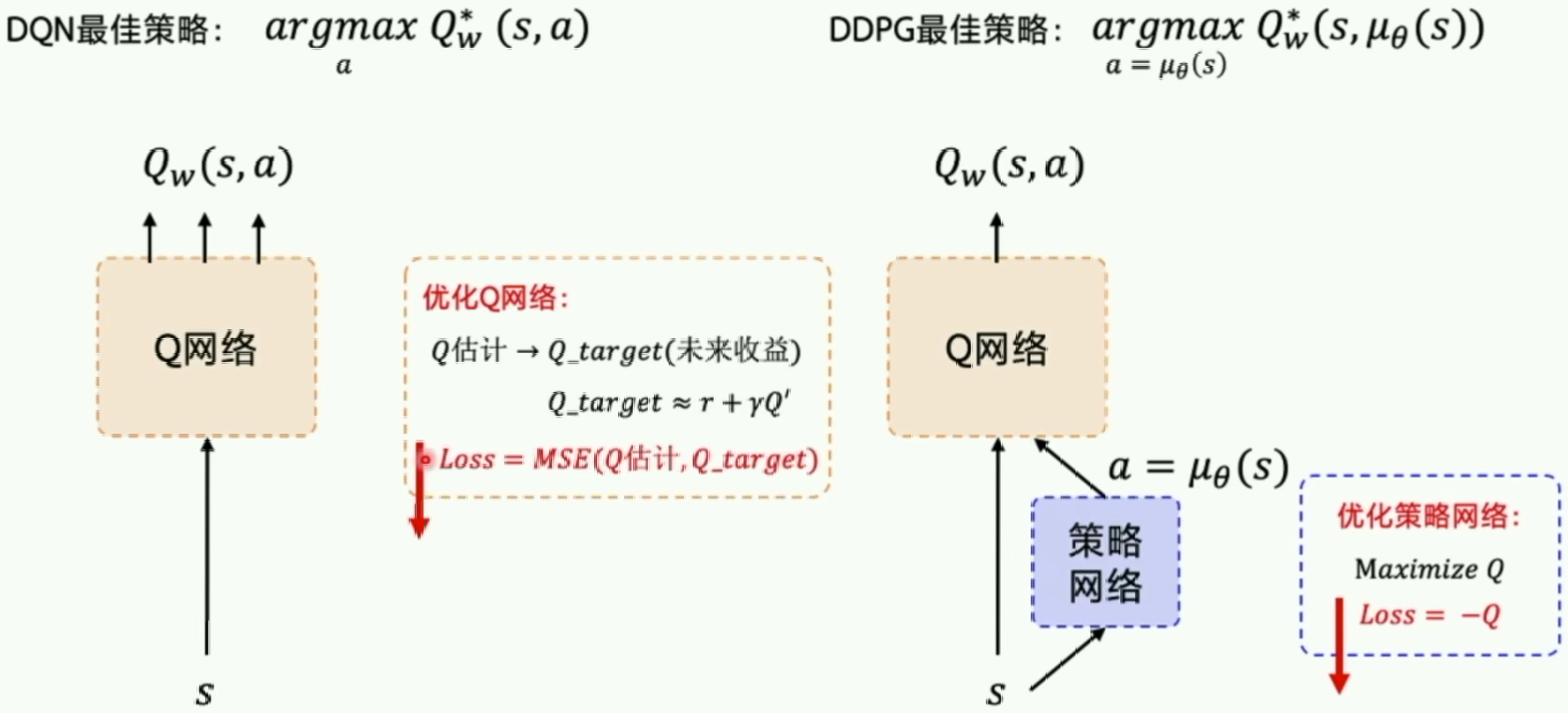
DDPG: Google DeepMind 提出的一种使用 Actor Critic 结构, 但是输出的不是行为的概率, 而是具体的行为的值, 用于连续动作 (continuous action) 的预测。
优点:DDPG可以在连续动作上更有效的学习,DDPG 结合了 DQN 结构, 提高了 Actor Critic 的稳定性和收敛性。
基础的Actor-Critic不是确定性策略梯度,是随机策略梯度,输出的还是行为的概率。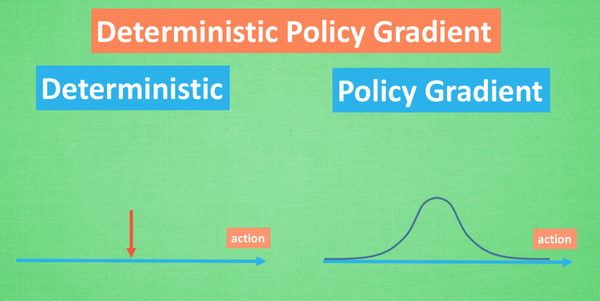
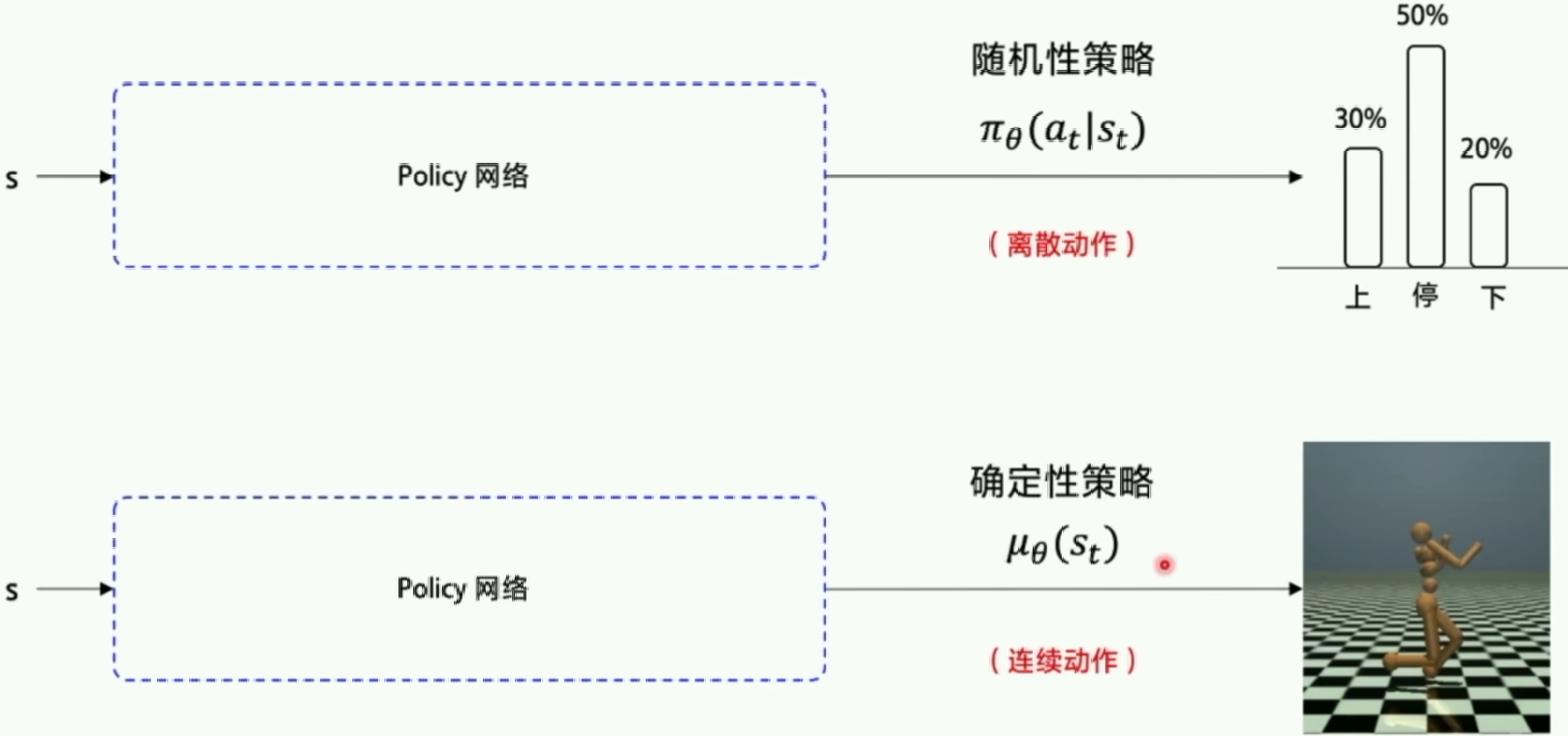
DPG:确定性策略梯度
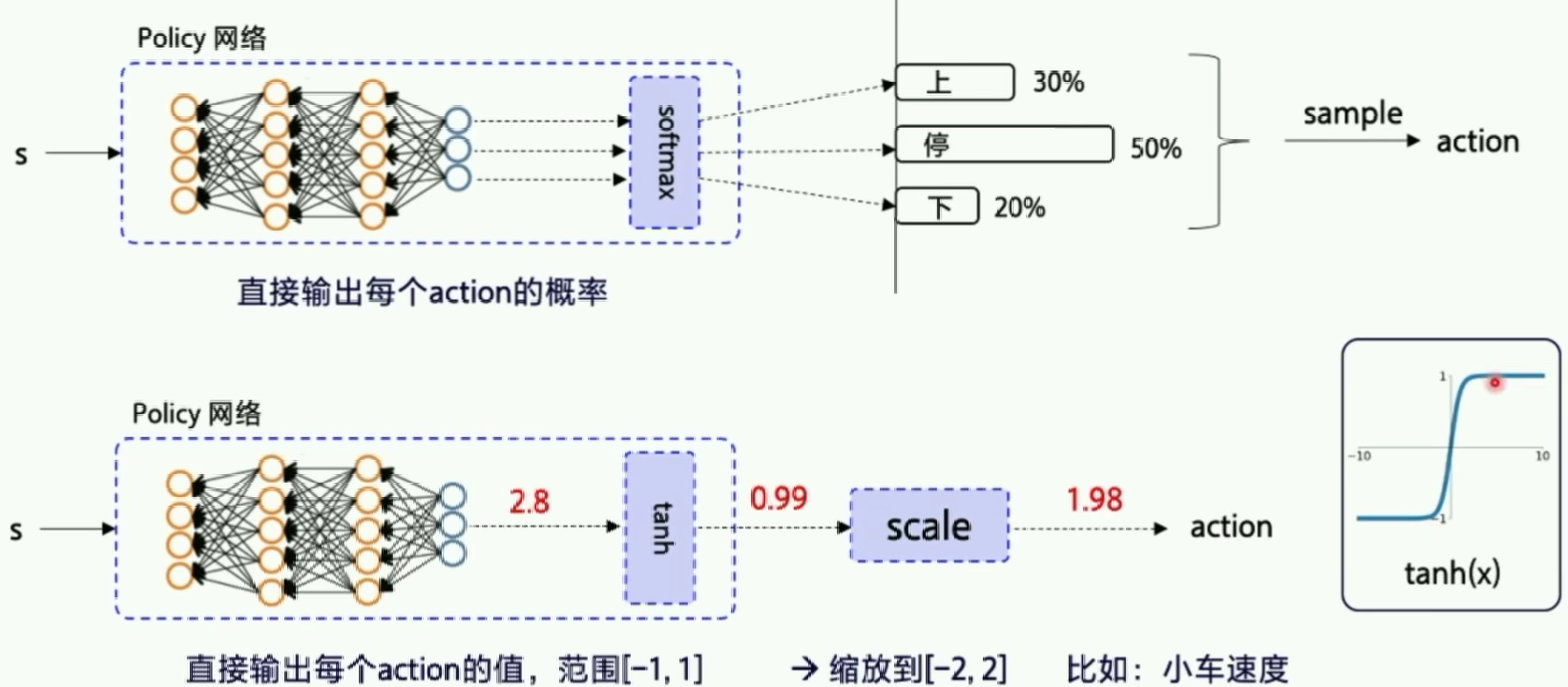
我们把输出行为的概率变成直接输出行为的值,所以这里的行为是确定性的,并且输出的是连续的值(可以解决DQN解决不了的连续问题)。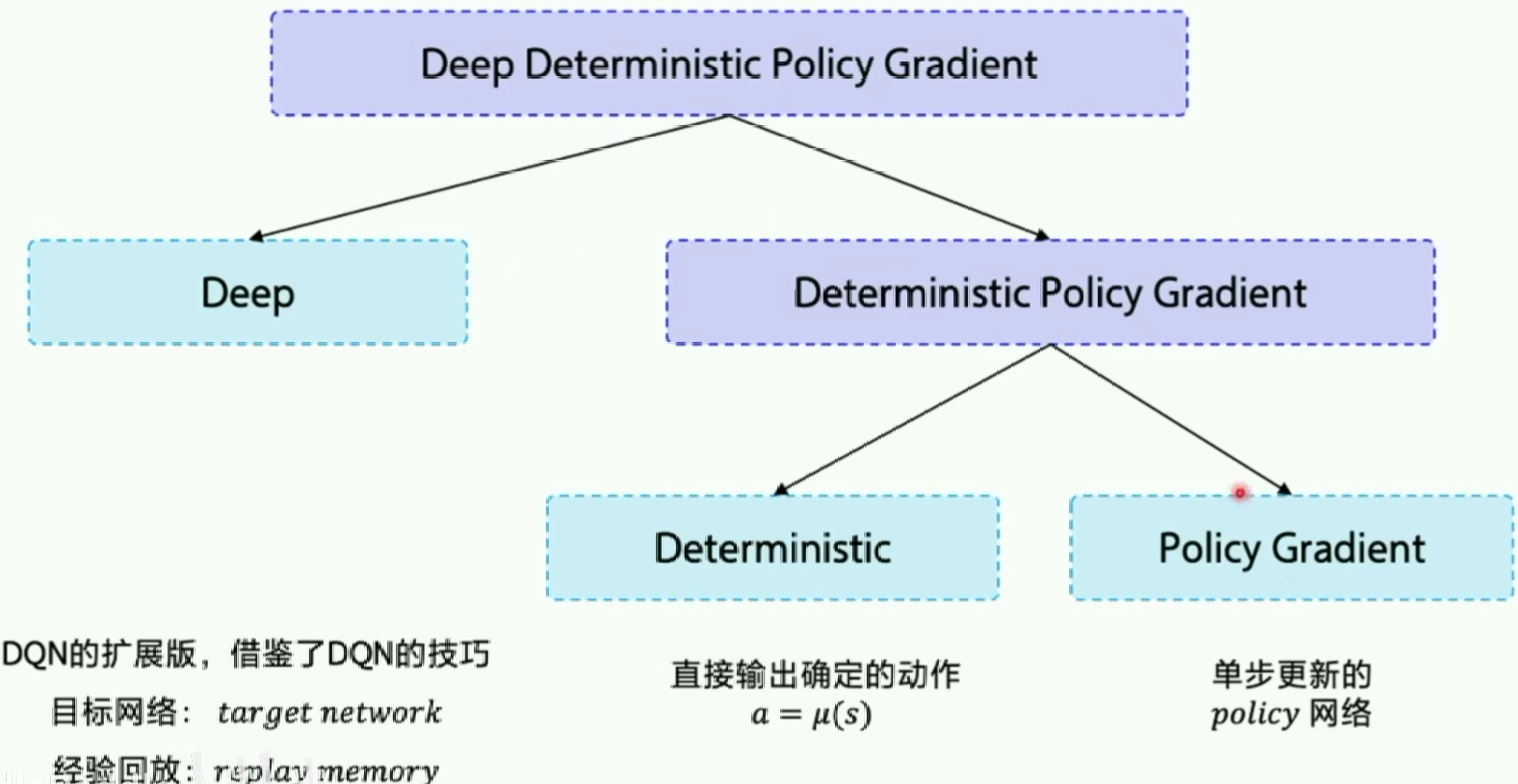
DDPG是一种Actor-Critic结构。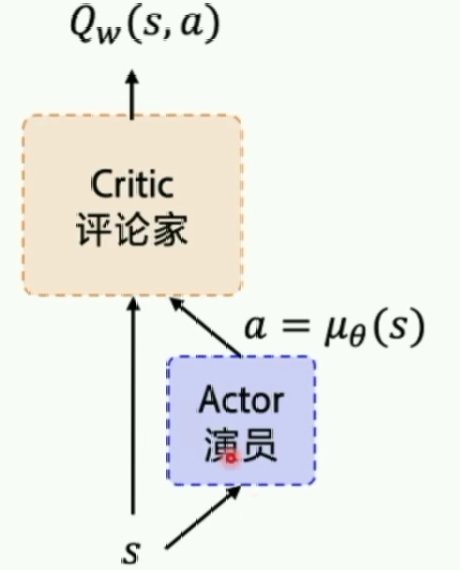
但是在AC结构的基础上采用的experience replay和fixed q-target技巧(这里的fix技巧还固定了一个策略网络)
DDPG输出的是确定性策略,DDPG中的Critic在更新计算TD差分值时,使用到了目标策略网络Actor的输出。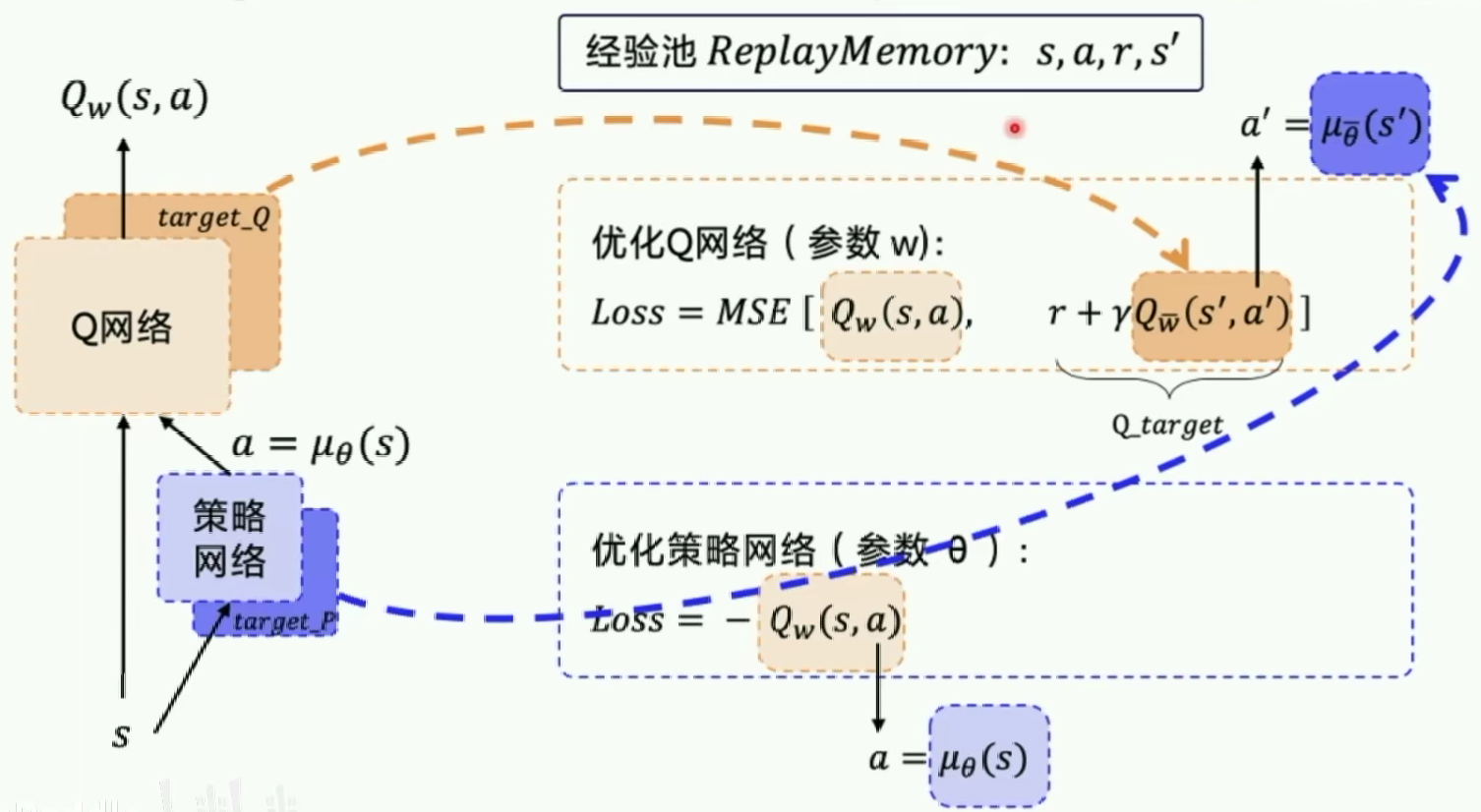
有人说一个fix q-target技巧算什么创新,你要是实际去做过实验就知道了,DDPG和朴素的AC方法(REINFORCE算法)的收敛效率差的贼多…
这是个很实用的创新。
同时,为了解决确定性策略的Exploration和策略更新的稳定性问题,还增加了随机量和soft-replace。具体算法伪代码如下所示:
- 算法第八行中的 N t N_t Nt就是为解决策略Exploration所添加的随机量;
- 第十行这里就是存储每步的状态,为后面update中使用经验回放作准备。
- 算法最后两行,就是soft-replace部分,不是完全更新,而是只更新网络中很小的一部分τ \tauτ,按照算法中的介绍,需要满足条件: τ < < 1 \tau<<1 τ<<1
基于PARL实现DDPG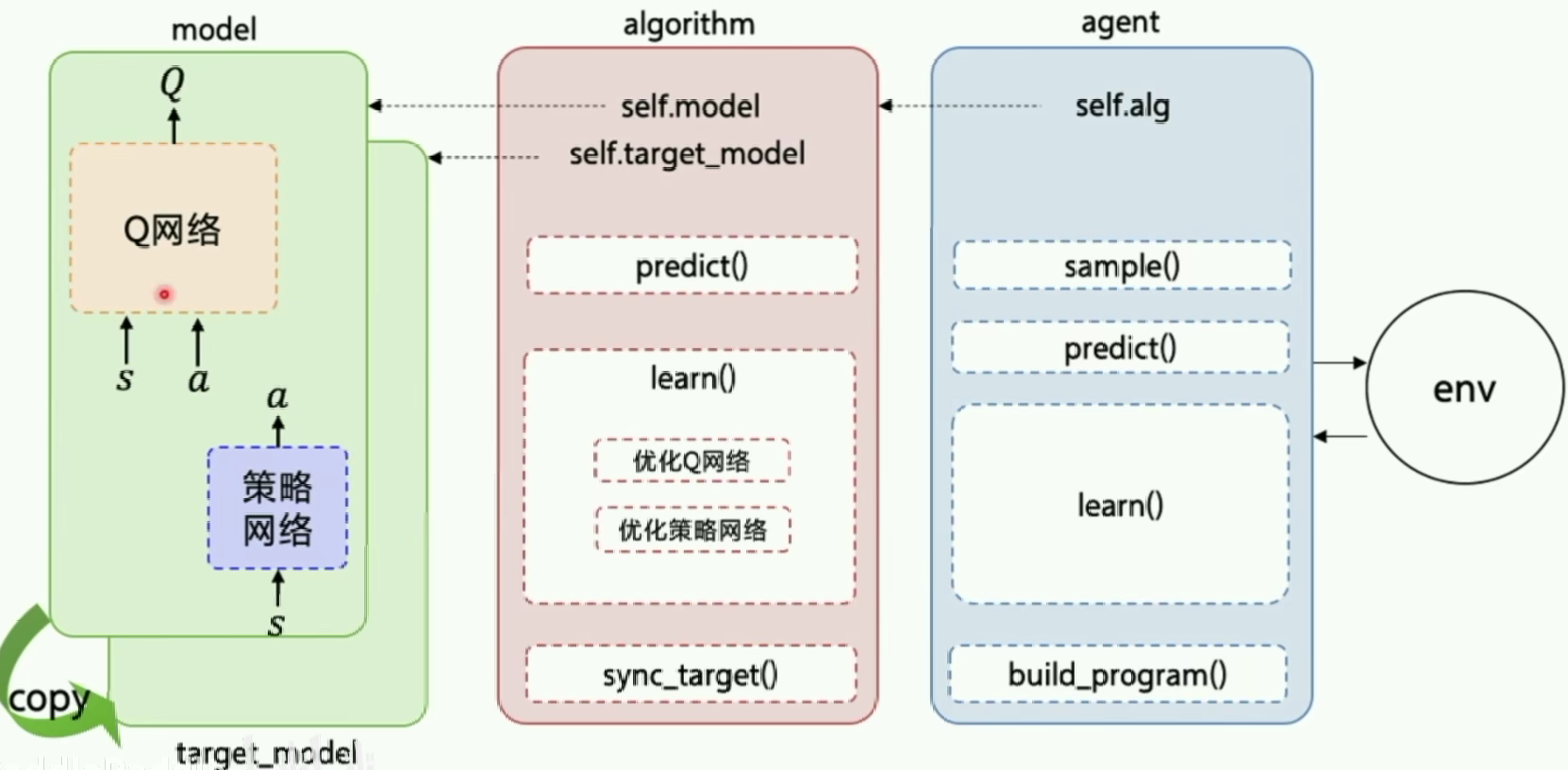
Reference
- https://www.bilibili.com/video/BV1yv411i7xd?p=18
- https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/intro-DDPG/
- 关于DPG\DDPG数学部分:基础算法篇(七),确定性策略的DPG与DDPG

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)