建筑兔零基础自学python记录21|实战人脸识别项目——视频人脸识别(上)10
对比分类器、识别器/recogizer.predict() /对比EigenFaces 、FisherFaces和LBPH/+=/全局变量和局部变量/cv.putText()/str()/+ 号撒腿右下跑,- 号转身左上飘
本次我们来尝试识别视频中的人脸,识别前需要跑上一次的代码,大家先打开备用~建筑兔零基础自学python记录20|实战人脸识别项目——数据训练09-CSDN博客
还是先上源代码,依旧很长但一部分是我们学过的代码了。在上一次分析结构的基础上,这次我们先来理解其整体结构~
import cv2
import os
recogizer=cv2.face.LBPHFaceRecognizer_create()
recogizer.read('M:/python/workspace/PythonProject/trainer/trainer.yml')
names=[]
warningtime = 0
def face_detect_demo(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
face_detector=cv2.CascadeClassifier('M:/python/pythoninstall/Lib/site-packages/cv2/data/haarcascade_frontalface_alt.xml')
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
#print('标签id:',ids,'置信评分:', confidence)
if confidence > 80:
global warningtime
warningtime += 1
cv2.putText(img, 'unknown', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv2.imshow('result',img)
def name():
path = 'M:/python/workspace/PythonProject/face/'
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
cap=cv2.VideoCapture('test3.mp4')
name()
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv2.waitKey(10):
break
cv2.destroyAllWindows()
cap.release()
print(names)1 代码结构:
可以看到整个代码主要分为5大部分:

2 视频人脸检测情况:
这一次我们先尝试运行代码看看识别情况如何~本次运行需要先运行上一次的代码(数据训练09),我在face人脸学习文件夹里放入了两张照片,并获得了一个trainer.yml的训练结果。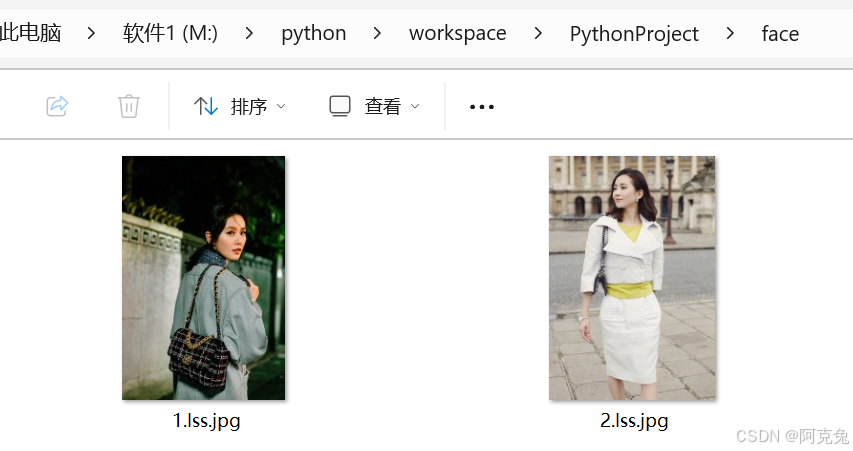
然后运行本次代码,可得下面视频结果:
人脸识别视频检测
可以看到识别出了目标人脸,其余都标注为unknown。


3.具体代码解读
我们把之前出现过的代码先进行一下标注:
import cv2
#导入与操作系统交互 os 模块
import os
#创建一个 LBPH(局部二值模式直方图)人脸识别器对象,用于训练和识别人脸。
recogizer=cv2.face.LBPHFaceRecognizer_create()
#读取训练好的人脸识别模型yml文件
recogizer.read('M:/python/workspace/PythonProject/trainer/trainer.yml')
#初始化一个空列表names,用于存储人脸对应的名称。
names=[]
#初始化一个全局变量warningtime,用于记录未知人脸出现的次数。
warningtime = 1
#自定义人脸识别
def face_detect_demo(img):
#彩图转化为灰图
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#调用人脸识别分类器
face_detector=cv2.CascadeClassifier('M:/python/pythoninstall/Lib/site-packages/cv2/data/haarcascade_frontalface_alt.xml')
#灰图中检测人脸
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
#原彩图中用红色矩形框人脸
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
#人脸中心画绿圆
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)(1)两个人脸识别器的区别(Haar/LBPH)

综上我们可以看出Haar属于分类器,而LBPH属于识别器。
后面就是没有学过的代码,我们来逐一解读:
(2)recogizer.predict( )识别输入人脸进行判断输出
recogizer.predict() 识别输入人脸,判断该人脸属于哪个预定义的类别(标签),并给出识别结果的置信度。
参数——输入图像:这是一个灰度图像,代表要进行识别的人脸。
- 标签 ID(
ids):它是一个整数,代表识别出的人脸对应的预定义标签。 - 置信度评分(
confidence):它是一个浮点数,用于衡量识别结果的可靠程度。置信度评分越低表示识别结果越可靠。在 LBPH 算法中,置信度评分通常在 0 到 200 之间,通常会设定一个阈值(如 80)来判断识别结果是否可信。如果置信度评分高于阈值,则认为识别结果不可靠,可能是未知人脸。
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w]) 本行代码意为:加载已训数的人脸识别器 recogizer 对人脸区域进行识别,得到对应的标签 ids 和置信度评分 confidence。
(3)对比EigenFaces 、FisherFaces和LBPH分类器

所以我们用2张图就实现了人脸识别,这正是LBPH的长处。换用其他两个分类器反而不好完成效果。
(4)人脸识别的置信度来判断识别结果的代码
if confidence > 80:
global warningtime
warningtime += 1
print('warningtime=',warningtime)
cv2.putText(img, 'unknown', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)recogizer.predict( )代码中我们学到:
置信度评分越低表示识别结果越可靠。在 LBPH 算法中,置信度评分通常在 0 到 200 之间,通常会设定一个阈值(如 80)来判断识别结果是否可信。如果置信度评分高于阈值,则认为识别结果不可靠,可能是未知人脸。
所以这里的if判断的就是置信度>80则输出警告,在识别框标注unknown,并在warningtime进行计数。反之则标注names列表中的名称。
其中有关warningtime的代码涉及:
global warningtime
warningtime += 1
print('warningtime=', warningtime)
global warningtime:声明warningtime为全局变量。因为在函数内部如果要修改全局变量的值,需要使用global关键字进行声明,否则 Python 会将其视为局部变量。warningtime += 1:将warningtime的值加 1,用于记录未知人脸出现的次数。print('warningtime=', warningtime):打印当前未知人脸出现的次数,方便调试和监控。
(5) +=
warningtime += 1-
+=是 Python 中的复合赋值运算符。 warningtime += 1等价于warningtime = warningtime + 1。
(6)全局变量和局部变量
全局变量从程序开始时创建,直到程序结束时才被销毁。整个运行过程中一直存在于内存中。
局部变量从其所在的函数、类或代码块被调用时开始创建,当执行结束后,所占用的内存会被释放,即局部变量被销毁。
举例:在函数内部可以直接访问全局变量
要修改全局变量的值,需要使用 global 关键字进行声明

(7) cv2.putText ()在图像上绘制文本
cv2.putText(img, text, org, fontFace, fontScale, color, thickness=None, lineType=None, bottomLeftOrigin=None)
#必须参数
cv2.putText(img, text, org, fontFace, fontScale, color)
cv2.putText(图片, 文本, 坐标, 字体,大小, 颜色)img:必需。要在其上绘制文本的图像。通常是一个 NumPy 数组,其数据类型一般为uint8,可以是单通道(灰度图像)或多通道(彩色图像)。text:必需。要绘制的文本内容。org:必需。文本字符串的起始坐标,是一个二元组(x, y),其中x表示水平方向的位置,y表示垂直方向的位置。在图像坐标系中,原点(0, 0)通常位于图像的左上角。fontFace:必需。指定字体类型,例如:cv2.FONT_HERSHEY_DUPLEX:比FONT_HERSHEY_SIMPLEX更复杂的字体。cv2.FONT_HERSHEY_PLAIN:一种细的无衬线字体。cv2.FONT_HERSHEY_SIMPLEX:一种简单的无衬线字体,是比较常用的字体类型。
fontScale:必需。控制字体的大小,是一个浮点数。值越大,字体越大。color:必需。指定文本的颜色。对于彩色图像,颜色通常表示为一个三元组(B, G, R),分别代表蓝色、绿色和红色通道的值,取值范围为 0 - 255;对于灰度图像,颜色为一个单值,表示灰度强度。thickness:可选。文本线条的粗细,默认值为 1。该参数为整数类型,值越大,线条越粗。lineType:可选。线条的类型。bottomLeftOrigin:可选参数。是一个布尔值,默认值为False。如果设置为True,则图像数据原点位于左下角;如果设置为False,则原点位于左上角。
cv2.putText(img, 'unknown', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)我们来解读一下代码,图像上的文本要求:
cv2.putText(img, 'unknown', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)——在图像上绘制文本,文本是unknown,位置是(x + 10, y - 10),字体无衬线,字体大小0.75,绿色
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)——在图像上绘制文本,文本是names列表中的,位置是(x + 10, y - 10),字体无衬线,字体大小0.75,绿色
(8)str( )将对象转换为字符串
str() 将对象转换为字符串,通俗理解就是要把给机器看的内容转化给人看。string简写为str,意为串。
str(names[ids-1])ids - 1
- Python 列表的索引是从 0 开始的,而人脸识别标签 ID 通常从 1 开始。
ids - 1为了两个表能对上。 - 也就是将name列表中的内容转化为字符串
(9)字符串和数字的互相翻译
str() 是将对象转换为字符串,那如果想反向操作是什么命令呢?

(10) OpenCV坐标移动规律简记
+ 号撒腿右下跑,- 号转身左上飘
在OpenCV中+表达向→向↓,-表达向←向↑。
所以代码中表示x + 10:x 坐标向右偏移 10 个像素。y - 10: y 坐标向上偏移 10 个像素。

综上后一部分代码我们可以解读为:
#识别输入人脸,获取标签ids,置信度confidence
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
#如果置信度confidence>80
if confidence > 80:
#warningtime作为全局变量
global warningtime
#每次出现都+1
warningtime += 1
#控制台输出warningtime=,值为warningtime
print('warningtime=',warningtime)
#图像上绘制文本,文本是unknown,位置是x向右偏移10个像素。y向上偏移10个像素,字体无衬线,字体大小0.75,绿色
cv2.putText(img, 'unknown', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
#图像上绘制文本,文本是names列表中的,其余同上
#坐标移动规律:+ 号撒腿右下跑,- 号转身左上飘
cv2.putText(img,str(names(ids-1)), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
#弹出窗口名为result
cv2.imshow('result',img)本次我们解读了从开始到定义人脸识别的部分,内容已经很多了。后续两个部分我们下次继续解读~
总结:
- Haar属于分类器,而LBPH属于识别器
recogizer.predict()识别输入人脸进行判断输出。评分越低越可靠,一般 LBPH用80来判断。- 对比EigenFaces 、FisherFaces(最好)和LBPH分类器(最少)
+=复合赋值运算符- 全局变量和局部变量
cv2.putText()在图像上绘制文本
cv2.putText(img, text, org, fontFace, fontScale, color)
cv2.putText(图片, 文本, 坐标, 字体,大小, 颜色)
- str( )将对象转换为字符串/int()float()字符串转换为对象
-
OpenCV坐标移动规律简记:+ 号撒腿右下跑,- 号转身左上飘

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)