【目标检测】YOLOv10GPU训练自己的数据 (超详细保姆级教程)——附带vscode,labelimg与anaconda安装
yolov10anacondavscodelabelimg 环境配置xml转txtYOLOv10 模型进行视频流处理确定计算设备(如 CPU 或 GPU),确保模型可以在可用的 GPU 上运行以提高处理速度。
前言
提示:本文是YOLOv10训练自己数据集的记录教程,需要大家在本地已配置好CUDA,cuDNN等环境,没配置的小伙伴可以查看下载cuda和cudnn(11.8版本)_cudnn下载-CSDN博客
yolov10项目代码
代码地址:https://github.com/THU-MIG/yolov10
论文地址:https://arxiv.org/pdf/2405.14458
1.Anaconda和vscode安装
Anaconda是一个强大的开源数据科学平台,它将很多好的工具整合在一起,极大地简化了使用者的工作流程,并能够帮助使用者解决一系列数据科学难题。
有小伙伴纠结先安装python还是安装anaconda,这边的建议是装anaconda,就不需要单独装python了,因为anaconda自带python,且安装了anaconda之后,默认python版本是anaconda自带的python版本。
Anaconda下载地址
- 注:在Anaconda安装的过程中,比较容易出错的环节是环境变量的配置,所以大家在配置环境变量的时候,要细心一些。
首先 登录Anaconda官网。
- 进去是这样的,直接点击"Download"即可。(必须要是Windows环境且是64位)
安装详细步骤
- 双击下载好的安装包
- 点击 Next
- 点击 I Agree
- 选择 JUST Me
- 选择安装路经
- 查看内容,图方便勾选自动添加环境变量
- 点击Install,安装需要等待一会儿。
- 点击Next:
- 对于两个“learn”自行选择,打上之后会下载好自动打开annconda。
安装完毕
在电脑屏幕左下角的Windows徽标键这里,选择点击绿色圈圈Anaconda Navifator将其打开
出现此界面即为安装成功:
 到这里,基本的安装和设置就好了。
到这里,基本的安装和设置就好了。
安装VScode
VScode国内也有许多网站,但是大部分都是要money的,直接官网下载就好,有的说官网下载慢,也可以找国内镜像(虽然我是下载很快了)
官网下载链接: VSCode下载
这个就是下载页面,按自己系统下载,这里我只说Windows
同意协议
没啥好说的,同意–>下一步。
选择安装路径
考虑一下自己盘的内存,点击浏览选择自己设置的安装路径,另外路径中不要含有中文,然后点击下一步。
选择附加任务项
①将“通过code 打开“操作添加到windows资源管理器文件上下文菜单
②将“通过code 打开”操作添加到windows资源管理器目录上下文菜单
说明:①②勾选上,可以对文件,目录点击鼠标右键,选择使用 VScode 打开。
③将code注册为受支持的文件类型的编辑器
说明:默认使用 VScode 打开诸如 txt,py 等文本类型的文件,一般建议不勾选。
让 VScode 支持的代码文件全部变成 VScode 默认打开,文件图标也会随之更改,很好辨认。
④添加到PATH(重启后生效)
说明:这步骤默认的,勾选上,不用配置环境变量,可以直接使用。
至于创建桌面快捷方式看个人需求,选好点击下一步。
VSCode中文配置
对于有些更喜欢中文操作的
装一些python扩展等等也是在这个地方,方法类似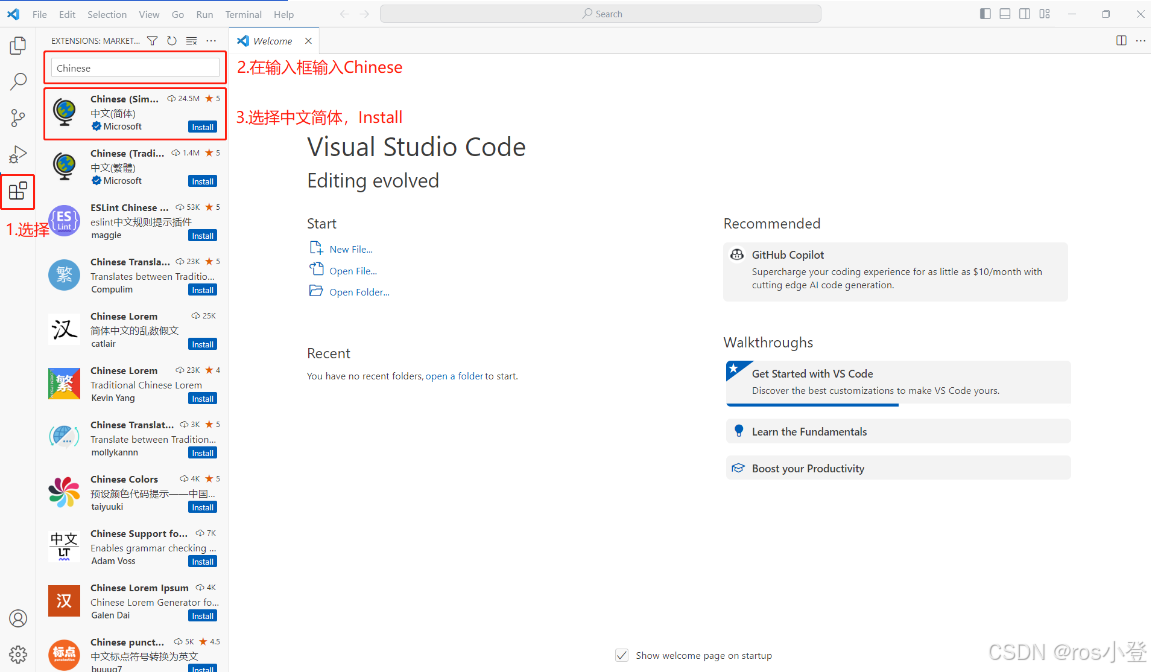
2.yolov10环境搭建
在配置好CUDA环境,并且获取到YOLOv10源码后,建议新建一个虚拟环境专门用于YOLOv10模型的训练。
conda create -n yolov10 python=3.9
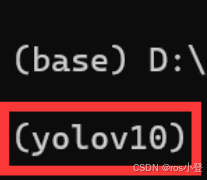
加载创建的yolov10环境:
conda activate yolov10
进入后()会变成你环境名称 (判断是否安装成功)
将YOLOv10加载到环境后,安装剩余的包。requirements.txt 中包含了运行所需的包和版本,利用以下命令批量安装:
pip install -r requirements.txt #如果报错用另一个命令,换国内源安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
去除模型只读权限(如果说你要修改模型,必须pip install -e.,如果说只是复现,可加可不加)
pip install -e . #如果报错用另一个命令
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
安装支持GPU的torch
这里我给大家上传到了百度网盘上:通过百度网盘分享的文件:torch_gpu.zip
链接:https://pan.baidu.com/s/13iN38yHQ_6c7-PFyGWXXJA?pwd=8q1x
提取码:8q1x
安装命令类似,这里我是将文件保存到D盘下:
pip install D:\torch_gpu\torch-2.3.1+cu118-cp39-cp39-win_amd64.whl
pip install D:\torch_gpu\torchaudio-2.3.1+cu118-cp39-cp39-win_amd64.whl
pip install D:\torch_gpu\torchvision-0.18.1+cu118-cp39-cp39-win_amd64.whl
3.检测是否安装正确
vscode打开终端
注意我的终端默认为
激活环境

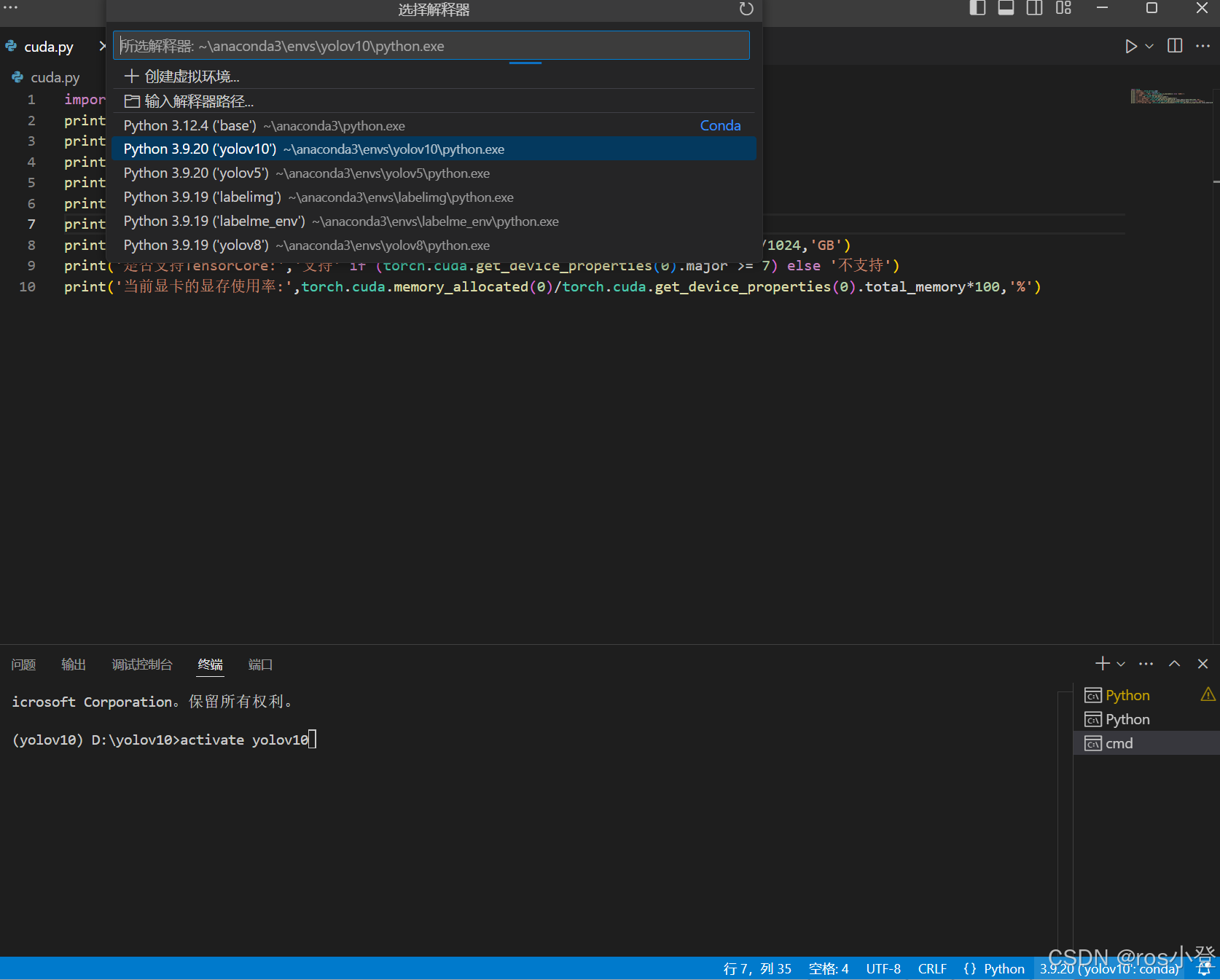
CTRL+shift+p 搜索python选择python解释器
 也可以点开python文件后点击界面右下角选择解释器
也可以点开python文件后点击界面右下角选择解释器
建立cuda.py
import torch
print('CUDA版本:',torch.version.cuda)
print('Pytorch版本:',torch.__version__)
print('显卡是否可用:','可用' if(torch.cuda.is_available()) else '不可用')
print('显卡数量:',torch.cuda.device_count())
print('当前显卡型号:',torch.cuda.get_device_name())
print('当前显卡的CUDA算力:',torch.cuda.get_device_capability())
print('当前显卡的总显存:',torch.cuda.get_device_properties(0).total_memory/1024/1024/1024,'GB')
print('是否支持TensorCore:','支持' if (torch.cuda.get_device_properties(0).major >= 7) else '不支持')
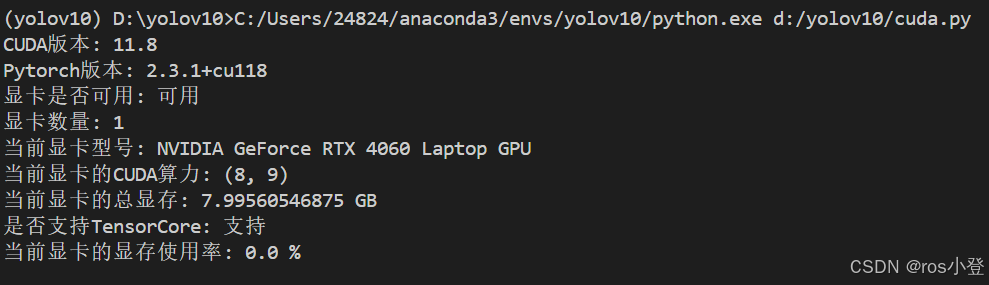
print('当前显卡的显存使用率:',torch.cuda.memory_allocated(0)/torch.cuda.get_device_properties(0).total_memory*100,'%')运行代码若环境配置成功应该类似显示为:
4.数据集制作
A.构建数据集
YOLOv10模型的训练需要原图像及对应的YOLO格式标签,这里先讲怎么构建数据集,后面会给出labelimg安装教程
我的原始数据存放在根目录的data文件夹(新建的)下,里面包含图像和标签。
标签格式如下:

具体格式为 class_id x y w h,分别代表物体类别,标记框中心点的横纵坐标(x, y),标记框宽高的大小(w, h),且都是归一化后的值,图片左上角为坐标原点。
将原本数据集按照8:1:1的比例划分成训练集、验证集和测试集三类,划分代码如下。
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
# 原始路径
image_original_path = "data/images/"
label_original_path = "data/labels/"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")
# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")
# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")
# 训练集目录
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
def del_file(path):
for i in os.listdir(path):
file_data = path + "\\" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.jpg'
srcLabel = label_original_path + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()
划分完成后将会在datasets文件夹下生成划分好的文件,其中images为划分后的图像文件,里面包含用于train、val、test的图像,已经划分完成;labels文件夹中包含划分后的标签文件,已经划分完成,里面包含用于train、val、test的标签;train.tet、val.txt、test.txt中记录了各自的图像路径。
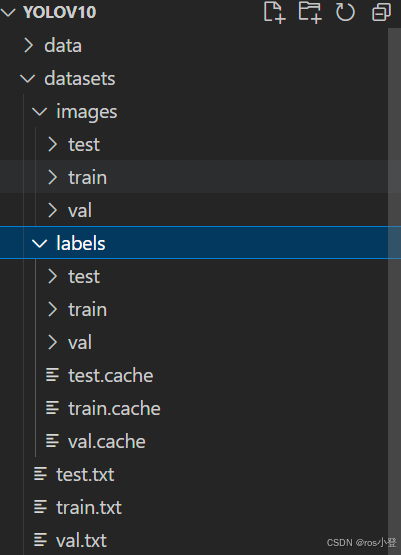
这里的.cache文件是我自己训练产生的,零基础新手不必在意
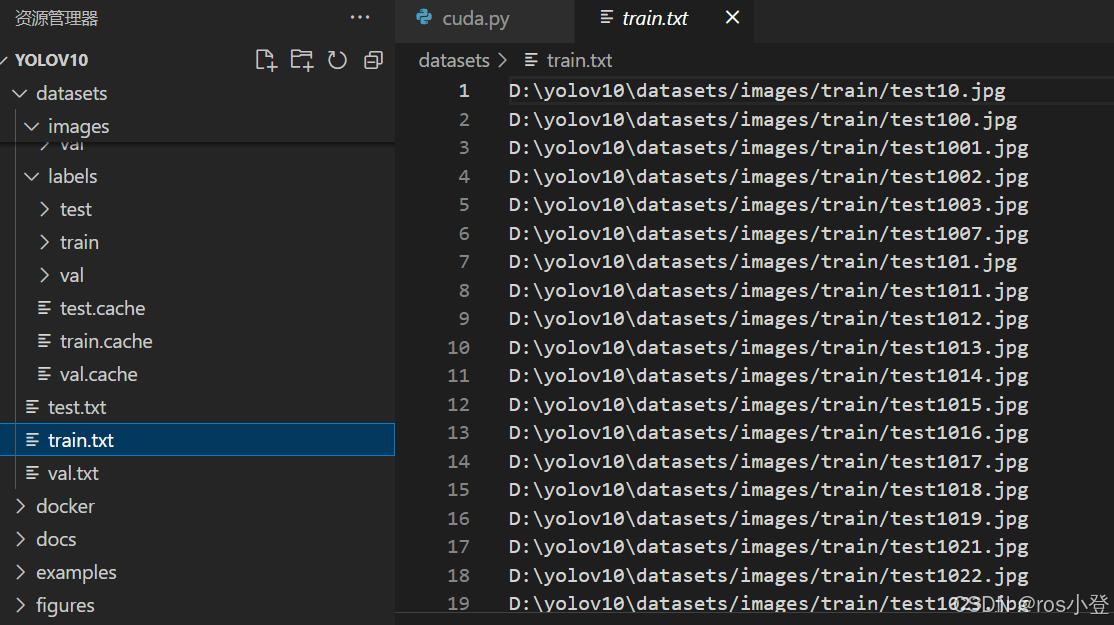
在训练过程中,也是主要使用这三个txt文件进行数据的索引。
B.修改配置文件
①数据集文件配置
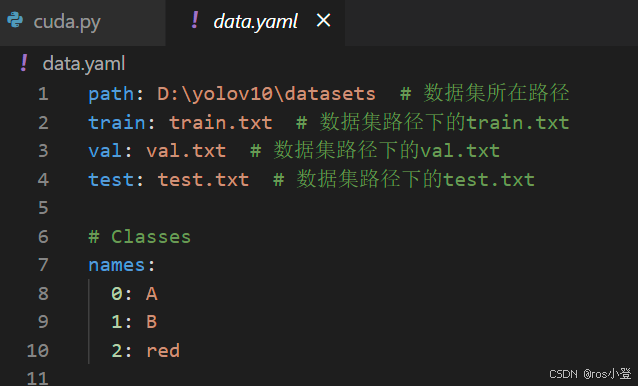
数据集划分完成后,在根目录文件夹下新建data.yaml文件,替代coco.yaml。用于指明数据集路径和类别,我这边只有三个类别,只留了三个,多类别的在name内加上类别名即可。data.yaml中的内容为:
path: ../datasets # 数据集所在路径
train: train.txt # 数据集路径下的train.txt
val: val.txt # 数据集路径下的val.txt
test: test.txt # 数据集路径下的test.txt# Classes
names:
0: A1: B
2: red
②模型文件配置
在ultralytics/cfg/models/v10文件夹下存放的是YOLOv10的各个版本的模型配置文件,检测的类别是coco数据的80类。在训练自己数据集的时候,只需要将其中的类别数修改成自己的大小。在根目录文件夹下新建yolov10n-test.yaml文件,此处以yolov10n.yaml文件中的模型为例,将其中的内容复制到yolov10n-test.yaml文件中 ,并将nc: 1 # number of classes 修改类别数` 修改成自己的类别数,如下:
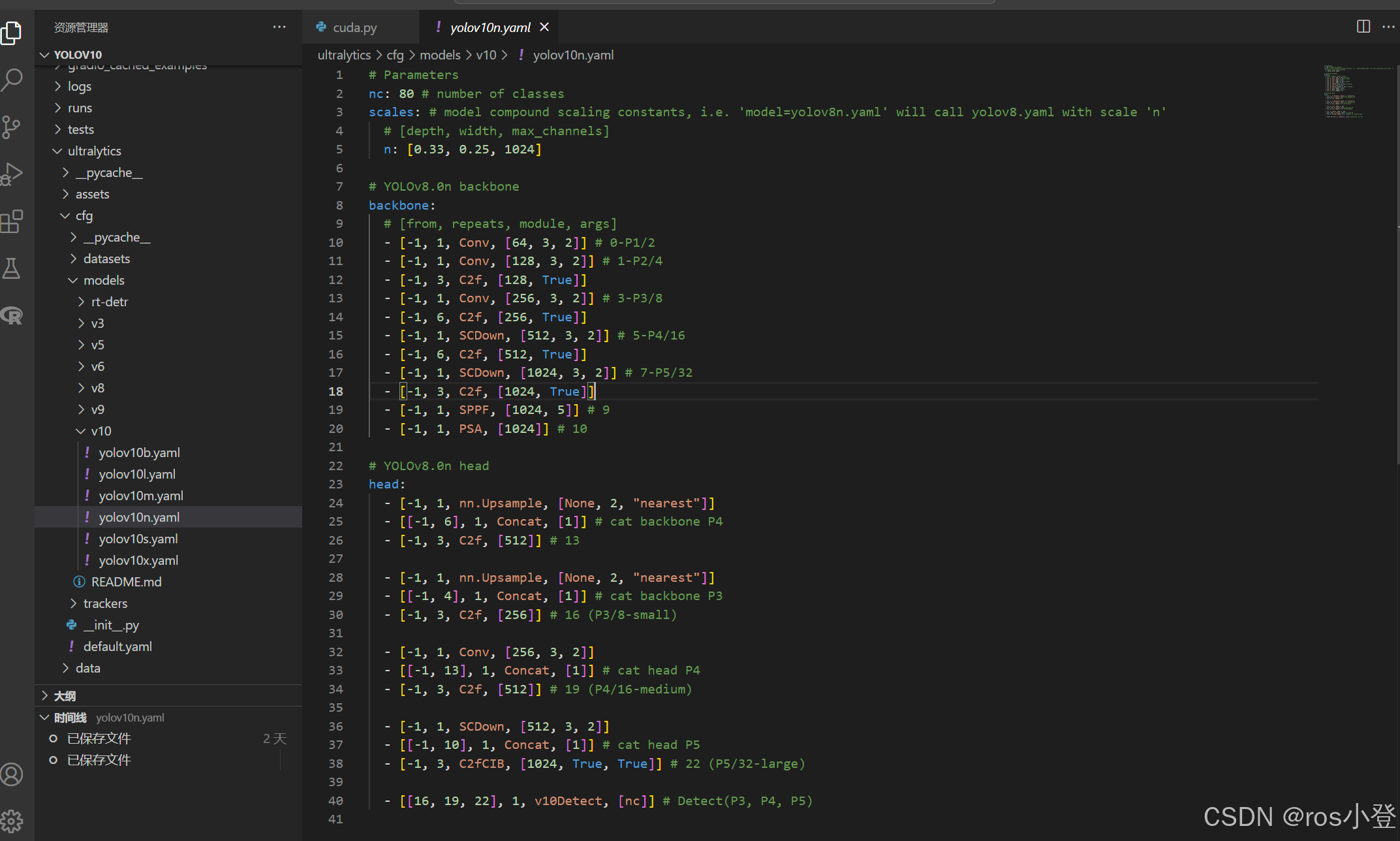
# Parameters
nc: 3 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PSA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
修改完成后,模型文件就配置好啦。
③训练文件配置
在进行模型训练之前,需要到官网下载预训练权重,权重地址为:Releases · THU-MIG/yolov10 · GitHub
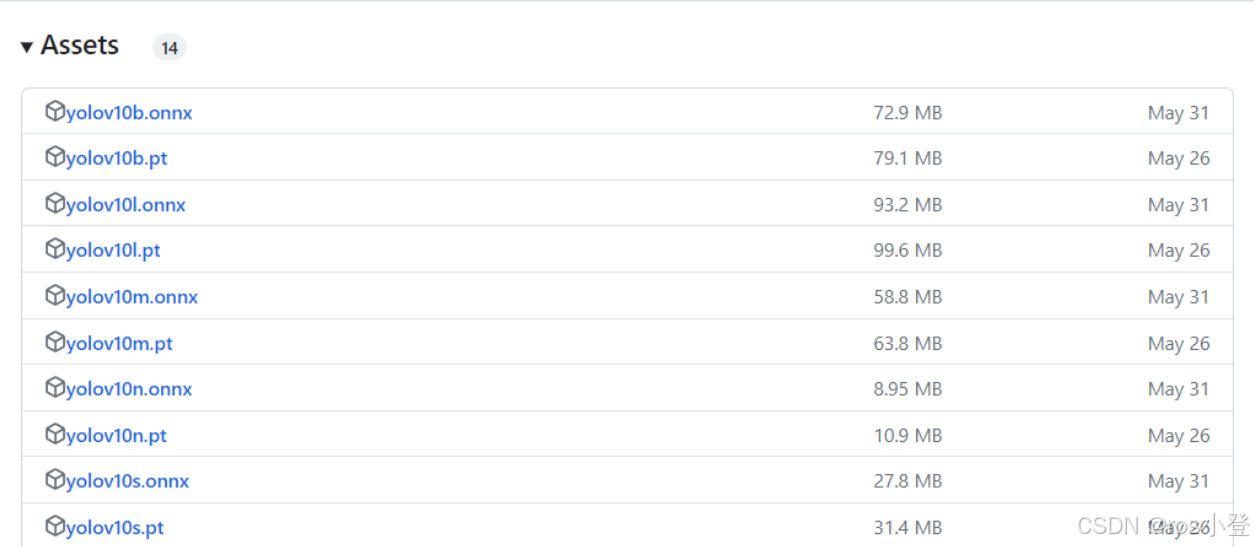
根据所选择的模型下载相应的权重,我这边下载的是yolov10n.pt,放在了根目录weights/yolov10n.pt路径下。
YOLOv10的超参数配置在ultralytics/cfg文件夹下的default.yaml文件中
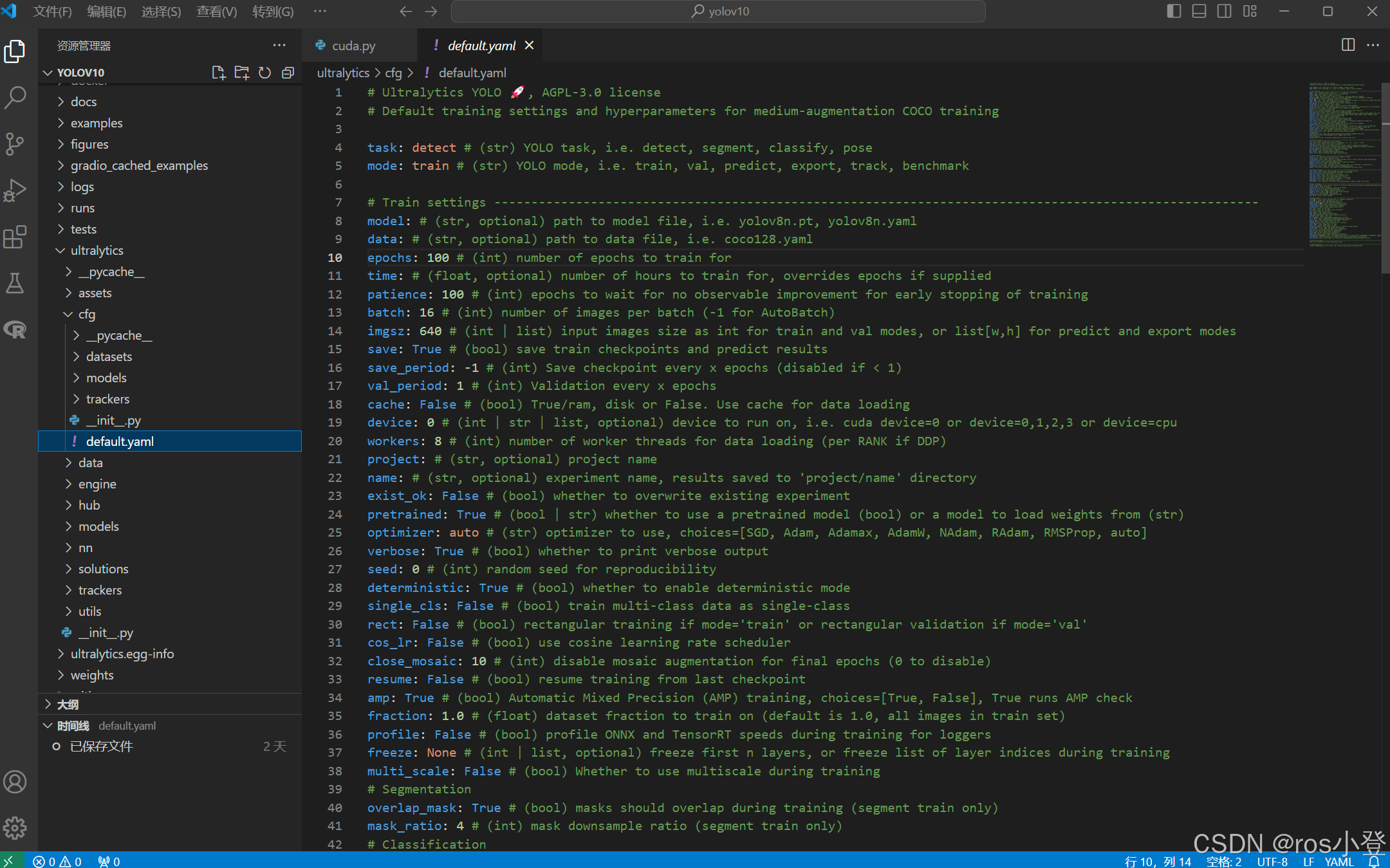
在模型训练中,比较重要的参数是weights、data、epochs、batch、imgsz、device以及workers。
weight是配置预训练权重的路径,可以指定模型的yaml文件或pt文件。
data是配置数据集文件的路径,用于指定自己的数据集yaml文件。
epochs指训练的轮次,默认是100次,只要模型能收敛即可。
batch是表示一次性将多少张图片放在一起训练,越大训练的越快,如果设置的太大会报OOM错误,我这边在default中设置16,表示一次训练16张图像。设置的大小为2的幂次,1为2的0次,16为2的4次。
imgsz表示送入训练的图像大小,会统一进行缩放。要求是32的整数倍,尽量和图像本身大小一致。
device指训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为device=0,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=cpu 使用 CPU 进行训练。
workers是指数据装载时cpu所使用的线程数,默认为8,过高时会报错:[WinError 1455] 页面文件太小,无法完成操作,此时就只能将workers调成0了。
模型训练的相关基本参数就是这些啦,其余的参数可以等到后期训练完成进行调参时再详细了解。
5.模型训练和测试
模型训练
由于YOLOv10未提供单独的训练程序用于训练,而只是使用命令行进行训练,此处提供两种训练方法,一是在终端使用命令行进行训练;二是新建训练程序,配置参数进行训练。
(1)、在终端使用命令行进行训练
打开终端或新建终端后,输入命令:
yolo detect train data=data.yaml model=yolov10n-test.yaml epochs=300 batch=16 imgsz=640 device=0 workers=8
(2)、新建训练程序,配置参数进行训练
在项目根目录下新建train.py文件,输入以下内容后运行当前文件即可开始训练。
from ultralytics import YOLOv10
# 加载模型
model = YOLOv10("yolov10n-test.yaml") # 模型结构
model = YOLOv10("weights/yolov10n.pt") # 加载预训练权重
if __name__ == '__main__':
model.train(data="data.yaml", imgsz=640, batch=32, epochs=300, workers=8) # 训练模型
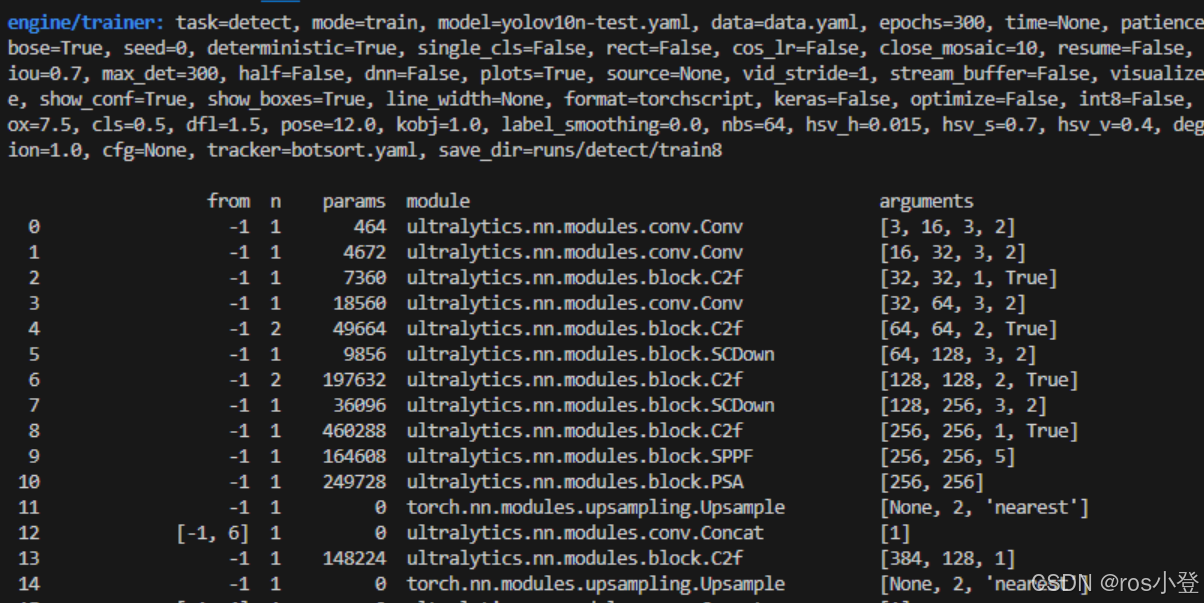

训练完成后,将会在runs/detect/train/weights文件夹下存放训练后的权重文件。
模型测试
(1)、在终端使用命令行进行测试
打开终端或新建终端后,输入命令:
yolo detect val data=data.yaml model=runs/detect/train/weights/best.pt batch=16 imgsz=640 split=test device=0 workers=8
(2)、新建训练程序,配置参数进行训练
在项目根目录下新建val.py文件,输入以下内容后运行当前文件即可开始测试。
from ultralytics import YOLOv10
def main():
# 加载模型,split='test'利用测试集进行测试
model = YOLOv10(r"runs/detect/train/weights/best.pt")
model.val(data="data.yaml", split='test', imgsz=640, batch=16, device=0, workers=8) #模型验证
if __name__ == "__main__":
main()
6.labelimg安装
2. 使用labelimg标注数据集转.xml格式
(1)安装并打开labelimg
① 在conda创建新环境labelimg,指令如下:
conda create -n labelimg python=3.9
② 激活lalelimg环境,指令如下:
conda activate labelimg
③ 在此环境下安装labelimg,指令可如下:
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple #不推荐,会出现依赖缺失或者版本不匹配问题
pip install labelimg #推荐用此方法安装
④ 打开labelimg,指令如下:
labelimg
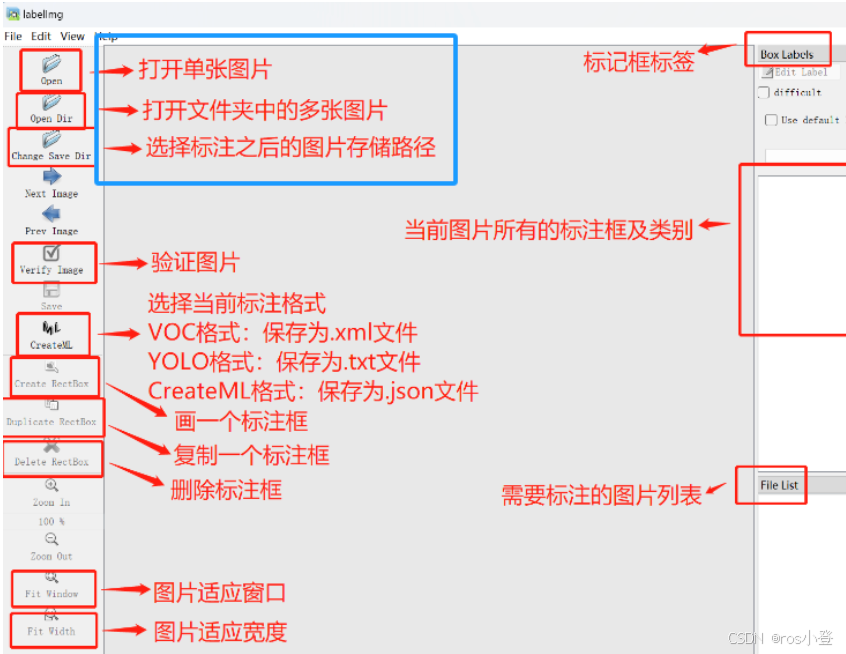
(2) 使用介绍:
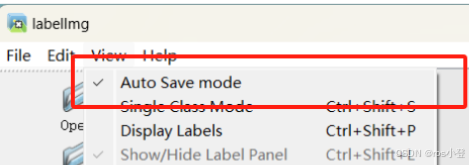
建议勾选上自动保存
数据集划分相关步骤:
Ⅰ选择PascalVOC(即.xml格式)
Ⅱ 点击Open Dir打开文件夹D:\ultralytics-main\data\images中的.jpg格式的图片
Ⅲ Change Save Dir选择文件夹D:\ultralytics-main\data\Annotations
Ⅳ 打好标签以后若先前勾选View-Auto Save mode选项即可自动保存

提供的一些简单代码
A. 可以打开电脑摄像头,加载训练好的模型进行识别——这个代码可以加载GPU,确保模型可以在可用的 GPU 上运行以提高处理速度。
import cv2
from ultralytics import YOLOv10
import time
import torch
import numpy as np
def main():
# 确保使用GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 为不同类别设置固定颜色 (BGR格式),可以自行更改
COLOR_MAP = {
'A': (255, 0, 0), # 蓝色
'B': (0, 255, 0), # 绿色
'red': (0, 0, 255) # 红色
}
# 加载模型并移至GPU
model = YOLOv10(r"runs/detect/train3/weights/best.pt")
model.to(device)
# 设置推理参数
model.conf = 0.1 # 置信度阈值
model.iou = 0.3 # NMS IOU阈值
model.agnostic = False # NMS类别不敏感
model.max_det = 300 # 最大检测数量
# 打开摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
cap.set(cv2.CAP_PROP_FPS, 60) # 设置帧率
# 检查摄像头
if not cap.isOpened():
print("无法打开摄像头")
return
# 创建窗口
cv2.namedWindow('YOLOv10 Detection', cv2.WINDOW_NORMAL)
# 初始化FPS计算
fps_start_time = time.time()
fps = 0
frame_count = 0
# 添加暂停标志
is_paused = False
print("键盘控制说明:")
print("'q': 退出程序")
print("'s': 保存当前帧")
print("'p': 暂停/继续")
print("'c': 清除所有标注")
# ... 前面的代码保持不变 ...
try:
while True:
if not is_paused:
ret, frame = cap.read()
if not ret:
print("无法读取摄像头画面")
break
# 开始计时
start_time = time.time()
# 转换图像格式并移至GPU
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 使用GPU进行预测
with torch.no_grad():
results = model.predict(
source=frame_rgb,
stream=True,
device=device,
verbose=False
)
# 处理检测结果
for result in results:
boxes = result.boxes
print(f"检测到 {len(boxes)} 个物体") # 调试信息
if len(boxes) > 0: # 如果检测到物体
for box in boxes:
# 获取边界框坐标
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy()
x1, y1, x2, y2 = map(int, [x1, y1, x2, y2])
# 获取置信度和类别
conf = float(box.conf)
cls = int(box.cls)
cls_name = result.names[cls]
print(f"类别: {cls_name}, 置信度: {conf:.2f}") # 调试信息
# 使用颜色映射中的固定颜色
color = COLOR_MAP.get(cls_name, (255, 255, 255))
# 确保坐标在有效范围内
x1, y1 = max(0, x1), max(0, y1)
x2, y2 = min(frame.shape[1], x2), min(frame.shape[0], y2)
# 绘制边界框
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
# 添加标签文本
label = f'{cls_name} {conf:.2f}'
t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.6, 1)[0]
c2 = x1 + t_size[0], y1 - t_size[1] - 3
cv2.rectangle(frame, (x1, y1), c2, color, -1)
cv2.putText(frame, label, (x1, y1-2),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,255,255), 1)
# ... 后面的代码保持不变 ...
# 计算和显示FPS
frame_count += 1
if frame_count >= 30:
fps = frame_count / (time.time() - fps_start_time)
fps_start_time = time.time()
frame_count = 0
# 显示FPS和设备信息
cv2.putText(frame, f'FPS: {fps:.1f}', (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(frame, f'Device: {device}', (10, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
# 如果暂停,显示暂停状态
if is_paused:
cv2.putText(frame, 'PAUSED', (10, 90),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
# 显示处理后的帧
cv2.imshow('YOLOv10 Detection', frame)
# 扩展的键盘控制
key = cv2.waitKey(1) & 0xFF
if key == ord('q'): # 退出
print("程序退出")
break
elif key == ord('s'): # 保存当前帧
filename = f'detection_{time.strftime("%Y%m%d_%H%M%S")}.jpg'
cv2.imwrite(filename, frame)
print(f"已保存图片: {filename}")
elif key == ord('p'): # 暂停/继续
is_paused = not is_paused
print("暂停" if is_paused else "继续")
elif key == ord('c'): # 清除所有标注
frame = cap.read()[1]
print("已清除所有标注")
finally:
# 释放资源
cap.release()
cv2.destroyAllWindows()
torch.cuda.empty_cache() # 清理GPU缓存
if __name__ == "__main__":
main()B. xml文件批量转txt文件
import os
import xml.etree.ElementTree as ET
def convert_xml_to_txt(xml_folder, txt_folder, classes):
if not os.path.exists(txt_folder):
os.makedirs(txt_folder)
for xml_file in os.listdir(xml_folder):
if not xml_file.endswith('.xml'):
continue
tree = ET.parse(os.path.join(xml_folder, xml_file))
root = tree.getroot()
txt_file_path = os.path.join(txt_folder, xml_file.replace('.xml', '.txt'))
with open(txt_file_path, 'w') as txt_file:
for obj in root.findall('object'):
class_name = obj.find('name').text
if class_name not in classes:
continue
class_id = classes.index(class_name)
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
# 获取图像的宽度和高度
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
# 转换为YOLO格式
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
box_width = (xmax - xmin) / width
box_height = (ymax - ymin) / height
txt_file.write(f"{class_id} {x_center} {y_center} {box_width} {box_height}\n")
if __name__ == "__main__":
xml_folder = 'C:\\Users\\24824\\Desktop\\智能车标签\\Annotations'
txt_folder = 'D:\\yolov10\\data\\labels'
classes = ['A', 'B', 'red'] # 替换为你的类别名称
convert_xml_to_txt(xml_folder, txt_folder, classes)
#xml_folder 是存放XML文件的目录。
# txt_folder 是输出TXT文件的目录。
# classes 是一个列表,包含所有可能的类别名称。请根据你的数据集替换为实际的类别名称。
# 运行此脚本后,TXT文件将以YOLO格式生成,适用于YOLOv10的训练。零基础新手常遇到的问题:
1.time.out 安装时报错,此时换源安装,如果你在使用 pip 安装 Python 包,可以通过如下命令更换源:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple package_name
此处后续还会跟进
1. 清华大学开源软件镜像源- 网址: 清华大学开源镜像源
https://mirrors.tuna.tsinghua.edu.cn/2. 阿里云开源软件镜像源- 网址: 阿里云开源镜像源
https://mirrors.aliyun.com/3. 中国科学技术大学开源软件镜像源- 网址: 中国科学技术大学开源镜像源
https://mirrors.ustc.edu.cn/
以上就是YOLOv10训练自己数据集的全部过程

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 66
66 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)