【scikit-learn】交叉验证及其用于参数选择、模型选择、特征选择的例子_交叉验证 模型选择 调参 流程(2)
上面的测试准确率可以看出,不同的训练集、测试集分割的方法导致其准确率不同,而交叉验证的基本思想是:将数据集进行一系列分割,生成一组不同的训练测试集,然后分别训练模型并计算测试准确率,最后对结果进行平均处理。这样来有效降低测试准确率的差异。
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。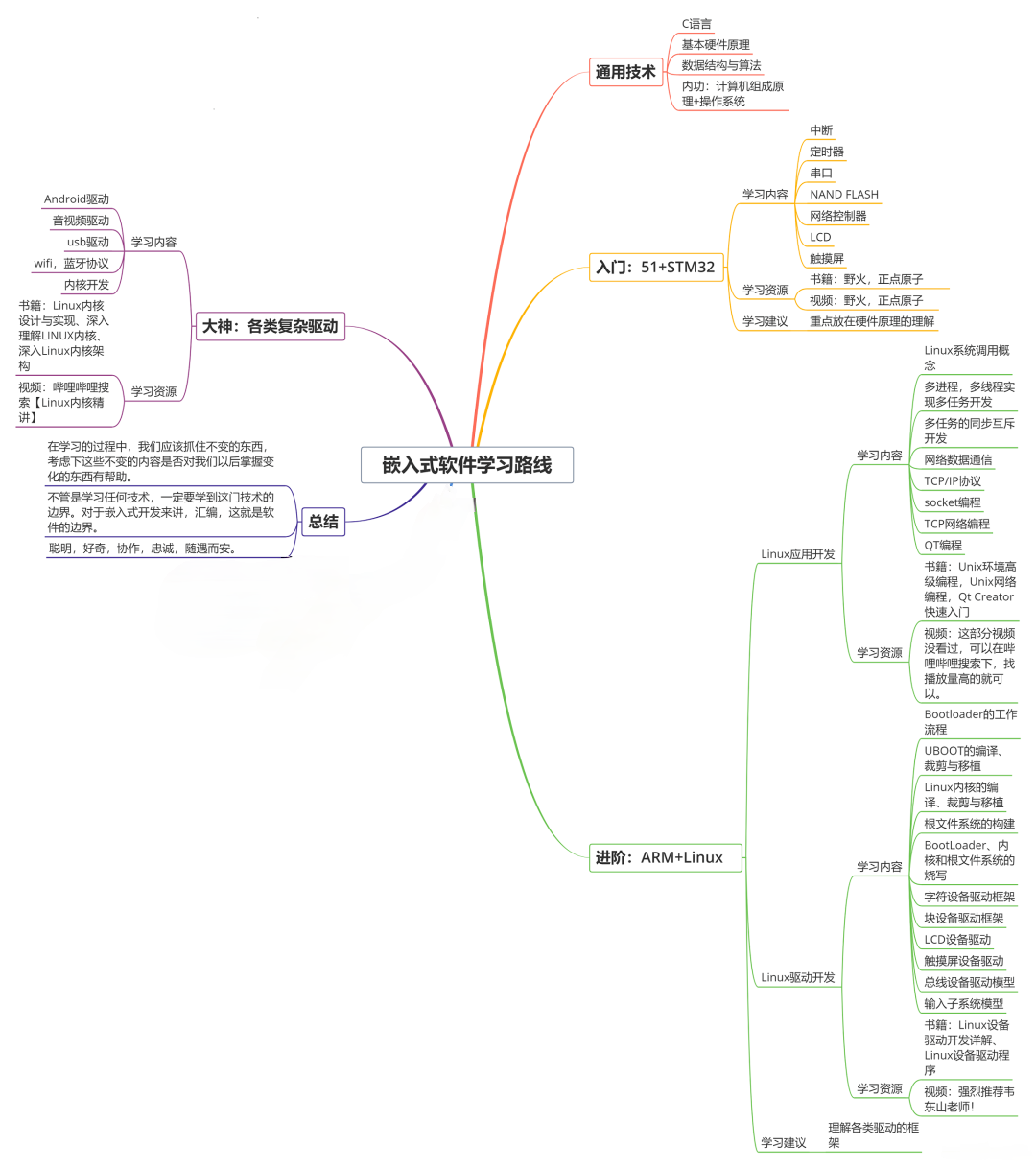
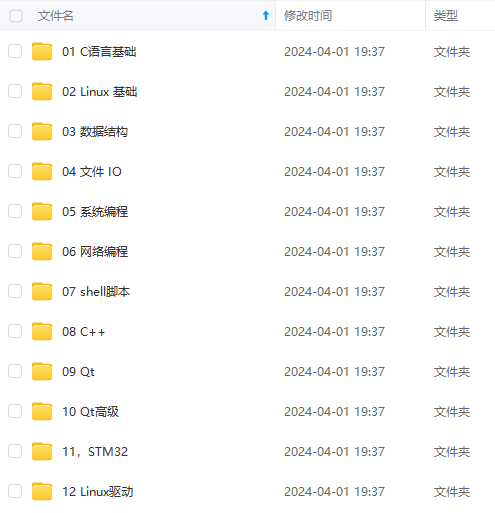
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
In [1]:
from sklearn.datasets import load\_iris
from sklearn.cross\_validation import train\_test\_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
In [2]:
# read in the iris data
iris = load\_iris()
X = iris.data
y = iris.target
In [3]:
for i in xrange(1,5):
print "random\_state is ", i,", and accuracy score is:"
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, random\_state=i)
knn = KNeighborsClassifier(n\_neighbors=5)
knn.fit(X\_train, y\_train)
y\_pred = knn.predict(X\_test)
print metrics.accuracy\_score(y\_test, y\_pred)
random_state is 1 , and accuracy score is:
1.0
random_state is 2 , and accuracy score is:
1.0
random_state is 3 , and accuracy score is:
0.947368421053
random_state is 4 , and accuracy score is:
0.973684210526
上面的测试准确率可以看出,不同的训练集、测试集分割的方法导致其准确率不同,而交叉验证的基本思想是:将数据集进行一系列分割,生成一组不同的训练测试集,然后分别训练模型并计算测试准确率,最后对结果进行平均处理。这样来有效降低测试准确率的差异。
2. K折交叉验证
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。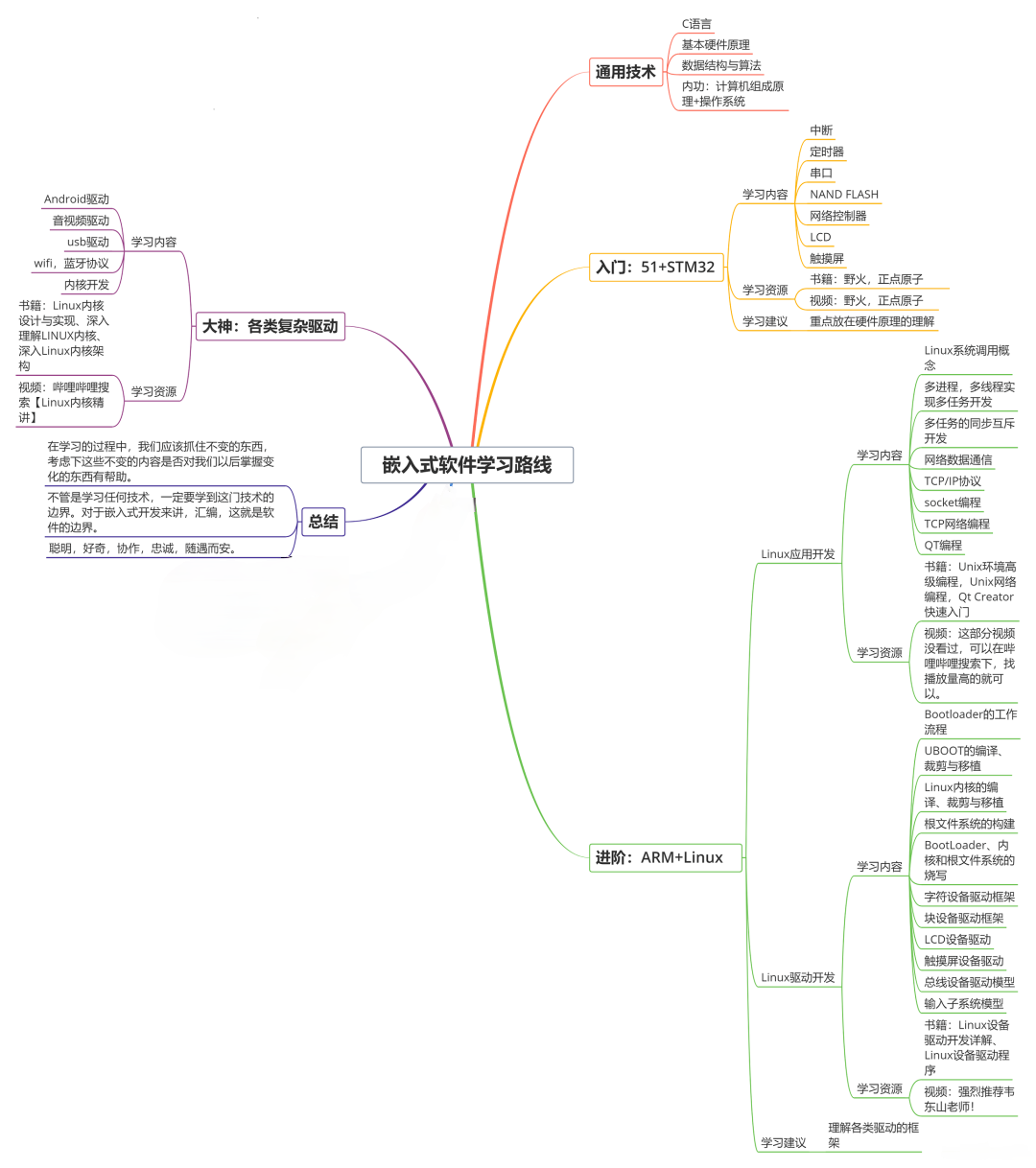
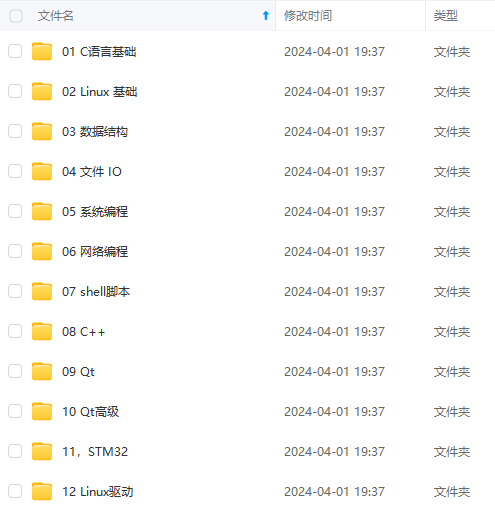
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
,可以加我V获取:vip1024c (备注嵌入式)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)