Day3:强化学习之Q-Learning代码例程
一、机器人多步决策过程用Qlearning算法思路:一、机器人多步决策过程用Qlearning算法思路:1.问题说明:机器人随机位于某个位置,需要到达位置6即为赢得游戏。2.奖励政策:机器人走迷宫一共有6个位置,6个位置的地图如下,给定奖惩规则为:不能通过给-1分,走到终点给100分。例如:如果机器人位于位置1,则该位置不能通过位置0(此时会给个-1分),走到了终点6就给一个100分。3.得到奖惩
一、机器人多步决策过程用Qlearning算法思路:
1.问题说明:
机器人随机位于某个位置,需要到达位置6即为赢得游戏。
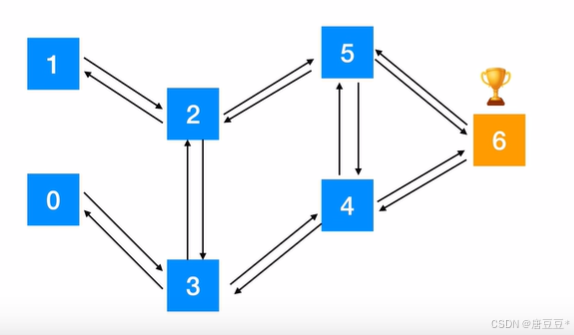
2.奖励政策:
机器人走迷宫一共有6个位置,6个位置的地图如下,给定奖惩规则为:不能通过给-1分,走到终点给100分。
例如:如果机器人位于位置1,则该位置不能通过位置0(此时会给个-1分),走到了终点6就给一个100分。
3.得到奖惩表格:
行表示的是当前机器人的位置(状态),列表示机器人可以选择走到哪个位置(动作)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
| 0 | -1 | -1 | -1 | 0 | -1 | -1 | -1 |
| 1 | -1 | -1 | 0 | 1 | -1 | -1 | -1 |
| 2 | -1 | 0 | -1 | 0 | -1 | 0 | -1 |
| 3 | 0 | -1 | 0 | -1 | 0 | -1 | -1 |
| 4 | -1 | -1 | -1 | 0 | -1 | 0 | 100 |
| 5 | -1 | -1 | 0 | -1 | 0 | -1 | 100 |
| 6 | -1 | -1 | -1 | -1 | 0 | 0 | 100 |
4.Q值更新方式
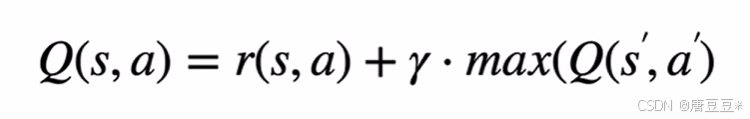
逻辑关系说明:
1)比如,如果机器人位于状态2,则此时可以选择Q(2,1)或者Q(2,3);对应Q(2,1)的下一个状态只能是Q(1,2),而对于Q(2,3)下一个状态可能是(Q(3,0),Q(3,2),Q(3,4))
2)此时可以在Q(2,1)和Q(2,3)中随机抽取,也就是下面这行代码

3)假设抽到了Q(2,3),此时下一个状态变为了3,则从q表中获得第3行里面的最大回报,再通过Q值更新公式对Q值进行更新,具体如下代码。

二、具体代码实现
import gym
import numpy as np
import random
q =np.zeros((7,7)) #初始化q列表为7*7的零矩阵,并将其转化为一个numpy对象;这个矩阵用于存储每个状态的预期回报值
# 奖惩:到结束位置,则奖励100;不能到的位置则给-1
r =np.array([[-1,-1,-1,0,-1,-1,-1],
[-1,-1,0,-1,-1,-1,-1],
[-1,0,-1,0,-1,0,-1],
[0,-1,0,-1,0,-1,-1],
[-1,-1,-1,0,-1,0,100],
[-1,-1,0,-1,0,-1,100],
[-1,-1,-1,-1,0,0,100]])
gamma =0.8 #折扣系数
#训练模型,获得Q表
for i in range(1000): #循环1000次
#每次训练迭代从随机状态开始,直到达到状态6结束
state = random.randint(0,6) #随机选择0~6中的整数,对每一个训练,随机选择一种状态,开始训练
while state !=6: #状态不等于6,也就是没到结束状态
r_pos_action =[] #创建一个空列表用于存储当前状态下所有可以执行的动作
for action in range(7): #遍历所有动作,将可以执行的动作添加到相应的可执行动作列表中
if r[state, action]>=0: #取r>=0的动作
r_pos_action.append(action) #将action的值添加到r_pos_action的末尾
if r_pos_action: #如果可执行动作列表不为空
next_state =r_pos_action[random.randint(0, len(r_pos_action)-1)] # 从符合条件的动作中,随机选择一个动作作为下一个状态
#在这里next_state就是随机选择的action
#下面的公式其实就是q[state,action]=r+gamma*np.max(q[next_state]),即Q算法中的q值更新公式
q[state,next_state] =r[state,next_state]+gamma*np.max(q[next_state]) # 更新Q值,其中np.max(q[next_state]) 是在q矩阵的next_state行中获取最大值
state =next_state
else: #如果没有可行的动作
break #如果没有可行动作,结束当前训练
#测试程序
state = random.randint(0,6) #随机选择0~6中的整数,抽取当前状态
print('机器人处于{}'.format(state))
count=0
while state !=6:
if count>20:
print('fail') #动作不超过20次
break
# 选择最大的q_max
q_max=q[state].max()
q_max_action = []
for action in range(7):
if q[state, action] == q_max:
q_max_action.append(action) #选择action所在的位置作为q_max_action
# 如果有多个动作都等于q_max, 则随机抽样,获取新的状态
next_state = q_max_action[random.randint(0,len(q_max_action)-1)]
print("机器人 goes to"+str(next_state)+'.')
state = next_state
count += 1
print(q)三、结果展示
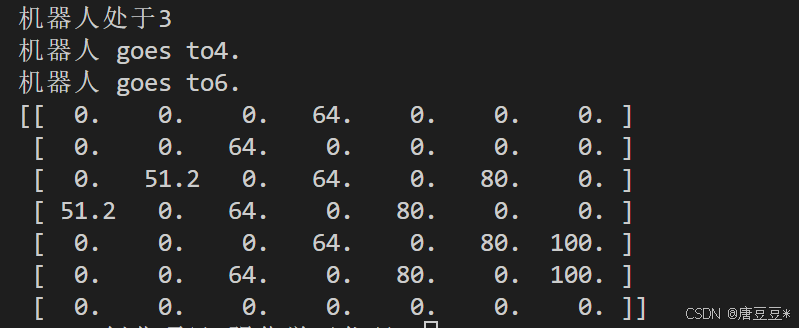
结果1:
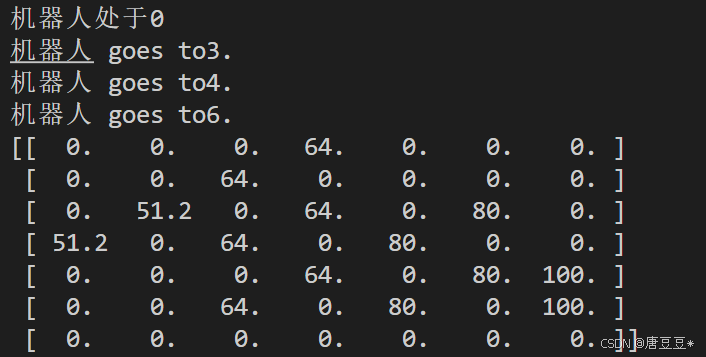
结果2:
学习视频:强化学习算法系列教程及代码实现-Q-Learning_哔哩哔哩_bilibili

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)