CNN卷积神经网络之注意力机制CBAM(六)
下面为你完整提取文档中关于。
CNN卷积神经网络之注意力机制CBAM(六)
文章目录
下面为你完整提取文档中关于 CBAM(Convolutional Block Attention Module) 的全部内容,包括:
- 核心思想与结构图
- 通道注意力(Channel Attention)详解
- 空间注意力(Spatial Attention)详解
- 消融实验图表
- 完整可运行的 PyTorch 代码(通道注意力、空间注意力、整合到 ResNet50)
1. CBAM 基本认知与结构图
| 图 1:CBAM 整体结构(通道注意力 + 空间注意力) |
|---|
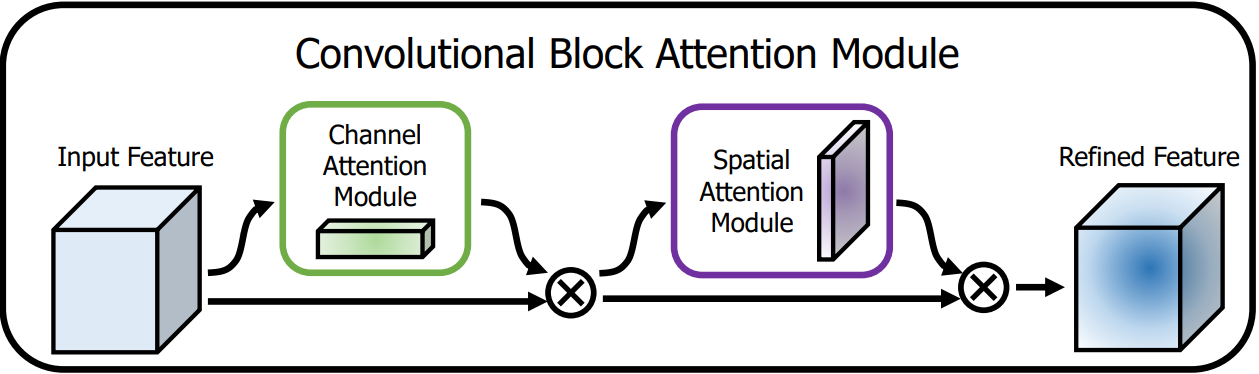 |
CBAM 是一个轻量级混合注意力模块,先后沿 通道维度 和 空间维度 计算注意力权重,公式化描述如下:
F ′ = M c ( F ) ⊗ F , F ′ ′ = M s ( F ′ ) ⊗ F ′ . \begin{aligned} \mathbf{F'} &= \mathbf{M_c}(\mathbf{F}) \otimes \mathbf{F}, \\ \mathbf{F''} &= \mathbf{M_s}(\mathbf{F'}) \otimes \mathbf{F'}. \end{aligned} F′F′′=Mc(F)⊗F,=Ms(F′)⊗F′.
- M c ∈ R C × 1 × 1 \mathbf{M_c} \in \mathbb{R}^{C\times 1\times 1} Mc∈RC×1×1:通道注意力图
- M s ∈ R 1 × H × W \mathbf{M_s} \in \mathbb{R}^{1\times H\times W} Ms∈R1×H×W:空间注意力图
- ⊗ \otimes ⊗:逐元素乘法(广播机制)
2. 通道注意力模块(Channel Attention)
2.1 原理与流程图
| 图 2:通道注意力流程 |
|---|
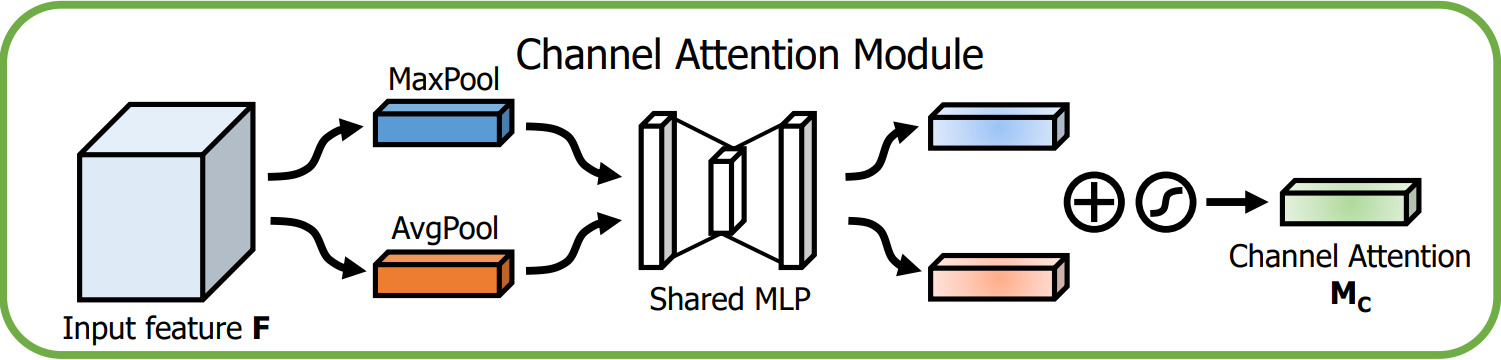 |
- 对输入特征图 F ∈ R C × H × W \mathbf{F}\in\mathbb{R}^{C\times H\times W} F∈RC×H×W 分别做 全局平均池化 和 全局最大池化,得到两个 1 × 1 × C 1\times 1\times C 1×1×C 的向量。
- 将两个向量分别送入 共享的 MLP(两层全连接:先降维 C / r C/r C/r,再升维回 C C C)。
- 将 MLP 输出的两个特征向量逐元素相加,经 Sigmoid 得到通道注意力图 $ m a t h b f M c mathbf{M_c} mathbfMc。
数学表达:
M c ( F ) = σ ( MLP ( AvgPool ( F ) ) + MLP ( MaxPool ( F ) ) ) \mathbf{M_c}(\mathbf{F})=\sigma\left(\text{MLP}\bigl(\text{AvgPool}(\mathbf{F})\bigr)+\text{MLP}\bigl(\text{MaxPool}(\mathbf{F})\bigr)\right) Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))
2.2 通道注意力 PyTorch 代码
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
3. 空间注意力模块(Spatial Attention)
3.1 原理与流程图
| 图 3:空间注意力流程 |
|---|
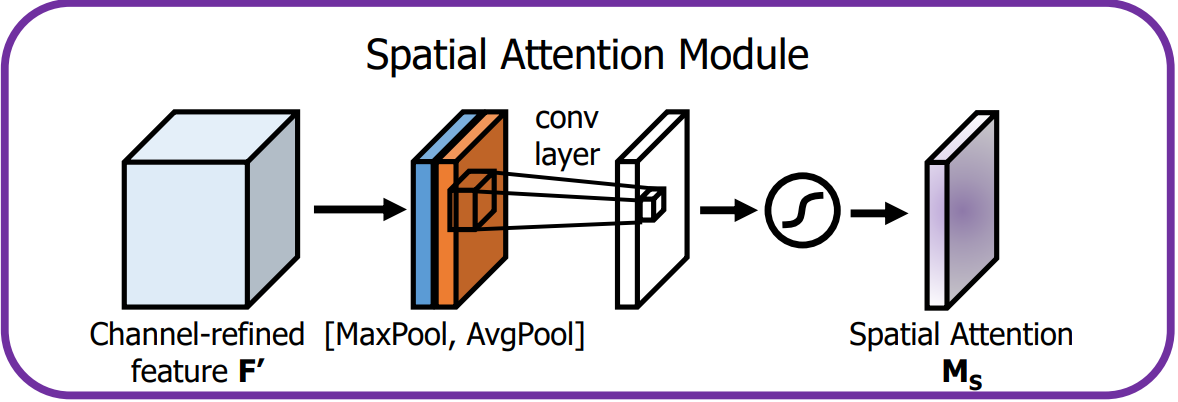 |
- 对 通道维度 分别做 最大池化 和 平均池化,得到两个 H × W × 1 H\times W\times 1 H×W×1 的二维图。
- 将两个二维图在通道维度 拼接,形成 H × W × 2 H\times W\times 2 H×W×2 的特征。
- 使用一个 7 × 7 7\times 7 7×7 卷积层将 2 2 2 通道压缩为 1 1 1 通道,再经 Sigmoid 得到空间注意力图 M s \mathbf{M_s} Ms。
数学表达:
M s ( F ) = σ ( f 7 × 7 ( [ AvgPool ( F ) ; MaxPool ( F ) ] ) ) \mathbf{M_s}(\mathbf{F})=\sigma\left(f^{7\times7}\bigl([\text{AvgPool}(\mathbf{F});\text{MaxPool}(\mathbf{F})]\bigr)\right) Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))
3.2 空间注意力 PyTorch 代码
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = kernel_size // 2
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
4. 消融实验图表
4.1 通道注意力有效性
| 图 4:仅通道注意力对比 |
|---|
 |
- 加入通道注意力后,所有模型均优于 baseline。
4.2 空间注意力叠加效果
| 图 5:叠加空间注意力 |
|---|
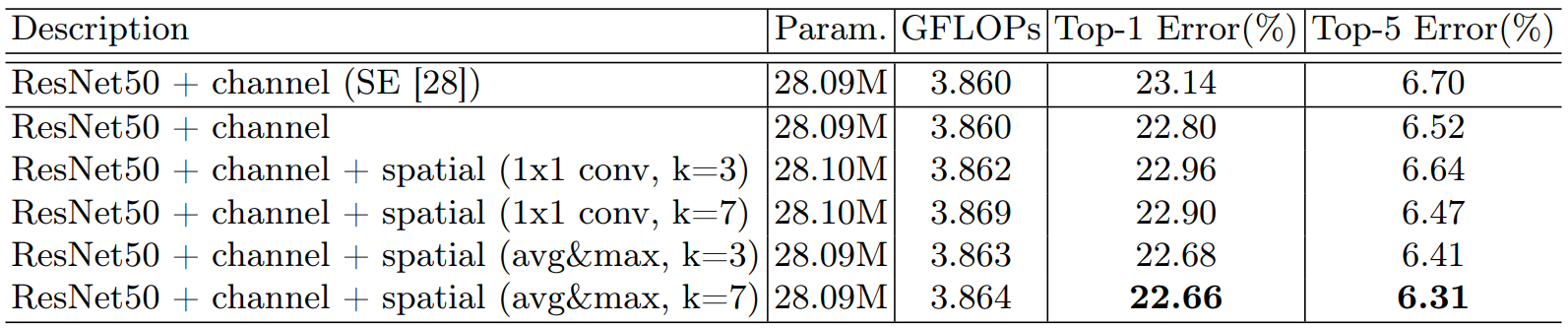 |
- CBAM(通道+空间) 优于单独通道注意力;MaxPool + AvgPool 组合 最佳。
4.3 注意力顺序对比
| 图 6:通道先 / 空间先 对比 |
|---|
 |
- 通道 → 空间 的顺序(即 CBAM 默认顺序)效果最好。
4.4 不同模型横向对比
| 图 7:CBAM 在不同模型上的增益 |
|---|
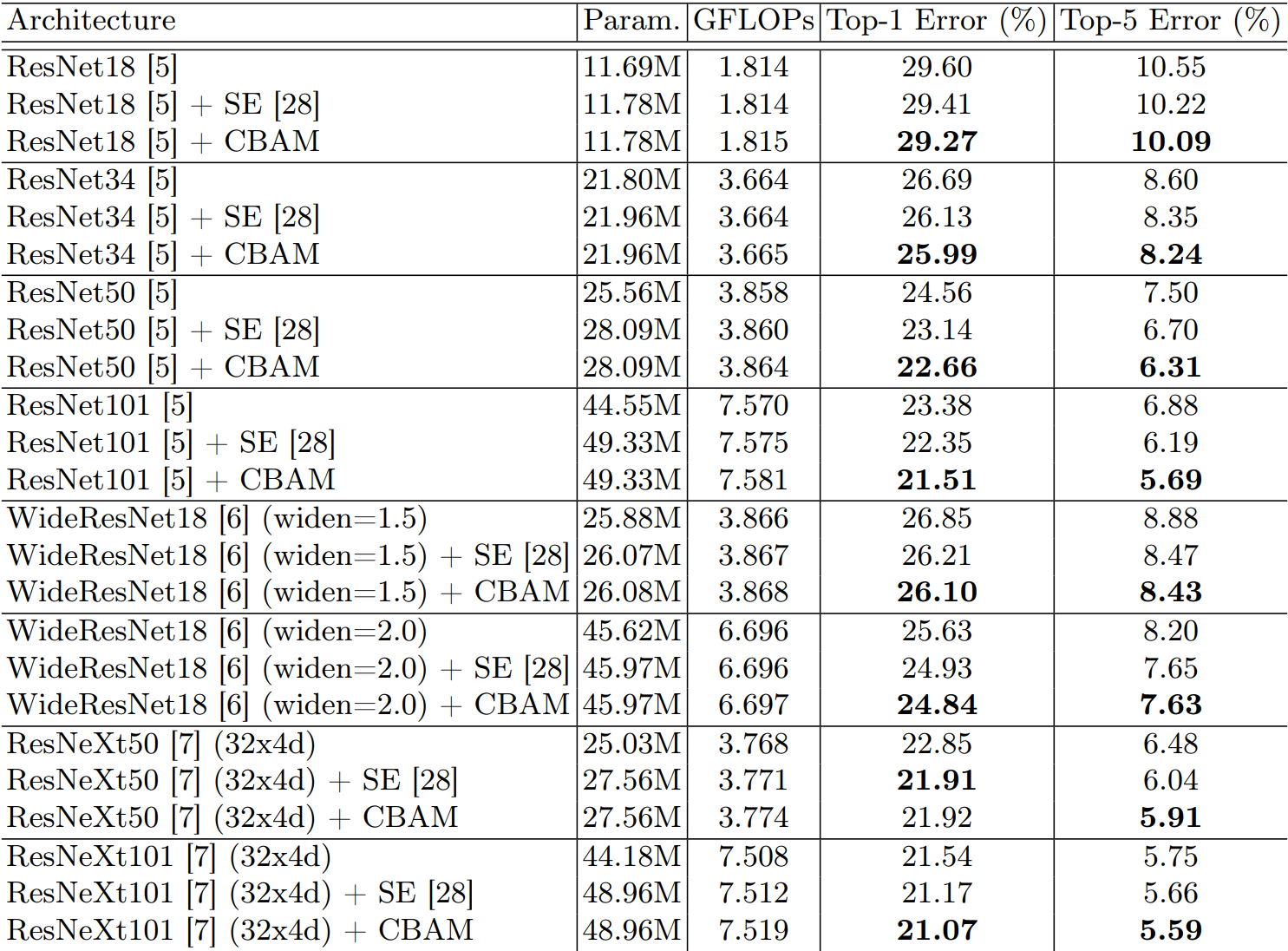 |
- 在 ResNet、WideResNet、ResNeXt 等主流网络上均带来一致提升。
5. ResNet50 整合 CBAM 完整代码
下面给出 ResNet50 + CBAM 的完整实现,可直接运行并导出 ONNX:
import torch
import torch.nn as nn
from torchvision.models.resnet import ResNet, Bottleneck, _resnet, ResNet50_Weights
# -------------------- 1. 通道注意力 --------------------
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
# -------------------- 2. 空间注意力 --------------------
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), "kernel_size must be 3 or 7"
padding = kernel_size // 2
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
# -------------------- 3. 改造 Bottleneck,插入 CBAM --------------------
class BottleneckCBAM(Bottleneck):
expansion = 4
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# conv3 的输出通道即为 planes * expansion
self.ca = ChannelAttention(self.conv3.out_channels)
self.sa = SpatialAttention()
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
# CBAM 注意力
out = self.ca(out) * out # 通道加权
out = self.sa(out) * out # 空间加权
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# -------------------- 4. 构建 ResNet50-CBAM --------------------
def resnet50_cbam(pretrained=False, **kwargs):
"""
返回带有 CBAM 的 ResNet50。
pretrained=True 时加载 ImageNet 预训练权重(注意:CBAM 部分需要微调)。
"""
if pretrained:
weights = ResNet50_Weights.DEFAULT
else:
weights = None
return _resnet(
BottleneckCBAM,
[3, 4, 6, 3],
weights,
progress=True,
**kwargs
)
# -------------------- 5. 测试脚本 --------------------
if __name__ == "__main__":
model = resnet50_cbam(pretrained=False, num_classes=10) # 10 类示例
model.eval()
dummy = torch.randn(1, 3, 224, 224)
# 打印网络结构(可选)
# print(model)
# 前向测试
with torch.no_grad():
out = model(dummy)
print("输出 shape:", out.shape) # 应为 [1, 10]
# 导出 ONNX
torch.onnx.export(model, dummy, "resnet50_cbam.onnx",
opset_version=11, input_names=["input"],
output_names=["output"])
print("已导出 resnet50_cbam.onnx")
小结
| 维度 | 关键要点 |
|---|---|
| 模块顺序 | 先通道注意力 → 后空间注意力 |
| 通道注意力 | AvgPool + MaxPool → Shared MLP → Sigmoid |
| 空间注意力 | Channel-wise Avg & Max → Concat → 7×7 Conv → Sigmoid |
| 即插即用 | 可插入任何 CNN 架构,仅需几行代码 |
| 效果 | 在 ImageNet、CIFAR 等多数据集、多模型上稳定提升 |

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)