卷积神经网络的压缩方法简介
卷积神经网络的压缩方法简介低秩近似剪枝与稀疏约束参数量化二值网络知识蒸馏紧凑的网络结构尽管卷积神经网络在诸如计算机视觉、自然语言处理等领域取得了出类拔萃的效果,但其动辄过亿的参数数量却使得诸多实际应用望而却步(特别是基于嵌入式设备的应用)。经典的VGG-16网络中,其参数数量达到了1亿3千多万。存储代价和计算代价都很大,严重制约了深度网络在移动端等小型设备上的应用。鉴于各种问题,神经网络的压缩逐渐
尽管卷积神经网络在诸如计算机视觉、自然语言处理等领域取得了出类拔萃的效果,但其动辄过亿的参数数量却使得诸多实际应用望而却步(特别是基于嵌入式设备的应用)。经典的VGG-16网络中,其参数数量达到了1亿3千多万。存储代价和计算代价都很大,严重制约了深度网络在移动端等小型设备上的应用。
鉴于各种问题,神经网络的压缩逐渐成为当下深度学习领域的热门研究课题。研究者们提出了各种新颖的算法,在追求模型高准确度的同时,尽可能地降低其复杂度,以期达到性能与开销上的平衡。
总体而言,绝大多数的压缩算法,均旨在将一个庞大而复杂的预训练模型(pre- trained model)转化为-一个精简的小模型。当然,也有研究人员试图设计出更加紧凑的网络结构,通过对新的小模型进行训练来获得精简模型。从严格意义上来讲,这种算法不属于网络压缩的范畴,但本着减小模型复杂度的最终目的,我们也将其归纳到本文的介绍内容中来。
按照压缩过程对网络结构的破坏程度,我们将模型压缩技术分为“前端压缩”与“后端压缩”两部分。所谓“前端压缩”,是指不改变原网络结构的压缩技术,主要包括知识蒸馏、紧凑的模型结构设计以及滤波器(filter) 层面的剪枝等;而“后端压缩”则包括低秩近似、未加限制的剪枝、参数量化以及二值网络等,其目标在于尽可能地减少模型大小,因而会对原始网络结构造成极大程度的改造。其中,由于“前端压缩”未改变原有的网络结构,仅仅只是在原模型的基础上减少了网络的层数或者滤波器的个数,其最终的模型可完美适配现有的深度学习库,如Caffe 等。相比之下,“后端压缩”为了追求极致的压缩比,不得不对原有的网络结构进行改造,如对参数进行量化表示等,而这样的改造往往是不可逆的。同时,为了获得理想的压缩效果,必须开发相配套的运行库,甚至是专门的硬件设备,其最终的结果往往是- -种压缩技术对应于一套运行库,从而带来了巨大的维护成本。
本文所提及的压缩,不仅仅指体积上的压缩,也包括时间上的压缩,其最终目的在于减少模型的资源占用。
低秩近似
卷积神经网络的基本计算模式是进行卷积运算。具体实现上,卷积操作由矩阵相乘完成。不过通常情况下,权重矩阵往往稠密且巨大,从而带来计算和存储上的巨大开销。为解决这种情况的一种直观的想法是,若能将该稠密矩阵由若干个小规模矩阵近似重构出来,那么便能有效降低存储和计算开销。由于这种算法大多采用低秩近似的技术来重构权重矩阵,我们将其归类为低秩近似算法。这里不再详细叙述,具体操作读者可自行查阅文献。
剪枝与稀疏约束
剪枝,作为模型压缩领域中的一种经典技术,已经被广泛运用到各种算法的后处理中。通过剪枝处理,在减小模型复杂度的同时,还能有效防止过拟合,提升模型泛化性。剪枝操作可类比于生物学上大脑神经突触数量的变化情况。很多哺乳动物在幼年时,其脑神经突触的数量便已经达到顶峰,随着大脑发育的成熟,突触数量会随之下降。类似的,在神经网络的初始化训练中,我们需要一定冗余度的参数数量来保证模型的可塑性与“容量”,而在完成训练后,则可以通过剪枝操作来移除这些冗余参数,使得模型更加成熟。
给定一个预训练好的网络模型,常用的剪枝算法一般都遵从如下操作流程:
1.衡量神经元的重要程度。这是剪枝算法中最重要的核心步骤。根据剪枝粒度的不同神经元的定义可以是一个权重连接,也可以是整个滤波器。衡量其重要程度的方法也是多种多样,从一些基本的启发式算法,到基于梯度的方案,其计算复杂度与最终的效果也是各有千秋。
2.移除掉一部分不重要的神经元。按照重要程度剪掉一定比例的神经元,这种方法更加简便,灵活性也更高。
3.对网络进行微调。
4.返回第1步,进行下一轮剪枝。
参数量化
所谓“量化”是从权重中归纳出若干“代表”,由这些“代表”来表示某一类权重的具体数值,“代表”被存储在码本之中,而原权重只需记录各自“代表”的索引即可,从而极大降低了存储开销。这种思想可类比于经典的词包模型。
最简单也是最基本的一种量化算法便是标量量化。
参数量化作为一种常用的后端压缩技术,能够以很小的性能损失实现模型体积的大幅下降。其不足之处在于,量化后的网络是“固定”的,很难再对其做任何改变,另一方面,这一类方法的通用性较差,往往是一种量化方法对应一套专门的运行库,造成较大的维护成本。
二值网络
二值网络可以被视为量化方法的一种极端情况:所有参数的取值只能是正负一。正式这种极端的设定,使得二值网络可以获得极大的压缩效益。
网络二值化首先需要解决两个基本问题:
**1.如何对权重进行二值化?**权重二值化通常有两个选择:一是直接根据权重的正负进行二值化,二是进行随机的二值化,但是第一种策略更加实用。
**2.如何计算二值权重的梯度?**这种解决方案常常是对符号函数进行放松。
知识蒸馏
知识蒸馏其实是迁移学习的一种,其最终目的是将一个庞大而复杂的模型所学到的知识,通过一定的技术手段迁移到精简的小模型上,使得小模型能够获得与大模型相近的性能。
在知识蒸馏的框架中,有两个基本要素起着决定性作用:
一是何谓“知识”,即是如何提取模型中的知识
二是如何“蒸馏”,即如何完成知识转移的任务。
紧凑的网络结构
可以设计一种更加紧凑的网络结构,将这些新颖的结构运用到神经网络的设计中来,能够使得模型在规模和精度之间达到一个较好的平衡。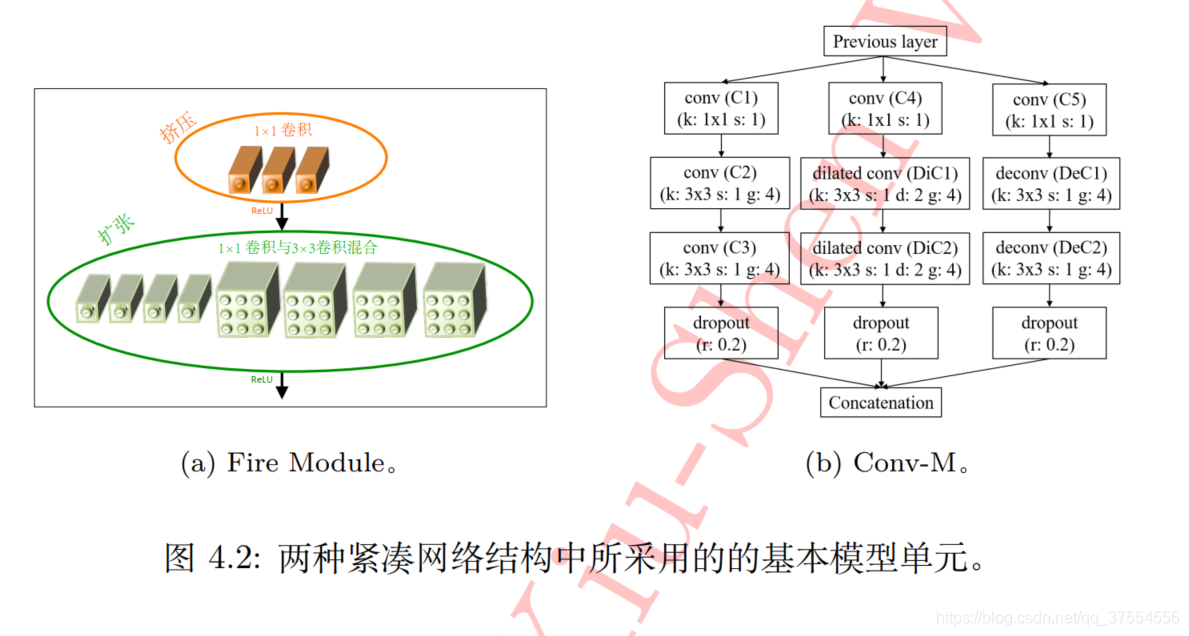
注:文章选自《解析深度学习—卷积神经网络原理与视觉实践》魏秀参著

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)