CNN-卷积神经网络
视觉处理三大任务:图像分类、目标检测、图像分割上游:特征提取,CNN下游:分类,目标,分割等
一、概述
视觉处理三大任务:图像分类、目标检测、图像分割
上游:特征提取,CNN 下游:分类,目标,分割等
卷积神经网络是深度学习在计算机视觉领域的突破性成果。它是一种专门用于处理具有网格状结构数据的深度学习模型,是含有卷积层的神经网络. 卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低运算量并特征增强;全连接层类似神经网络的部分,用来输出想要的结果。
二、卷积层
2.1、卷积核
卷积核是卷积运算过程中必不可少的一个“工具”,在卷积神经网络中,卷积核是非常重要的,它们被用来提取图像中的特征,卷积核其实就是一个矩阵。

2.2、卷积计算
卷积的过程是将卷积核在图像上进行滑动计算,每次滑动到一个新的位置时,卷积核和图像进行点对点的计算,并将其求和得到一个新的值,然后将这个新的值加入到特征图中,最终得到一个新的特征图。
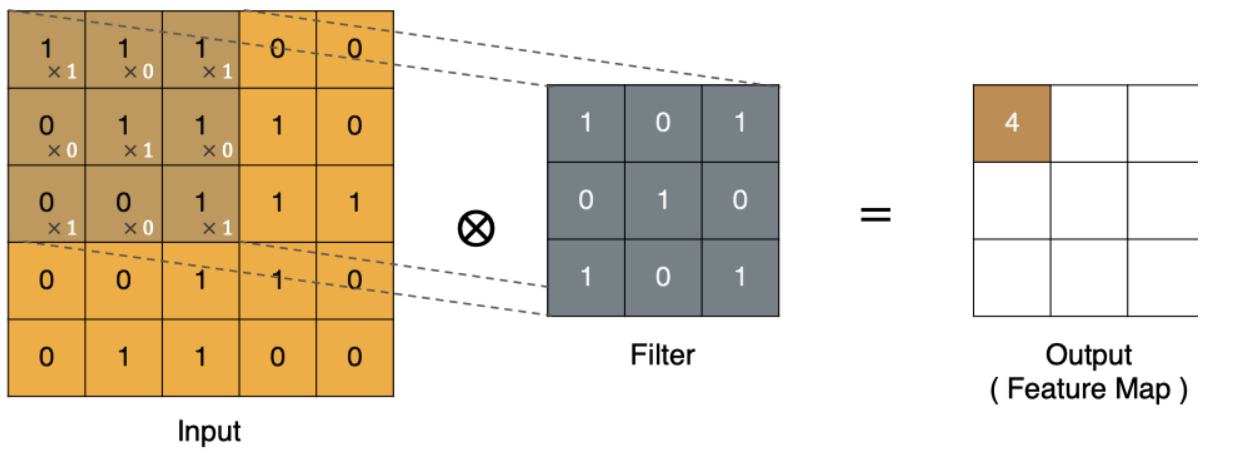
计算:
1x1+1x0+1x1+0x0+1x1+1x0+0x1+0x0+1x1=4
# 面向对象的模块化编程
from matplotlib import pyplot as plt
import os
import torch
import torch.nn as nn
def test001():
# 使用plt读取图片
img = plt.imread('./img/彩色.png')
print(img.shape)
# 转换为张量:HWC ---> CHW ---> NCHW 链式调用
img = torch.tensor(img).permute(2, 0, 1).unsqueeze(0)
# 创建卷积核 (501, 500, 4)
conv = nn.Conv2d(
in_channels=4, # 输入通道
out_channels=32, # 输出通道
kernel_size=(5, 3), # 卷积核大小
stride=1, # 步长
padding=0, # 填充
bias=True
)
# 使用卷积核对图像进行卷积操作 [9999] [[[[]]]]
out = conv(img)
# 输出128个特征图
conv2 = nn.Conv2d(
in_channels=32, # 输入通道
out_channels=128, # 输出通道
kernel_size=(5, 5), # 卷积核大小
stride=1, # 步长
padding=0, # 填充
bias=True
)
out = conv2(out)
# print(out)
# 把图像显示出来
print(out.shape)
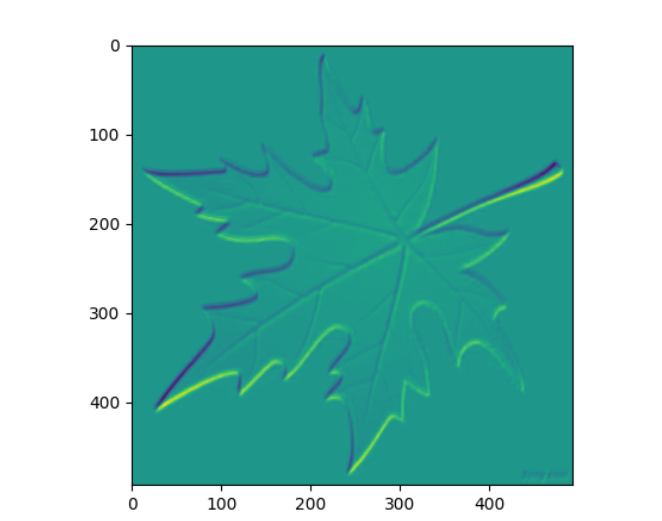
plt.imshow(out[0][10].detach().numpy())
plt.show()
# 作为主模块执行
if __name__ == "__main__":
test001()执行结果:
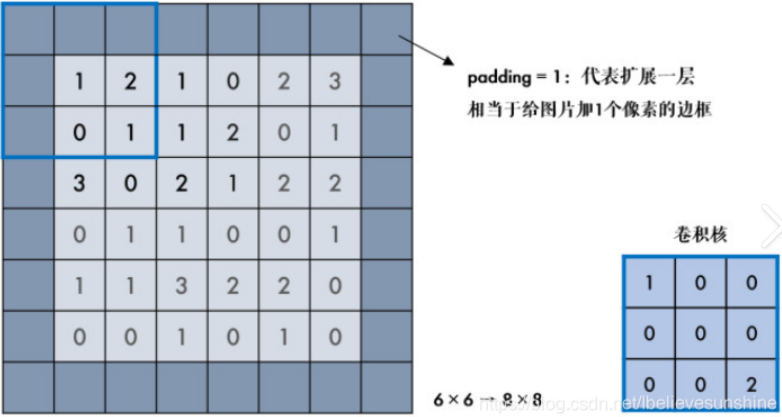
2.3、边缘填充
padding 边缘填充可以更好的保护图像边缘数据的特征。
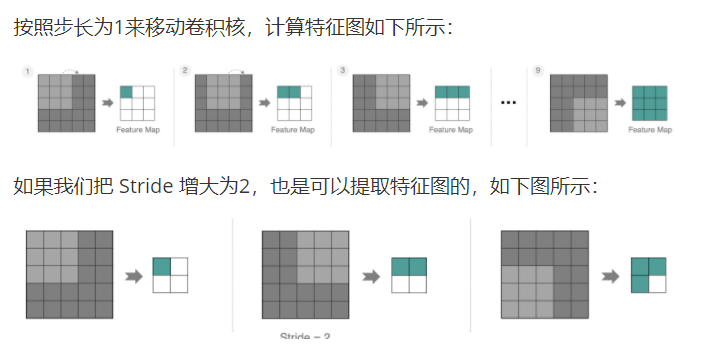
2.4、步长
stride太小:重复计算较多,计算量大,训练效率降低;
stride太大:会造成信息遗漏,无法有效提炼数据背后的特征;
三、池化层
3.1、概述
池化层 (Pooling) 降低空间维度, 缩减模型大小,提高计算速度。
池化层主要分为两种:
1、最大池化 max pooling
最大池化是从每个局部区域中选择最大值作为池化后的值,这样可以保留局部区域中最显著的特征。
2、平均池化 avgPooling
平均池化是将局部区域中的值取平均作为池化后的值,这样可以得到整体特征的平均值。
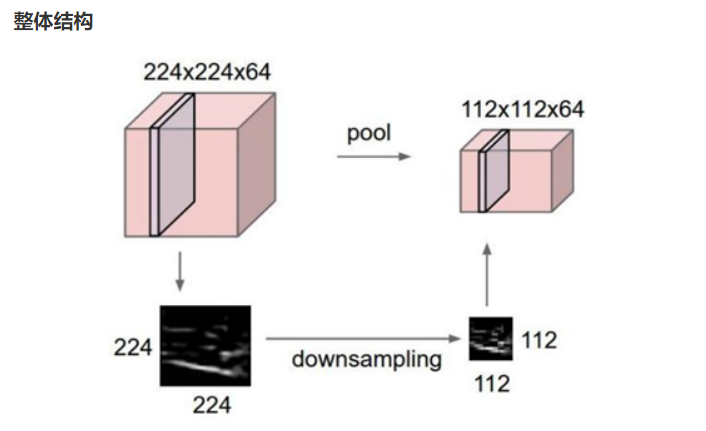
3.2、池化层的作用
优势:
-
通过降低特征图的尺寸,池化层能够减少计算量,从而提升模型的运行效率。
-
池化操作可以带来特征的平移、旋转等不变性,这有助于提高模型对输入数据的鲁棒性。
-
池化层通常是非线性操作,例如最大值池化,这样可以增强网络的表达能力,进一步提升模型的性能。
缺点:池化操作会丢失一些信息。
API:
最大池化层:kernel_size=2 卷积核大小为2,stride=2 步长为2
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)平均池化层:kernel_size=2 卷积核大小为2,stride=2 步长为2
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
四、卷积知识扩展
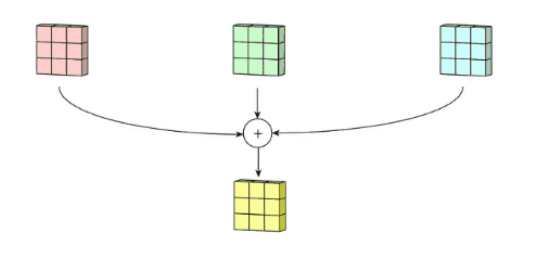
4.1、多通道卷积
最平常的彩色图片拥有R,G,B三层通道,所以会分别进行卷积,然后再将这三个通道的卷积结果进行合并。
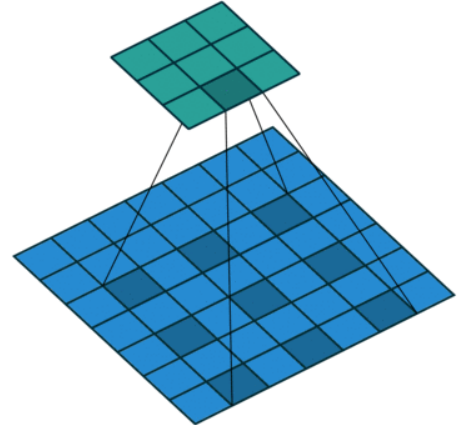
4.2、膨胀卷积
目的:为了扩大感受野。
在卷积核的元素之间插入空格“膨胀”内核,形成空洞卷积,并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,内核元素之间没有插入空格,变为标准卷积。当L=2时,内核元素之间插入一个空格,变成空洞卷积。
import torch
import torch.nn as nn
torch.nn.Conv2d(
in_channels=3, # 输入通道数
out_channels=16, # 输出通道数
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=0, # 填充
dilation=1, # 膨胀率(默认1为标准卷积)
)API:
dilation=1
4.3、可分离卷积
4.3.1、空间可分离卷积
空间可分离卷积是将卷积核分解为两项独立的核分别进行操作。在数学中我们可以将矩阵分解:
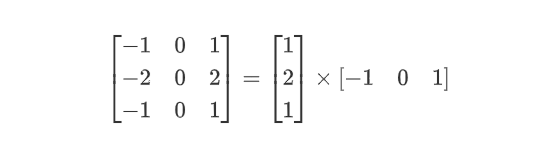
根据数学矩阵的理论我们可以:
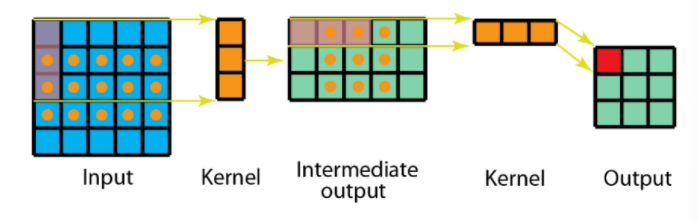
import torch
import torch.nn as nn
#可分离卷积
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.c1 = nn.Conv2d(
in_channels=1,
out_channels=1,
kernel_size=(3,1),
stride=1,
)
self.c2= nn.Conv2d(
in_channels=1,
out_channels=1,
kernel_size=(1, 3),
stride=1,
)
def forward(self, x):
x = self.c1(x)
out = self.c2(x)
return out
#正常卷积
class net(nn.Module):
def __init__(self):
super(net, self).__init__()
self.c1 = nn.Conv2d(
in_channels=1,
out_channels=1,
kernel_size=(3,3),
stride=1,
)
def forward(self, x):
x = self.c1(x)
return x
if __name__ == '__main__':
torch.manual_seed(1)
input_data = torch.randn(1, 1, 32,32)
model1 = Net()
out = model1(input_data)
model2 = net()
out1 = model2(input_data)
print(out.shape)
print(out1.shape)4.3.2、深度可分离卷积
深度可分离卷积由两部分组成:深度卷积核和1 * 1 逐点卷积

import torch
import torch.nn as nn
#深度可分离卷积
class DepthwiseSeparableConv(nn.Module):
def __init__(self):
super(DepthwiseSeparableConv, self).__init__()
self.depthwise = nn.Conv2d(
in_channels=8,
out_channels=8,
kernel_size=3,
stride=1,
groups=8
)
self.pointwise = nn.Conv2d(
in_channels=8,
out_channels=8,
kernel_size=1,
stride=1,
)
def forward(self, x):
x = self.depthwise(x)
out = self.pointwise(x)
return out
#正常卷积
class Conv(nn.Module):
def __init__(self):
super(Conv, self).__init__()
self.conv = nn.Conv2d(
in_channels=8,
out_channels=8,
kernel_size=3,
stride=1,
)
def forward(self, x):
out = self.conv(x)
return out
if __name__ == '__main__':
x = torch.randn(1, 8, 32, 32)
model = DepthwiseSeparableConv()
model1 = Conv()
out = model(x)
out1 = model1(x)
print(out.shape)
print(out1.shape)4.4、感受野
就是感受的视野范围。
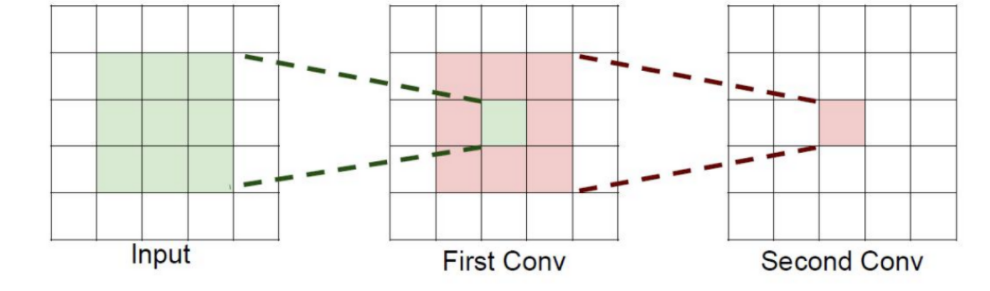
作用:所需的参数更少,卷积的过程更多了,特征提取也会更细致。
五、卷积神经网络案例
实现一个基于全连接层的神经网络,用于 CIFAR-10 图像分类任务。
import torch
from torch import nn,optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
#数据增强 随机水平翻转、随机旋转
def prepare_data():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.4914,0.4822,0.4465),(0.2023,0.1994,0.2010,)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(10)
])
# 测试集仅标准化
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载CIFAR-10数据集
train_set = datasets.CIFAR10(
root='./cifar10',
train=True,
transform=transform,
download=False
)
test_set = datasets.CIFAR10(
root='./cifar10',
train=False,
transform=test_transform,
download=False
)
# 创建数据加载器
train_loader = DataLoader(
dataset=train_set,
batch_size=64,
shuffle=True,
num_workers=4
)
test_loader = DataLoader(
dataset=test_set,
batch_size=512,
shuffle=False,
num_workers=4
)
return train_loader,test_loader
#模型架构
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
# 输入层 -> 隐藏层1
self.fc1 = nn.Linear(32 * 32 * 3, 1024)
self.bn1 = nn.BatchNorm1d(1024)
self.dropout1 = nn.Dropout(0.3)
# 隐藏层1 -> 隐藏层2
self.fc2 = nn.Linear(1024, 512)
self.bn2 = nn.BatchNorm1d(512)
self.dropout2 = nn.Dropout(0.3)
# 隐藏层2 -> 隐藏层3(新增)
self.fc3 = nn.Linear(512, 256) # 增加第三层
self.bn3 = nn.BatchNorm1d(256)
# 隐藏层3 -> 输出层
self.fc4 = nn.Linear(256, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 32 * 32 * 3)
x = self.dropout1(self.bn1(self.fc1(x)))
x = self.relu(x)
x = self.dropout2(self.bn2(self.fc2(x)))
x = self.relu(x)
x = self.bn3(self.fc3(x))
x = self.relu(x)
x = self.fc4(x)# 最终输出(logits)
return x
#训练流程
def train(model, train_loader, epochs, device):
model.train()
criterion = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(opt, mode='min', factor=0.5, patience=10)
for epoch in range(epochs):
count = 0
loss_sum = 0
for x, y in train_loader:
# 将数据移到指定设备
x, y = x.to(device), y.to(device)
# 前向传播 + 反向传播
y_pred = model(x)
loss = criterion(y_pred, y)
opt.zero_grad()
loss.backward()
opt.step()
# 统计准确率
loss_sum += loss.item()
_, pred = torch.max(y_pred, dim=1)
count += (pred == y).sum().item()
avg_loss = loss_sum / len(train_loader)
acc = count / len(train_loader.dataset)
print(f"Epoch [{epoch + 1}/{epochs}], Loss: {avg_loss:.4f}, Acc: {acc:.4f}")
# 学习率调度
scheduler.step(avg_loss)
#评估流程
def eval(model, test_loader, device):
model.eval()
eval_loss = 0
count = 0
criterion = nn.CrossEntropyLoss()
with torch.no_grad(): # 关闭梯度计算,加速推理
for x, y in test_loader:
# 将数据移到指定设备
x, y = x.to(device), y.to(device)
y_pred = model(x)
# 计算损失和准确率
eval_loss += criterion(y_pred, y).item()
_, pred = torch.max(y_pred, dim=1)
count += (pred == y).sum().item()
eval_loss /= len(test_loader)
acc = 100 * count / len(test_loader.dataset)
print(f"Test Loss: {eval_loss:.4f}, Acc: {acc:.4f}")
#整体运行逻辑
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
model = MyNet().to("device")
train_loader,test_loader = prepare_data()
#训练模型
train(model,train_loader,epochs=25,device=device)
#评估模型
eval(model,test_loader,device=device)
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)