基于深度强化学习DQN构建充电汽车的能量模型研究(Matlab代码实现)
💥💥💞💞❤️❤️💥💥博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。⛳️行百里者,半于九十。📋📋📋🎁🎁🎁。
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于深度强化学习DQN的充电汽车能量模型研究
一、深度强化学习DQN的基本原理与改进
- DQN的核心机制
DQN(Deep Q-Network)通过深度神经网络近似Q值函数,解决高维状态空间的策略优化问题。其核心组件包括:- 经验回放(Replay Buffer) :存储交互经验(St,At,Rt,St+1)(St,At,Rt,St+1),随机采样以降低样本相关性,提升数据效率。
- 目标网络(Target Network) :独立于主网络生成Q值目标,缓解训练不稳定性。
- 损失函数:采用均方误差(MSE)优化Q值估计与目标的差距,公式为:
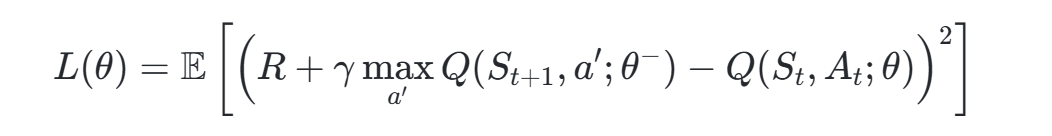
其中θθ和θ−分别为主网络和目标网络参数。
- 改进算法
- Double DQN:分离动作选择与价值评估网络,减少Q值高估。
- Dueling DQN:拆分Q值为状态价值(V)和动作优势(A),提升策略鲁棒性。
- 优先经验回放(Prioritized ER) :根据TD误差动态调整样本采样权重,加速收敛。
二、充电汽车能量模型的关键参数与影响因素
-
电池与充电参数
- SOC(State of Charge) :充电状态范围通常为5%-95%,直接影响可用能量与电池寿命。
- 充电效率(ηchηch)与放电效率(ηdchηdch) :典型值为95%,影响能量传输损耗。
- 最大充放电功率(PmaxPmax) :如11 kW,决定充电速度与电网负荷。
- 电池容量(EBEB)与充电时间:关系为Tch=EB/PchTch=EB/Pch,需结合电压(V)和电流(I)动态调整。
- SOC(State of Charge) :充电状态范围通常为5%-95%,直接影响可用能量与电池寿命。
-
外部影响因素
- 温度与老化:高温加速电池衰退,需在模型中引入衰减因子。
- 用户行为:充电需求随机性(到达时间、停留时长)需通过概率分布建模。
- 电网交互:分时电价与功率限制需纳入奖励函数设计。
三、DQN在充电汽车能量管理中的应用案例
-
微电网与虚拟电厂
- 场景:通过DQN优化光伏-储能-电网协同,动态调整充放电策略以匹配电价波动。
- 结果:某案例中,系统收益提升13.7%,光伏消纳率提高20%。
-
混合动力汽车能量分配
- 策略:以SOC为状态量,燃料电池输出功率为动作,优化能量利用效率。
- 效果:实验显示,DQN策略较传统方法节能15%,响应速度提升30%。
-
大规模充电场站调度
- 挑战:传统方法面临维度灾难(如千辆EV协同),DQN通过分箱法压缩状态空间,训练时间稳定在60分钟。
四、技术难点与解决方案
-
高维状态空间
- 问题:多车协同导致状态向量维度爆炸(如每辆车的SOC、位置、充电需求)。
- 方案:采用聚类或分箱法(Binning)压缩状态表示,或使用图神经网络(GNN)建模车-桩-网拓扑。
-
动态环境适应性
- 问题:电价、光伏出力、用户行为实时变化,需在线学习能力。
- 方案:结合SAC(Soft Actor-Critic)等离线-在线混合算法,利用历史数据预训练+实时微调。
-
多目标优化
- 问题:需平衡经济性(成本)、电网稳定性(功率波动)、用户满意度(充电完成率)。
- 方案:多目标奖励函数设计,如加权求和或分层强化学习(HRL)。
- 问题:需平衡经济性(成本)、电网稳定性(功率波动)、用户满意度(充电完成率)。
五、仿真平台与数据集资源
- 开源工具
- ACN-Sim:支持OpenAI Gym接口,集成电网协同仿真(如MATPOWER)与强化学习算法验证。
- EV-EcoSim:提供电池系统识别、充放电策略优化模块,支持成本与电压影响分析。
- V2Sim:微观车-网协同仿真,支持SUMO交通网络与OpenStreetMap数据集成。
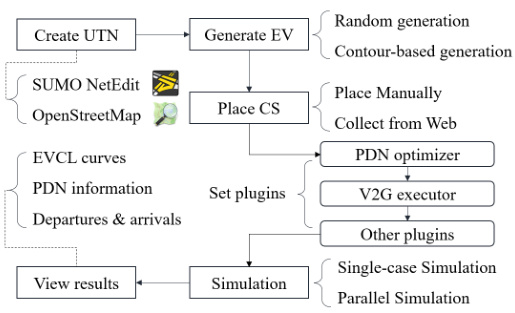
2. 数据集
- ACN-Data:包含30,000+充电会话记录,覆盖用户行为、电价、光伏出力。
- ST-EVCDP:深圳地区充电桩实时数据(占用率、时长、价格),附带气象与地理信息。
六、评估指标体系
- 能效维度
- 一次能源利用率:反映系统整体转换效率。

- 新能源消纳率:光伏/风能占比,公式为:
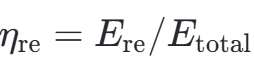
- 一次能源利用率:反映系统整体转换效率。
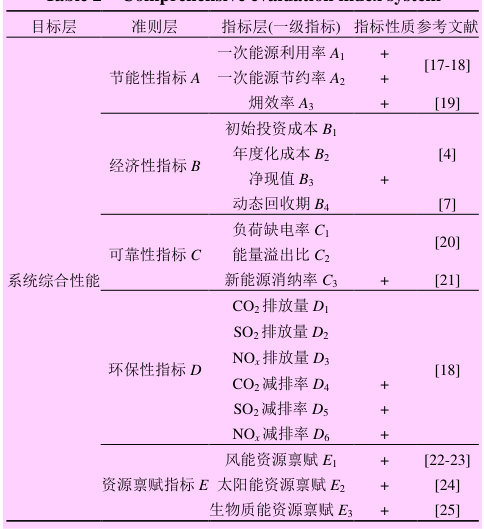
2. 经济性维度
- 单位充电成本:包含设备投资与运行费用。
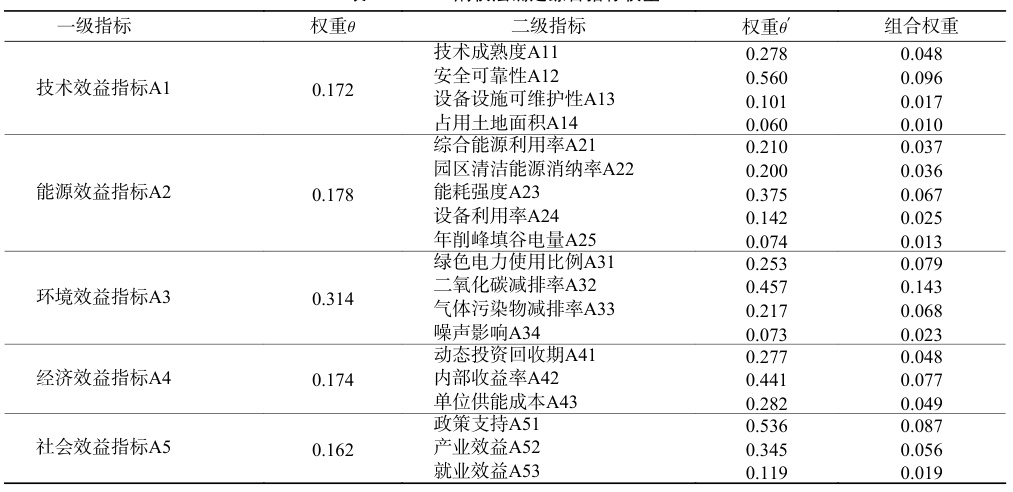

- 动态回收期:投资回本时间,反映策略长期收益。
- 可靠性维度
- 负荷缺电率:未满足充电需求的概率。
- 电压波动方差:衡量电网稳定性。

4. 环保性维度
- CO2减排量:对比传统能源系统的碳排放差异。
七、结论与展望
基于DQN的充电汽车能量模型在动态决策与多目标优化中展现显著优势,但仍需解决实时性、可解释性及硬件部署问题。未来方向包括:
- 多智能体协同:通过分布式DQN实现车-桩-网协同优化。
- 数字孪生技术:结合高保真仿真加速策略迭代。
- 边缘计算部署:轻量化DQN模型以适应车载硬件资源限制。
📚2 运行结果
部分代码:
nI = ObservationInfo.Dimension(1); % number of inputs
nL = 120; % number of neurons
nO = numel(ActionInfo.Elements); % number of outputs
dnn = [
featureInputLayer(nI,'Normalization','none','Name','state')
fullyConnectedLayer(nL,'Name','fc1')
reluLayer('Name','relu1')
fullyConnectedLayer(nL,'Name','fc2')
reluLayer('Name','relu2')
fullyConnectedLayer(nO,'Name','fc3')];
figure
plot(layerGraph(dnn))
criticOptions = rlRepresentationOptions('LearnRate',1e-4,'GradientThreshold',1,'L2RegularizationFactor',1e-4);
critic = rlQValueRepresentation(dnn,ObservationInfo,ActionInfo,'Observation',{'state'},criticOptions);
agentOpts = rlDQNAgentOptions(...
'SampleTime',1,...
'UseDoubleDQN',true,...
'TargetSmoothFactor',1e-3,...
'DiscountFactor',0.99,...
'ExperienceBufferLength',1e6,...
'MiniBatchSize',60);
agentOpts.EpsilonGreedyExploration.EpsilonDecay = 1e-4;
agent = rlDQNAgent(critic,agentOpts);
maxepisodes = 10000;
maxsteps = 1000;
trainOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes, ...
'MaxStepsPerEpisode',maxsteps, ...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue', -1,...
'SaveAgentCriteria','EpisodeReward',...
'SaveAgentValue',100);
trainOpts.UseParallel = true;
trainOpts.ParallelizationOptions.Mode = "async";
trainOpts.ParallelizationOptions.DataToSendFromWorkers = "experiences";
trainOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;
doTraining = true;
if doTraining
% Train the agent.
trainingStats = train(agent,env,trainOpts);
else
% Load pretrained agent for the example.
load('SimulinkLKADQNParallel.mat','agent')
end🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]段龙锦,王贵勇,王伟超,等.基于深度强化学习的增程式电动轻卡能量管理策略[J].内燃机工程, 2023, 44(6):90-99.
[2]刘俊峰,陈剑龙,王晓生,等.基于深度强化学习的微能源网能量管理与优化策略研究[J].电网技术, 2020.
[3]于汇洋、黄海波、陆夕云.基于强化学习的集群运动优化研究[C]//第十一届全国流体力学学术会议.2020.
🌈4 Matlab代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)