知识抽取与挖掘
本文内容仅仅是一个学习内容的梳理,无具体知识点的细节。
目录
一、知识抽取定义
从不同来源,不同结构的数据中,进行知识的提取,并形成知识,存入到知识图谱
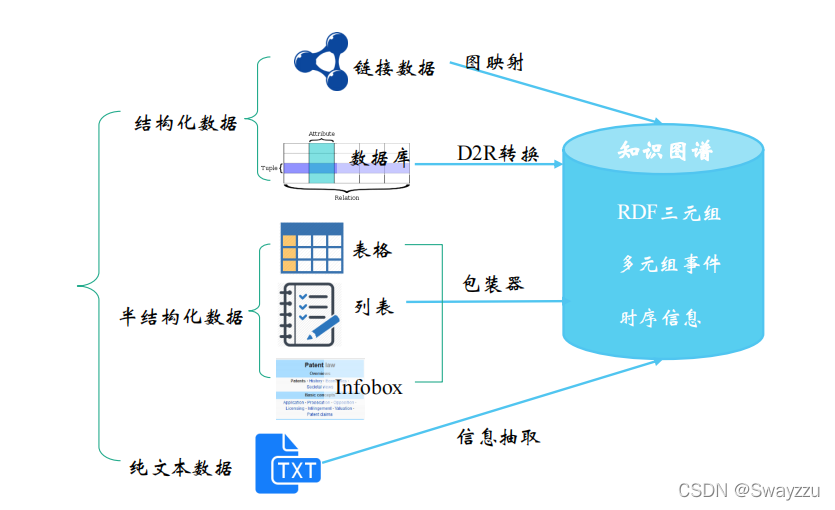
二、知识抽取关键技术
根据知识的来源,有来自于结构化数据,链接数据,半结构化数据,以及文本数据,每一个数据来源,都有对应的关键技术难点,如下图所示

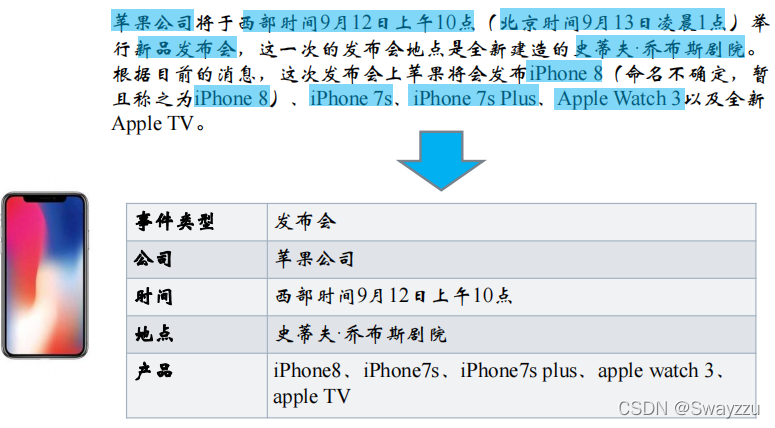
三、面向非结构化数据的抽取任务
1.实体识别
如下,句子中类似于地点信息,时间信息,人物信息等等,只要是我们需要的重点信息,都可以认为是实体。
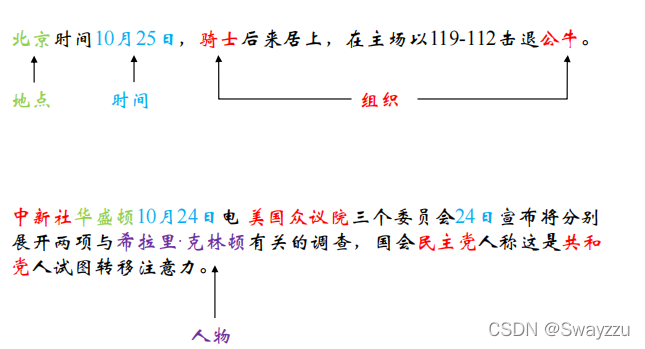
通常,我们可以使用序列标注,进行实体实体识别,比如HMM,或者CRF,Bi-LSTM方法等。
2.关系抽取
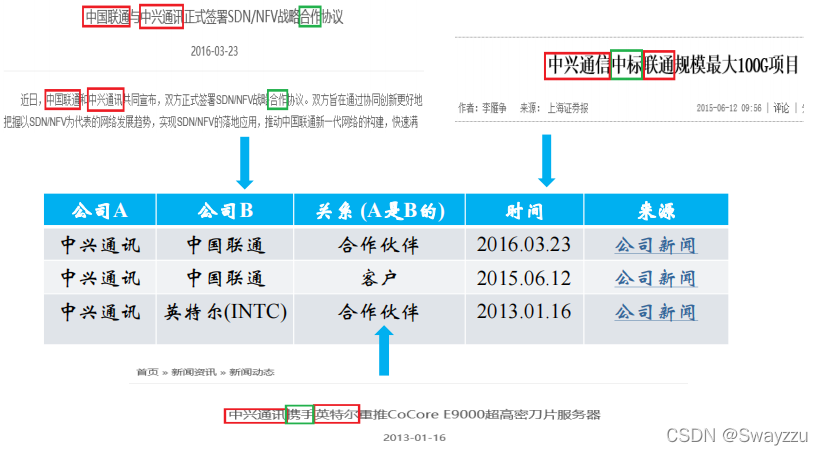
①关系抽取举例
如下图所示,根据一句话,我们可以抽取出实体之间的关系,比如王健林和王思聪是父子关系等。

②关系抽取方法
这里只做总结,不进行详细描述。
基于模板的方法:
→设定触发词,比如“老婆”,那么文本中出现“老婆”的时候,它的前后的实体就可能是夫妻关系。
→基于依存句法,比如A现身于B,这里“现身于”是核心词,A和B可能是定语、宾语,这样就可以根据语法来抽取关系。
监督学习方法:
重点是特征设计,可以使用以下内容作为特征

模型可以使用Bi-LSTM+attention,CNN+attention等
半监督学习方法:
→远程监督方法:比如知识库中存在“创始人(乔布斯,苹果公司)”,那么就可以从非结构化文本中,把包含这两个实体的句子,作为训练样例。
→bootstrapping方法:之前有写文章介绍过,以及改进版的snowball,这里不再描述。
3.事件抽取
相关术语:

举例如下:

事件抽取中,联合抽取方法效果相对较好,也就是通过多个模型,进行联合预测。
四、面向结构化数据的抽取任务
通过比如D2R, Vitruoso, Morph等工具,以及Direct Mapping或R2RML等语言,将数据提取。
Direct Mapping 举例如下:

R2RML 举例如下:

五、面向半结构化数据的抽取任务
1.百科类数据
比如维基百科等,通常都会有自己的数据的目录,以及对知识的具体描述
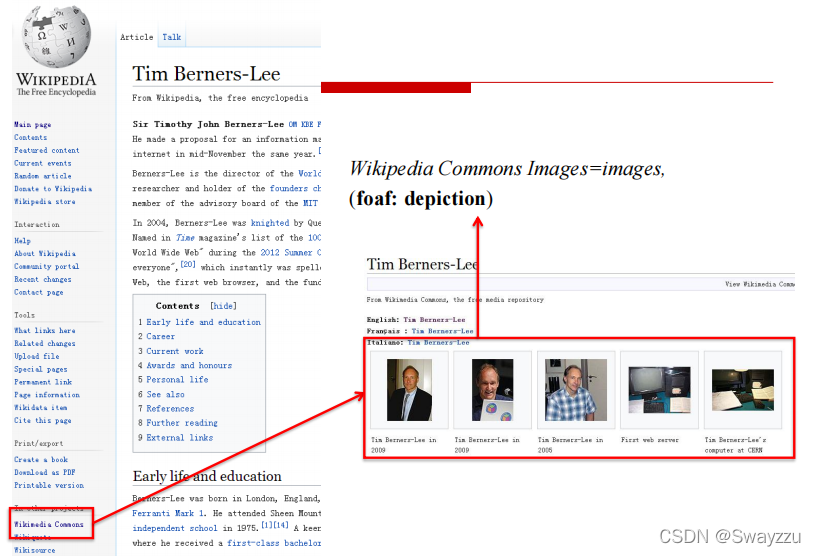
通过映射,将半结构化的数据存入知识库。
2.网页类数据
①手工方式提取
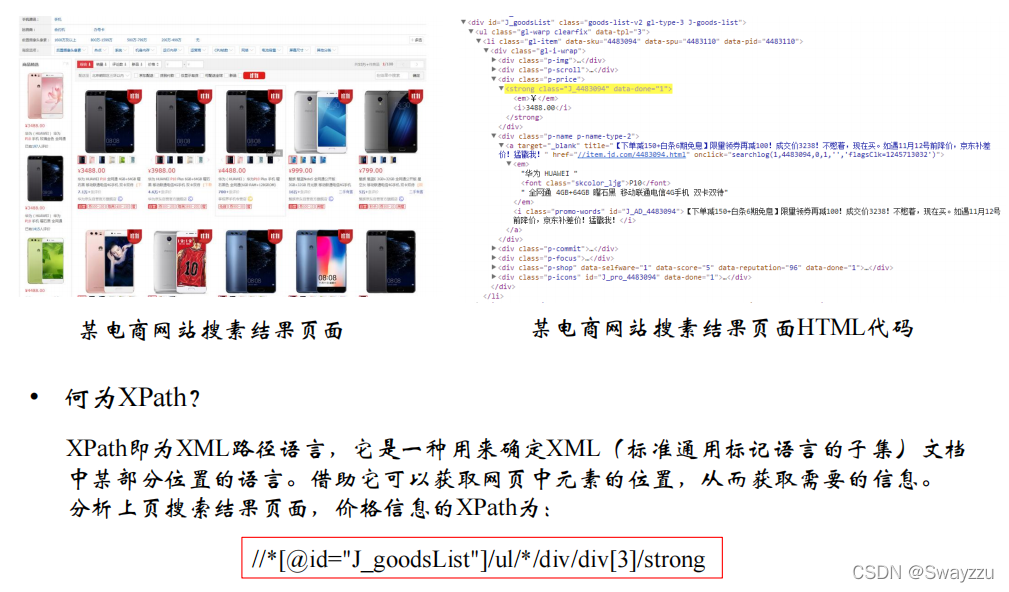
上面是通过XPath进行的提取,也可以通过CSS:

②包装器方式抽取
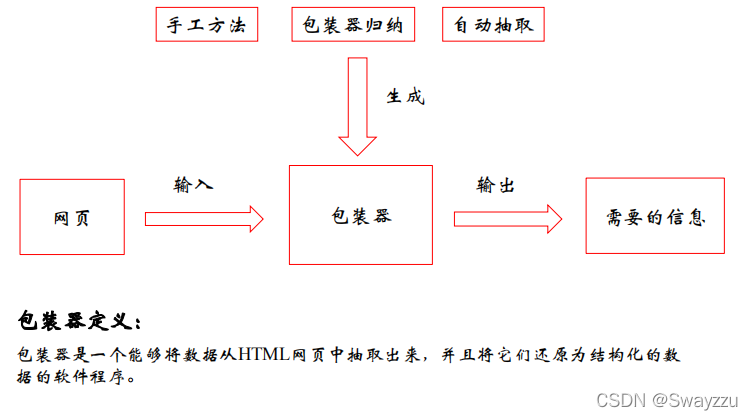
举例如下:
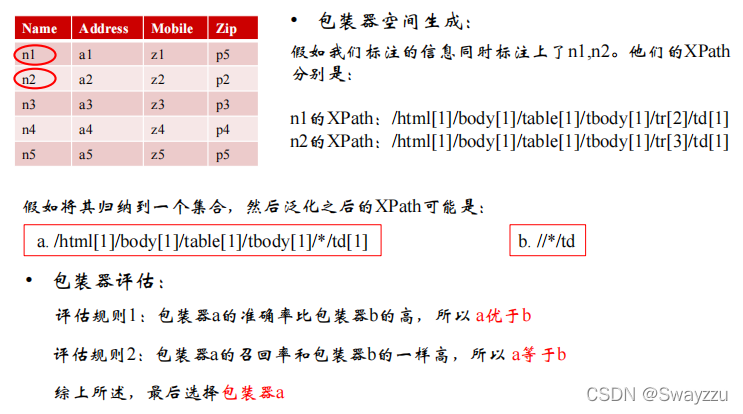
③自动抽取
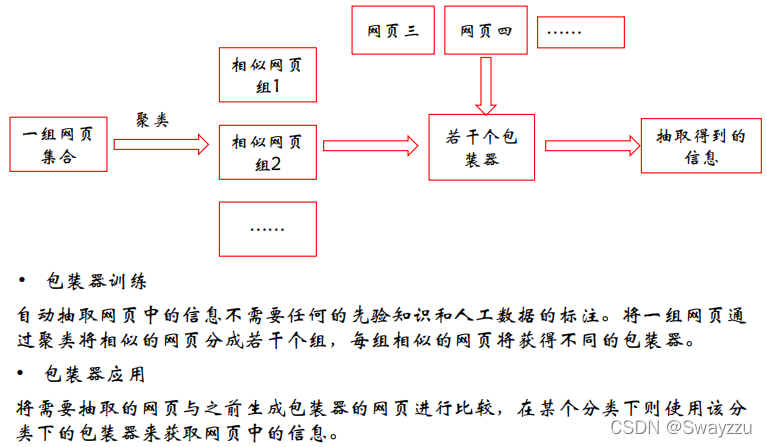


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)