登上Nature封面的硬核idea:强化学习+卡尔曼滤波的完美融合,双赢!
《Nature》封面研究:强化学习+卡尔曼滤波的突破性进展 最新发表在《Nature》的研究展示了强化学习与卡尔曼滤波的创新结合。该系统在无人机竞速中达到世界冠军水平,其优势在于: 卡尔曼滤波提供高精度状态估计 强化学习实现更稳健的决策 显著提升系统抗干扰能力 计算效率大幅提高 研究团队同时分享了14篇相关论文资源,包含: KalMamba高效概率状态空间模型 量子倒立摆新型基准环境 强化学习在量
今天分享一个能上Nature封面的idea:强化学习+卡尔曼滤波。
这一篇登上《Nature》封面的研究介绍了一种名为Swift的自主无人机竞速系统。该系统融合强化学习与卡尔曼滤波,实现了与人类世界冠军相当的竞速水平,并刷新了赛事最快纪录。
这一结合带来了显著优势:强化学习借助卡尔曼滤波提供的高精度状态估计,能够做出更精准、稳健的决策,从而提升系统的实时性、计算效率及鲁棒性,在面对噪声、干扰等不确定因素时仍保持出色表现。该方法展现出巨大的研究潜力,特别适合关注智能控制、自主导航等方向的同学参考。
为助力科研,我已整理出14篇强化学习+卡尔曼滤波最新相关论文,涵盖算法详解与开源代码,便于复现与深入学习。
关注VX公众号【学长论文指导】发送暗号 9 领取
【论文1】KalMamba: Towards Efficient Probabilistic State Space Models for RL under Uncertainty
研究方法
该论文提出了KalMamba,一种结合了概率状态空间模型(SSMs)与确定性SSMs可扩展性的高效架构。KalMamba利用Mamba学习线性高斯SSM的动态参数,并在潜在空间中进行标准的卡尔曼滤波和 smoothing。通过并行关联扫描,实现了时间并行计算,显著提高了计算效率。在DeepMind Control Suite的多个任务中,KalMamba与Soft Actor-Critic(SAC)结合,展示了与最新SSMs相当的性能,同时在长序列交互中显著提高了计算效率。
论文创新点
-
高效架构:KalMamba通过结合概率SSMs的不确定性意识和确定性SSMs的可扩展性,提出了一种高效的学习架构,适用于高维、部分信息的强化学习环境。
-
并行化卡尔曼滤波:通过将卡尔曼滤波和平滑操作表述为关联操作,利用并行扫描技术,实现了时间并行计算,显著降低了长序列的训练时间。
-
紧耦合信念状态:KalMamba在训练中使用平滑信念,但在执行时仅使用过滤信念,通过归纳偏置确保了过滤和平滑信念之间的紧密耦合,保证了策略学习的合理性。
-
模型结构如下
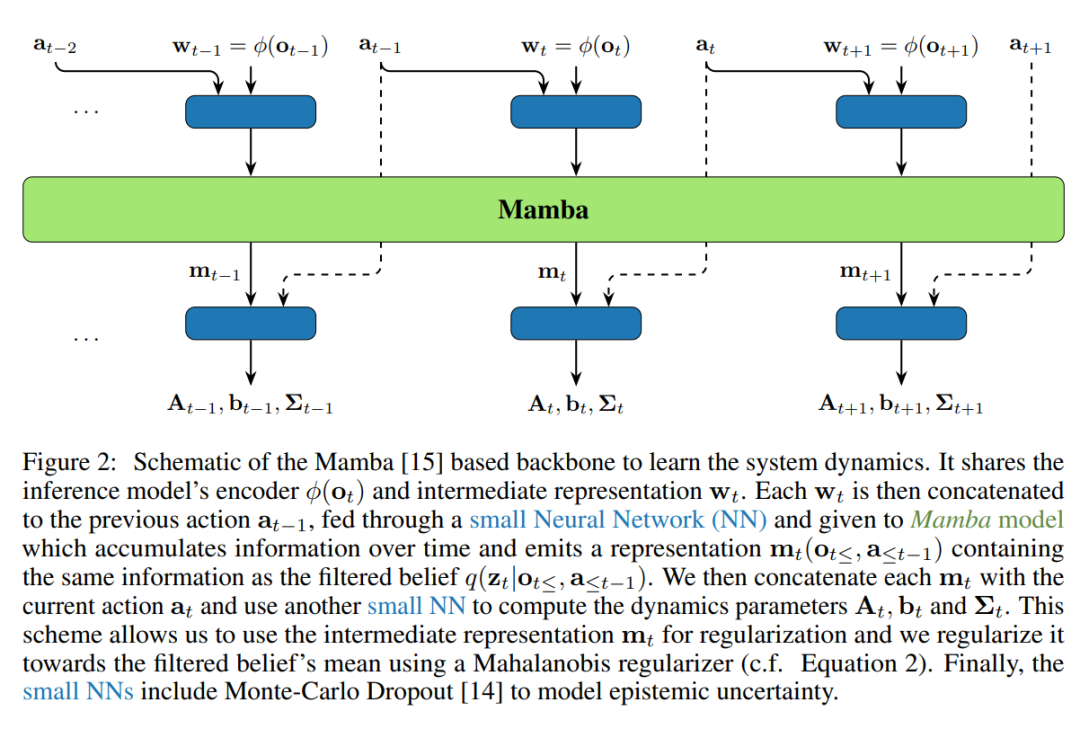
实验结果
在DeepMind Control Suite的多个任务中,KalMamba与SAC结合,展示了与最新SSMs相当的性能。特别是在长序列任务中,KalMamba的训练时间显著少于基线方法,且随着序列长度的增加,性能进一步提升。此外,实验表明KalMamba的关键组件(如Mamba、蒙特卡洛 dropout 和正则化损失)对模型性能至关重要。
论文链接:https://arxiv.org/abs/2406.15131v1
论文2】The Quantum Cartpole: A benchmark environment for non-linear reinforcement learning
研究方法
论文提出了量子倒立摆(Quantum Cartpole)作为非线性强化学习的基准环境,并比较了带有和不带状态估计器的控制算法在稳定量子粒子不稳定状态方面的表现。研究中使用了弱量子测量和无模型强化学习智能体,展示了在高度非线性场景中强化学习控制器相较于传统控制器的优势,并验证了通过经典代理进行转移学习的可行性。
论文创新点
-
量子控制系统:提出了量子倒立摆问题,这是一个基于经典倒立摆问题的量子版本,用于评估反馈控制算法在量子系统中的性能。
-
强化学习控制器:设计了两种强化学习控制智能体(RLC和RLE),分别负责控制力和状态估计。这些智能体使用近端策略优化(PPO)算法进行训练,无需系统模型或噪声模型即可学习控制策略。
-
转移学习:验证了在经典系统上训练的强化学习智能体可以有效地迁移到量子系统控制任务中,为复杂量子系统的控制提供了新方法。
-
模型结构如下
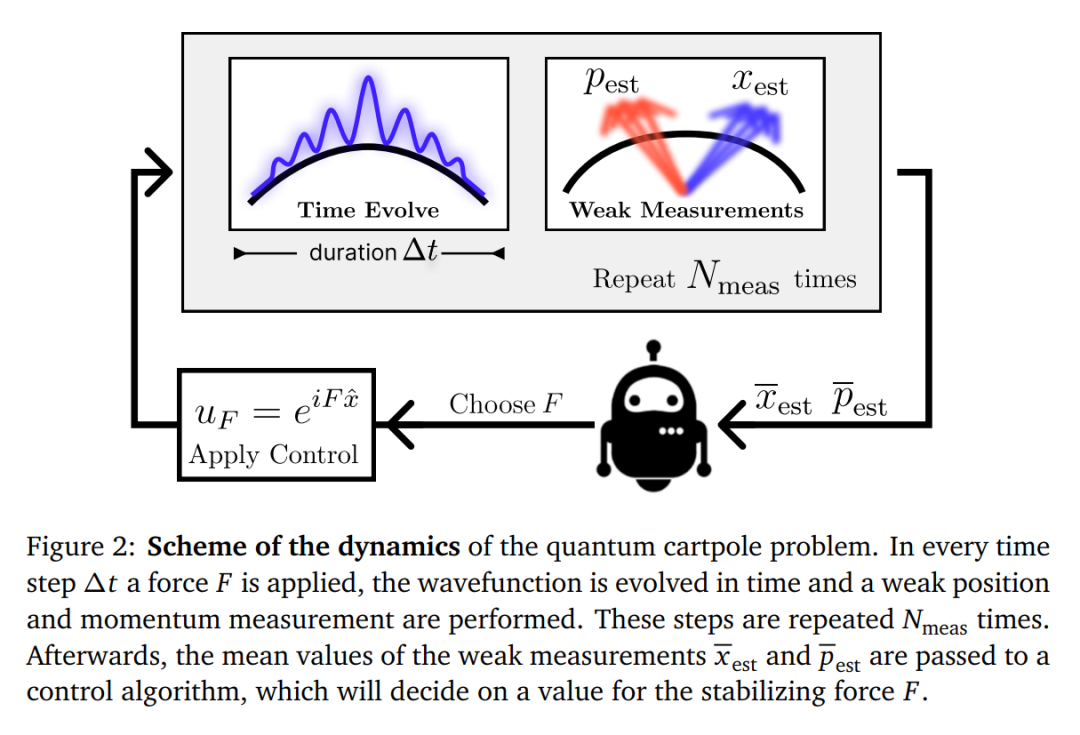
实验结果
在量子倒立摆环境中,强化学习控制器在非线性场景中表现出优于传统线性二次高斯控制(LQGC)算法的性能。特别是在高度非线性的四次势阱中,强化学习控制器的性能提升了约60%。此外,通过转移学习在经典系统上训练的智能体在量子系统上的表现几乎与专门在量子系统上训练的智能体相同,证明了转移学习的有效性。
论文链接:https://arxiv.org/abs/2311.00756v2
【总结】
强化学习与卡尔曼滤波的结合在控制领域展现出了巨大的潜力。无论是用于高效状态空间模型还是量子控制系统的非线性强化学习,这些方法都显著提升了模型在不确定性环境中的性能和鲁棒性。对于研究者来说,这些创新不仅提供了新的研究方向,还为发表创新性的论文提供了机会。未来,随着这些技术的进一步发展和优化,它们有望在更多的复杂控制任务中发挥重要作用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 31
31 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)