基于深度增强学习的路径规划算法【附代码】
✅博主简介:本人擅长建模仿真、数据分析、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。基于深度增强学习的路径规划算法在近年来得到了广泛的关注,特别是在机器人流程自动化(RPA)的领域中,自动化路径规划能够显著提高效率、降低成本,并减少人为错误。RPA的任务往往涉及大量的重复性操作,适用于自动化处理,但由于操作环境复杂多变,路径规划的精度和效率仍然面临挑战。

✅博主简介:本人擅长建模仿真、数据分析、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
基于深度增强学习的路径规划算法在近年来得到了广泛的关注,特别是在机器人流程自动化(RPA)的领域中,自动化路径规划能够显著提高效率、降低成本,并减少人为错误。RPA的任务往往涉及大量的重复性操作,适用于自动化处理,但由于操作环境复杂多变,路径规划的精度和效率仍然面临挑战。本文针对RPA中的路径规划问题,提出了一种基于改进深度增强学习方法的路径规划算法,特别是改进的双深度Q网络(Double Deep Q Network,DDQN)算法,并通过创新的采样策略和环境建模提升算法性能。以下是本文的主要内容。
1. 针对RPA环境的路径规划问题分析
RPA在各类业务流程中的应用已经非常广泛,包括财务、客户服务等领域,然而其操作环境往往存在复杂的页面结构和交互元素,例如Web页面中的大量重复内容、位置变化和语义模糊等问题。这种复杂性导致路径规划任务变得更加困难,因为传统的增强学习算法无法准确获取环境中的关键信息,尤其是在语义分析和位置信息方面容易出现偏差。
为了解决这一问题,本文引入了隐喻地图的概念,将页面上的交互元素进行抽象,并将元素之间的相对位置信息通过类地图方式表示出来。这种方法不仅能够有效保留页面元素之间的逻辑关系,还能为增强学习模型提供更为清晰的环境反馈。通过这种虚拟环境建模,增强学习模型可以更好地探索路径,有效提高路径规划的准确性和效率。
隐喻地图的思想为增强学习模型提供了一个相对完整的环境反馈,使模型能够更加准确地理解操作对象之间的关联性。在模型学习过程中,虚拟环境能够为每个页面元素的动作反馈提供明确的指示,从而确保路径探索的有效性。
2. 改进的采样策略与优先级计算
为了提升DDQN算法的探索效率,本文提出了一种改进的采样策略。传统的增强学习算法在路径规划中面临的问题之一是探索过程中的样本采集效率低下,常常因为样本选择不当而导致训练过程出现偏差。特别是当样本的优先级与实际的重要性不符时,模型的训练会受到影响。
本文基于排名的优先级采样策略(rank-based prioritization),结合元素位置信息的杰卡德系数作为优先度,从而优化了样本采集的过程。杰卡德系数是一种衡量集合相似度的指标,通过将其与位置信息结合,能够在采样过程中更精确地反映样本的重要性。相比于传统的优先级采样策略,该方法显著减少了采样过程中的偏差,确保了每个样本在采样过程中的贡献度能够与其实际的重要性相一致。
这一改进采样策略的优势在于:首先,它能够通过结合位置信息,使得样本的选择更加合理,有效地提高了模型在复杂环境中的探索效率。其次,通过改进后的采样策略,模型能够更快地收敛,并且减少了训练过程中无效样本的影响。实验结果表明,改进的采样策略在处理复杂路径规划任务时具有较好的效果。
3. 基于深度双Q网络(DDQN)的路径规划算法
深度Q网络(DQN)算法是增强学习中的一种经典方法,它通过利用神经网络估计Q值,实现了复杂环境中的路径规划。然而,DQN算法在某些情况下容易出现过估计问题,导致模型学习路径时收敛速度慢,甚至无法找到最优路径。为此,本文采用了改进的双深度Q网络(DDQN)算法,进一步提升路径规划的性能。
DDQN的核心思想是通过分别估计当前策略和目标策略中的Q值,来减少Q值的过估计问题。本文基于这一思想,对DDQN算法进行了进一步的优化,主要包括以下两点:
-
Focal-CIoU损失的优化:在传统DDQN算法的基础上,本文对边界框损失函数进行了改进,采用了Focal-CIoU损失函数。该函数能够更好地处理路径规划过程中涉及的空间位置约束问题,尤其在处理复杂环境中的目标检测时,能够有效减少边界框预测的误差。
-
双网络结构的优化:本文进一步优化了DDQN的双网络结构,通过动态调整目标网络的更新频率,确保模型能够更稳定地学习到不同场景下的路径规划策略。同时,引入了经验回放机制,提升了训练样本的利用率,避免了训练过程中的样本浪费问题。
通过上述优化,改进后的DDQN算法能够在复杂路径规划任务中表现出更好的稳定性和收敛速度,特别是在面对大量不确定性的RPA任务环境时,该算法能够快速找到最优路径,有效提高了任务执行的效率和准确性。
4. 实验验证与比较分析
为了验证本文提出的基于改进DDQN算法的路径规划方法的有效性,本文设计了一系列实验,比较了不同算法在相同实验环境下的表现。实验包括DQN、DDQN、PPO(Proximal Policy Optimization)和SAC-Discrete(Soft Actor-Critic离散版)算法,目的是通过随机任务样本的抽取,评估各算法在路径规划任务中的收敛速度、迭代次数以及模型的稳定性。
实验结果表明,改进后的DDQN算法在路径规划任务中的表现优于其他算法。具体而言,该算法在迭代次数上显著减少,收敛速度更快,且在面对复杂环境时表现出更强的鲁棒性。特别是在RPA任务中,改进的DDQN算法能够更快地找到最优路径,并且在路径执行过程中错误率较低,这表明了该算法在实际应用中的可行性。
此外,实验还显示,PPO和SAC-Discrete等算法在处理简单路径规划任务时表现出较好的效果,但在复杂环境中容易陷入局部最优解,难以达到全局最优。而改进的DDQN算法则通过更合理的采样策略和优化的双网络结构,能够更加有效地探索复杂的路径空间,确保模型在各种任务场景下均能找到最优解。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random
# 定义Q网络
class QNetwork(nn.Module):
def __init__(self, state_size, action_size, seed):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_size)
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 定义DDQN智能体
class DDQNAgent:
def __init__(self, state_size, action_size, seed, gamma=0.99, lr=0.001):
self.state_size = state_size
self.action_size = action_size
self.seed = random.seed(seed)
self.gamma = gamma
self.lr = lr
self.qnetwork_local = QNetwork(state_size, action_size, seed)
self.qnetwork_target = QNetwork(state_size, action_size, seed)
self.optimizer = optim.Adam(self.qnetwork_local.parameters(), lr=self.lr)
self.memory = deque(maxlen=100000)
self.batch_size = 64
self.tau = 0.001
def step(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
if len(self.memory) > self.batch_size:
experiences = self.sample()
self.learn(experiences)
def act(self, state, eps=0.):
state = torch.from_numpy(state).float().unsqueeze(0)
self.qnetwork_local.eval()
with torch.no_grad():
action_values = self.qnetwork_local(state)
self.qnetwork_local.train()
if random.random() > eps:
return np.argmax(action_values.cpu().data.numpy())
else:
return random.choice(np.arange(self.action_size))
def learn(self, experiences):
states, actions, rewards, next_states, dones = experiences
Q_targets_next = self.qnetwork_target(next_states).detach().max(1)[0].unsqueeze(1)
Q_targets = rewards + (self.gamma * Q_targets_next * (1 - dones))
Q_expected = self.qnetwork_local(states).gather(1, actions)
loss = nn.MSELoss()(Q_expected, Q_targets)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.soft_update(self.qnetwork_local, self.qnetwork_target, self.tau)
def soft_update(self, local_model, target_model, tau):
for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):
target_param.data.copy_(tau*local_param.data + (1.0-tau)*target_param.data)
def sample(self):
experiences = random.sample(self.memory, k=self.batch_size)
states = torch.from_numpy(np.vstack([e[0] for e in experiences if e is not None])).float()
actions = torch.from_numpy(np.vstack([e[1] for e in experiences if e is not None])).long()
rewards = torch.from_numpy(np.vstack([e[2] for e in experiences if e is not None])).float()
next_states = torch.from_numpy(np.vstack([e[3] for e in experiences if e is not None])).float()
dones = torch.from_numpy(np.vstack([e[4] for e in experiences if e is not None]).astype(np.uint8)).float()
return (states, actions, rewards, next_states, dones)
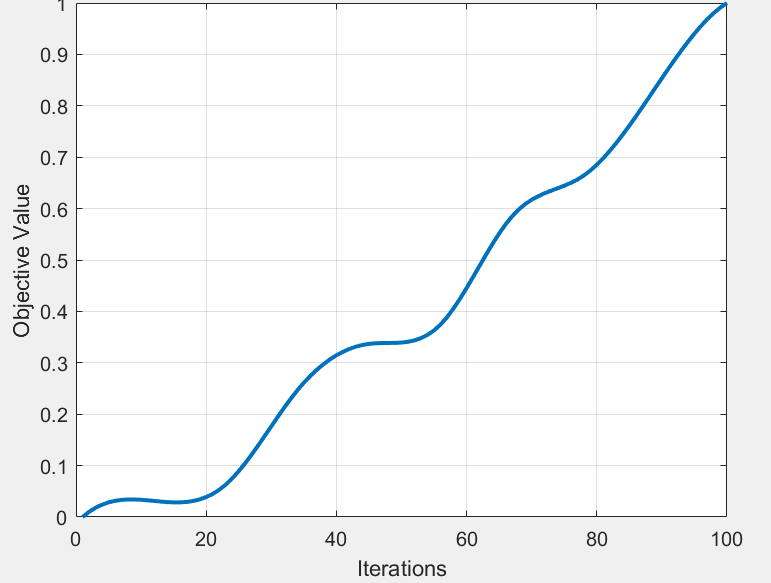

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)