强化学习|什么是强化学习?
强化学习是一种通过不断尝试和错误反馈来学习规律、实现目标的机器学习方法,类似于计算机通过虚拟老师(如反馈分数)来决定哪些行为在特定环境中能获得高分或避免低分。与监督学习不同,强化学习无需预设数据和标签,而是在实际环境中持续探索和学习。实际应用中,如AlphaGo利用强化学习在围棋比赛中取得胜利,展示了其强大潜力。强化学习中提及的算法,如Q-Learning和Deep Q Network,通过模拟环
一、强化学习概念介绍
强化学习reinforcement learning。强化学习是一类算法,是让计算机实现从一开始什么都不懂,脑袋里一点想法都没有。通过不断的尝试,从错误中学习,最后找到规律学习到达到目标的方法,这就是一个完整的强化学习过程。实际中的强化学习例子很多,比如近期最有名的alphago机器头一次的围棋场上战胜人类的高手,让计算机自己学着如何玩经典的游戏,这些都是让计算机在不断的尝试中更新自己的行为准则,从这个进一步的学习如何下好围棋,这个如何操控游戏而得到高分。

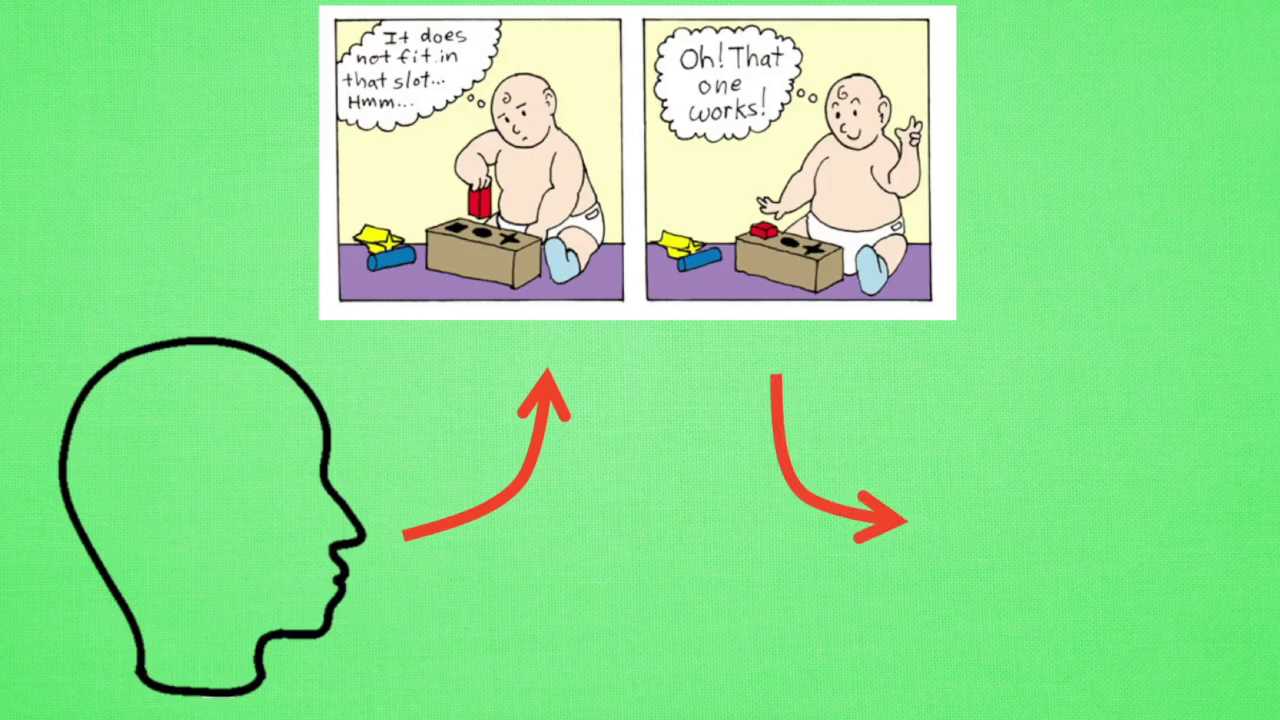
(一)计算机如何自己进行学习?——强化学习的本质(打分)
既然要计算机自己学,那么计算机是通过什么样的方法来学习呢?原来计算机也需要一位虚拟的好老师,这位老师比较吝啬,他不会告诉你如何行动,如何做决定,他为你做的事情只有给你的行为打分。那我们应该以什么样的形式学习这些现有的资源,或者说怎么样从分数中学习出我们应该怎么样做决定呢?很简单,我只需要记住那些高分低分对应的行为,下一次用同样的行为拿到高分,并避免低分的行为。比如老师会根据我的开心程度来打分,我开心时可以得到高分,我不开心的时候得到低分。有了这些被打分的经验,我就能判断,为了得到高分,我应该选取一张开心的脸,避免选到伤心的脸。这也是强化学习的核心思想。




(二)改如何理解强化学习中的分数
可以看出,在强化学习中,一种行为的分数十分重要,所以强化学习具有分数导向性。我们换一个角度来思考,这种分数导向性好比我们在监督学习中的正确标签。我们知道,监督学习是已经有了数据和数据对应的正确标签,比如这样,监督学习就能学习出哪些脸对应哪些标签。不过,强化学习还要更进一步,一开始他并没有数据和标签,他需要通过一次次在环境中的尝试获取这些数据和标签,然后再学习通过哪些数据能够对应上哪些标签,通过学习这样的规律,尽可能的选择带来高分的行为。比如这里的开心点,这也证明了在强化学习中,分数标签就是他的老师,他和监督学习中的老师也差不多。

(三)强化学习的分类?
强化学习是一个大家族,它包含了很多算法,我们也会一一提到最终的一些比较有名的算法。比如有通过行为的价值来选取特定行为的方法,包括使用表格学习的q-learning傻傻或者神经网络学习的deep q network,还有直接输出行为的power galaxy gradients。

二、学习疑问解答
(一)强化学习和智能体之间的联系和区别?两者是否一致?
强化学习(Reinforcement Learning, RL)和智能体(Agent)是两个紧密相关但本质不同的概念,它们的联系与区别可以从定义、角色和应用场景等方面展开分析。
(1)核心定义
1. 强化学习(RL)
- 本质:是一种机器学习方法论,研究智能体如何在环境交互中通过试错学习策略,以最大化长期累积奖励。
- 核心要素:
- 环境(Environment):智能体之外的一切,提供状态和奖励反馈。
- 智能体(Agent):执行决策的主体,通过动作影响环境。
- 状态(State):环境的描述,智能体决策的依据。
- 动作(Action):智能体在状态下的选择。
- 奖励(Reward):环境对动作的反馈信号,指导学习目标。
- 目标:优化策略(Policy),即从状态到动作的映射关系,使长期奖励最大化。
2. 智能体(Agent)
- 本质:是一个具有感知、决策和执行能力的实体,能够在环境中自主行动以实现目标。
- 核心组件:
- 感知模块:获取环境状态(如传感器数据)。
- 决策模块:根据状态和目标选择动作(可能基于规则、算法或学习模型)。
- 执行模块:作用于环境(如机器人的机械臂)。
- 范畴:智能体是一个更广泛的概念,其决策机制可以基于多种方法,包括:
- 强化学习(如 AlphaGo Zero)、监督学习(如图像分类机器人)、传统算法(如基于规则的聊天机器人)等。
(2)联系:强化学习是智能体的 “大脑” 之一
-
强化学习为智能体提供决策算法
智能体通过强化学习算法(如 Q-learning、策略梯度、深度强化学习 DRL)从环境中学习策略,实现自主决策。例如:- 机器人通过强化学习学习避障策略;
- 游戏 AI(如 OpenAI Five)通过强化学习掌握复杂游戏策略。
-
智能体是强化学习的 “执行者”
强化学习的理论框架必须通过智能体与环境的交互才能落地。智能体的感知、动作空间定义了强化学习问题的边界(如状态维度、动作离散 / 连续),其与环境的互动数据(状态 - 动作 - 奖励序列)是强化学习算法的训练素材。
(3)、区别:范畴、角色与独立性
| 维度 | 强化学习 | 智能体 |
|---|---|---|
| 本质 | 机器学习方法论(算法层面) | 具自主决策能力的实体(系统层面) |
| 关注点 | 如何设计算法让智能体 “学习” | 如何实现感知、决策、执行的完整闭环 |
| 独立性 | 不能独立存在,需依赖智能体和环境 | 可独立存在(如基于规则的智能体) |
| 目标 | 优化策略以最大化奖励 | 完成特定任务(奖励仅是目标的一种形式) |
| 典型问题 | 如何设计高效的探索 - 利用平衡策略 | 如何融合多传感器数据、处理延迟等工程问题 |
(4)是否一致?—— 两者完全不同,但深度耦合
-
不一致性
- 强化学习是方法论,智能体是实体。
- 一个智能体可以不使用强化学习(如传统控制算法的机器人),而强化学习必须通过智能体才能体现价值。
-
耦合性
在现代 AI 中,强化学习常作为智能体决策模块的核心算法,尤其在需要自主适应动态环境的场景(如自动驾驶、机器人控制)中。此时,智能体的 “智能” 很大程度上来源于强化学习的优化能力。
(5)典型场景举例
-
使用强化学习的智能体
- AlphaStar(星际争霸 AI):智能体通过深度强化学习(DRL)学习战略决策,感知游戏状态(如单位位置、资源量),执行建造、攻击等动作。
- 波士顿动力机器人:智能体通过强化学习优化运动控制策略,适应复杂地形。
-
不使用强化学习的智能体
- 基于规则的智能恒温器:根据预设温度阈值开关空调,决策不依赖学习算法。
- 监督学习驱动的图像分类机器人:通过预训练模型识别物体并执行动作,无需与环境持续交互学习。
(6)总结
- 联系:强化学习是智能体实现自主决策的重要工具,智能体是强化学习的物理载体。
- 区别:强化学习属于算法层面的方法论,智能体是包含感知、决策、执行的完整系统。
- 是否一致? 不一致,但在实际应用中常深度结合 ——强化学习为智能体赋予 “学习能力”,而智能体为强化学习提供 “落地场景”。理解两者的差异有助于更清晰地设计 AI 系统:例如,当优化算法时聚焦强化学习理论,当处理工程问题时则需从智能体的整体架构出发。
(二)强化学习在工业界有什么作用?为什么我们要学习强化学习?
强化学习在工业界的核心作用:通过模拟环境交互优化复杂决策,解决传统算法难以应对的动态问题。在智能制造中,可优化产线调度(如特斯拉产线效率提升12%)、预测设备故障(宝马减少65%停机时间);能源领域,实现电网储能动态调节(Google数据中心冷却能耗降40%)和可再生能源并网优化(国家电网弃风率降至5%以下);智能物流中,动态规划货车路径(UPS年省3亿美元燃油)、提升仓储周转率(京东缺货率降40%);机器人场景则用于高精度装配(波士顿动力魔方复原)和巡检(大疆无人机效率提升5倍),显著提升各行业自动化水平与效率。
学习强化学习的关键价值:其“试错-反馈-优化”机制适配现实复杂决策需求,是自动驾驶、机器人等前沿领域的核心技术。工业界对该技能人才需求旺盛,2025年相关岗位平均年薪达45万元,且需融合数学、工程与领域知识,具备跨行业迁移能力(如从医疗药物研发到工业能效优化)。此外,强化学习与数字孪生、5G结合推动产业智能化转型(如华为矿山AI调度效率提升30%),掌握它可在技术竞争中占据先机,成为连接算法理论与工业实践的关键角色。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)