GPT-2只需要非监督学习
1 简介GPT先是非监督的预训练,然后进行监督训练微调。而GPT-2,是想只需要非监督训练即可,不用再监督训练。本文根据2019《Language Models are Unsupervised Multitask Learners》翻译总结。从标题就可以看出来,作者尝试只使用非监督学习。监督学习是脆弱、敏感的,比如当数据分布稍微改变,或者只针对的某个特定任务。我们本文描述语言模型可以不需要任何监
1 简介
GPT先是非监督的预训练,然后进行监督训练微调。而GPT-2,是想只需要非监督训练即可,不用再监督训练。
本文根据2019《Language Models are Unsupervised Multitask Learners》翻译总结。从标题就可以看出来,作者尝试只使用非监督学习。
监督学习是脆弱、敏感的,比如当数据分布稍微改变,或者只针对的某个特定任务。
我们本文描述语言模型可以不需要任何监督训练微调(只有预训练的非监督学习),即零调整,包括参数和架构,来应用于下游任务。作者认为语言模型就该是这个样子,可能符合人类语言思维吧。这是GPT-2的主要思想。
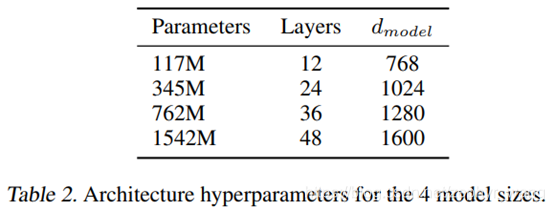
GPT-2对GPT没用太多结构调整,只是增加了参数量,下面最大参数那个是GPT-2,最小那个是GPT,第2小的参数量类似BERT。
采用的非监督实验数据就是用爬虫从网上爬出来的文章。
输入采用的BPE(byte pair encoding),基于byte序列的BPE,不需要预处理、tokenization、或者vocab size。
2 实验结果
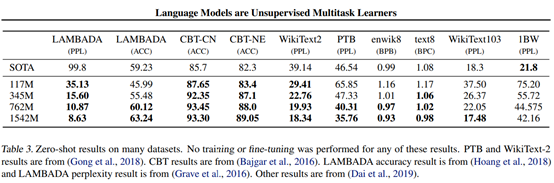
GPT-2在阅读理解上的表现可以和监督训练的相媲美;
但在其他任务,如概述总结(summarization),GPT-2还只是在初级阶段。
此外GPT-2在问题回答、翻译任务上,也表现一般。
所以GPT-2有待于进一步发展,但其不需要监督训练微调,只需要预训练的思想是不错的。
下面列了一些GPT-2表现较好的数据集:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)