舰载机自主降落强化学习算法毕业论文【附代码+数据】
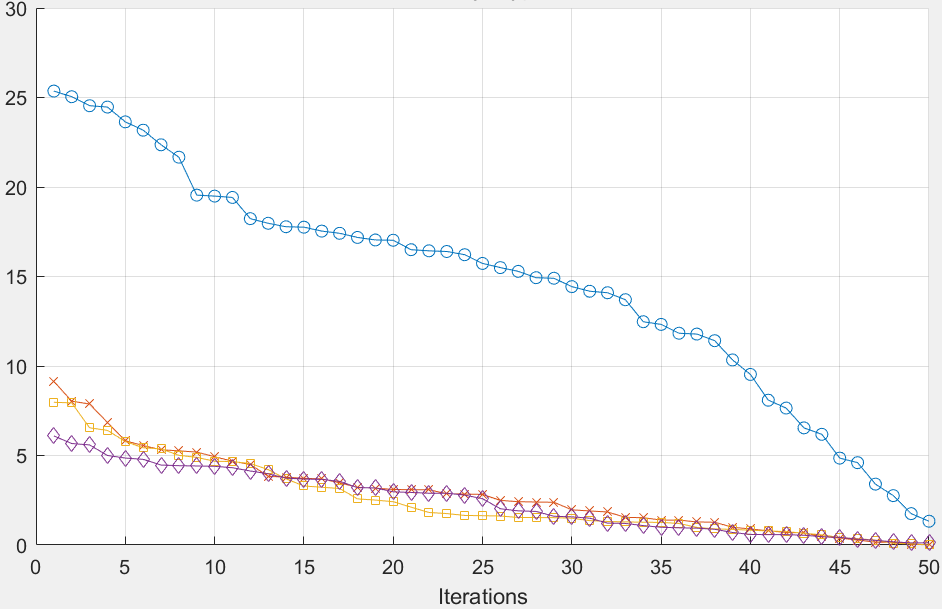
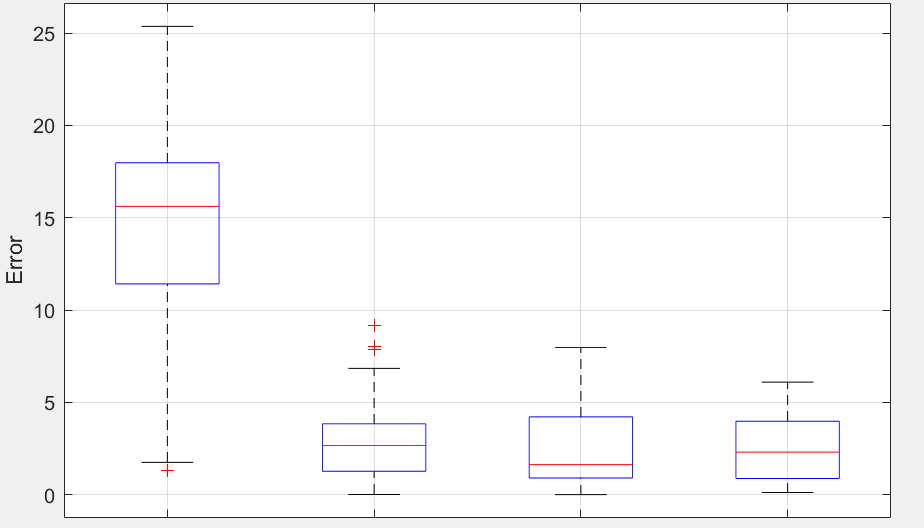
在实验部分,本文首先在MuJoCo基准任务中对IL-Ada CQL算法的性能进行了测试,实验结果表明,IL-Ada CQL在保持Ada CQL算法高效训练的同时,进一步提升了策略的稳定性,尤其是在复杂环境中,IL-Ada CQL展现出了更强的鲁棒性。随后,本文将IL-Ada CQL算法应用于复杂海况下的舰载机自主降落任务中,实验结果显示,IL-Ada CQL能够在显著减少训练数据量的前提下,依然保

✅博主简介:本人擅长数据处理、建模仿真、论文写作与指导,科研项目与课题交流。项目合作可私信或扫描文章底部二维码。
(1) 基于自适应保守值函数更新的强化学习算法研究
舰载机在复杂海况下的自主降落面临极为严峻的挑战,不仅因为航母是一个移动平台,还因为海面上的风浪等外界条件瞬息万变,这给强化学习模型的训练带来了极大的困难。通常情况下,强化学习依赖于智能体与环境的在线交互来学习和优化策略,但在复杂海况下,在线交互所需的训练数据量急剧增加,导致训练效率明显下降,甚至可能导致训练过程中的策略不稳定。因此,本文提出了一种基于自适应保守值函数更新的强化学习算法——Ada CQL(Adaptive Conservative Q-Learning),以此提升复杂海况下舰载机自主降落任务的训练效率和模型的稳定性。
传统的保守值函数学习(CQL)算法通过对值函数进行保守估计,减小了在离线强化学习环境中由于值函数估计偏差导致的策略崩塌问题。然而,CQL算法在处理带有约束的操作时,仍然会引入额外的值函数估计偏差,特别是在高度动态的环境中,值函数可能因外部扰动而发生严重波动,进而影响决策的准确性。为了解决这个问题,本文提出的Ada CQL算法,通过自适应调整值函数的更新范围,使得保守值函数更新更加灵活和稳定。
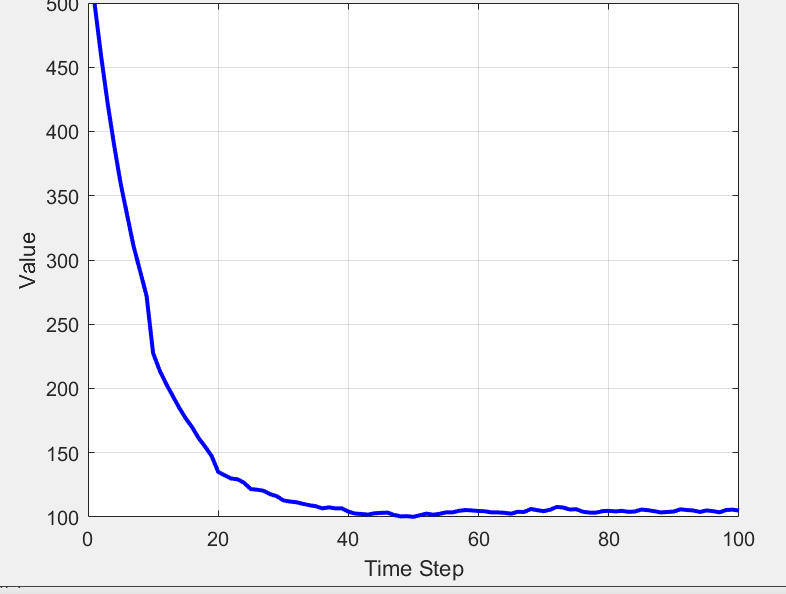
具体而言,Ada CQL通过监控环境中反馈的奖励信号和值函数更新的变化,动态调整值函数的保守更新幅度。在训练过程中,Ada CQL算法能够根据舰载机在不同海况条件下的表现,自适应地收紧或放宽值函数的约束,确保在动态环境下依然能够稳定地优化策略。为了验证Ada CQL算法的有效性,本文首先在MuJoCo仿真环境中的基准任务中进行了实验分析,实验结果表明,Ada CQL算法在复杂场景中的奖励性能和策略稳定性方面均优于传统的CQL算法。在应用于舰载机自主降落任务的实验中,Ada CQL进一步展示了其提升训练效率和最终降落精度的能力。实验结果表明,与其他强化学习算法相比,Ada CQL在复杂海况下的收敛速度更快,且有效提高了降落的成功率。
(2) 基于模仿学习的自适应值函数更新算法研究
虽然Ada CQL算法有效地解决了值函数约束操作带来的估计偏差问题,但在复杂海况下,训练过程中还会面临另一个重要挑战:样本分布外动作的估计偏差。强化学习模型在训练过程中常常会遇到未见过的动作样本,这些样本在复杂环境中极易引发策略的不稳定,进而导致模型的表现大幅波动。因此,本文进一步提出了一种基于模仿学习的自适应值函数更新算法——IL-Ada CQL(Imitate Learning Adaptive Conservative Q-Learning),旨在通过模仿学习引导目标值函数的更新,减小分布外动作带来的偏差,提高模型在复杂海况下的稳定性。
模仿学习是一种通过观察专家演示数据来引导智能体学习的算法,它能够帮助智能体更好地应对复杂场景下的动作选择问题。在IL-Ada CQL算法中,模仿学习通过离线样本所建议的动作,引导值函数更新过程中的动作选择。这种方式有效减少了未见过的动作样本被选中的概率,从而减小了因分布外动作估计偏差而导致的值函数更新问题。具体来说,IL-Ada CQL通过分析离线样本的分布,动态调整策略的选择,使得值函数能够更加稳健地进行更新。
在实验部分,本文首先在MuJoCo基准任务中对IL-Ada CQL算法的性能进行了测试,实验结果表明,IL-Ada CQL在保持Ada CQL算法高效训练的同时,进一步提升了策略的稳定性,尤其是在复杂环境中,IL-Ada CQL展现出了更强的鲁棒性。随后,本文将IL-Ada CQL算法应用于复杂海况下的舰载机自主降落任务中,实验结果显示,IL-Ada CQL能够在显著减少训练数据量的前提下,依然保持较高的策略准确性,并有效提高了着舰任务的成功率。这一结果表明,IL-Ada CQL不仅在离线强化学习场景中有效解决了分布外动作带来的估计偏差问题,还为舰载机自主降落等高动态任务提供了一种稳定、可靠的强化学习训练方法。
(3) 复杂海况下舰载机自主降落的强化学习系统实验与验证
为了验证本文提出的Ada CQL和IL-Ada CQL算法在复杂海况下的实际应用效果,本文构建了一个高度仿真的海况环境,模拟舰载机在不同风浪条件下的自主降落任务。该仿真环境包括动态海浪、随机风力以及航母平台的移动,旨在逼真再现舰载机实际降落过程中可能遇到的各种复杂情况。在该仿真平台上,本文对不同强化学习算法进行了广泛的对比实验,以评估其在复杂海况下的性能。
实验结果显示,传统的强化学习算法(如深度Q学习、策略梯度等)在复杂海况下难以稳定收敛,尤其是在面对强风或大浪条件时,降落的成功率大幅下降。而本文提出的Ada CQL算法能够在大多数复杂环境下稳定收敛,并且在较短的训练时间内便能实现较高的降落精度。相比之下,IL-Ada CQL算法在此基础上进一步提升了策略的鲁棒性,即便在极端的海况条件下,舰载机依然能够稳定完成降落任务。
% 初始化参数
num_states = 100; % 状态数量
num_actions = 4; % 动作数量 (例如上升、下降、左移、右移)
Q_table = zeros(num_states, num_actions); % Q表初始化
gamma = 0.95; % 折扣因子
alpha = 0.1; % 学习率
epsilon = 0.1; % 探索率
% 仿真环境初始化 (假设状态和动作均为离散)
max_iterations = 1000;
for iteration = 1:max_iterations
% 初始化初始状态
current_state = randi([1, num_states]);
for step = 1:100
% 根据epsilon-greedy策略选择动作
if rand < epsilon
action = randi([1, num_actions]); % 探索
else
[~, action] = max(Q_table(current_state, :)); % 利用Q表
end
% 执行动作 (这里为模拟的状态转移和奖励函数)
next_state = randi([1, num_states]); % 状态转移模拟
reward = randi([-10, 10]); % 奖励函数模拟
% 更新Q值
Q_table(current_state, action) = (1 - alpha) * Q_table(current_state, action) + ...
alpha * (reward + gamma * max(Q_table(next_state, :)));
% 状态更新
current_state = next_state;
end
end
% 展示Q表学习结果
disp('Learned Q-Table:');
disp(Q_table);
% 绘制策略图
[~, optimal_actions] = max(Q_table, [], 2);
figure;
bar(optimal_actions);
title('Learned Optimal Actions');
xlabel('State');
ylabel('Optimal Action');

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)