2024年最全Python实现自动问答系统(毕设源码)_python构造判断题答题程序(1),字节跳动算法工程师面试经验
1、项目结构|------data/ # 数据存放|------dicts/ # 存放特征词(运行build_cakg.py后自动生成)|------question/ # 存放问句中的疑问词|------reference/ # 存放指代词|------tail/ # 存放尾词(后缀词)|------data.json # 从年报中组织出的数据|------raw.7z # 11-19年的年报。
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
平台
- Windows 10 x64
- Python 3.7
- Neo4j community 3.5.20
(文末源码可分享)
运行
1、确保安装所需依赖
pip install -r requirements.txt
注:python-Levenshtein 如果安装不成功,则可以下载对其进行离线安装。
2、构建知识图谱
修改const.py文件中连接数据库使用的URI,USERNAME和PASSWORD的值。然后执行:
python build_cakg.py
运行大约需要2~5分钟。
3、可以使用两种方式运行:
①. 运行命令行端
python run_cmd.py
普通问题的回答以字符串的形式给出;带有图表的回答,图表会被渲染至results文件夹中。
②. 运行web端(效果图见下文)
python run_web.py
带有图表的回答和普通回答一样会被渲染至web页面中,同时也被保存至本地results文件夹中。
注1:最好使用谷歌浏览器(Google Chrome);
注2:生成图表的文件夹地址可以在const.py中更改CHART_RENDER_DIR。
4、have fun!
简介
1、项目结构
--------------------------------------- root
|------data/ # 数据存放
|------dicts/ # 存放特征词(运行build_cakg.py后自动生成)
|------question/ # 存放问句中的疑问词
|------reference/ # 存放指代词
|------tail/ # 存放尾词(后缀词)
|------data.json # 从年报中组织出的数据
|------raw.7z # 11-19年的年报
|------demo/ # 以jupyter-notebook的形式给出了各种问题类型的演示和说明
|------doc/ # 存放有关readme的文件
|------lib/ # 函数库
|------results/ # 存放某些问题生成的图表(会自动生成)
|------test/ # 存放一些单元测试
|------web/ # web app
......
|------answer_search.py # 回答组织器
|------build_cakg.py # 构建知识图谱
|------chatbot.py # 自动问答器
|------const.py # 常量
|------question_classifier.py # 分类器
|------question_parser.py # 解析器
......
2、数据组织
①. 基本构想
通过浏览公报发现:
- 每一年所涉及的目录大差不差,有时多有时少,或者只是改个名字;
- 目录中涉及的指标每年都有一定的变动,而且某些指标里面嵌套指标,还有些指标中给出了各地区的组成值;
- 指标的值有数值类型,也有字符串类型,有的有单位,有些则没有,而且有些单位在某些年份还不同。
基于上述几点,我将知识图谱的构建以年份为中心展开,将各个目录、指标等等实体作为知识图谱的结点。结点与结点之间相连接的关系称为结构关系(详细见下文),那么将每个年份结点到各个指标和地区的关系称为值关系(详细见下文)。
将结构和值两种关系拆开:
- 从结构关系来看,不用一个年度录入一个年度的所有指标,每个年度中肯定有重复指标,这样避免了数据冗余。若每年的指标位置基本不变,则上述做法直接可行,但实际上指标出现的位置可能每年都飘忽不定,所以若直接按上述做法会出现这种情况:
假设2012年指标C1包含指标A、B,指标C2包含指标C;2013年指标C1包含指标A,指标C2包含指标B、C;则其结构关系为:
其中橙色的边是2012年特有的,蓝色的则是2013年特有的,而黑色的是它们共有的。但在知识图谱中这些边没有颜色之分,是按上图整个结构存储的,这就造成了一个父子结构关系错乱的问题,比如:我要查找13年指标C1包含的所有指标,则A和B都会被返回,而实际上B不应该被返回。
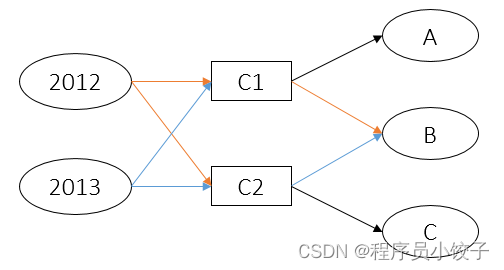
为了解决上述问题,并且不增加任何额外的关系,我为每个关系引入了一个生命周期属性life。这个属性运用了掩码的思想,每个年份维护自己的掩码(运行构建知识图谱脚本时会被自动生成),在遇到上述问题时,拿来和关系中的life做与运算,若结果不为0,就说明此年份包含此指标,反之则不含。
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)
👉五、Python练习题
检查学习结果。
👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)