【图像分割】2021-SegFormer NeurIPS
SegFormer论文详解,2021CVPR收录,将Transformer与语义分割相结合的作品,动机来源有:SETR中使用VIT作为backbone提取的特征较为单一,PE限制预测的多样性,传统CNN的Decoder来恢复特征过程较为复杂。主要提出多层次的Transformer-Encoder和MLP-Decoder,性能达到SOTA。SegFormer是一个将transformer与轻量级多层
文章目录
【图像分割】2021-SegFormer NeurIPS
论文题目: SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
论文地址:https://arxiv.org/abs/2105.15203v3
代码地址: https://github.com/NVlabs/SegFormer
论文团队:香港大学, 南京大学, NVIDIA, Caltech
SegFormer论文详解,2021CVPR收录,将Transformer与语义分割相结合的作品,
1. 简介
1.1 简介
- 2021可以说是分割算法爆发的一年,首先
ViT通过引入transform将ADE20K mIOU精度第一次刷到50%,超过了之前HRnet+OCR效果, - 然后再是
Swin屠榜各大视觉任务,在分类,语义分割和实例分割都做到了SOTA,斩获ICCV2021的bset paper, - 然后Segformer有凭借对transform再次深层次优化,在拿到更高精度的基础之上还大大提升了模型的实时性。
动机来源有:SETR中使用VIT作为backbone提取的特征较为单一,PE限制预测的多样性,传统CNN的Decoder来恢复特征过程较为复杂。主要提出多层次的Transformer-Encoder和MLP-Decoder,性能达到SOTA。
1.2 解决的问题
SegFormer是一个将transformer与轻量级多层感知器(MLP)解码器统一起来的语义分割框架。SegFormer的优势在于:
- SegFormer设计了一个新颖的分级结构transformer编码器,输出多尺度特征。它不需要位置编码,从而避免了位置编码的插值(当测试分辨率与训练分辨率不同时,会导致性能下降)。
- SegFormer避免了复杂的解码器。提出的MLP解码器从不同的层聚合信息,从而结合局部关注和全局关注来呈现强大的表示。作者展示了这种简单和轻量级的设计是有效分割transformer的关键。
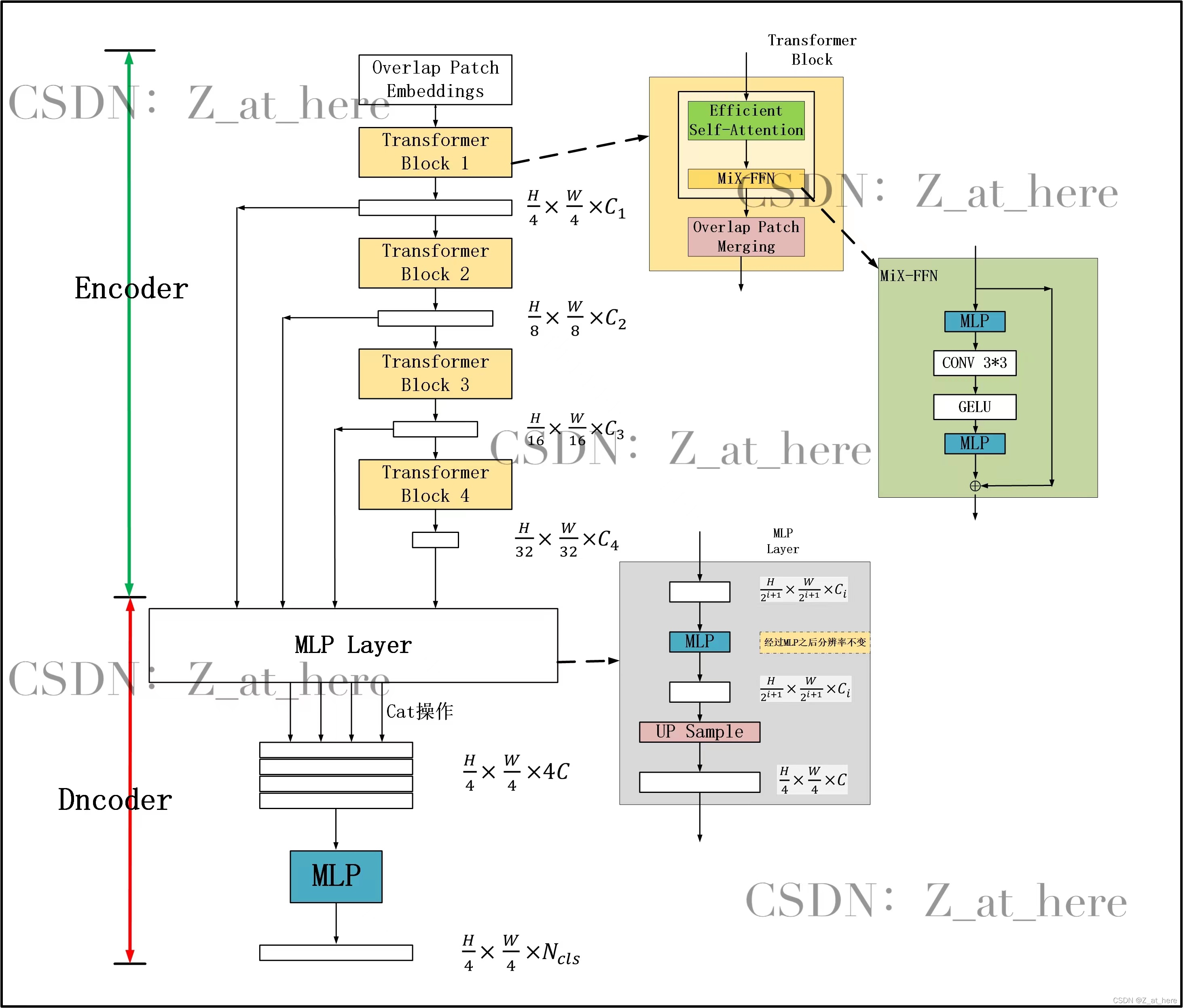
2. 网络
2.1 架构
1) 总体结构
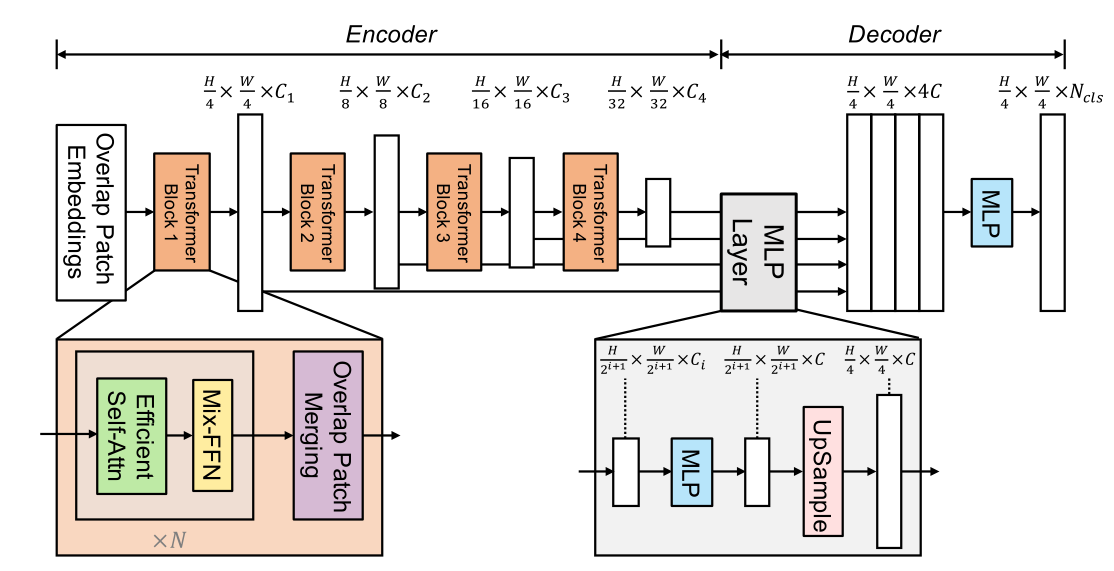
这种架构类似于ResNet,Swin-Transformer。经过一个阶段,
-
编码器:一个分层的Transformer编码器,用于生成高分辨率的粗特征和低分辨率的细特征
由Transformer blocks*N 组成一个单独的阶段(stage)。
一个Transformer block 由3个部分组成
- Overlap Patch Merging
- Mix-FFN
- Effcient Self-Atten
-
解码器:一个轻量级的All-MLP解码器,融合这些多级特征,产生最终的语义分割掩码。
2) 编码器MiT backbone
下面是SegFormer的编码器的具体配置
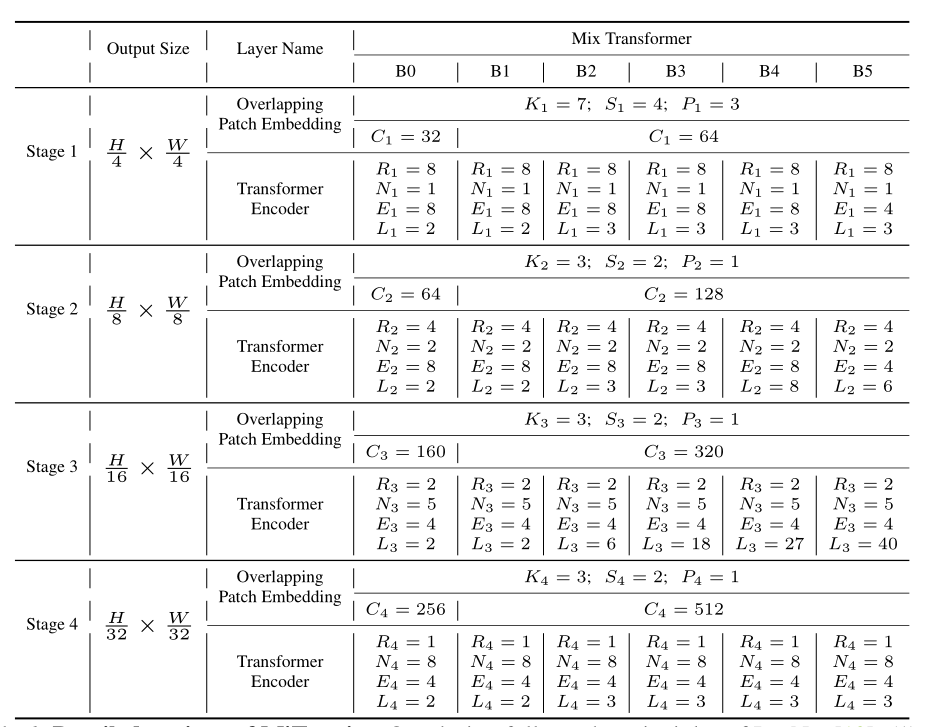
3) 分层结构
与只能生成单分辨率特征图的ViT不同,该模块的目标是对给定输入图像生成类似cnn的多级特征。这些特征提供了高分辨率的粗特征和低分辨率的细粒度特征,通常可以提高语义分割的性能。
更准确地说,给定一个分辨率为 H × W × 3 H\times W\times 3 H×W×3。我们进行patch合并,得到一个分辨率为 ( H 2 i + 1 × W 2 i + 1 × C ) (\frac{H}{2^{i+1}}\times \frac{W}{2^{i+1}}\times C) (2i+1H×2i+1W×C)的层次特征图 F i F_i Fi,其中 i ∈ { 1 , 2 , 3 , 4 } i\in\{1,2,3,4\} i∈{1,2,3,4}。
举个例子,经过一个阶段 F 1 = ( H 4 × W 4 × C ) → F 2 = ( H 8 × W 8 × C ) F_1=(\frac{H}{4}\times \frac{W}{4}\times C) \to F_2=(\frac{H}{8}\times \frac{W}{8}\times C) F1=(4H×4W×C)→F2=(8H×8W×C)
2.2 分层的Transformer 编码器(MiT)
编码器由3个部分组成,首先讲一下,下采样模块
1) Overlap Patch Merging
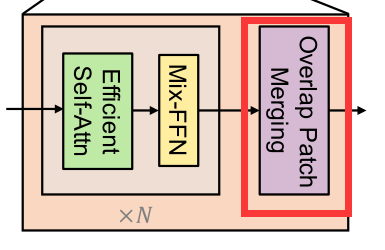
对于一个映像patch,ViT中使用的patch合并过程将一个 N × N × 3 N\times N\times 3 N×N×3的图像统一成 1 × 1 × C 1\times 1\times C 1×1×C向量。这可以很容易地扩展到将一个 2 × 2 × C i 2\times 2\times C_i 2×2×Ci特征路径统一到一个 1 × 1 × C i + 1 1\times 1\times C_{i+1} 1×1×Ci+1向量中,以获得分层特征映射。
使用此方法,可以将层次结构特性从 F 1 = ( H 4 × W 4 × C ) → F 2 = ( H 8 × W 8 × C ) F_1=(\frac{H}{4}\times \frac{W}{4}\times C) \to F_2=(\frac{H}{8}\times \frac{W}{8}\times C) F1=(4H×4W×C)→F2=(8H×8W×C)。然后迭代层次结构中的任何其他特性映射。这个过程最初的设计是为了结合不重叠的图像或特征块。因此,它不能保持这些斑块周围的局部连续性。相反,我们使用重叠补丁合并过程。因此,论文作者分别通过设置K,S,P为(7,4,3)(3,2,1)的卷积来进行重叠的Patch merging。其中,K为kernel,S为Stride,P为padding。
说的这么花里胡哨的,其实作用就是
和MaxPooling一样,起到下采样的效果。使得特征图变成原来的 1 2 \frac{1}{2} 21
import torch
import torch.nn as nn
from torch import Tensor
class patchembed(nn.Module):
def __init__(self, c1=3, c2=32, patch_size=7, stride=4):
"""
:param c1: 输入通道数
:param c2: 输出通道数
:param patch_size:
:param stride:
"""
super().__init__()
self.proj = nn.Conv2d(c1, c2, patch_size, stride, patch_size // 2) # padding=(ps[0]//2, ps[1]//2)
self.norm = nn.LayerNorm(c2)
def forward(self, x: Tensor) -> Tensor:
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
# 可以看出, 输入是3通道
model=patchembed(c1=3, c2=32, patch_size=7, stride=4)
# 返回的结果是[ batch_size, 下采样完的宽* 下采样完的高,输出通道数]
x, H, W=model(x)
print(x.shape)# torch.Size([1, 3136, 32])
print(H,W)# 56 56 224
# 下采样4倍就是56
2) Efficient Self-Attention
编码器的主要计算瓶颈是自注意层。在原来的多头自注意过程中,每个头 K , Q , V K,Q,V K,Q,V都有相同的维数 N × C N\times C N×C,其中 N = H × W N=H\times W N=H×W为序列的长度,估计自注意为:
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d h e a d ) V Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_{head}}})V Attention(Q,K,V)=Softmax(dheadQKT)V
这个过程的计算复杂度是 O ( N 2 ) O(N^2) O(N2),这对于大分辨率的图像来说是巨大的。
论文作者认为,网络的计算量主要体现在自注意力机制层上。为了降低网路整体的计算复杂度,论文作者在自注意力机制的基础上,添加的缩放因子 R R R,来降低每一个自注意力机制模块的计算复杂度。
K ^ = R e s h a p e ( N R , C ⋅ R ) ( K ) K = L i n e a r ( C ⋅ R , C ) ( K ^ ) \begin{aligned} \hat{K}&=Reshape(\frac{N}{R},C\cdot R)(K) \\ K&=Linear(C\cdot R,C)(\hat{K}) \end{aligned} K^K=Reshape(RN,C⋅R)(K)=Linear(C⋅R,C)(K^)
其中第一步将 K K K的形状由 N × C N\times C N×C转变为 N R × ( C ⋅ R ) \frac{N}{R}\times(C\cdot R) RN×(C⋅R),
第二步又将 K K K的形状由 N R × ( C ⋅ R ) \frac{N}{R}\times(C\cdot R) RN×(C⋅R)转变为 N R × C \frac{N}{R}\times C RN×C。因此,计算复杂度就由 O ( N 2 ) O(N^2) O(N2)降至 O ( N 2 R ) O(\frac{N^2}{R}) O(RN2)。在作者给出的参数中,阶段1到阶段4的 R R R分别为 [ 64 , 16 , 4 , 1 ] [64,16,4,1] [64,16,4,1]
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
class Attention(nn.Module):
def __init__(self, dim, head, sr_ratio):
"""
注意力头
:param dim: 输入维度
:param head: 注意力头数目
:param sr_ratio: 缩放倍数
"""
super().__init__()
self.head = head
self.sr_ratio = sr_ratio
self.scale = (dim // head) ** -0.5
self.q = nn.Linear(dim, dim)
self.kv = nn.Linear(dim, dim * 2)
self.proj = nn.Linear(dim, dim)
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, sr_ratio, sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x: Tensor, H, W) -> Tensor:
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.head, C // self.head).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.sr(x).reshape(B, C, -1).permute(0, 2, 1)
x = self.norm(x)
k, v = self.kv(x).reshape(B, -1, 2, self.head, C // self.head).permute(2, 0, 3, 1, 4)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x
if __name__ == '__main__':
#
# x=torch.randn(1,3,224,224)
# model=patchembed(c1=3, c2=32, patch_size=7, stride=4)
# x, H, W=model(x)
# 这里是 1,3,224,224 经过一个patchembed 的操作,进行了一个4 倍的下采样
# 所以出来的结果为[1,3136,32]
# [ batch_size=1, 下采样完的宽* 下采样完的高=56*56=3136 ,输出通道数=32]
x = torch.randn(1, 3136, 32)
H, W = 56, 56
model = Attention(dim=32, head=8, sr_ratio=4)
y = model(x, H, W)
print(y.shape)# torch.Size([1, 3136, 32])
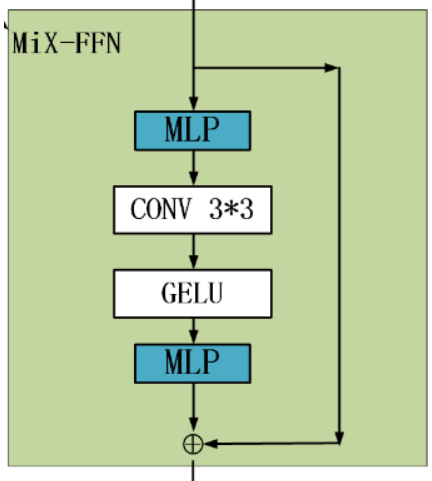
3) Mix-FFN
VIT使用位置编码PE(Position Encoder)来插入位置信息,但是插入的PE的分辨率是固定的,这就导致如果训练图像和测试图像分辨率不同的话,需要对PE进行插值操作,这会导致精度下降。
为了解决这个问题CPVT(Conditional positional encodings for vision transformers. arXiv, 2021)使用了3X3的卷积和PE一起实现了data-driver PE。
引入了一个 Mix-FFN,考虑了padding对位置信息的影响,直接在 FFN (feed-forward network)中使用 一个3x3 的卷积,MiX-FFN可以表示如下:
X o u t = M L P ( G E L U ( C o n v 3 × 3 ( M L P ( X i n ) ) ) ) + X i n X_{out}=MLP(GELU(Conv_{3\times3}(MLP(X_{in}))))+X_{in} Xout=MLP(GELU(Conv3×3(MLP(Xin))))+Xin
其中 X i n X_{in} Xin是从self-attention中输出的feature。Mix-FFN混合了一个 3 ∗ 3 3*3 3∗3的卷积和MLP在每一个FFN中。即根据上式可以知道MiX-FFN的顺序为:输入经过MLP,再使用 C o n v 3 × 3 Conv_{3\times3} Conv3×3操作,正在经过一个GELU激活函数,再通过MLP操作,最后将输出和原始输入值进行叠加操作,作为MiX-FFN的总输出。
在实验中作者展示了 3 ∗ 3 3*3 3∗3的卷积可以为transformer提供PE。作者还是用了深度可以分离卷积提高效率,减少参数。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
class DWConv(nn.Module):
"""
深度可分离卷积。
"""
def __init__(self, dim):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)
def forward(self, x: Tensor, H, W) -> Tensor:
B, _, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
return x.flatten(2).transpose(1, 2)
class MLP(nn.Module):
def __init__(self, c1, c2):
super().__init__()
self.fc1 = nn.Linear(c1, c2)
self.dwconv = DWConv(c2)
self.fc2 = nn.Linear(c2, c1)
def forward(self, x: Tensor, H, W) -> Tensor:
return self.fc2(F.gelu(self.dwconv(self.fc1(x), H, W)))
if __name__ == '__main__':
x=torch.randn(1,3136, 64)
H,W=56,56
model=MLP(64,128)
y=model(x,H,W)
print(y.shape)
2.3 轻量级MLP解码器
SegFormer集成了一个轻量级解码器,只包含MLP层。实现这种简单解码器的关键是,SegFormer的分级Transformer编码器比传统CNN编码器具有更大的有效接受域(ERF)。
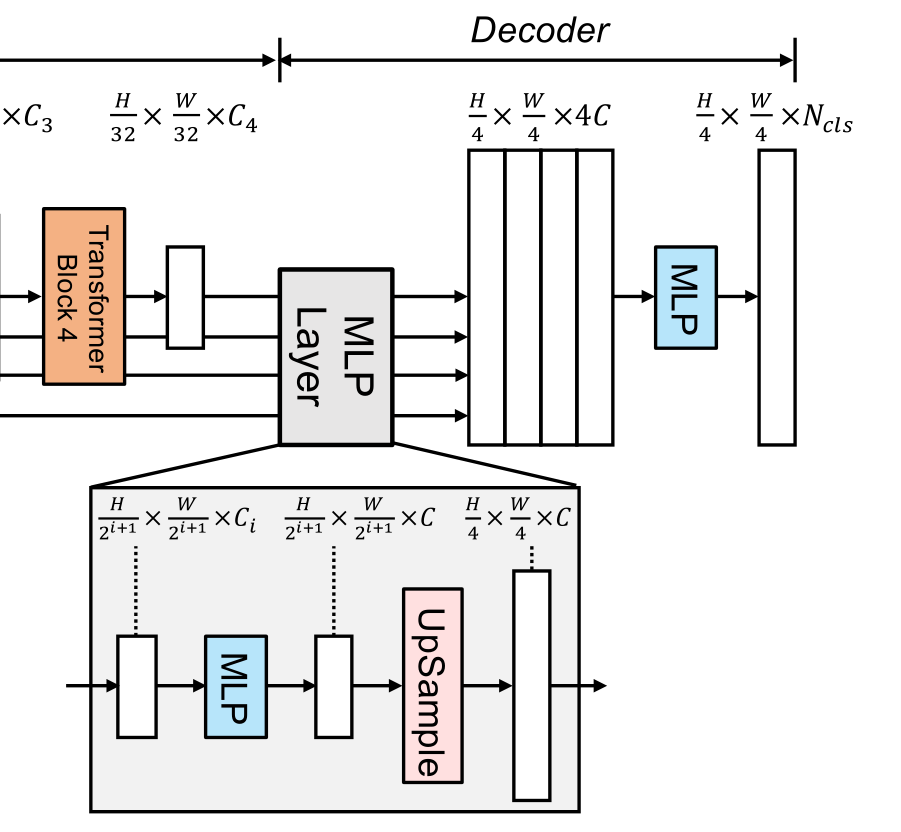
SegFormer所提出的全mlp译码器由四个主要步骤组成。
- 来自MiT编码器的多级特性通过MLP层来统一通道维度。
- 特征被上采样到1/4并连接在一起。
- 采用MLP层融合级联特征 F F F
- 另一个MLP层采用融合的 H 4 × W 4 × N c l s \frac{H}{4}\times \frac{W}{4}\times N_{cls} 4H×4W×Ncls分辨率特征来预测分割掩码 M M M,其中表示类别数目
解码器可以表述为:
F ^ i = L i n e a r ( C i , C ) ( F i ) , ∀ i F ^ i = U p s a m p l e ( W 4 × W 4 ) ( F ^ i ) , ∀ i F = L i n e a r ( 4 C , C ) ( C o n c a t ( F ^ i ) ) , ∀ i M = L i n e a r ( C , N c l s ) ( F ) \begin{aligned} \hat{F}_i&=Linear(C_i,C)(F_i),\forall i \\ \hat{F}_i&=Upsample(\frac{W}{4}\times \frac{W}{4})(\hat{F}_i),\forall i \\ F&=Linear(4C,C)(Concat(\hat{F}_i)),\forall i \\ M&=Linear(C,N_{cls})(F) \end{aligned} F^iF^iFM=Linear(Ci,C)(Fi),∀i=Upsample(4W×4W)(F^i),∀i=Linear(4C,C)(Concat(F^i)),∀i=Linear(C,Ncls)(F)
2.4 有效接受视野(ERF)
这个部分是 用来证明 解码器是非常有效的
对于语义分割,保持较大的接受域以包含上下文信息一直是一个中心问题。SegFormer使用有效接受域(ERF)作为一个工具包来可视化和解释为什么All-MLP译码器设计在TransFormer上如此有效。在下图中可视化了DeepLabv3+和SegFormer的四个编码器阶段和解码器头的ERF:
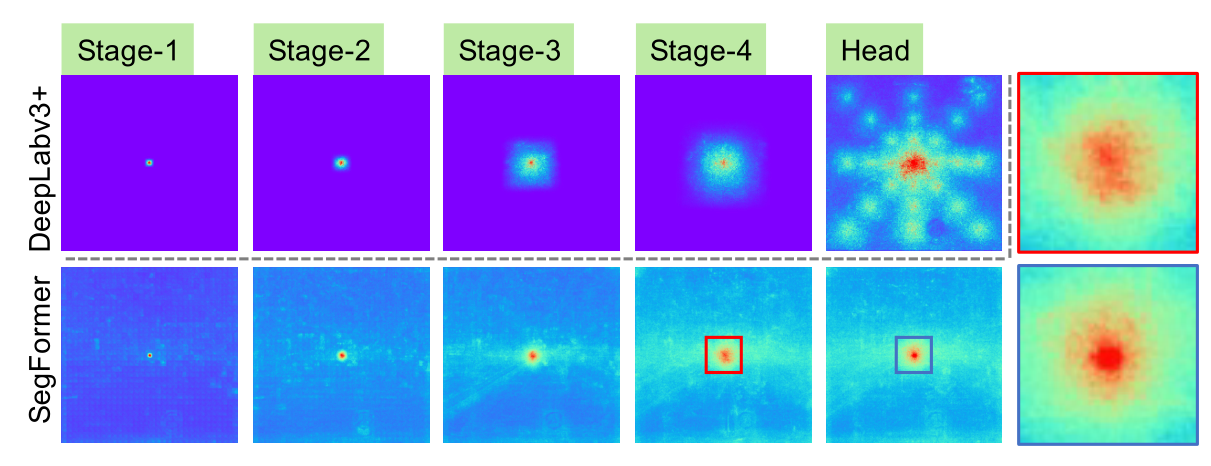
从上图中可以观察到:
- DeepLabv3+的ERF即使在最深层的Stage4也相对较小。
- SegFormer编码器自然产生局部注意,类似于较低阶段的卷积,同时能够输出高度非局部注意,有效捕获Stage4的上下文。
- 如放大Patch所示,MLP头部的ERF(蓝框)与Stage4(红框)不同,其非局部注意力和局部注意力显著增强。
CNN的接受域有限,需要借助语境模块扩大接受域,但不可避免地使网络变复杂。All-MLP译码器设计得益于transformer中的非局部注意力,并在不复杂的情况下导致更大的接受域。然而,同样的译码器设计在CNN主干上并不能很好地工作,因为整体的接受域是在Stage4的有限域的上限。
更重要的是,All-MLP译码器设计本质上利用了Transformer诱导的特性,同时产生高度局部和非局部关注。通过统一它们,All-MLP译码器通过添加一些参数来呈现互补和强大的表示。这是推动我们设计的另一个关键原因。
3. 代码
下面展示的SegFormer 的Bo版本。其他版本,可以自己调整
import torch
from torch import nn, Tensor
from typing import Tuple
from torch.nn import functional as F
import warnings
import math
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
Copied from timm
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
def __init__(self, p: float = None):
super().__init__()
self.p = p
def forward(self, x: Tensor) -> Tensor:
if self.p == 0. or not self.training:
return x
kp = 1 - self.p
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = kp + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
return x.div(kp) * random_tensor
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
# Cut & paste from PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
def norm_cdf(x):
# Computes standard normal cumulative distribution function
return (1. + math.erf(x / math.sqrt(2.))) / 2.
if (mean < a - 2 * std) or (mean > b + 2 * std):
warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
"The distribution of values may be incorrect.",
stacklevel=2)
with torch.no_grad():
# Values are generated by using a truncated uniform distribution and
# then using the inverse CDF for the normal distribution.
# Get upper and lower cdf values
l = norm_cdf((a - mean) / std)
u = norm_cdf((b - mean) / std)
# Uniformly fill tensor with values from [l, u], then translate to
# [2l-1, 2u-1].
tensor.uniform_(2 * l - 1, 2 * u - 1)
# Use inverse cdf transform for normal distribution to get truncated
# standard normal
tensor.erfinv_()
# Transform to proper mean, std
tensor.mul_(std * math.sqrt(2.))
tensor.add_(mean)
# Clamp to ensure it's in the proper range
tensor.clamp_(min=a, max=b)
return tensor
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
# type: (Tensor, float, float, float, float) -> Tensor
r"""Fills the input Tensor with values drawn from a truncated
normal distribution. The values are effectively drawn from the
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
with values outside :math:`[a, b]` redrawn until they are within
the bounds. The method used for generating the random values works
best when :math:`a \leq \text{mean} \leq b`.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
"""
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
############################################
# backbone 部分
class Attention(nn.Module):
def __init__(self, dim, head, sr_ratio):
"""
注意力头
:param dim: 输入维度
:param head: 注意力头数目
:param sr_ratio: 缩放倍数
"""
super().__init__()
self.head = head
self.sr_ratio = sr_ratio
self.scale = (dim // head) ** -0.5
self.q = nn.Linear(dim, dim)
self.kv = nn.Linear(dim, dim * 2)
self.proj = nn.Linear(dim, dim)
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, sr_ratio, sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x: Tensor, H, W) -> Tensor:
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.head, C // self.head).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.sr(x).reshape(B, C, -1).permute(0, 2, 1)
x = self.norm(x)
k, v = self.kv(x).reshape(B, -1, 2, self.head, C // self.head).permute(2, 0, 3, 1, 4)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x
class DWConv(nn.Module):
"""
深度可分离卷积。
"""
def __init__(self, dim):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)
def forward(self, x: Tensor, H, W) -> Tensor:
B, _, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
return x.flatten(2).transpose(1, 2)
class MLP(nn.Module):
def __init__(self, c1, c2):
super().__init__()
self.fc1 = nn.Linear(c1, c2)
self.dwconv = DWConv(c2)
self.fc2 = nn.Linear(c2, c1)
def forward(self, x: Tensor, H, W) -> Tensor:
return self.fc2(F.gelu(self.dwconv(self.fc1(x), H, W)))
class PatchEmbed(nn.Module):
def __init__(self, c1=3, c2=32, patch_size=7, stride=4):
"""
下采样模块
:param c1: 输入通道数
:param c2: 输出通道数
:param patch_size: patch 大小
:param stride: 下采样倍数
"""
super().__init__()
self.proj = nn.Conv2d(c1, c2, patch_size, stride, patch_size // 2) # padding=(ps[0]//2, ps[1]//2)
self.norm = nn.LayerNorm(c2)
def forward(self, x: Tensor) -> Tensor:
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class Block(nn.Module):
def __init__(self, dim, head, sr_ratio=1, dpr=0.):
"""
这是一个标准的transformer block。
:param dim: 输入维度
:param head: 注意力头的维度
:param sr_ratio:
:param dpr:
"""
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = Attention(dim, head, sr_ratio)
self.drop_path = DropPath(dpr) if dpr > 0. else nn.Identity()
self.norm2 = nn.LayerNorm(dim)
self.mlp = MLP(dim, int(dim * 4))
def forward(self, x: Tensor, H, W) -> Tensor:
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
mit_settings = {
'B0': [[32, 64, 160, 256], [2, 2, 2, 2]], # [embed_dims, depths]
'B1': [[64, 128, 320, 512], [2, 2, 2, 2]],
'B2': [[64, 128, 320, 512], [3, 4, 6, 3]],
'B3': [[64, 128, 320, 512], [3, 4, 18, 3]],
'B4': [[64, 128, 320, 512], [3, 8, 27, 3]],
'B5': [[64, 128, 320, 512], [3, 6, 40, 3]]
}
class MiT(nn.Module):
def __init__(self, model_name: str = 'B0'):
super().__init__()
assert model_name in mit_settings.keys(), f"MiT model name should be in {list(mit_settings.keys())}"
embed_dims, depths = mit_settings[model_name]
drop_path_rate = 0.1
self.embed_dims = embed_dims
# patch_embed
self.patch_embed1 = PatchEmbed(3, embed_dims[0], 7, 4)
self.patch_embed2 = PatchEmbed(embed_dims[0], embed_dims[1], 3, 2)
self.patch_embed3 = PatchEmbed(embed_dims[1], embed_dims[2], 3, 2)
self.patch_embed4 = PatchEmbed(embed_dims[2], embed_dims[3], 3, 2)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
self.block1 = nn.ModuleList([Block(embed_dims[0], 1, 8, dpr[cur + i]) for i in range(depths[0])])
self.norm1 = nn.LayerNorm(embed_dims[0])
cur += depths[0]
self.block2 = nn.ModuleList([Block(embed_dims[1], 2, 4, dpr[cur + i]) for i in range(depths[1])])
self.norm2 = nn.LayerNorm(embed_dims[1])
cur += depths[1]
self.block3 = nn.ModuleList([Block(embed_dims[2], 5, 2, dpr[cur + i]) for i in range(depths[2])])
self.norm3 = nn.LayerNorm(embed_dims[2])
cur += depths[2]
self.block4 = nn.ModuleList([Block(embed_dims[3], 8, 1, dpr[cur + i]) for i in range(depths[3])])
self.norm4 = nn.LayerNorm(embed_dims[3])
def forward(self, x: Tensor) -> Tensor:
B = x.shape[0]
# stage 1
x, H, W = self.patch_embed1(x)
# torch.Size([1, 3136, 64])
for blk in self.block1:
x = blk(x, H, W)
# x= torch.Size([1, 3136, 64])
x1 = self.norm1(x).reshape(B, H, W, -1).permute(0, 3, 1, 2)# ([1, 64, 56, 56])
# stage 2
x, H, W = self.patch_embed2(x1)
for blk in self.block2:
x = blk(x, H, W)
x2 = self.norm2(x).reshape(B, H, W, -1).permute(0, 3, 1, 2)
# stage 3
x, H, W = self.patch_embed3(x2)
for blk in self.block3:
x = blk(x, H, W)
x3 = self.norm3(x).reshape(B, H, W, -1).permute(0, 3, 1, 2)
# stage 4
x, H, W = self.patch_embed4(x3)
for blk in self.block4:
x = blk(x, H, W)
x4 = self.norm4(x).reshape(B, H, W, -1).permute(0, 3, 1, 2)
return x1, x2, x3, x4
############################################
# if __name__ == '__main__':
# model = MiT('B0')
# x = torch.zeros(1, 3, 224, 224)
# outs = model(x)
# for y in outs:
# print(y.shape)
class FFN(nn.Module):
def __init__(self, dim, embed_dim):
super().__init__()
self.proj = nn.Linear(dim, embed_dim)
def forward(self, x: Tensor) -> Tensor:
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
class ConvModule(nn.Module):
def __init__(self, c1, c2):
super().__init__()
self.conv = nn.Conv2d(c1, c2, 1, bias=False)
self.bn = nn.BatchNorm2d(c2) # use SyncBN in original
self.activate = nn.ReLU(True)
def forward(self, x: Tensor) -> Tensor:
return self.activate(self.bn(self.conv(x)))
class SegFormerHead(nn.Module):
def __init__(self, dims: list, embed_dim: int = 256, num_classes: int = 19):
super().__init__()
for i, dim in enumerate(dims):
self.add_module(f"linear_c{i+1}", FFN(dim, embed_dim))
self.linear_fuse = ConvModule(embed_dim*4, embed_dim)
self.linear_pred = nn.Conv2d(embed_dim, num_classes, 1)
self.dropout = nn.Dropout2d(0.1)
def forward(self, features: Tuple[Tensor, Tensor, Tensor, Tensor]) -> Tensor:
B, _, H, W = features[0].shape
outs = [self.linear_c1(features[0]).permute(0, 2, 1).reshape(B, -1, *features[0].shape[-2:])]
for i, feature in enumerate(features[1:]):
cf = eval(f"self.linear_c{i+2}")(feature).permute(0, 2, 1).reshape(B, -1, *feature.shape[-2:])
outs.append(F.interpolate(cf, size=(H, W), mode='bilinear', align_corners=False))
seg = self.linear_fuse(torch.cat(outs[::-1], dim=1))
seg = self.linear_pred(self.dropout(seg))
return seg
segformer_settings = {
'B0': 256, # head_dim
'B1': 256,
'B2': 768,
'B3': 768,
'B4': 768,
'B5': 768
}
class SegFormer(nn.Module):
def __init__(self, variant: str = 'B0', num_classes: int = 19) -> None:
super().__init__()
self.backbone = MiT(variant)
self.decode_head = SegFormerHead(self.backbone.embed_dims, segformer_settings[variant], num_classes)
self.apply(self._init_weights)
def _init_weights(self, m: nn.Module) -> None:
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out // m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2d)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
def init_pretrained(self, pretrained: str = None) -> None:
if pretrained:
self.backbone.load_state_dict(torch.load(pretrained, map_location='cpu'), strict=False)
def forward(self, x: Tensor) -> Tensor:
y = self.backbone(x)
y = self.decode_head(y) # 4x reduction in image size
# 直接做4倍上采样
y = F.interpolate(y, size=x.shape[2:], mode='bilinear', align_corners=False) # to original image shape
return y
if __name__ == '__main__':
model = SegFormer('B2', num_classes=19)
# x = torch.zeros(1, 3, 214,214)
# y = model(x)
# print(y.shape)
from thop import profile
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops / 1e9))
print("params:{:.3f}M".format(params / 1e6))
参考资料
https://blog.csdn.net/weixin_43610114/article/details/125000614
https://blog.csdn.net/weixin_44579633/article/details/121081763
https://blog.csdn.net/qq_39333636/article/details/124334384
语义分割之SegFormer分享_xuzz_498100208的博客-CSDN博客

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)