多视图数据特征重要性和表示学习方法 WMvRL
多视图数据特征重要性和表示学习方法是机器学习和数据挖掘领域中的一个重要研究方向,特别适用于处理包含多个来源或模态信息的数据集。这类方法旨在从多个视图中提取和融合特征,同时考虑不同视图中的特征对最终任务的重要性,进而生成一个高质量的统一表示。下面详细介绍一下这一方法的关键组成部分和流程。
多视图数据特征重要性和表示学习方法是机器学习和数据挖掘领域中的一个重要研究方向,特别适用于处理包含多个来源或模态信息的数据集。这类方法旨在从多个视图中提取和融合特征,同时考虑不同视图中的特征对最终任务的重要性,进而生成一个高质量的统一表示。下面详细介绍一下这一方法的关键组成部分和流程。
多视图数据特征重要性
在多视图学习中,每个视图提供的特征可能对目标任务的贡献度不同。特征重要性评估旨在量化每个特征对模型预测能力的贡献。常用的方法包括:
- 基于统计的方法:如互信息、卡方检验等,评估特征与目标变量之间的
相关性。 - 基于模型的方法:如随机森林中的特征重要性,通过计算特征分裂带来的信息增益或基尼不纯度减少来评估。
- 基于优化的方法:在优化目标函数的过程中
自动学习特征权重,如LASSO、Elastic Net正则化等。
表示学习
表示学习(Representation Learning)的目标是将原始数据转换成一个更容易进行机器学习的形式,通常是低维、有意义的特征表示。在多视图数据中,表示学习方法通常涉及以下几个步骤:
- 特征提取:从每个视图单独
提取特征,可能包括PCA、t-SNE、词嵌入等。 - 多视图融合:将不同视图的特征以某种方式结合起来,常见的融合策略有早期融合(数据级别)、晚期融合(特征或决策级别)和中间融合(模型级别)。
- 联合表示学习:直接在多视图数据上
学习一个统一的表示,这可以通过多视图聚类、深度学习模型(如多视图自编码器、多视图神经网络)等方法实现。
结合特征重要性和表示学习的方法
在实际操作中,结合特征重要性和表示学习通常遵循以下步骤:
1. 特征权重初始化
- 可以基于上述提到的方法之一,对每个视图的特征进行
初步的权重分配。
2. 加权特征表示构建
- 利用这些权重,对每个视图的数据进行
加权处理,形成加权特征表示。这一步骤可以是简单的加权求和,或者是更复杂的加权融合策略。
3. 多视图融合与表示优化
- 将加权后的各视图特征进一步融合,形成一个
综合的多视图表示。此过程可能涉及到优化问题的设定,如最小化不同视图表示之间的差异、最大化与目标任务相关的表示能力等。
4. 目标函数设计与优化
- 设计一个目标函数,该函数不仅要考虑多视图表示的准确性(如通过分类或回归任务的损失函数衡量),还要考虑特征重要性(通过正则化项控制特征权重的合理性)。
5. 训练与调整
- 使用
梯度下降、变分推断或其他优化技术来调整模型参数和特征权重,以最小化目标函数。
6. 评估与应用
- 在独立的测试集上评估得到的多视图表示,通过
分类准确率、回归误差或其他任务相关的性能指标来衡量方法的有效性。
实例应用
例如,在社交媒体情感分析任务中,可以将文本评论、图像表情和用户互动记录作为三个不同的视图。通过上述流程,我们可以学习到每种信息来源的特征重要性,并融合这些信息形成一个综合的情感表示,以更准确地预测用户的情感倾向。
总之,多视图数据特征重要性和表示学习方法通过综合考虑和优化不同数据视图的特征,提升了模型的泛化能力和理解复杂数据的能力,广泛应用于推荐系统、多媒体检索、生物信息学等多个领域。
例子
假设我们有一个电影推荐系统,其数据包含两个视图——用户的文本评论(Text View)和用户的历史评分记录(Rating View),目标是学习一个用户偏好表示用于电影推荐。
计算步骤与涉及公式
1. 数据预处理
- Text View: 对每条文本评论进行
分词、去除停用词,然后使用TF-IDF转换为向量表示。 - Rating View: 构建用户对电影的评分矩阵,
未评分的用0填充。
2. 特征重要性评估(以Text View为例)
采用TF-IDF值作为初步的特征重要性指标。对于词汇w在文档d中的重要性可表示为:
TF-IDF(w,d)=tf(w,d)×idf(w)\text{TF-IDF}(w,d) = \text{tf}(w,d) \times \text{idf}(w)TF-IDF(w,d)=tf(w,d)×idf(w)
其中,
- tf(w,d)\text{tf}(w,d)tf(w,d)是词
w在文档d中的词频, - idf(w)=logNnw\text{idf}(w) = \log\frac{N}{n_w}idf(w)=lognwN,其中
N是文档总数,nwn_wnw是包含词w的文档数。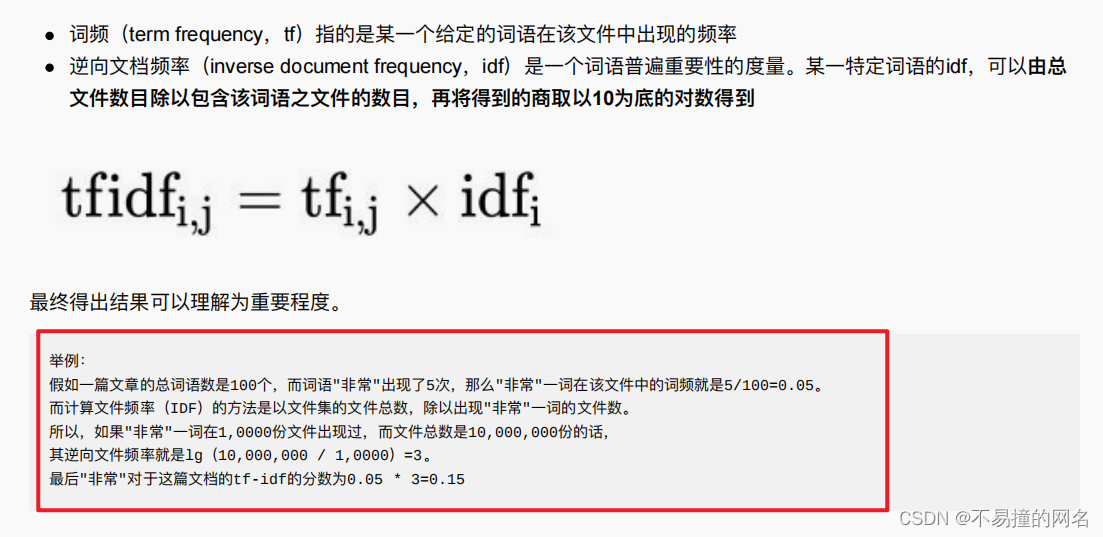
3. 加权特征表示构建
对于Text View,直接利用TF-IDF作为特征权重。对于Rating View,可以基于评分频率或评分方差 来赋予每个评分项重要性,例如:
Weight(rij)=σij∑kσik \text{Weight}(r_{ij}) = \frac{\sigma_{ij}}{\sum_k \sigma_{ik}} Weight(rij)=∑kσikσij
这里σij\sigma_{ij}σij是用户 i 对电影 j 评分的标准差,用于衡量评分的波动性,波动性越大表示该评分对用户偏好的揭示能力越强。
在上述公式中,(r_{ij}) 表示用户 (i) 对电影 (j) 的评分。这个符号通常用于推荐系统和协同过滤任务中,其中:
- (i) 是用户索引,
- (j) 是电影索引,
- rijr_{ij}rij 是一个实数值,表示用户 (i) 对电影 (j) 打出的具体评分。
4. 多视图融合
采用加权融合策略,构建综合用户偏好表示 vuv_uvu:
vu=α⋅∑d∈TextuTF-IDF(d)+(1−α)⋅∑jWeight(ruj)⋅ruj v_u = \alpha \cdot \sum_{d \in \text{Text}_u} \text{TF-IDF}(d) + (1-\alpha) \cdot \sum_{j} \text{Weight}(r_{uj}) \cdot r_{uj} vu=α⋅d∈Textu∑TF-IDF(d)+(1−α)⋅j∑Weight(ruj)⋅ruj
其中,α\alphaα是融合系数,平衡文本评论和评分记录的重要性。
TF-IDF(d)\text{TF-IDF}(d)TF-IDF(d) 是一个术语,表示文档(或在这个上下文中,用户的文本评论)(d) 中每个词的TF-IDF值的累加或加权和,用于计算用户 (u) 在文本视图(Text View)上的加权表示。
5. 目标函数设计与优化
假设我们使用矩阵分解(如SVD)来进一步优化表示并预测未知评分。目标函数可以是预测误差的最小化,加上一个正则项来防止过拟合:
minU,V∑(i,j)∈Ω(rij−uiTvj)2+λ(∣∣U∣∣2+∣∣V∣∣2)\min_{U,V} \sum_{(i,j) \in \Omega} (r_{ij} - u_i^T v_j)^2 + \lambda(||U||^2 + ||V||^2)U,Vmin(i,j)∈Ω∑(rij−uiTvj)2+λ(∣∣U∣∣2+∣∣V∣∣2)
其中,(U)和(V)分别是用户和电影的低维表示矩阵,Ω\OmegaΩ是已知评分的索引集合,λ\lambdaλ是正则化参数。
在公式 minU,V∑(i,j)∈Ω(rij−uiTvj)2+λ(∣∣U∣∣2+∣∣V∣∣2)\min_{U,V} \sum_{(i,j) \in \Omega} (r_{ij} - u_i^T v_j)^2 + \lambda(||U||^2 + ||V||^2)minU,V∑(i,j)∈Ω(rij−uiTvj)2+λ(∣∣U∣∣2+∣∣V∣∣2) 中,这是一个典型的矩阵分解问题,通常用于推荐系统或者协同过滤等场景。这里的 uiu_iui 和 vjv_jvj 分别代表用户和用户偏好表示 的 latent factor(隐含因子)向量。
具体来说:
- uiu_iui 表示第 (i) 个用户在
低维空间中的特征向量。在推荐系统中,这个向量可以理解为该用户的偏好向量,反映了用户对不同隐含特征的喜好程度。 - vjv_jvj 类似地,表示第 (j) 个物品的特征向量,可以理解为该物品的属性向量,反映了物品在这些隐含特征上的
表达强度。
公式解释:
- rijr_{ij}rij 表示用户 (i) 对电影 (j) 的实际评分(如果已知的话),或者表示用户 (i) 是否与电影 (j) 有交互(如购买、点击等)的二元指示。
- Ω\OmegaΩ 是观察到的用户-电影交互的集合,即我们有数据的评分或交互对。
- uiTvju_i^T v_juiTvj 是用户 (i) 的特征向量与物品 (j) 的
特征向量的点积,可以看作是基于隐含特征预测出的用户 (i) 对物品 (j) 的评分。 - (rij−uiTvj)2(r_{ij} - u_i^T v_j)^2(rij−uiTvj)2 计算的是
预测评分与实际评分之间的差的平方,也就是预测误差的平方和,这是最小化的目标函数,意在使模型预测尽可能接近实际评分。 - λ(∣∣U∣∣2+∣∣V∣∣2)\lambda(||U||^2 + ||V||^2)λ(∣∣U∣∣2+∣∣V∣∣2) 是正则项,其中 ∣∣U∣∣2||U||^2∣∣U∣∣2 和 ∣∣V∣∣2||V||^2∣∣V∣∣2 分别是用户和电影特征向量矩阵的 Frobenius 范数的平方,λ\lambdaλ 是正则化参数,用来控制模型复杂度,
避免过拟合。通过加入这个项,鼓励学习到的 (U) 和 (V) 向量元素值较小,增加模型的泛化能力。
6. 训练与调整
通过梯度下降法或其他优化算法迭代更新(U)和(V),直至收敛。
7. 应用
得到用户和电影的低维表示后,可以计算任意用户对未评分电影的预测评分,从而进行个性化推荐。
这个例子展示了如何将特征重要性评估融入到多视图表示学习中,通过综合不同类型的用户行为数据,提升推荐系统的精准度和鲁棒性。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)