物理信息强化学习(PIRL)研究进展:顶刊成果与前沿应用解析
在人工智能与控制理论交叉领域,物理信息强化学习(Physics-informed Reinforcement Learning, PIRL)正成为顶会顶刊的高频热点。继近期登上 IEEE Transactions on Systems, Man, and Cybernetics: Systems(IEEE TSE,一区顶刊)后,该方向持续展现出理论创新与工程落地的双重潜力,尤其在数据稀缺、系统动态
在人工智能与控制理论交叉领域,物理信息强化学习(Physics-informed Reinforcement Learning, PIRL)正成为顶会顶刊的高频热点。继近期登上 IEEE Transactions on Systems, Man, and Cybernetics: Systems(IEEE TSE,一区顶刊)后,该方向持续展现出理论创新与工程落地的双重潜力,尤其在数据稀缺、系统动态复杂的场景中优势显著。
一、PIRL 核心优势与研究价值
PIRL 融合了物理规律的严格约束与强化学习的自适应决策能力,突破了传统数据驱动方法对大规模数据的依赖,同时弥补了纯物理模型在复杂动态环境中的局限性。其核心优势体现在:
- 数据高效性:在航空航天、高端装备制造等数据获取成本高昂的领域,通过嵌入物理先验知识(如守恒定律、稳定性条件),大幅减少对训练数据的需求。
- 复杂系统适应性:针对湍流控制、柔性机器人操作等强非线性、高维度动态系统,可通过物理约束正则化策略空间,提升算法鲁棒性。
- 工业落地潜力:在工业自动化、智能交通等场景中,结合实时物理模型与在线优化,实现对复杂流程的精准控制。
方法:论文提出了一种无需模型的物理信息强化学习算法,通过引入Lyapunov稳定性定理和策略迭代算法的收敛条件,利用物理信息神经网络分别逼近值函数和控制策略,旨在解决具有输入约束的非线性系统的最优控制问题。
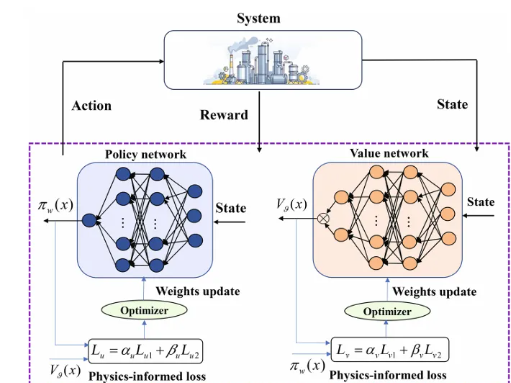
创新点:
-
提出了一种结合物理信息的强化学习算法,用于解决具有输入约束的非线性系统的最优控制问题。
-
开发了一种不依赖于非线性系统的第一性原理或数据驱动模型的强化学习算法,通过迭代学习过程获取接近最优的控制策略。
-
提出了一种新方法,通过设计初始神经网络结构,自动化推导初始可行控制策略。
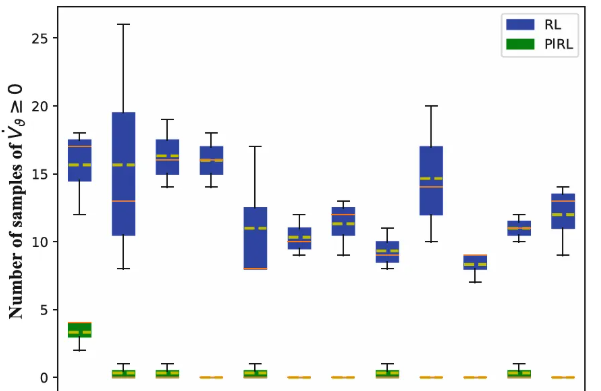
方法:本文提出了一种基于物理信息深度强化学习(DRL)的公交多策略控制系统,通过融合历史数据和实时交通信息,动态调整公交车的停留时间、车速和信号优先权,有效缓解公交串行问题,显著提高公交运行效率和稳定性。
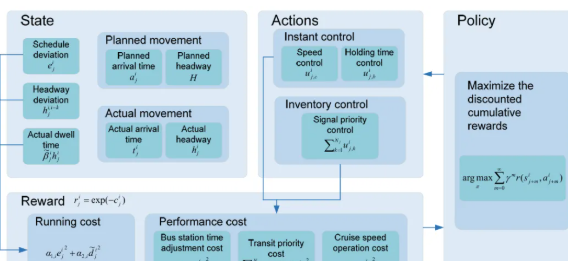
创新点:
-
提出了一种基于分布式深度强化学习(DRL)的多策略融合方法,用于动态公交控制。
-
引入了一种物理信息驱动的DRL状态融合方法,以及一个定制的奖励函数,通过集成先验物理知识来提升多策略控制的效率。
-
开发了一种高效的基于分布式近端策略优化(DPPO)的学习程序,用于训练公交控制模型。
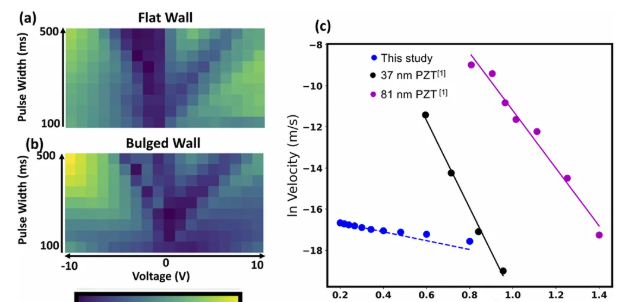
方法:本文通过物理信息强化学习(PIRL)实现了对铁电材料中畴壁的自主设计和操控。利用自主化的压电响应力显微镜(PFM)平台,结合强化学习算法,构建了一个基于物理信息的动态模型(surrogate model),用于预测电场作用下畴壁的响应。
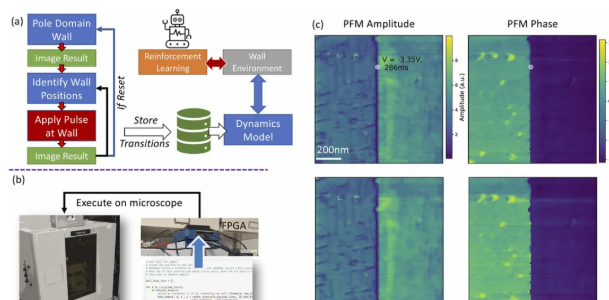
创新点:
-
提出了一种结合物理启发的动态模型和强化学习的方法来自动操控铁电薄膜中畴壁。
-
通过使用代理模型估算系统中的畴壁速度,作者能够在不同电压下预测畴壁的速度。
-
通过PFM图像数据,成功训练了一个动态模型来预测畴壁在不同脉冲下的位移,并利用此模型训练RL代理学习合适的操作策略。
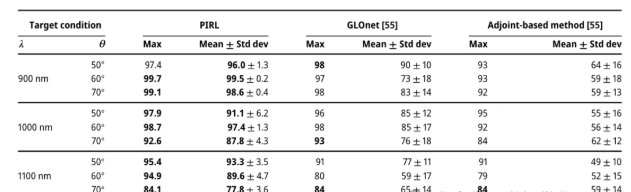
方法:本文研究提出了物理信息强化学习(PIRL)方法,将伴随梯度法与强化学习相结合,以提高采样效率并克服局部最优问题,通过设计一维自适应超表面光束偏转器,展示了PIRL在大规模组合设计空间中的优越性.
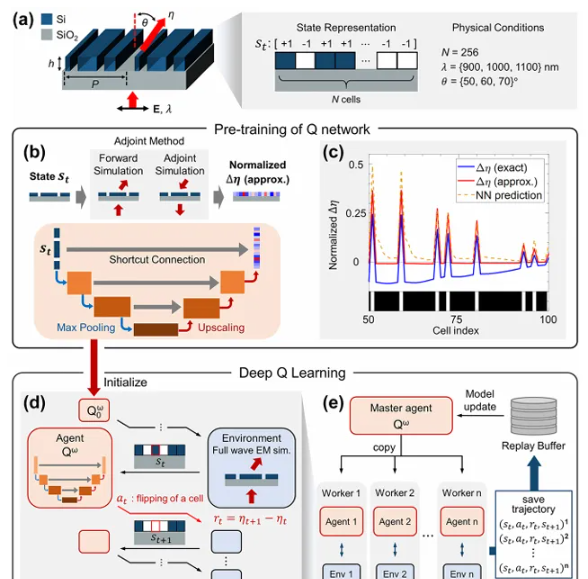
创新点:
-
物理信息强化学习(PIRL)结合了基于伴随法的物理信息与深度强化学习,显著提高了样本效率。
-
在预训练数据集不匹配的情况下,迁移学习仍能在不同的目标偏转角条件下实现与PIRL相当的优化性能。
-
在无信息强化学习中,U-Net通过其固有的网络架构在收敛速度和最终值方面优于全连接网络(FCN)。
谢谢观看!更多论文创新点请关注公-众-号:学长论文指导【回复:977】自取哈~

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)