大数据毕业设计:个性化就业推荐系统 招聘推荐系统 spark技术 协同过滤推荐算法✅
大数据毕业设计:个性化就业推荐系统 招聘推荐系统 spark技术 协同过滤推荐算法✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
基于Python语言、PySpark技术、Django框架、requests爬虫、协同过滤推荐算法、HTML
2、项目界面
(1)职位查询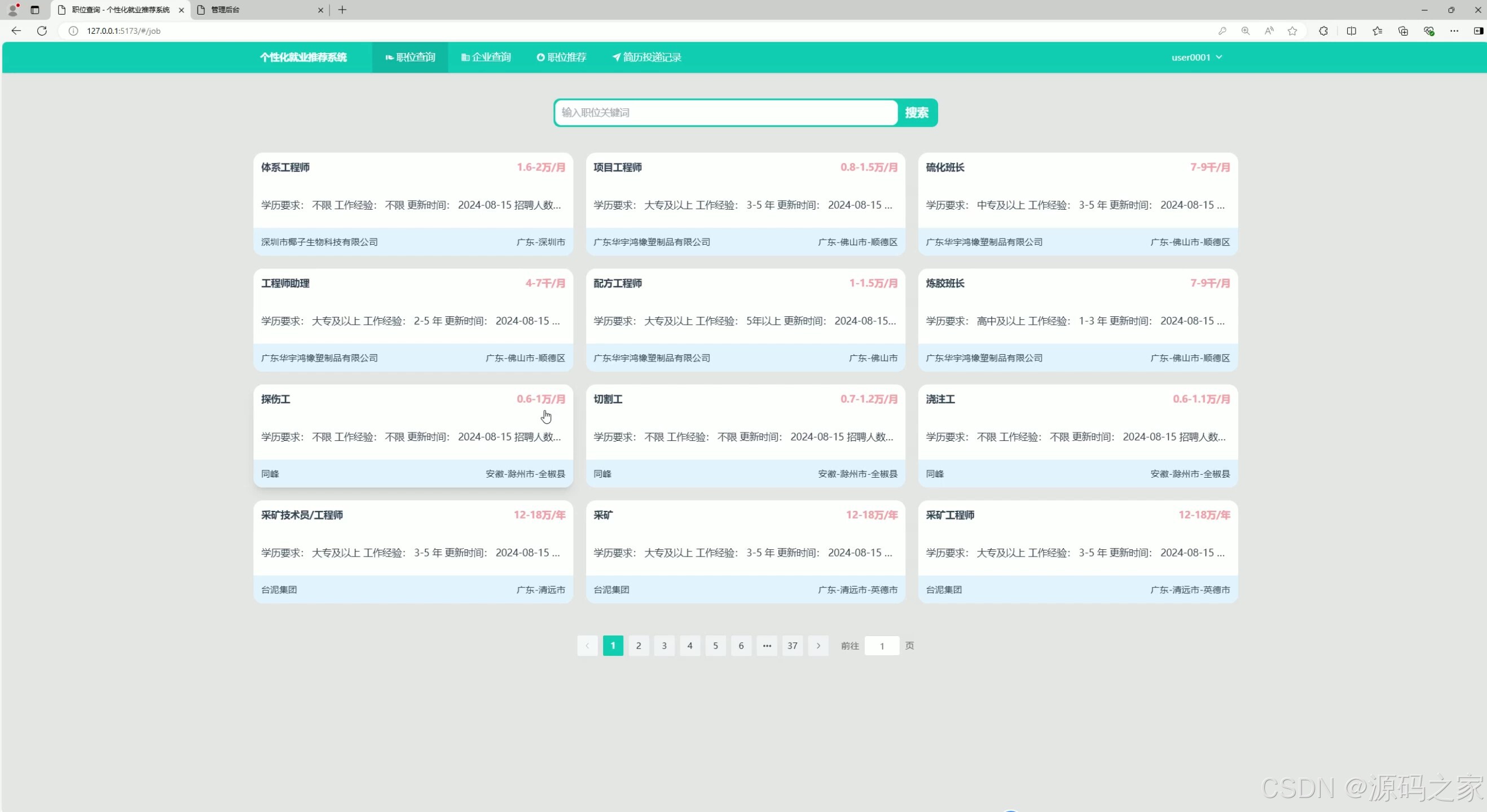
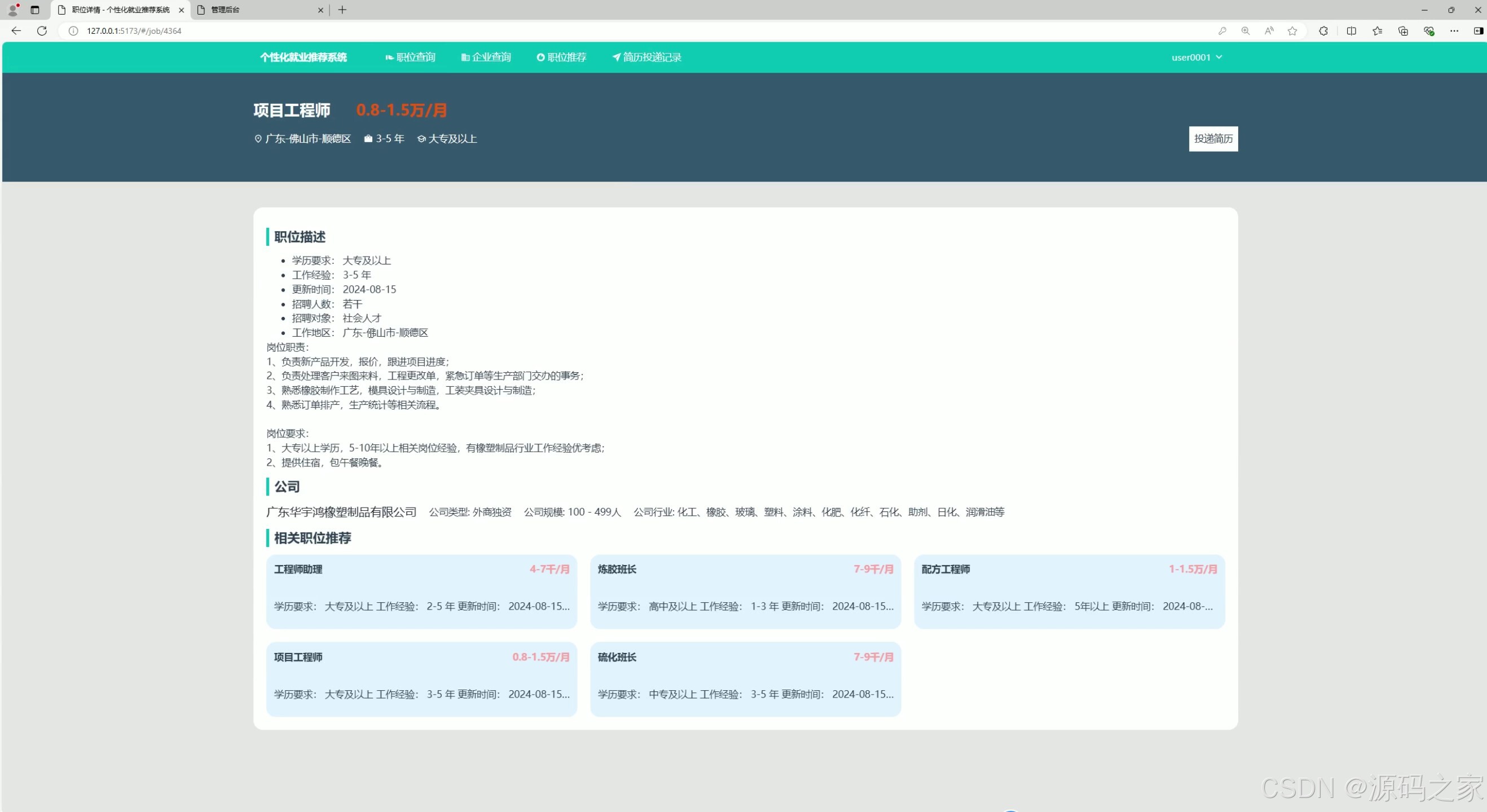
(2)职位详情页面
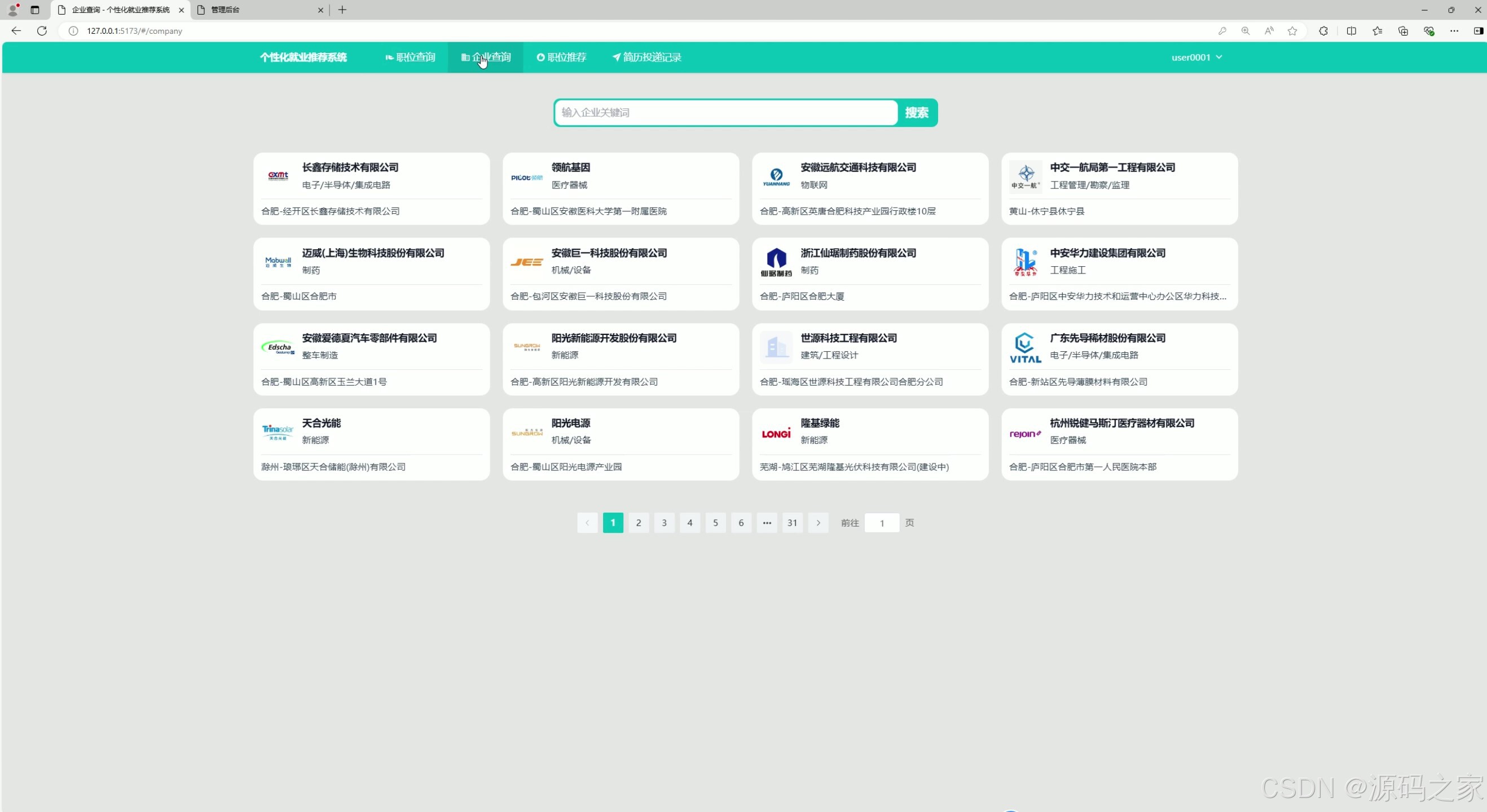
(3)企业查询
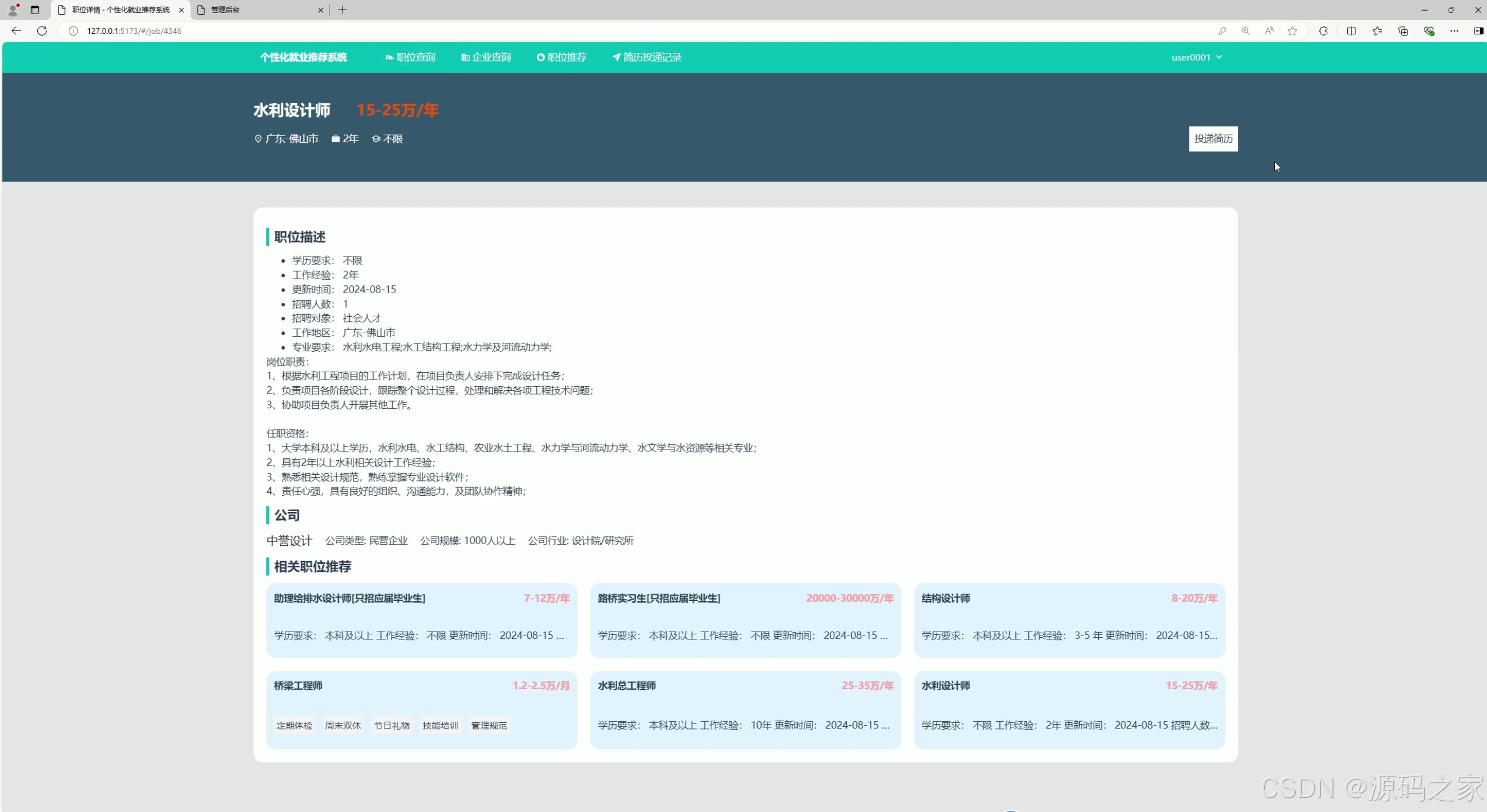
(4)相关岗位推荐----基于物品协同过滤推荐算法
(5)岗位推荐—基于用户协同过滤推荐算法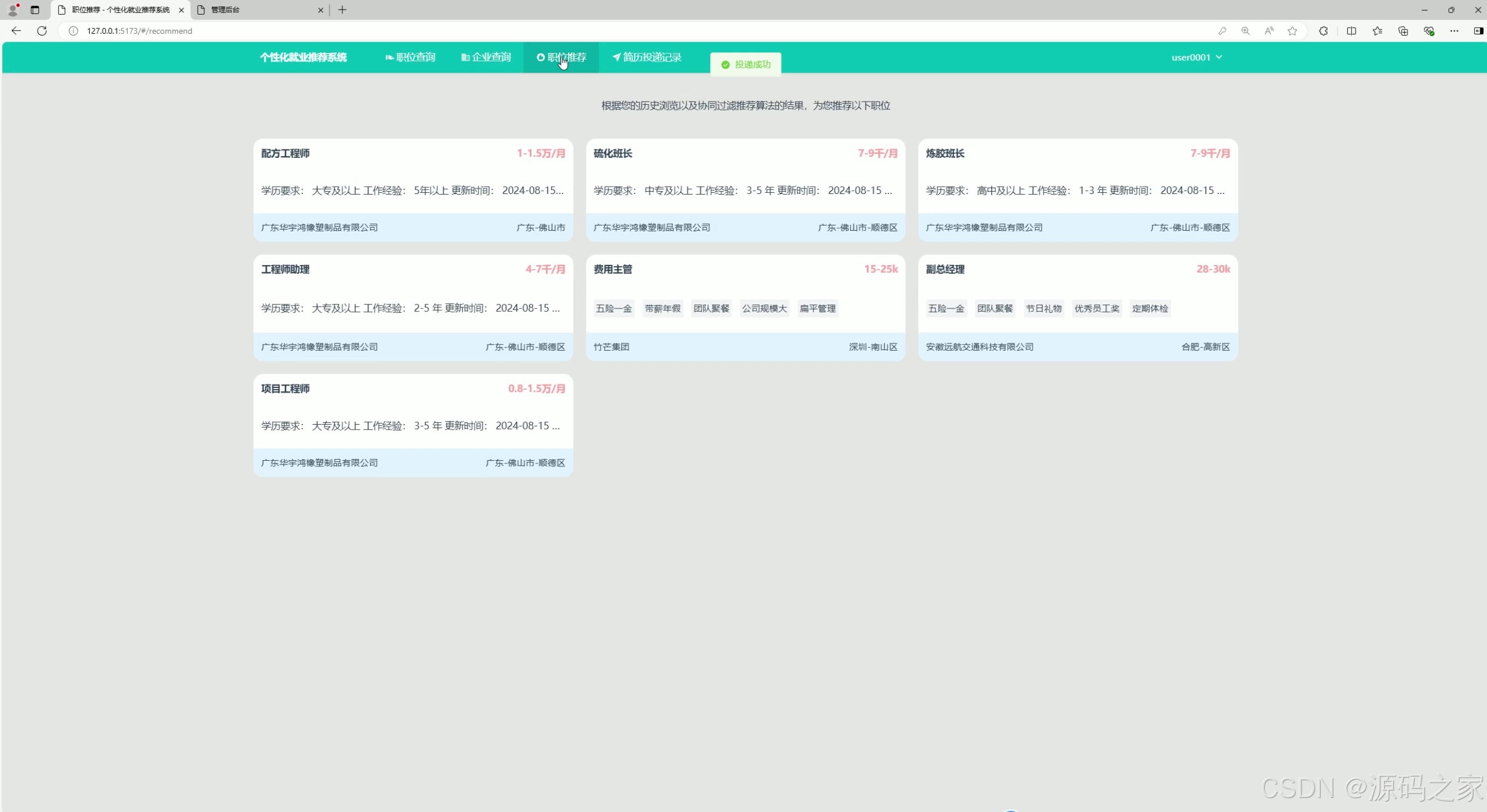
(6)后台数据管理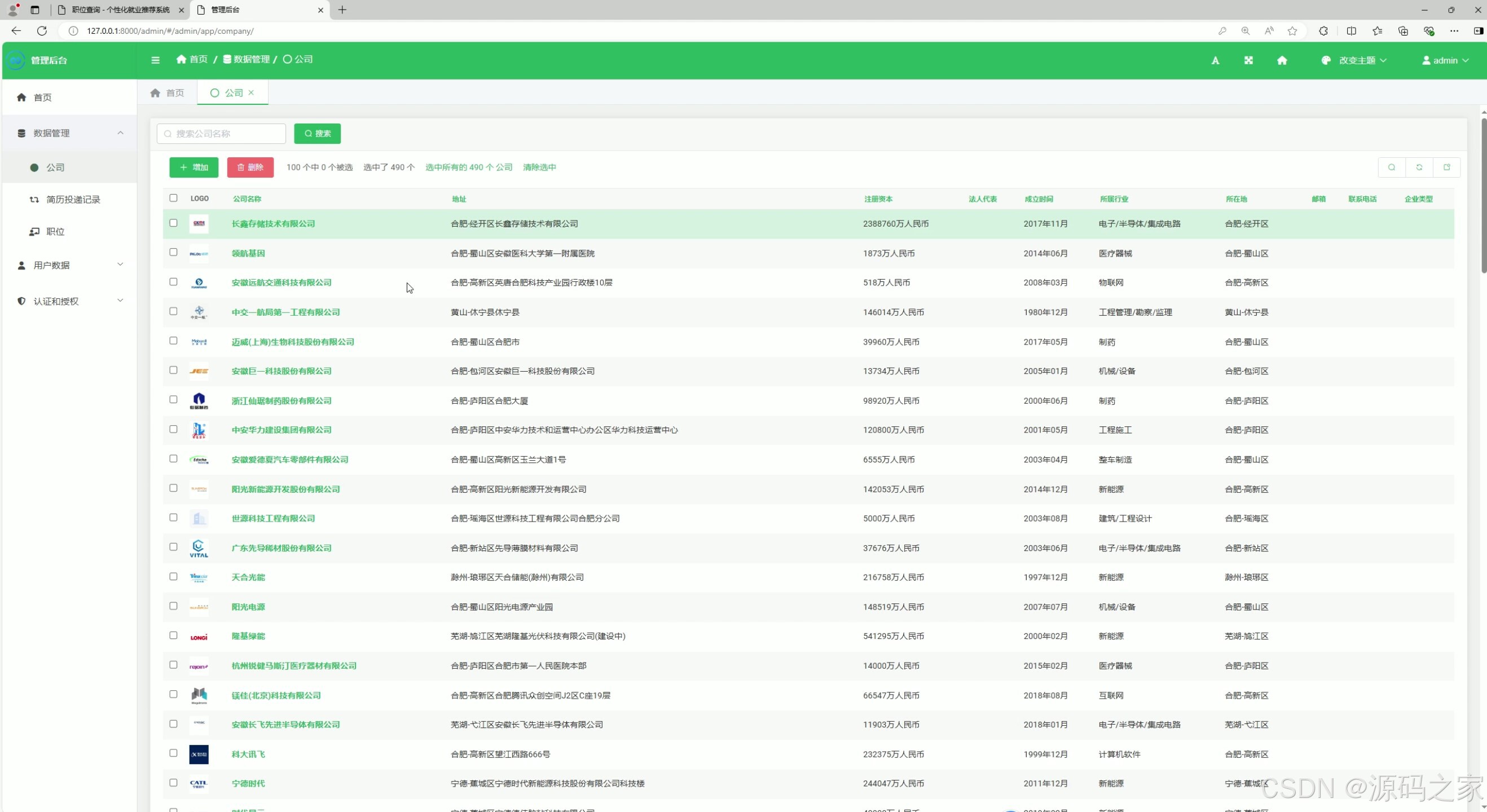
(7)注册登录
(8)数据爬取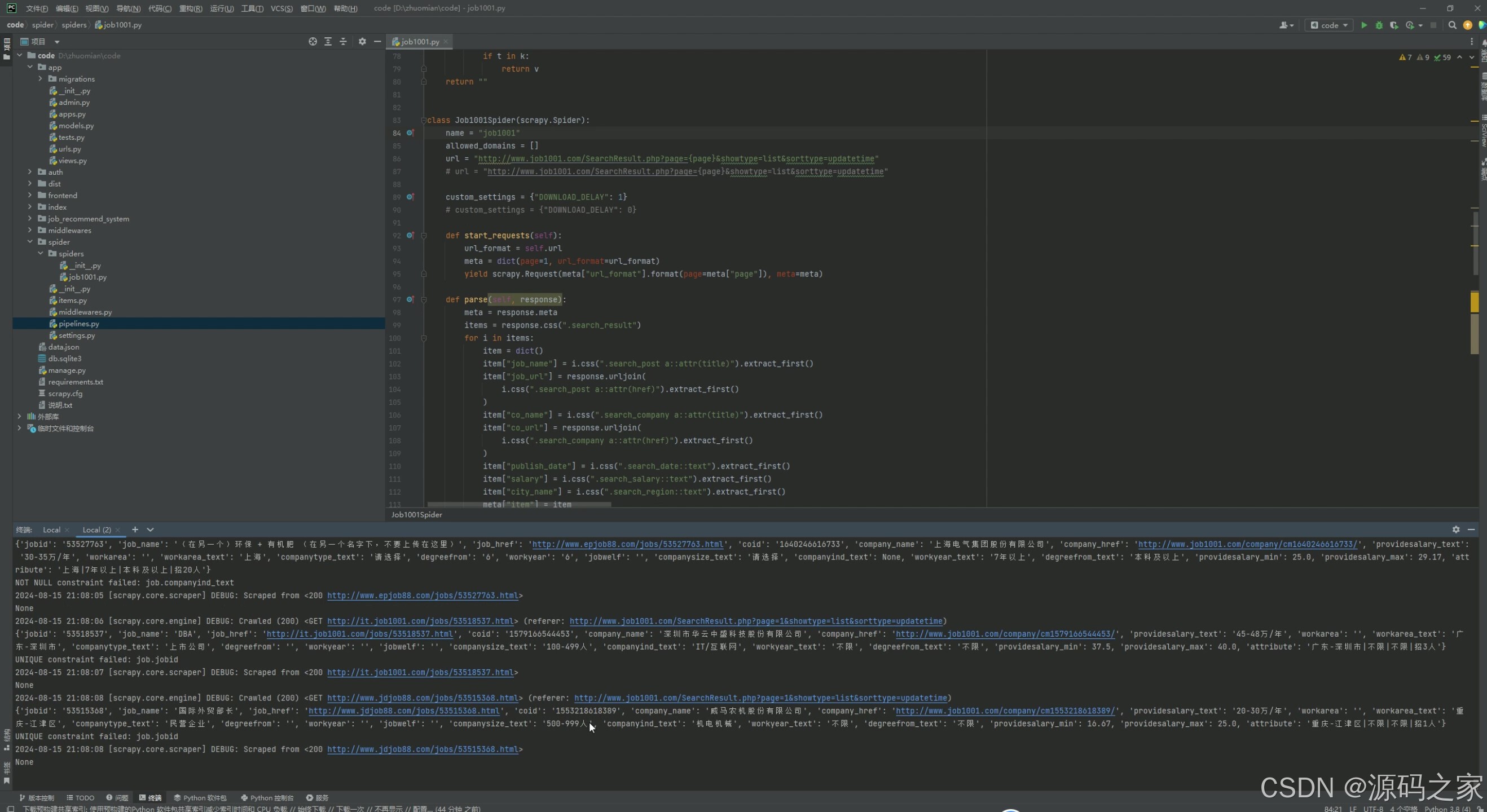
3、项目说明
该系统是一个创新的招聘推荐平台,它结合了大数据处理、机器学习算法和Web开发技术,旨在为企业和求职者提供更加精准、高效的匹配服务。
在数据处理方面,系统采用了PySpark技术。PySpark是Apache Spark的Python API,它提供了强大的分布式计算能力,能够处理海量的招聘数据和用户行为数据。通过PySpark,系统能够高效地清洗、转换和存储数据,为后续的分析和推荐提供坚实的基础。
在Web开发方面,系统采用了Django框架。Django是一个高级的Python Web框架,它允许快速开发安全、可维护的网站。通过Django,系统构建了一个用户友好的界面,使得企业和求职者能够方便地浏览、搜索和推荐职位。
为了获取最新的招聘信息,系统还采用了requests爬虫技术。requests是一个简单易用的HTTP库,它允许发送HTTP请求并获取响应。通过requests爬虫,系统能够定期从各大招聘网站抓取最新的职位信息,并实时更新到数据库中。
在推荐算法方面,系统实现了协同过滤推荐算法。协同过滤是一种基于用户行为或物品属性的推荐方法,它能够根据用户的历史行为和偏好来推荐相似的职位。通过协同过滤算法,系统能够为用户推荐符合其兴趣和能力要求的职位,提高匹配的精准度和用户的满意度。
总的来说,该系统通过整合Python语言、PySpark技术、Django框架、requests爬虫以及协同过滤推荐算法等先进技术,构建了一个高效、智能的招聘推荐平台。它不仅能够为企业提供优质的招聘服务,还能够为求职者提供更加精准的职位推荐,促进人才与企业的有效对接。未来,该系统将继续优化算法、提升性能,为用户提供更加优质、便捷的服务。
4、核心代码
# 职位信息分页查询
def get_jobs(request):
data = request.json
not_q = ("total", "page", "pagesize", "providesalary")
pagesize = data.get("pagesize", 12)
page = data.get("page", 1)
# 加入筛选条件
params = {k: v for k, v in data.items() if k not in not_q and v}
# 薪资范围筛选条件做特别处理
if "providesalary" in data and data["providesalary"]:
q = salary_q[data["providesalary"]]
params_q = Q(**params) & q
# 其余筛选条件直接加入
else:
params_q = Q(**params)
# 筛选职位,并按照职位id倒排
objs = Job.objects.filter(params_q).order_by("-id").all()
pg = Paginator(objs, pagesize)
# 分页
page = pg.page(page)
# 返回数据
return JsonResponse(
{
"total": pg.count,
"records": to_dict(page.object_list),
}
)
def post_resume(request):
jid = request.json.get("jid")
ResumePost.objects.update_or_create(
defaults=dict(user=request.user, job=Job.objects.get(pk=jid)),
user=request.user,
job=Job.objects.get(pk=jid),
)
return JsonResponse({"ok": 1})
# 获取单个职位详细信息
def get_job(request):
# 按所给职位id,查出职位信息并返回
id = request.json.get("id")
obj = get_object_or_404(Job, id=id)
ViewHistory.objects.create(user=request.user, job=obj)
return JsonResponse(to_dict([obj])[0])
def get_company(request):
id = request.json.get("id")
obj = get_object_or_404(Company, id=id)
return JsonResponse(to_dict([obj])[0])
def get_companys(request):
body = request.json
pagesize = body.get("pagesize", 10)
page = body.get("page", 1)
exclude_fields = ["pagesize", "page", "total"]
query = {k: v for k, v in body.items() if k not in exclude_fields and v}
q = Q(**query)
objs = Company.objects.filter(q).order_by("-id")
paginator = Paginator(objs, pagesize)
pg = paginator.page(page)
result = list(pg.object_list)
result = to_dict(result)
return JsonResponse({"total": paginator.count, "records": result})
def get_resume_posts(request):
body = request.json
pagesize = body.get("pagesize", 10)
page = body.get("page", 1)
exclude_fields = ["pagesize", "page", "total"]
query = {k: v for k, v in body.items() if k not in exclude_fields and v}
q = Q(**query, user__id=request.user.id)
objs = ResumePost.objects.filter(q).order_by("-id")
paginator = Paginator(objs, pagesize)
pg = paginator.page(page)
result = list(pg.object_list)
for i in result:
i.j = to_dict([i.job])[0]
result = [
{**i["j"], "created_time": i["created_time"].strftime("%Y-%m-%d %H:%M:%S")}
for i in to_dict(result)
]
return JsonResponse({"total": paginator.count, "records": result})
def get_user_recommend_jobs(request):
topK = 12
# 基于用户推荐
try:
ids = AppConfig.recommendJobsForUser(request.user.id, topK=topK)
jobs = Job.objects.filter(id__in=ids).order_by("?")
return JsonResponse(to_dict(jobs), safe=False)
except:
return history_recommand(request, topK)
def get_content_recommend_jobs(request):
# 基于物品推荐
topK = 6
body = request.json
id = body.get("id")
o = Job.objects.get(pk=id)
try:
ids = AppConfig.recommendProductsForProduct(o.id, topK=topK)
jobs = Job.objects.filter(id__in=ids).order_by("?")
except:
jobs = Job.objects.filter(companyind_text=o.companyind_text).order_by("?")[
:topK
]
return JsonResponse(to_dict(jobs), safe=False)
def history_recommand(request, topK=5):
jobIds = (
ViewHistory.objects.filter(user_id=request.user.id)
.values_list("job_id")
.distinct()
)
jobs = []
# 根据历史查看记录推荐
if jobIds:
jobIds = [i[0] for i in jobIds]
cates = [
i[0]
for i in Job.objects.filter(id__in=jobIds).values_list("companyind_text")
]
most_common_cates = list(dict(Counter(cates).most_common(2)).keys())
jobs = Job.objects.filter(companyind_text__in=most_common_cates).order_by("?")[
:topK
]
# 没有记录则随机推荐
else:
jobs = Job.objects.order_by("?")[:topK]
return JsonResponse(to_dict(jobs), safe=False)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)