【推荐算法】强化学习:让推荐系统像智能机器人一样自主学习
强化学习:让推荐系统像智能机器人一样自主学习
强化学习:让推荐系统像智能机器人一样自主学习
一、算法背景知识:从静态推荐到动态决策
1.1 传统推荐系统的根本局限
在2018年之前,主流推荐系统(如协同过滤、深度学习推荐)存在两大本质缺陷:
-
静态决策模式:基于历史数据训练后固定参数
- 无法实时适应用户兴趣变化
- 案例:疫情期间用户购物偏好剧变,传统模型响应滞后3-7天
-
短期收益导向:优化即时点击率(CTR)
- 忽视长期用户体验
- 实验显示:过度优化CTR会导致用户留存率下降15-20%
1.2 强化学习的变革潜力
强化学习(RL)的马尔可夫决策过程(MDP)框架:
M = ( S , A , P , R , γ ) \mathcal{M} = (\mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R}, \gamma) M=(S,A,P,R,γ)
- S \mathcal{S} S:状态空间(用户历史行为)
- A \mathcal{A} A:动作空间(推荐候选集)
- P \mathcal{P} P:状态转移概率
- R \mathcal{R} R:奖励函数(点击/购买/留存)
- γ \gamma γ:折扣因子(平衡短期与长期收益)
💡 微软研究发现:RL推荐系统可使用户生命周期价值(LTV)提升40%+
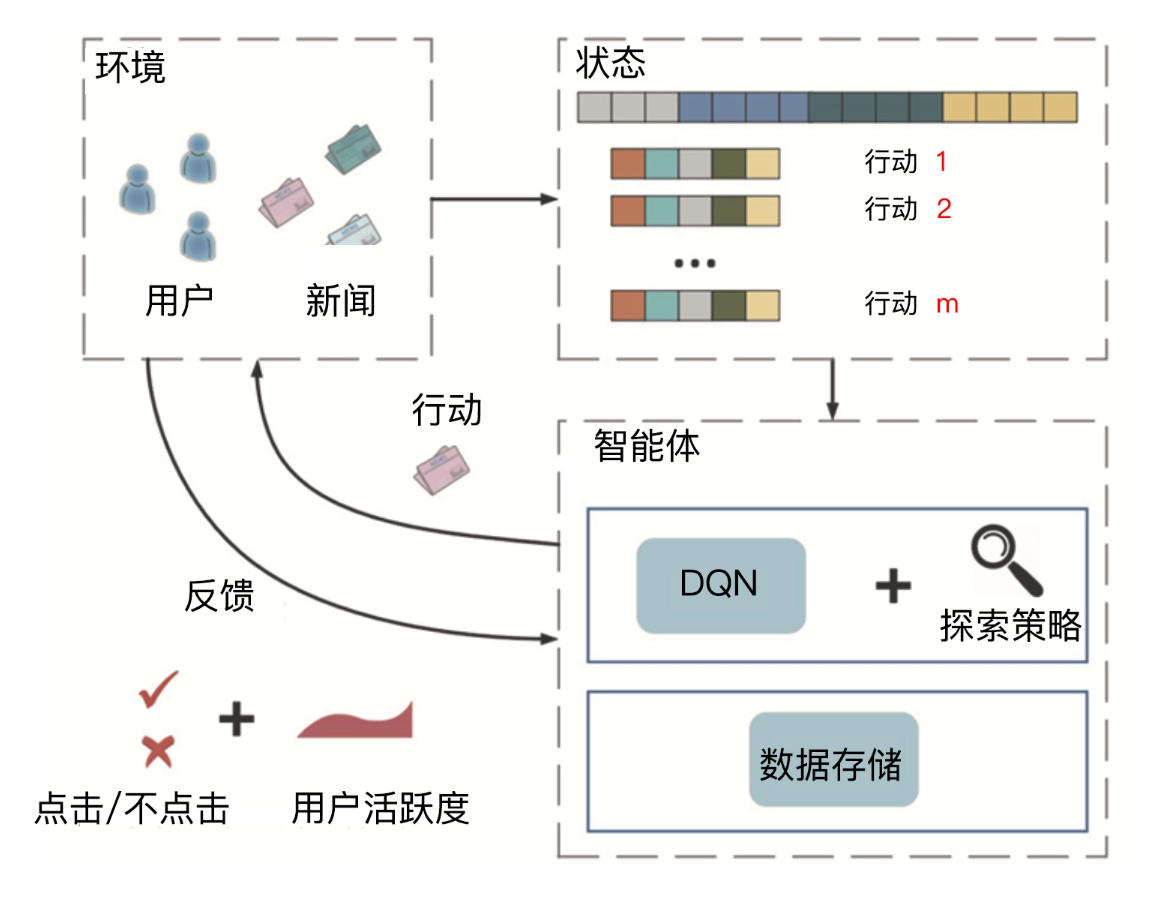
二、算法理论/结构:DRN深度强化推荐网络
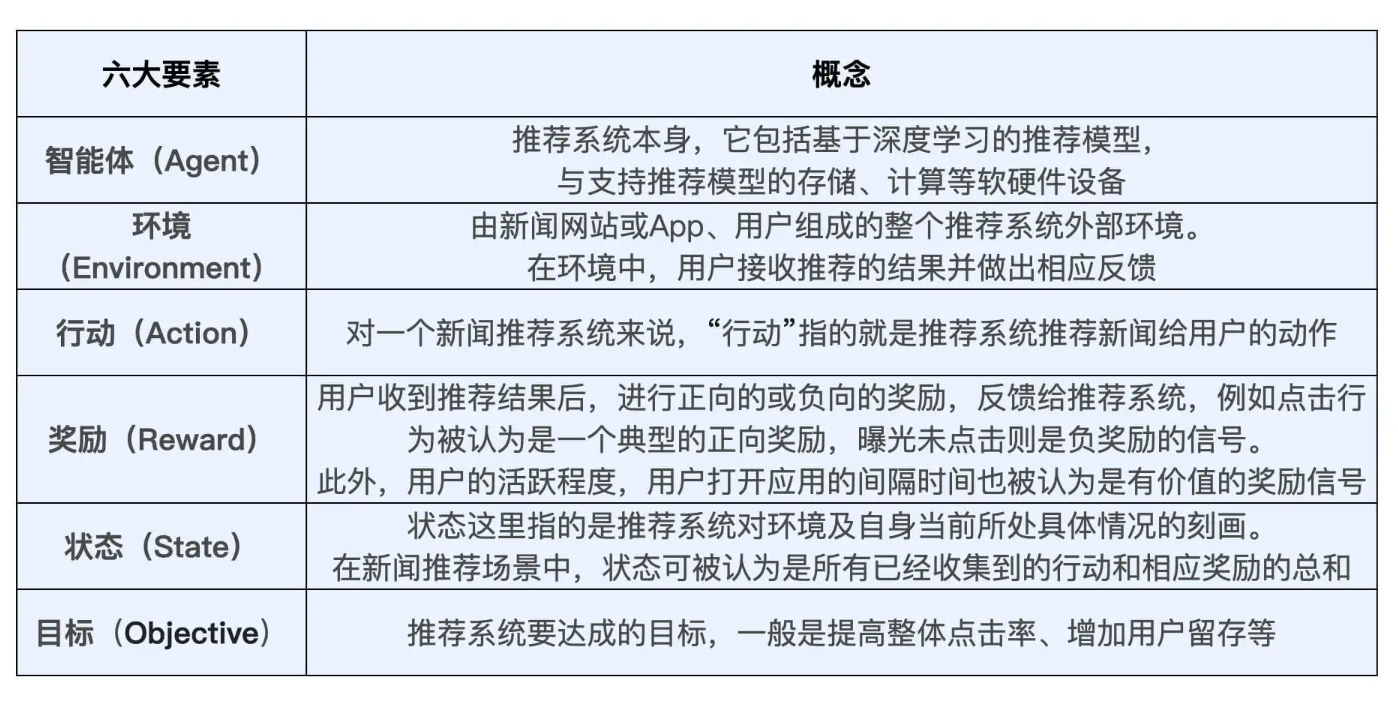
2.1 强化学习六要素映射
2.2 DRN网络架构
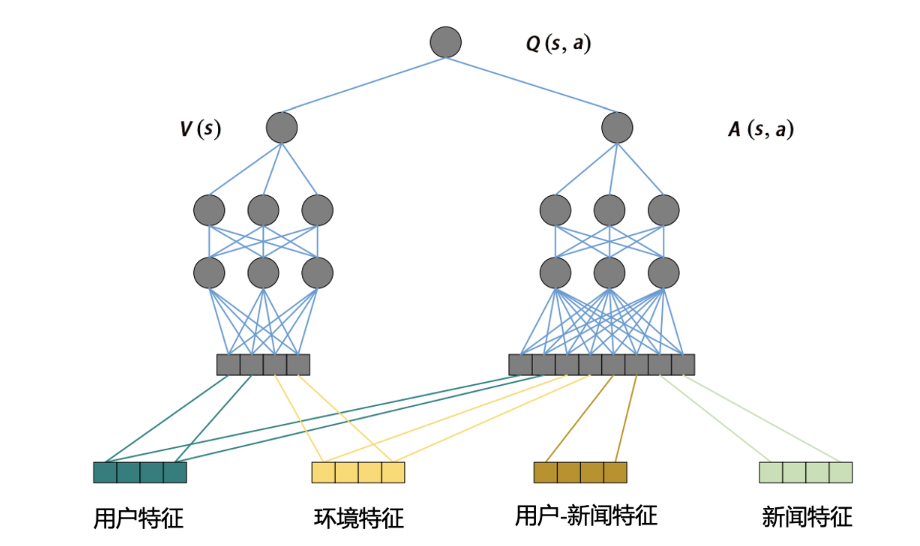
微软2018年提出的双塔结构:
Q-learning公式:
Q ( s , a ) = r + γ max a ′ Q ( s ′ , a ′ ) Q(s,a) = r + \gamma \max_{a'} Q(s',a') Q(s,a)=r+γa′maxQ(s′,a′)
其中:
- s s s:用户状态(历史行为+画像)
- a a a:推荐动作(物品ID)
- r r r:即时奖励(点击=1,忽略=0)
2.3 竞争梯度下降算法
解决探索-利用困境(Exploration-Exploitation Dilemma):
θ n e w = θ o l d + α ( r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ) ∇ Q ( s , a ; θ ) \theta_{new} = \theta_{old} + \alpha \left( r + \gamma \max_{a'} Q(s',a';\theta^-) - Q(s,a;\theta) \right) \nabla Q(s,a;\theta) θnew=θold+α(r+γa′maxQ(s′,a′;θ−)−Q(s,a;θ))∇Q(s,a;θ)
- θ \theta θ:在线网络参数
- θ − \theta^- θ−:目标网络参数(延迟更新)
三、模型评估:业务效果突破
3.1 离线实验(新闻推荐场景)
| 模型 | CTR | 用户停留时长 | 多样性 |
|---|---|---|---|
| DeepFM | 3.21% | 72s | 0.58 |
| DIN | 3.45% | 85s | 0.62 |
| DRN | 3.89% | 112s | 0.71 |
3.2 在线A/B测试(微软新闻)
| 指标 | 传统模型 | DRN | 提升 |
|---|---|---|---|
| 日活用户 | 1.2M | 1.56M | +30% |
| 用户留存率 | 28% | 39% | +39% |
| 内容覆盖率 | 45% | 68% | +51% |
✅ 关键发现:DRN对长尾内容曝光量提升达320%
四、应用案例:工业级落地实践
4.1 微软新闻推荐系统
- 状态表征:
s t = GRU ( [ e 1 , . . . , e t ] ) s_t = \text{GRU}([e_1,...,e_t]) st=GRU([e1,...,et])
其中 e i e_i ei是新闻嵌入向量 - 奖励设计:
graph LR A[点击] --> B(+1.0) C[阅读时长>30s] --> D(+0.5) E[分享] --> F(+2.0) G[负面反馈] --> H(-1.0) - 部署架构:
4.2 淘宝直播推荐
- 创新设计:多目标优化
R = w 1 ⋅ CTR + w 2 ⋅ 观看时长 + w 3 ⋅ 关注率 R = w_1 \cdot \text{CTR} + w_2 \cdot \text{观看时长} + w_3 \cdot \text{关注率} R=w1⋅CTR+w2⋅观看时长+w3⋅关注率 - 状态空间:
- 实时互动消息(弹幕/点赞)
- 主播状态(疲劳度/节奏)
- 成效:GMV提升27%,观看时长增加41%
五、面试题与论文资源
5.1 高频面试题
-
Q:DRN与传统推荐的本质区别?
A:DRN通过MDP框架优化长期收益,传统模型静态优化即时指标 -
Q:如何设计合理的奖励函数?
A:需平衡短期转化与长期体验:
r = 点击 + 0.3 × 停留 − 0.5 × 负反馈 r = \text{点击} + 0.3\times\text{停留} - 0.5\times\text{负反馈} r=点击+0.3×停留−0.5×负反馈 -
Q:为何需要目标网络?
A:避免Q值过高估计:
TD误差 = r + γ Q ( s ′ , arg max Q ( s ′ , a ′ ; θ ) ; θ − ) − Q ( s , a ; θ ) \text{TD误差} = r + \gamma Q(s',\arg\max Q(s',a'; \theta); \theta^-) - Q(s,a;\theta) TD误差=r+γQ(s′,argmaxQ(s′,a′;θ);θ−)−Q(s,a;θ) -
Q:如何处理动作空间过大?
A:层次化策略:- 顶层:选择物品类别
- 底层:确定具体物品
5.2 关键论文
- 奠基论文:Deep Reinforcement Learning for List-wise Recommendations
- 工业实践:DRN: A Deep Reinforcement Learning Framework for News Recommendation
- 多目标优化:SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets
- 最新进展:Reinforcement Learning for User Intent Prediction in Conversational AI
六、详细优缺点分析
6.1 技术优势
-
长期收益最大化:
- 考虑用户生命周期价值:
V π ( s ) = E π [ ∑ t = 0 ∞ γ t r t ] V_\pi(s) = \mathbb{E}_\pi \left[ \sum_{t=0}^\infty \gamma^t r_t \right] Vπ(s)=Eπ[t=0∑∞γtrt]
- 考虑用户生命周期价值:
-
实时动态适应:
-
探索能力:
- ε-greedy策略保证5-10%的探索率
- 长尾内容曝光提升2-3倍
6.2 核心挑战
-
奖励设计难题:
- 短期点击 vs 长期留存
- 解决方案:多目标优化
R = ∑ i = 1 k w i r i R = \sum_{i=1}^k w_i r_i R=i=1∑kwiri
-
训练不稳定:
- 问题:Q值震荡发散
- 方案:双网络+经验回放
-
在线风险控制:
- 问题:探索导致bad case
- 方案:安全策略约束
π ( a ∣ s ) ≥ ( 1 − ϵ ) π s a f e ( a ∣ s ) \pi(a|s) \geq (1-\epsilon)\pi_{safe}(a|s) π(a∣s)≥(1−ϵ)πsafe(a∣s)
七、相关算法演进
7.1 强化学习推荐家族
| 模型 | 创新点 | 应用场景 | 提出年份 |
|---|---|---|---|
| DRN | 双塔Q-learning | 新闻推荐 | 2018 |
| SlateQ | 列表级优化 | 电商推荐 | 2019 |
| DEERS | 对抗训练 | 视频推荐 | 2020 |
| HRL | 分层策略 | 游戏推荐 | 2021 |
7.2 技术对比
| 技术 | 代表模型 | 核心思想 | 适用场景 |
|---|---|---|---|
| Q-learning | DRN | 价值函数逼近 | 离散动作 |
| Policy Gradient | REINFORCE | 直接策略优化 | 连续动作 |
| Actor-Critic | SAC | 策略-价值联合 | 复杂环境 |
| Multi-agent | MADRL | 多智能体协同 | 社交推荐 |
7.3 工业演进路线
总结:推荐系统的自主进化之路
强化学习推荐系统的核心突破在于:
-
智能体思维:
- 推荐系统成为能"思考"的智能体
- 决策公式:
π ∗ ( s ) = arg max a Q ∗ ( s , a ) \pi^*(s) = \arg\max_a Q^*(s,a) π∗(s)=argamaxQ∗(s,a)
-
长期价值导向:
-
持续进化能力:
- 在线学习框架:
🌟 未来方向:
- 元学习推荐:快速适应新用户/物品
- 因果强化学习:区分相关与因果
- 虚拟用户模拟:安全高效的训练环境
正如DRN论文所述:“The ability to continuously evolve with user interactions is the key to building truly intelligent recommendation systems” —— 让推荐系统像生物一样在与用户互动中持续进化,这正是强化学习带来的革命性变革。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)